Selected from the HuggingFace blog
This article will introduce the building blocks of MoE, training methods, and the trade-offs to consider when using them for inference.
Mixture of Experts (MoE) is a commonly used technique in LLMs aimed at improving efficiency and accuracy. The way this method works is by breaking complex tasks into smaller, more manageable subtasks, each handled by a specialized mini-model or “expert”.
Earlier, it was revealed that GPT-4 adopted an ensemble system consisting of 8 expert models. Recently, Mistral AI released Mixtral 8x7B, which also uses this architecture, achieving impressive performance (link: a magnetic link sweeping the AI community, 87GB seed directly open-sourced 8x7B MoE model).
The two pushes from OpenAI and Mistral AI have made MoE a hot topic in the open AI community.
This article will introduce the building blocks of MoE, training methods, and the trade-offs to consider when using them for inference.
MoE, short for Mixture of Experts, has the following characteristics:
-
Faster pre-training speed compared to dense models;
-
Faster inference speed compared to models with the same number of parameters;
-
Requires a large amount of GPU memory since all expert models need to be loaded into memory;
-
Faces many challenges in fine-tuning, but recent work in MoE instruction fine-tuning is promising in solving these issues.
What Is Mixture of Experts (MoE)?
The scale of the model is one of the most important factors determining model quality. Given a fixed budget, training a larger model with fewer steps is better than training a smaller model with more steps.
MoE can pre-train models with fewer computational resources, meaning it can significantly enlarge the model or dataset size with the same computational cost as dense models. Specifically, during pre-training, MoE models can reach performance comparable to dense models much faster.
So, what exactly is MoE? From the perspective of transformer models, MoE consists of two main elements:
-
Using sparse MoE layers instead of dense feedforward network (FFN) layers. In MoE layers, there are a certain number (e.g., 8) of “experts”, each of which is a neural network. In practice, experts can be FFNs or more complex networks, or even MoEs themselves, forming a multi-layer MoE structure.
-
Using gating networks or routing to decide which token to send to which expert. For example, in the diagram below, “More” is sent to the second expert while “Parameters” is sent to the first expert. Planning how to route tokens to experts is one of the key considerations when using MoE, as routing is also composed of learned parameters and is pre-trained simultaneously with other parts of the network.
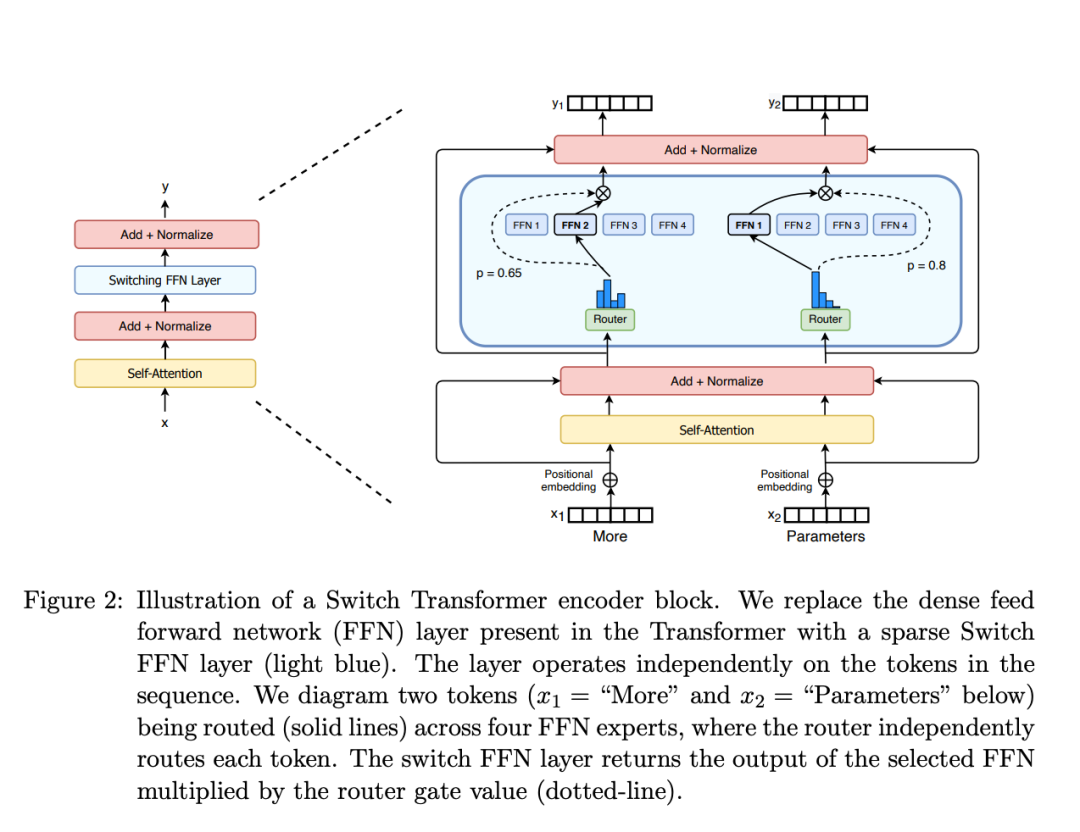
MoE Layer in Switch Transformers (https://arxiv.org/abs/2101.03961)
In short, in MoE, an MoE layer replaces each FFN layer in the transformer, composed of a gating network and a certain number of expert networks.
Although MoE has advantages such as efficient pre-training and fast inference compared to dense models, it also faces several challenges:
-
Training: MoE can significantly improve pre-training computational efficiency, but it struggles with generalization during fine-tuning, leading to overfitting.
-
Inference: Although MoE may have many parameters, only a portion of them is used during inference. Inference speed is much faster than that of a dense model with the same number of parameters. However, all parameters need to be loaded into RAM, resulting in high memory requirements. For example, given a MoE like Mixtral 8x7B, sufficient GPU memory is needed to accommodate a dense model with 47B parameters. Why 47B parameters instead of 8 x 7B = 56B? This is because, in MoE models, only the FFN layers are considered independent expert networks, while the parameters of the rest of the model are shared. At the same time, assuming each token only passes through two expert networks, the inference speed (FLOPs) behaves like using a 12B model (instead of a 14B model) because it performs 2x7B matrix multiplication, while some layers are shared (which will be detailed later).
Having provided a rough introduction to MoE, let’s delve into the development trajectory of MoE.
MoE originated from the 1991 paper “Adaptive Mixture of Local Experts” (https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf). The idea of this paper is similar to ensemble methods, providing a supervisory program for systems composed of different networks, with each network handling different subsets of the training set. Each individual network or expert specializes in different regions of the input space. As for how to select experts, this is determined by the gating network, which assigns weights to each expert network. During training, both the expert networks and the gating network need to be trained.
Between 2010 and 2015, the development of two research areas contributed to the later advancements of MoE:
-
Componentization of expert networks: In traditional MoE, the entire system consists of a gating network and multiple expert networks. Researchers explored MoE as a holistic model in SVMs, Gaussian processes, and other methods. Eigen, Ranzato, and Ilya’s research explored using MoE as part of deeper networks. MoE can be a component of multi-layer networks, making it possible for models to be both large and efficient.
-
Conditional computation: Traditional networks process all input data at each layer. Subsequently, Yoshua Bengio studied methods to dynamically activate or deactivate component networks based on the input tokens.
These works prompted researchers to explore mixture of experts models in the context of NLP. Specifically, Shazeer, Geoffrey Hinton, Jeff Dean, and Google’s Chuck Norris expanded this idea to a 137B LSTM (https://arxiv.org/abs/1701.06538) by introducing sparse networks, thus maintaining extremely fast inference speed even at large scales. The focus of this work is on machine translation, although it also has some drawbacks, such as high communication costs and training instability.
MoE Layer in Outrageously Large Neural Network Paper
MoE can train models with trillions of parameters, such as the open-source 1.6T parameter Switch Transformer. The field of computer vision is also exploring MoE, but here we will focus on explaining it in the context of NLP.
The term sparsification comes from the idea of conditional computation. In dense models, all parameters are active, while sparsification allows only certain parts of the entire system to run.
As mentioned earlier, Shazeer explored MoE in machine translation. Conditional computation (only certain parts of the network are active) allows for scaling model size without increasing computational load, thus each MoE layer can contain thousands of expert networks.
However, this design brings some challenges. For example, while increasing batch size generally benefits model performance, the batch size in MoE can shrink as data flows through the activated expert networks. For instance, if the batch size is 10 tokens, where 5 tokens may end up in one expert network, and the other 5 tokens may end up in 5 different expert networks, resulting in uneven batch size and underutilization.
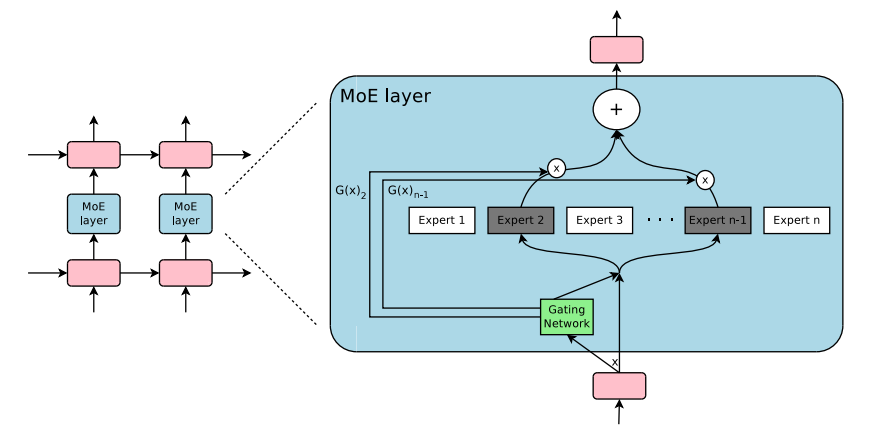
How to solve this problem? One method is to let the learned gating network (G) decide which expert networks (E) to relay input information to:
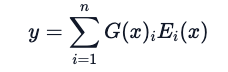
In this case, all expert networks will compute all inputs — using a weighted multiplication approach. However, what if G is 0? In this case, there is no need to compute through the corresponding expert network, saving computational resources. So, what does a typical gating function look like? In the most traditional setting, a simple network with a softmax function is used. This network learns which expert to relay input data to.

Shazeer’s research also explored other gating mechanisms, such as Top-K noise gating. This gating method introduces some (tunable) noise and then retains the top K. That is:

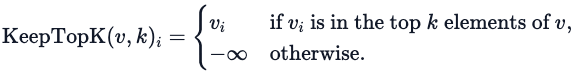
3. Activate with softmax.

This sparsification operation brings some interesting characteristics. By using a sufficiently small k (e.g., one or two), researchers found that training and inference speeds are faster than settings that activate many expert networks. So why not just keep the expert network when top=1? The initial guess of researchers was that routing to more than one expert is necessary for the gating network to learn how to route to different experts, hence at least two experts must be selected. The Switch Transformer part will revisit this decision.
Why add noise? This is for load balancing.
As mentioned earlier, if all tokens are only sent to a few favored expert networks, training efficiency will become poor. Typically in MoE training, the gating network tends to converge to frequently activating the same few expert networks. This situation becomes more pronounced as training progresses, as the favored expert networks are trained faster and thus more easily selected. To mitigate this, an auxiliary loss can be added to encourage equal importance for all experts. This loss ensures that all experts receive roughly the same number of training samples. Later, we will explore the concept of expert capacity, which is the threshold for how many tokens an expert can handle. In transformers, the auxiliary loss is indicated through the aux_loss parameter.
Transformers are a clear example where increasing the number of parameters can improve performance, thus it is natural for Google to extend the parameter count of Transformers to over 600 billion in GShard.
GShard uses top-2 gating technology in both the encoder and decoder, replacing FFN layers with MoE layers. The diagram below shows part of the encoder.
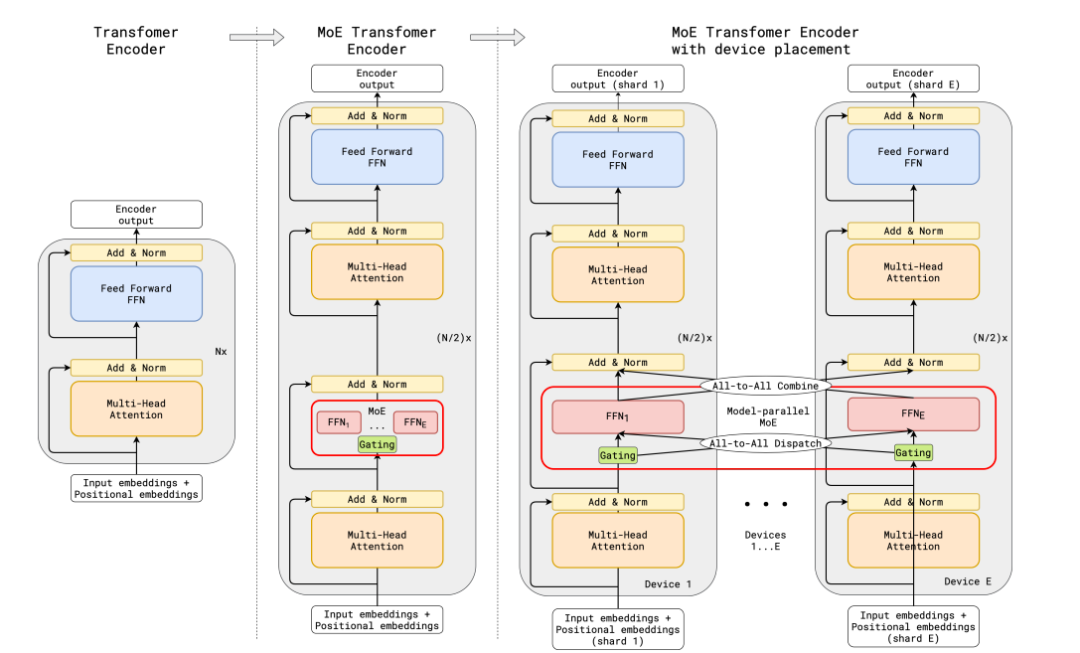
MoE Transformer Encoder in GShard
This setup is very favorable for large-scale computation: when scaled across multiple devices, MoE layers will be shared across devices, while all other layers will be replicated. Specific details will be further discussed in the section “Efficient Training of MoE”.
To maintain balanced load and scale efficiency, the authors of GShard introduced some improvements, in addition to using auxiliary losses similar to those discussed in the previous section:
-
Random routing: In the top-2 setting, researchers always select the first-ranked expert, while the second expert is selected with a probability proportional to its weight.
-
Expert capacity: A threshold can also be set for how many tokens an expert can handle. If both experts have reached their capacity, the token is considered overflow and is sent to the next layer via residual connections (or completely dropped in other instances). This concept will become one of the most important concepts in MoEs. Why set expert capacity? Because all tensor shapes are statically determined at compile time, but it is impossible to know in advance how many tokens each expert will receive as input, so capacity needs to be determined.
The contribution of GShard lies in establishing a parallel computing model for MoEs. It is important to note that during inference, only a portion of the expert networks will be triggered. At the same time, there are also steps that require data sharing, such as self-attention mechanisms, applicable to all tokens. This is why, for a 47B model composed of 8 experts, GShard can compute it with a 12B dense model. If using top-2, it would require 14B parameters. However, considering that attention operations are shared, the actual number of parameters used is 12B.
Despite the bright prospects of MoE, they still have drawbacks in training and fine-tuning instability. The emergence of the Switch Transformer (https://arxiv.org/abs/2101.03961) is significant, as the authors even released a model with 2048 experts and 1.6 trillion parameters on Hugging Face (https://huggingface.co/google/switch-c-2048). Compared to T5-XXL, the pre-training speed of the Switch Transformer improved by 4 times.
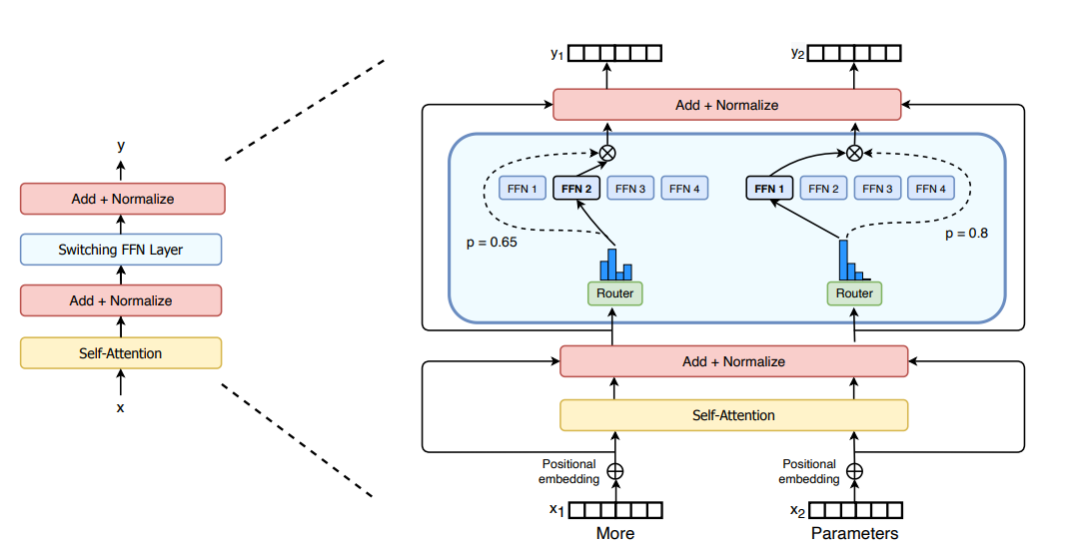
Switch Transformer Layer in Switch Transformer Paper
Just as the authors of GShard replaced FFN layers with MoE layers, the Switch Transformer paper proposed a Switch Transformer layer that takes two inputs (two different tokens) and has four expert networks.
In contrast to the initial idea of using at least two expert networks, Switch Transformers adopted a simplified single-expert strategy. The effects of this approach are as follows:
-
Reduces the computational load of routing
-
Each expert’s batch size is at least halved
-
Reduces communication costs
-
Still guarantees the quality of the model
Switch Transformer also explores the concept of expert capacity.
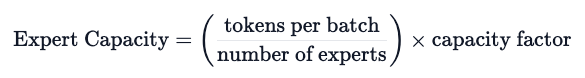
The recommended capacity calculation method mentioned above averages the number of tokens in the batch size across experts. If a capacity factor greater than 1 is used, it can provide a buffer when tokens are not perfectly balanced. Increasing capacity leads to higher communication costs between devices, so trade-offs need to be carefully considered. Especially under lower capacity factors (1-1.25), the performance of Switch Transformer is particularly outstanding.
The authors of Switch Transformer also revisited and simplified the load balancing loss mentioned in the chapter. For each switch layer, the auxiliary loss is added to the total loss of the model during training. This loss encourages the model to tend towards uniform routing and can be weighted using hyperparameters.
The authors of Switch Transformer also experimented with selective precision, such as using bfloat16 parameter precision for training experts while using full precision for other computations. Lower precision can reduce communication costs, computational costs, and memory for storing tensors. In the initial experiments, both the experts and the gating network were trained using bfloat16, but the training results were unstable. This was primarily due to the routing network’s involvement in the computation: since the routing network has exponential functions, higher precision is very important. To reduce instability, routing was also computed using full precision.
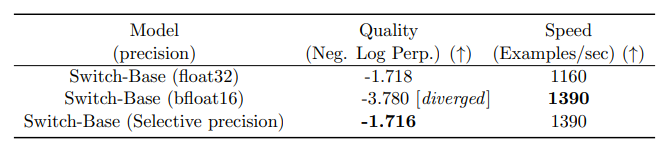
Using selective precision does not degrade quality and can train models faster.
In the fine-tuning section, Switch Transformer used an encoder-decoder setting and corresponded T5 with MoE. GLaM (https://arxiv.org/abs/2112.06905) explored how to train models with GPT-3 quality at one-third of the computational cost, thereby scaling model size. The focus of GLaM authors’ research is on pure decoder models and the evaluation results of few-shot and zero-shot, not fine-tuning. They used Top-2 routing and larger capacity factors. Additionally, they also investigated capacity factors as a metric, which can be adjusted based on the desired computational amount during training and validation.
Stable Training Based on Z-loss Loss Function for Routing Networks
The balancing loss discussed above may lead to instability issues. However, many methods can be used to stabilize sparse models at the cost of quality. For example, introducing dropout can improve stability but harms model performance. On the other hand, adding more multiplicative components can enhance model performance quality but reduce stability.
The routing loss introduced in ST-MoE (https://arxiv.org/abs/2202.08906) penalizes large logarithmic values entering the gating network, significantly improving training stability without compromising quality. Since this loss encourages smaller values, rounding errors decrease, which greatly affects the exponential functions in the gating.
What Can Expert Networks Learn?
According to the observations of ST-MoE authors, encoding expert networks focus on groups of tokens or shallow concepts. For example, punctuation experts, proper noun experts, etc. On the other hand, decoding expert networks have lower specialization. The authors also trained in multilingual environments. Contrary to what one might imagine, no expert network specializes in a single language: due to the routing distribution and load balancing of tokens, no single language expert network is specialized.
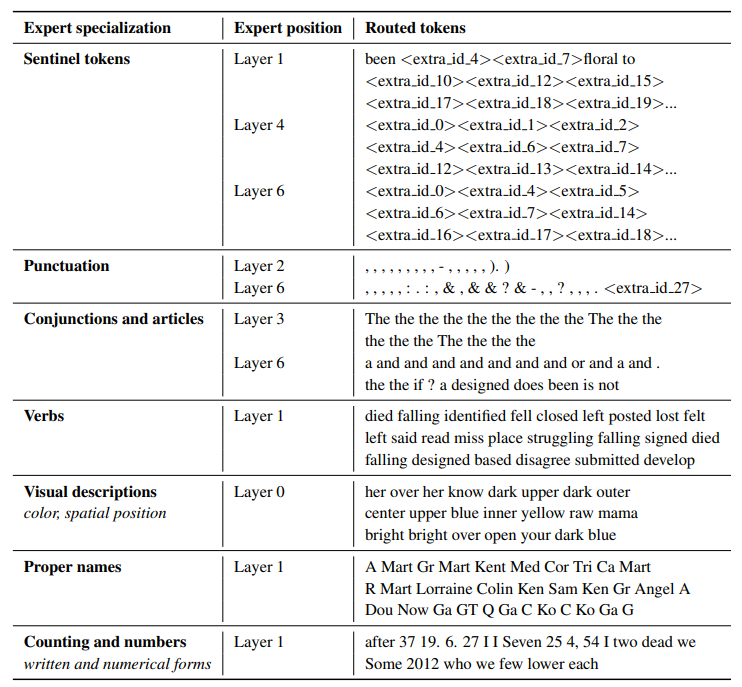
Table in ST-MoE Paper Showing Which Expert Each Group of Tokens Was Sent To
The Impact of Increasing the Number of Experts on Pre-training
The more experts there are, the higher the sampling efficiency and the faster the speed, but the returns diminish (especially after a scale of 256 or 512), and inference requires more GPU memory. The large-scale characteristics studied in Switch Transformers are consistent even in small scales, even when each layer has 2, 4, or 8 experts.
Mixtral supports version 4.36.0 of transformers. Use pip install “transformers==4.36.0 –upgrade” to update.
The overfitting dynamics of dense models and sparse models are entirely different. Sparse models are more prone to overfitting, thus, higher regularization can be explored within the experts themselves (e.g., a dropout can be set for dense layers and a higher dropout for sparse layers).
Another decision-making issue is whether to use auxiliary loss for fine-tuning. The authors of ST-MoE tried turning off auxiliary loss and found that even with up to 11% token dropping, the quality was not significantly affected. Token dropping may be a form of regularization that helps prevent overfitting.
The authors of Switch Transformer observed that with fixed pre-training perplexity, sparse models performed worse on downstream tasks than dense models, especially in tasks heavy on inference, such as SuperGLUE. On the other hand, sparse models surprisingly performed well on knowledge-intensive datasets like TriviaQA. The authors also observed that fewer experts helped fine-tuning. Another observation regarding generalization issues is that models perform poorly on smaller tasks but well on larger ones.
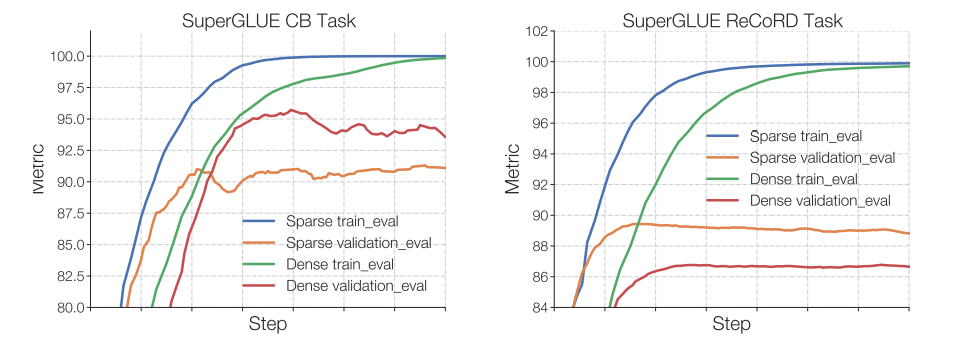
In smaller tasks (left image), significant overfitting can be seen, with sparse models performing much worse on the validation set. In larger tasks (right image), MoE performs well. The images are from the ST-MoE paper.
Attempting to freeze all non-expert weights resulted in a significant drop in performance, which was expected since the MoE layers occupy most of the network. Conversely, when attempting the opposite method: only freezing the parameters of the MoE layers, it was found that the results were almost as good as updating all parameters. This finding helps speed up fine-tuning and reduce memory usage.
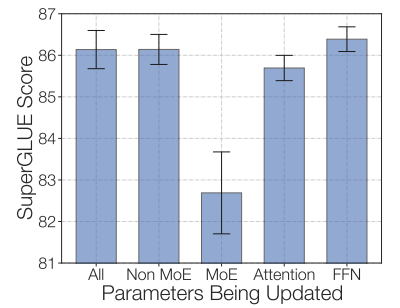
By only freezing the MoE layers, training speed can be accelerated while maintaining quality. This image is from the ST-MoE paper.
The final issue to consider when fine-tuning sparse MoE is that different MoEs have different fine-tuning hyperparameters — for example, sparse models often benefit more from smaller batch sizes and higher learning rates.
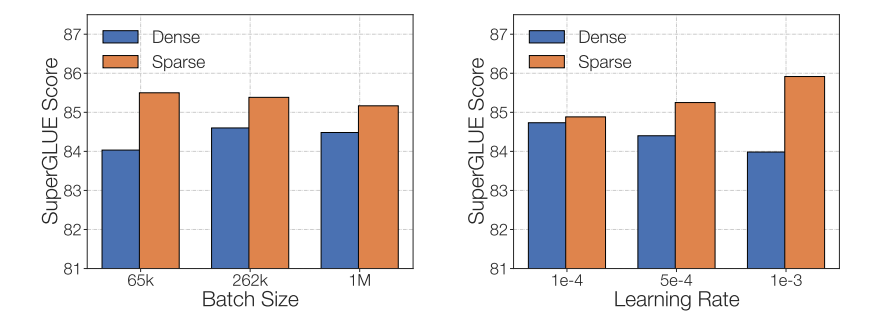
The quality of fine-tuning sparse models improves with increasing learning rates and decreasing batch sizes. This image is from the ST-MoE paper.
Researchers have been working hard to fine-tune MoE, a process fraught with twists and turns. A recent paper titled “MoEs Meets Instruction Tuning” conducted experiments such as:
-
-
Multi-task instruction fine-tuning
-
Single-task fine-tuning after multi-task instruction tuning
In the paper, when the authors fine-tuned MoE and T5, T5’s equivalent simulated output performed better. When the authors fine-tuned Flan T5 and MoE, MoE’s performance was significantly better. Moreover, the improvement of Flan-MoE relative to MoE was greater than that of Flan T5 relative to T5, indicating that MoE may benefit more from instruction tuning than dense models. The increase in tasks benefits MoE even more. Contrary to previous recommendations to turn off the auxiliary loss function, the loss function can actually help prevent overfitting.
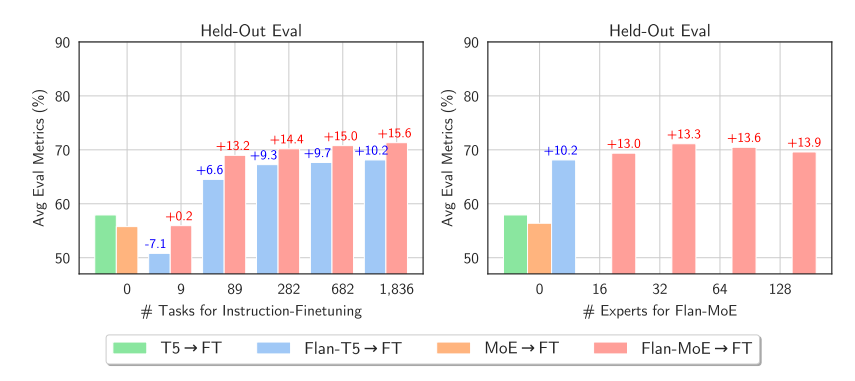
Sparse models benefit more from instruct-tuning compared to dense models. This image is from the “MoEs Meets Instruction Tuning” paper.
When to Use Sparse MoE and When to Use Dense MoE?
Expert models are suitable for high-throughput scenarios using multiple machines. Given a fixed pre-training computational budget, sparse models will be more ideal. For low-throughput scenarios with limited GPU memory, dense models will perform better.
Note: It is not appropriate to directly compare the parameter counts of sparse and dense models, as they represent distinctly different meanings.
Efficient Training of MoE
The initial MoE work set the MoE layers as a branching setup, leading to slow model computation speeds because GPUs were not designed for this, and the need for devices to send information to other devices resulted in network bandwidth becoming a bottleneck. This section will discuss some existing works to make the pre-training and inference of these models more practical.
Types of parallel computing:
-
Data parallelism: The same weights are replicated across all cores, and data is split across cores.
-
Model parallelism: The model is partitioned across different cores, and data is replicated across different cores.
-
Model and data parallelism: The model and data are partitioned across different cores. Note that different cores handle different batches of data.
-
Expert parallelism: Experts are placed on different workstations. If combined with data parallelism, each core has different experts, and data is split across all cores.
In the expert parallelism mode, experts are placed on different workstations, each workstation collecting different batches of training samples. For non-MoE layers, the behavior of expert parallelism is the same as data parallelism. For MoE layers, the tokens in the sequence are sent to the workstation where the required expert is located.
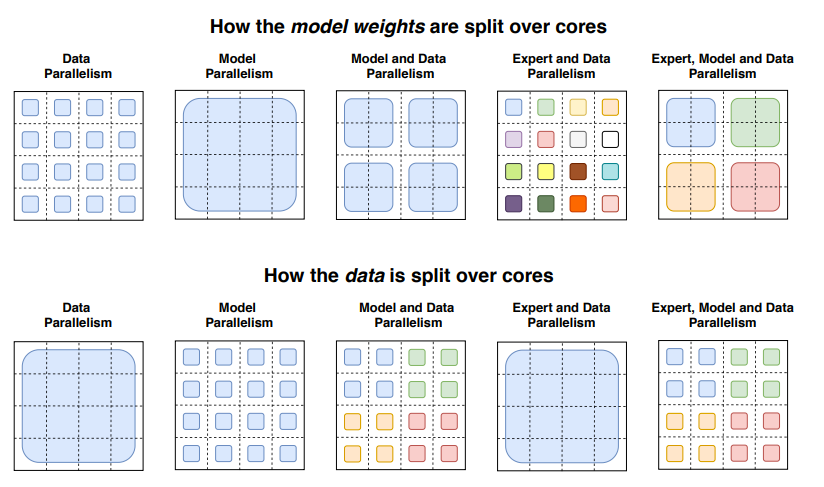
Illustration from Switch Transformers Paper Showing How Data and Models Are Split Across Different Cores via Different Parallel Techniques.
Capacity Factor and Communication Costs
Increasing the capacity factor (CF) can improve model quality but increases communication costs and memory overhead. If all-to-all communications are slow, using a smaller capacity factor is better. Here’s a configuration you can refer to: using a top-2 routing mechanism with a capacity factor of 1.25, leaving one expert per core. During validation, the capacity factor can be adjusted to reduce computational load.
mistralai/Mixtral-8x7B-Instruct-v0.1 can be deployed to inference terminals.
A significant drawback of MoE is the large number of parameters. Local use cases may prefer to use smaller models. Here are several techniques that help with local deployment:
-
The authors of Switch Transformer conducted distillation experiments. Distilling MoE into dense models can retain 30-40% of the sparsification gains. Therefore, distillation can provide faster preprocessing speeds and the benefits of smaller models.
-
Innovative routing algorithms: Route complete sentences or tasks to expert networks, using sub-networks for extraction to provide services.
-
MoE aggregation: This technique can merge expert weights, thus reducing the parameters used during inference.
Other Efficient Training Methods
FasterMoE (proposed in March 2022) analyzes the performance of MoE in efficient distributed systems and examines the theoretical limits of different parallel strategies, as well as techniques to reduce latency through fine-grained communication scheduling and topology-aware gating that selects experts based on the lowest latency, resulting in a 17-fold speed increase.
Megablocks (https://arxiv.org/abs/2211.15841) introduced a brand-new GPU kernel capable of handling the dynamic problems present in MoE, exploring efficient sparse pre-training. The paper recommends not dropping any token and implements efficient token mapping techniques to significantly enhance speed. The trick is that traditional MoE uses batched matrix multiplication, assuming all experts have the same shape and the same number of tokens. In contrast, Megablocks represents MoE layers as block sparse operations, capable of adapting to unbalanced distributions.
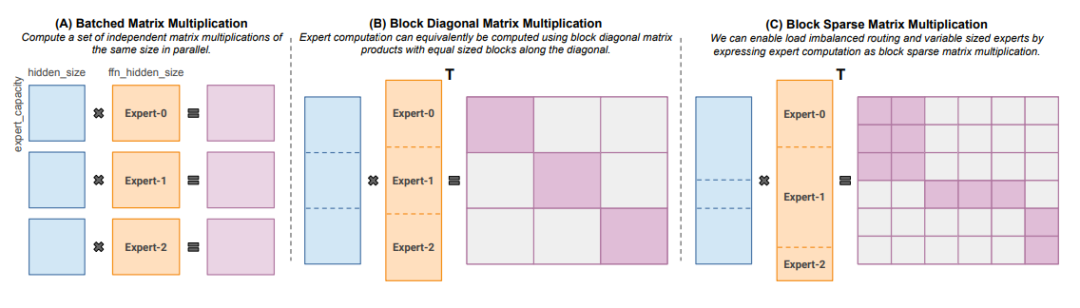
Block Sparse Matrix Multiplication for Different Sizes of Experts and Tokens. Image from MegaBlocks Paper.
Open-source MoE Algorithms
Current open-source MoE projects:
-
Megablocks: https://github.com/stanford-futuredata/megablocks
-
Fairseq: https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm
-
OpenMoE: https://github.com/XueFuzhao/OpenMoE
-
Switch Transformer (Google): A T5-based ensemble engine with 8 to 2048 experts. The largest model has 1.6 trillion parameters.
-
NLLB MoE (Meta): MoE variant of the NLLB translation model.
-
OpenMoE: MoE based on Llama.
-
Mixtral 8x7B (Mistral): A high-quality translation model outperforming Llama 2 70B, with faster inference speed.
Here are some interesting areas worth exploring:
-
Distilling Mixtral into dense models
-
Exploring merging techniques for expert models and analyzing their impact on inference time
-
Quantization techniques for Mixtral
Original link: https://huggingface.co/blog/moe?continueFlag=a09556ebd7121bce97f7bbb8eb2598c8
© THE END
For reprints, please contact this public account for authorization
For submissions or inquiries: [email protected]

