
Recently, it feels like the New Year has come early. Just last night, DeepSeek and Kimi both released their version 1.0, and Kimi was the first to publish its technical report, which is quite interesting… When it comes to Kimi, everyone has the impression that it has a technological first-mover advantage, being the first to thoroughly understand long texts and leading in productization. Their first technical report is definitely worth studying carefully.
Just as I was about to get started, I noticed that the great Jim Fan was also looking at it, and he commented:

First, looking at the results, one sentence sums it up: it is the strongest in multimodal long reasoning, and it can shorten model inference without significantly degrading performance. This also indirectly indicates that the Kimi 1.5 series has infinite potential; it is hard to imagine how explosive the pure text performance would be when fully scaled.
Looking at the rankings, Kimi 1.5 far exceeds OpenAI’s version 1.0 in long reasoning for mathematics, pure text, and multimodal tasks; it performs comparably to it on Codeforces assessments, and slightly worse on LiveCode assessments, but has a significant advantage over QVQ and QwQ.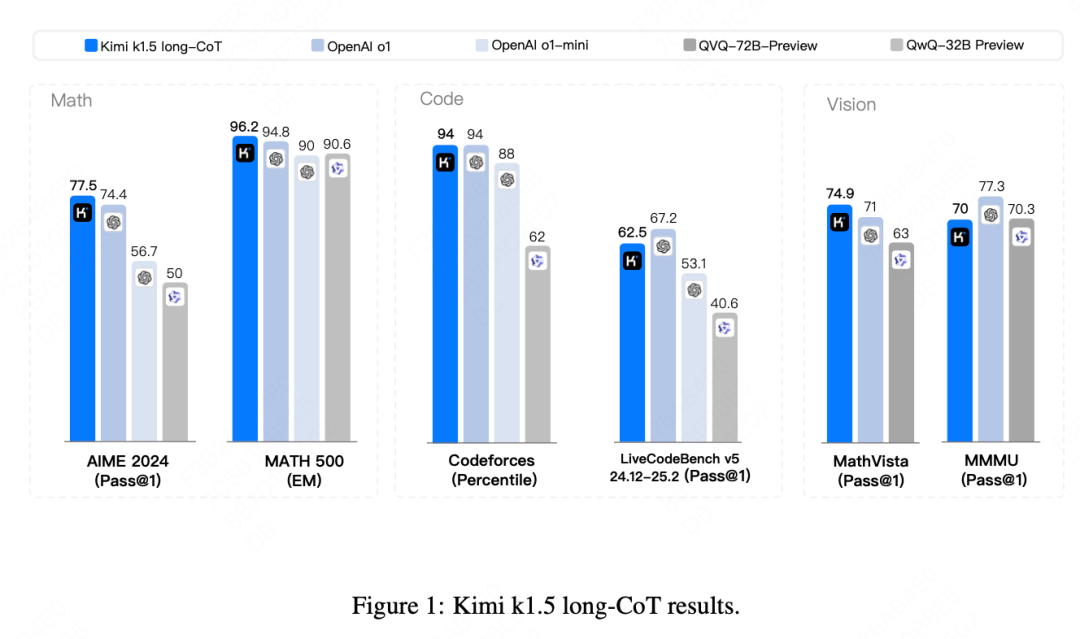
In short reasoning, thanks to a core secret weapon they developed, Kimi 1.5’s sweet capabilities lead the entire leaderboard. In terms of mathematical ability, both GPT-4o and Claude 3.5-Sonnet are far inferior to Kimi 1.5, especially on the AIME leaderboard where Kimi 1.5 scores 60.8, while the highest DeepSeek-V3 only scores 39.2, which is a significant gap. Moreover, Kimi 1.5 is basically at a first-rate level in other scenarios, surpassing current open-source models.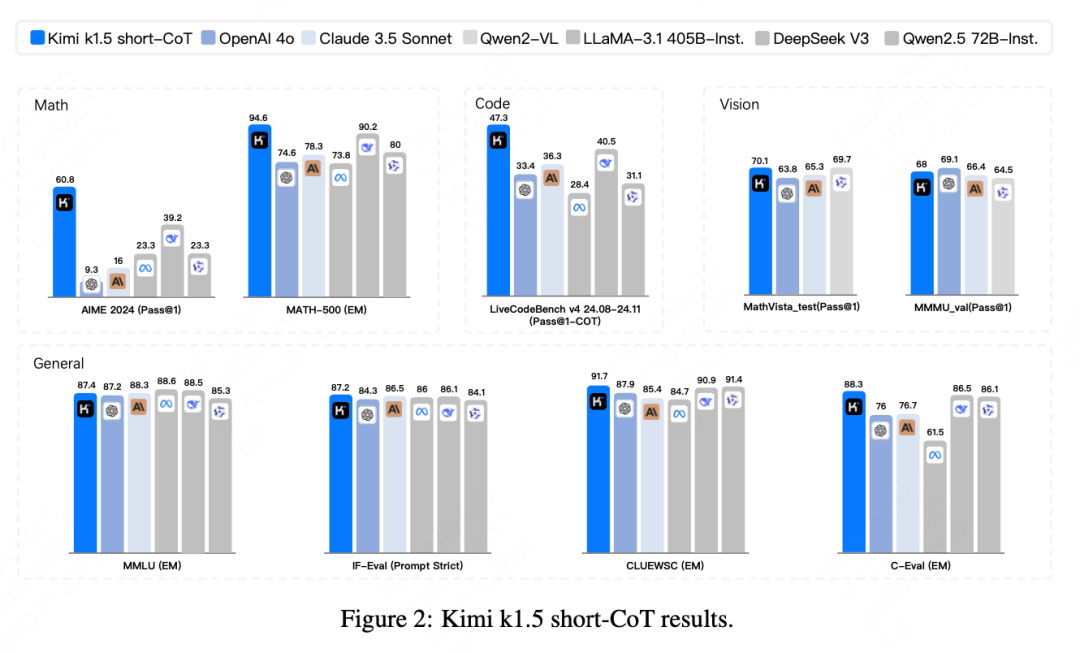
The most important part is the original technical report, which was released less than 24 hours ago. With Kimi’s help, I read it carefully. I couldn’t help but marvel that Kimi has some high-level talents.
Report link: https://github.com/MoonshotAI/Kimi-k1.5/blob/main/Kimi_k1.5.pdfKimi 1.5 summarizes its four major innovations:
1. Long context expansion 2. Improved strategy optimization 3. Simplified framework 4. Multimodal
If you think, is that all? Then you are completely mistaken. Around these four categories, at least 30 very detailed tricks are written, all of which are points that cause great pain and confusion for everyone.
For example, does the O series technology route really need to be so long for COT?
With MCTS and PRM being so prominent, it seems to have determined the technology route of the O series; why can’t I achieve the same results?
And how to implement reinforcement learning infrastructure?
This technical report is written in great detail.
For instance, in the long2short section, the details of the exploration process are basically all written out, including some particularly fine points:
Model merging: Previously, model merging was used to improve the generalization of models. Kimi 1.5 discovered that the long-COT model and the short-COT model can also be merged to improve output efficiency, neutralizing output content without the need for training.
Shortest rejection sampling: For the model output results, perform n sampling (in experiments, n=8), selecting the shortest correct result for model fine-tuning.
DPO: Similar to the shortest rejection sampling, use the long-COT model to generate multiple output results, with the shortest correct output as the positive sample, while longer responses (including incorrect long outputs and correct long outputs that are 1.5 times longer than the selected positive sample) as negative samples, conducting DPO preference learning through the constructed positive and negative samples.
Long2Short reinforcement learning: After the standard reinforcement learning training phase, select a model that achieves the best balance between performance and output efficiency as the base model, and conduct a separate long-COT to short-COT reinforcement learning training phase. In this phase, a length penalty is applied to further penalize outputs that exceed the expected length, while ensuring that the model can still be correct.
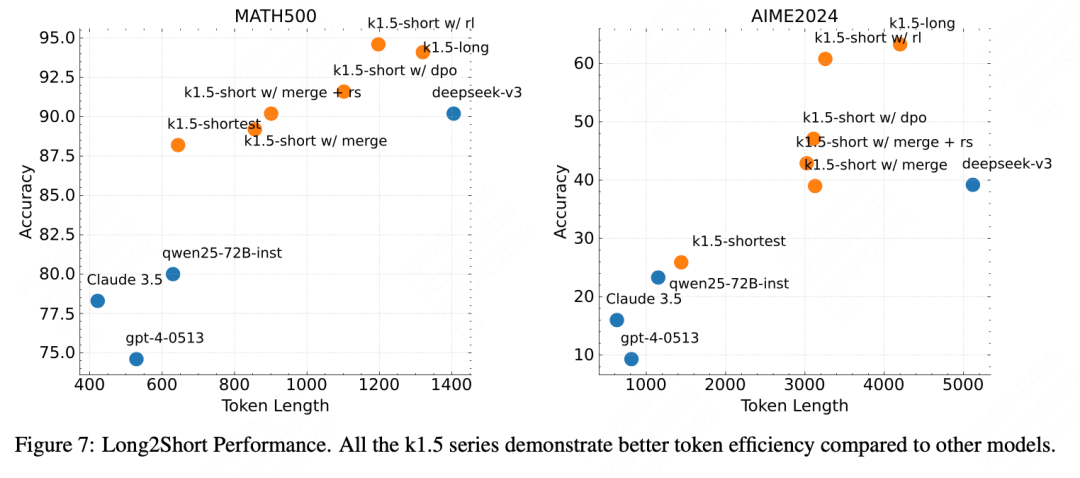
The long2short section has also been proven in experiments to significantly improve reasoning efficiency at minimal cost, achieving an optimal balance between output token length and accuracy.
Do we really need MCTS and PRM?
Kimi 1.5 and DeepSeek’s technical reports both mention this issue, and Kimi has taken a bolder step by further simplifying in PPO, where the value network is also unnecessary. It’s important to know that making technology fancy may make you look impressive, but through practical experimentation, it may not always be genuinely useful. Following Occam’s Razor principle, bringing out models that actually work is the true skill.
In the RL section, Kimi thoroughly explains their reinforcement learning setup and the reasoning process, as well as how to solve the length issue that confuses many, detailing various sampling settings, as well as the mathematical and coding RM modeling details.
In setting up the prompt set, Kimi 1.5 follows three principles:
Diversity Coverage: Prompts should cover a wide range of subjects, such as STEM, coding, and general reasoning, to enhance the model’s adaptability and ensure wide application across different fields.
Balanced Difficulty: Prompts should include a good distribution of easy, medium, and difficult questions to facilitate gradual learning and prevent overfitting to specific complexity levels.
Accurate Evaluability: Prompts should allow evaluators to conduct objective and reliable assessments, ensuring that model performance is measured based on correct reasoning rather than specific patterns or random guessing (this is why it does not rely on MCTS).
In the core RL setup, a variant of online policy gradient descent (simplified PPO) is used as Kimi 1.5’s training algorithm. The algorithm iteratively executes. In the i-th iteration, the current model is used as the reference model, and the following relative entropy regularization policy optimization problem is optimized:
Where τ > 0 is the parameter controlling the degree of regularization. This objective has a closed-form solution:
Here
is the normalization factor. Taking the logarithm of both sides gives the following constraints for any (y, z) that can utilize off-policy data during optimization:
The following loss function can be derived:
To approximate , use samples
The technical report also finds that using the empirical mean of sampled rewards produces effective practical results. This is reasonable because is close to when is expected rewards under . Finally, by optimizing the above loss function, this RL algorithm is optimized. For each question x, k responses are sampled from the reference policy , and the gradient is given by the following formula:
In fact, in addition to the core RL algorithm setup, the technical report also mentions some headaches in RL, such as reward hacking, length penalty settings, sampling strategies, RM modeling details, and multimodal data fusion, which are worth a look.
Lastly, I must mention the infra section.
Infra has become the hottest and most powerful technical direction in the second half of the year, mainly because there is not much reference experience in this area, and general frameworks do not consider making particularly deep and detailed optimizations for the sake of high reusability. If algorithm optimization is addition, infra optimization is multiplication, with a strong multiplicative effect. Improvements in training efficiency, stability, and experimental efficiency can directly translate into reduced time costs. The results that other algorithm engineers can achieve only by sacrificing sleep can be optimized by infra experts while they sleep soundly. Not to mention that when models scale to a certain extent, only infra can help traditional algorithm engineers run experiments.
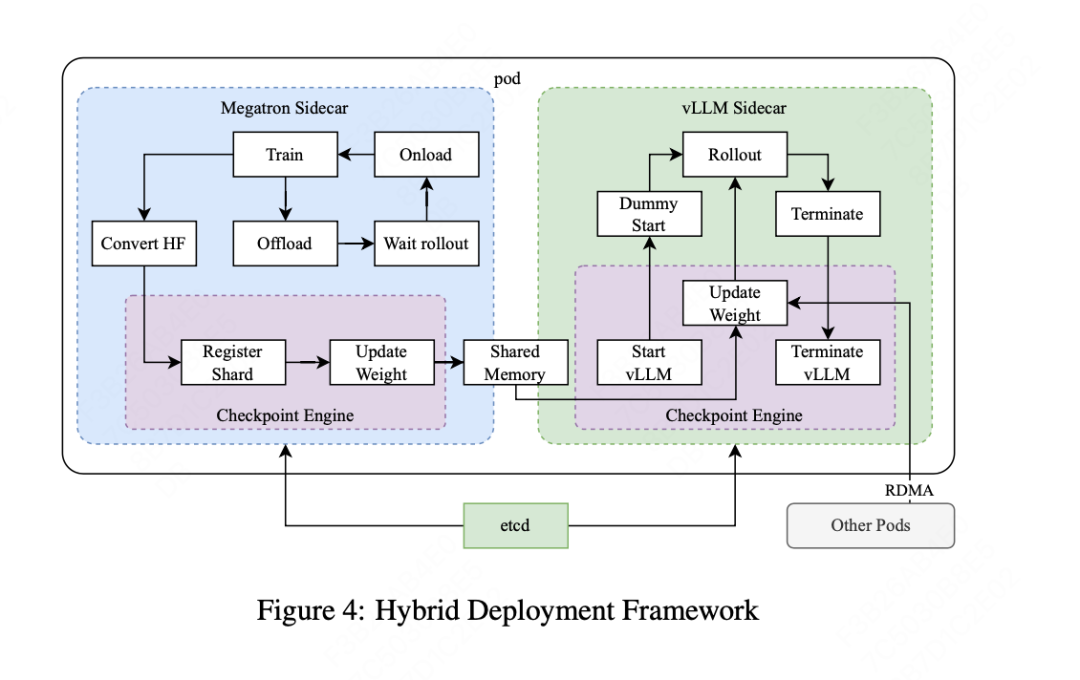
As shown in the figure above, the RL infra operates overall through an iterative synchronous method, where each iteration includes a trajectory generation (rollout) phase and a training phase. In the trajectory generation phase, the trajectory generation work units (rollout workers) coordinated by the central master control unit generate trajectories by interacting with the model, producing response sequences to various inputs. These trajectories are then stored in a replay buffer, which ensures the diversity and unbiasedness of training data by breaking temporal correlations. In the subsequent training phase, the training work units (trainer workers) access these experiences to update the model’s weights. This cyclical process allows the model to continuously learn from its behaviors, adjusting its strategy over time to improve performance.
The central master control unit serves as the command center for the entire system, managing the data flow and communication between trajectory generation work units, training work units, reward model evaluation, and the replay buffer. It ensures the system operates in coordination, balances the load, and facilitates efficient data processing. Training work units access these trajectories, whether from single iterations or distributed across multiple iterations, to compute gradient updates, optimize model parameters, and enhance performance. This process is supervised by the reward model, which evaluates the quality of the model’s outputs and provides feedback to guide the training process. The evaluation by the reward model is crucial for determining the effectiveness of the model’s strategy and guiding it towards optimal performance.
The system also integrates a code execution service, specifically designed to handle code-related issues, which is an important component of the reward model. This service evaluates the model’s outputs in real programming scenarios, ensuring that the model’s learning is closely aligned with real-world programming challenges. By validating the model’s solutions against actual code execution, this feedback loop is vital for refining the model’s strategy and enhancing its performance in code-related tasks.
Specifically, for the mixed deployment of infra construction, several stages are broken down: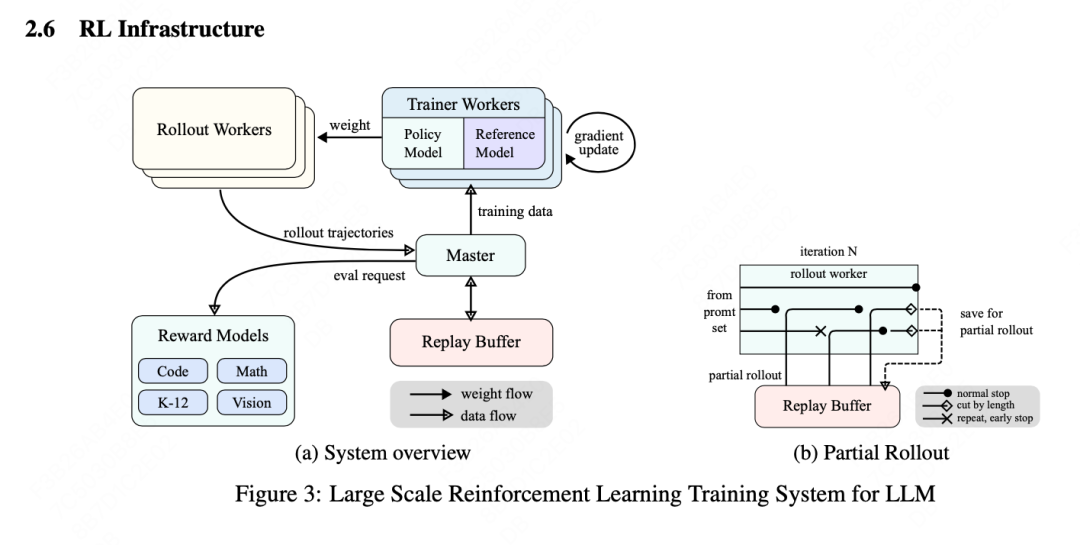
Training Phase: Megatron (Shoeybi et al. 2020) and vLLM (Kwon et al. 2023) run in separate containers, which are encapsulated by a shell process called checkpoint-engine (see section 2.6.3 for details). Megatron starts the training process first. After training is complete, Megatron releases GPU memory and prepares to pass the current weights to vLLM.
Inference Phase: Megatron and vLLM run in separate containers, encapsulated by the shell process of checkpoint-engine. Megatron starts the training process first, and after training is complete, Megatron releases GPU memory and prepares to pass the current weights to vLLM. After Megatron releases memory, vLLM starts with virtual model weights and receives the latest weight updates from Megatron via Mooncake. After the replay is completed, checkpoint-engine stops all vLLM processes.
Subsequent Training Phase: After releasing the memory occupied by vLLM, Megatron reloads the memory and begins the next round of training.
Existing frameworks find it challenging to meet all the following characteristics simultaneously:
Complex Parallel Strategies: Megatron and vLLM may adopt different parallel strategies. It is difficult to share training weights distributed across multiple nodes in Megatron with vLLM.
Minimizing Idle GPU Resources: For online policy reinforcement learning, SGLang and vLLM may retain some GPUs during training, leading to idle training GPUs. How to share the same devices makes training more efficient.
Dynamic Scalability: By increasing the number of inference nodes while keeping the training process unchanged, training can be significantly accelerated. How to efficiently utilize idle GPU nodes.
Finally, Kimi 1.5 is now also undergoing a gray release. You can check your Kimi interface to see if it is available; if so, you can experience the overall effect of Kimi 1.5 in advance.
This technical report was read with the assistance of Kimi.