


In the past two years, multi-task learning has been gradually replacing traditional single-task learning and becoming a mainstream research direction in the field of artificial intelligence. The reason is that multi-task learning allows us to gain as much AI capability as possible with minimal human input. For example, ChatGPT is a natural language generation model based on multi-task learning. Through massive data training and model fine-tuning for specific tasks, ChatGPT can achieve high performance and broad generalizability.
This shift from single-task to multi-task is particularly evident in the field of computer vision. Under traditional computer vision algorithm frameworks, we often need to create different models for different tasks. For instance, face recognition requires specific algorithms, cat face recognition requires another set of algorithms, and flower identification requires yet another algorithm. This not only leads to low overall training efficiency but also greatly limits the scalability of the algorithms.
To address this issue, in addition to the typical solution provided by ChatGPT, Microsoft has introduced a new foundational computer vision model called Florence. Florence is a typical multi-task learning computer vision model capable of performing various types of visual tasks, including image classification, object detection, visual question answering, and video analysis, often outperforming traditional single-task learning models in each sub-task. At the same time, the scaling law also applies to the Florence model; the larger the data scale, the more intelligent the model becomes.
Next, we will focus on interpreting the structure, training methods, capabilities of the Florence model, and its potential impact on the future of AI and computer vision.
01.
Deficiencies of Traditional Single-Task Computer Vision Models
Summarizing the types of computer vision tasks, we can simply categorize them into three dimensions: time, space, and modality.
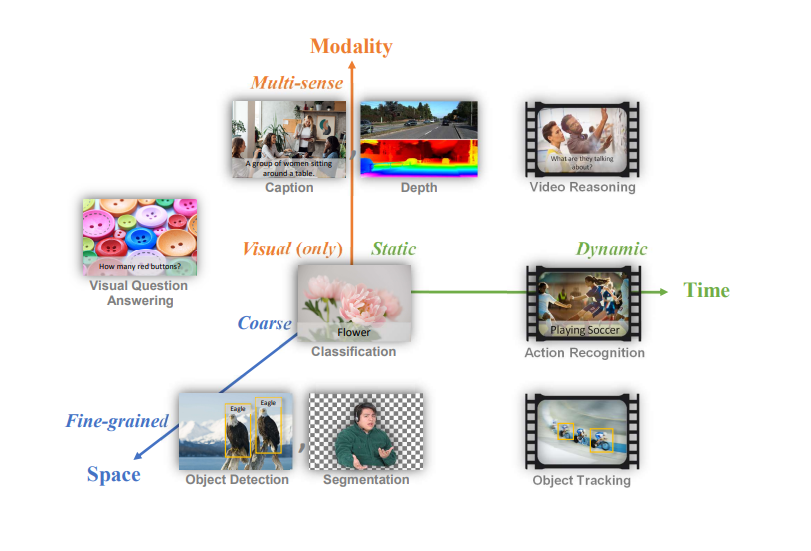
Figure 1: Common Computer Vision Tasks Mapped to Spatiotemporal Modality Space
-
Space: This includes both coarse-grained scene understanding and fine-grained object detection and segmentation. At a coarse-grained level, there are tasks like image classification, which aim to identify the main subject of an image. Fine-grained analysis includes tasks like object detection, which require identifying and locating multiple objects in an image and segmenting tasks that demand precise delineation of object boundaries.
-
Time: Computer vision tasks involve static images and dynamic videos. Static tasks include image classification, object detection, and visual question answering. Dynamic tasks involve analyzing sequences of images that change over time, such as action recognition or object tracking in videos.
-
Modality: Pure visual tasks include image classification and object detection, while multi-modal tasks combine visual data with other types of information, such as text (in image descriptions or visual question answering), depth information, and even audio in some video analysis tasks.
Traditionally, we need to train different models for different tasks, but this single-task learning model has three major issues:
-
Low development and deployment efficiency: Creating and maintaining separate models for each task requires significant resources and time.
-
Difficulties in knowledge transfer: A model optimized for one task often struggles to apply the knowledge learned to other related tasks.
-
Limited ability to handle new situations: When faced with scenarios significantly different from the training data, specialized models may perform poorly.
02.
Introduction to Florence
In contrast to the single-task models mentioned above, Florence aims to develop a universal foundational model that integrates multiple components in its architecture, each addressing different tasks, including image recognition, object detection, visual question answering, and image description, as well as visual understanding. Its most distinctive feature is that the model leverages a combination of visual and language understanding to process and interpret both text and visual data, making it particularly suitable for applications requiring multi-modal capabilities.
Specifically, the versatility of Florence stems from its unified architecture, which has two main components: Florence Pretrained Models and Florence Adaptation Models.
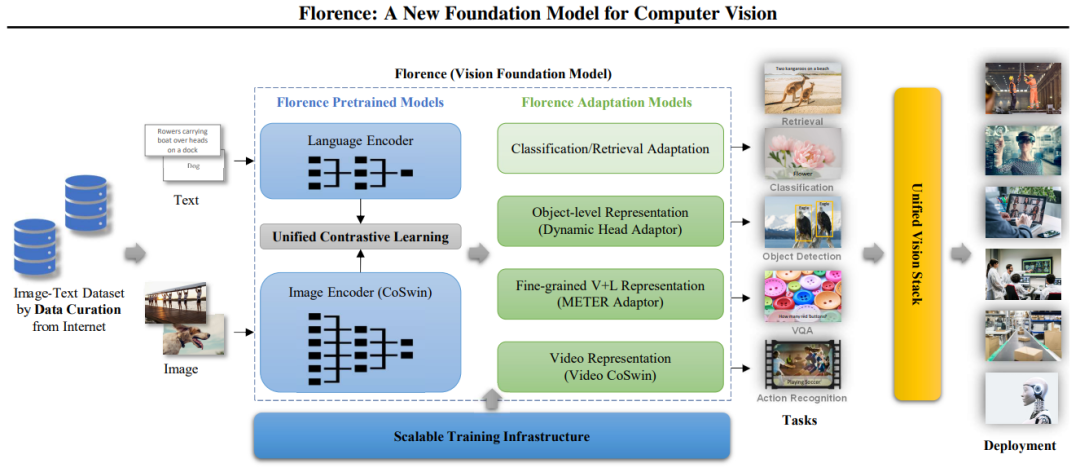
Figure 2: Workflow for Building Florence: From Data Management to Deployment
2.1 Florence Pretrained Models
The Florence pretrained model consists of several key components designed to effectively process and align visual and textual data.
-
Language Encoder: This component processes text inputs, allowing the model to understand and generate language related to visual content. It is similar to models like BERT or GPT but works with visual information.
-
Image Encoder (CoSwin): Based on the CoSwin hierarchical visual transformer, this encoder processes visual information, converting raw pixel data into meaningful representations. It builds upon the architecture of transformers in natural language processing, making it suitable for image processing.
-
Unified Contrastive Learning: This module aligns visual and textual representations, enabling the model to understand the relationships between images and their descriptions, helping the model learn which text corresponds to which images and vice versa.
2.2 Florence Task Adaptation Models
This model is designed to effectively adapt to various types of tasks through few-shot and zero-shot transfer learning and allows for efficient deployment with minimal epochs of training. Specifically, this component supports:
1. Classification/Retrieval Adaptation: This component allows Florence to perform image classification and cross-modal retrieval tasks. For example, it can classify images into predefined categories or find images that match a given text description.
2. Object-Level Representation (Dynamic Head Adapter): This adapter supports fine-grained object detection and segmentation tasks, allowing the model to classify the contents of images and locate and outline specific objects.
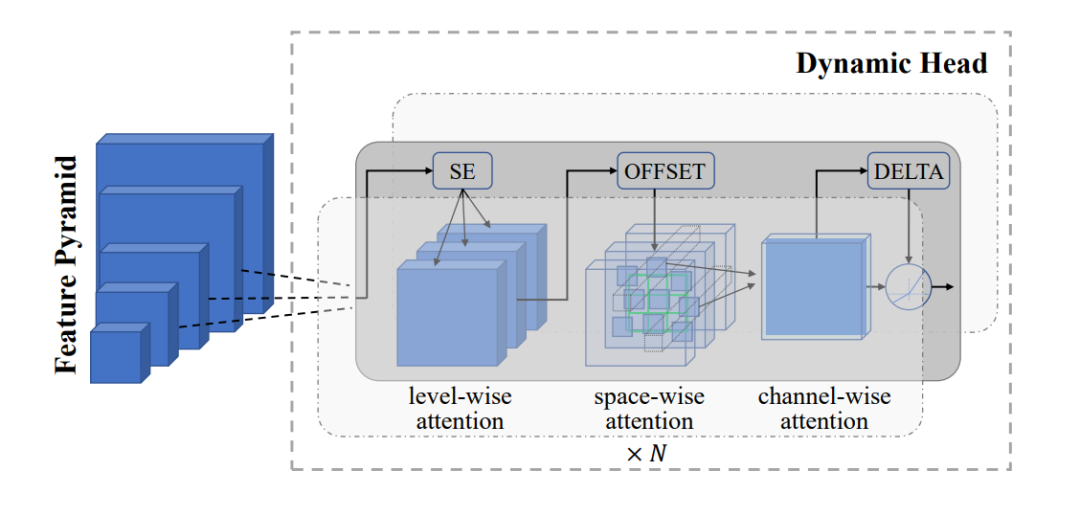
Figure 3: Dynamic Head Adapter for Object-Level Visual Representation Learning
As shown in the figure above, the Dynamic Head Adapter processes visual information through a series of attention mechanisms:
The input is a feature pyramid containing visual information at different scales. For example, in an image of a busy street scene:
-
The largest blocks may represent the overall layout of buildings and roads.
-
The middle blocks may capture individual cars and pedestrians.
-
The smallest blocks can focus on details such as license plates or facial features.
The adapter employs three types of attention:
-
Level-wise Attention (SE): Focuses on important features at different levels of the pyramid. In our street scene, SE might emphasize the car level in a vehicle detection task or the facial feature level in a person identification task.
-
Space-wise Attention: This involves relevant spatial locations within each level represented by a 3D grid. For example, when searching for pedestrians, it might focus on sidewalk areas, while detecting vehicles might focus on road areas.
-
Channel-wise Attention: Highlights important feature channels displayed as the last block. Some channels may be more suitable for detecting shapes, while others may be better for detecting color information.
OFFSET and DELTA components fine-tune spatial boundaries. They help precisely locate target boundaries, such as accurately outlining cars or people in a street scene.
This multi-stage attention process enables the model to detect and segment objects by focusing on the most relevant information at different scales and spatial locations. For instance, it can simultaneously detect large objects like buses, medium objects like cars, and small objects like traffic signs in a street scene.
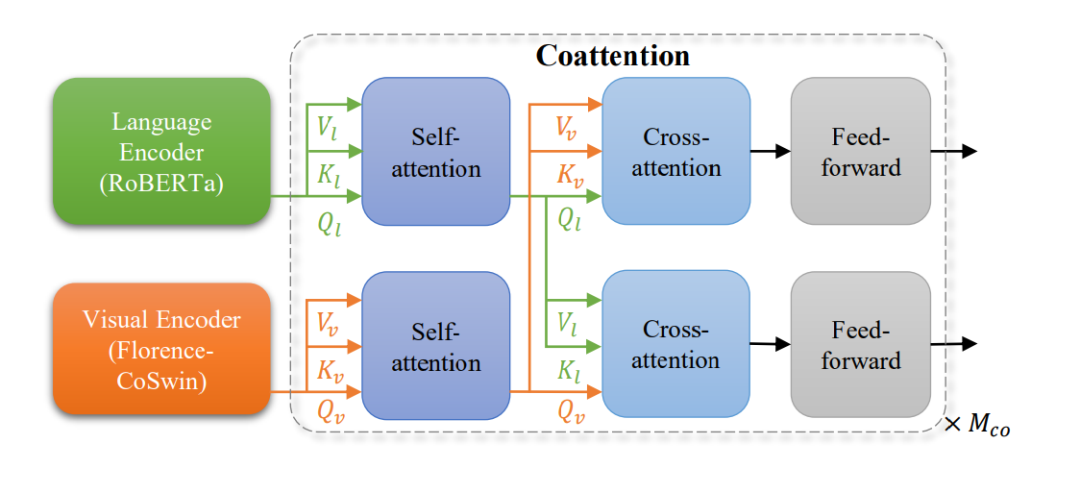
Figure 4: METER Adapter Used as the Florence V+L Adaptation Model
The METER adapter shown in the figure uses a joint attention mechanism to fuse visual and textual information. Let’s see how it works:
-
The language encoder (RoBERTa) processes text inputs. For example, it might handle the question: “What color is the car parked next to the fire hydrant?”
-
The visual encoder (Florence-CoSwin) processes visual inputs, analyzing the street scene image.
-
Both inputs go through separate self-attention layers, allowing each modality to process its information independently. Text self-attention might focus on keywords like color, car, and fire hydrant, while visual self-attention might highlight the areas in the image containing the car and fire hydrant.
-
The outputs of these self-attention layers are then fed into a cross-attention layer, where the visual and textual information combines.
-
Text features attend to relevant parts of the image (Vl, Kl, Ql arrows point downward). For our example, this might link the words car and fire hydrant to their visual representations in the image.
-
Image features relate to relevant parts of the text (Vv, Kv, Qv arrows point upward). This might involve linking the visual features of the car to the word color in the question.
-
Finally, both streams go through feed-forward layers for further processing of this combined information.
-
This process repeats Mco times, allowing for multiple rounds of refinement.
This architecture allows the model to first process text and images separately, then gradually combine the information, enabling it to understand the complex relationships between visual and textual content. For example, in street scene recognition, the model would identify the correct car based on its proximity to the fire hydrant, determine its color, and form an answer such as: “The car parked next to the fire hydrant is blue.”
This unified structure enables Florence to handle a range of tasks such as image classification and video recognition with just one foundational model and specific task adapters.
03.
Florence’s Capabilities: