Generative AI is a type of artificial intelligence technology that utilizes machine learning models and deep learning techniques to generate new content by studying patterns in historical data. This content can be text, images, audio, or video. Unlike traditional systems that generate output based on given rules or data, generative AI autonomously creates entirely new content, similar to human creativity (Figure 1). For example, the widely discussed chatbot ChatGPT uses the core model GPT-3, which can generate high-quality natural language text for applications in chatting, writing, and automated customer service.
By Mengfei
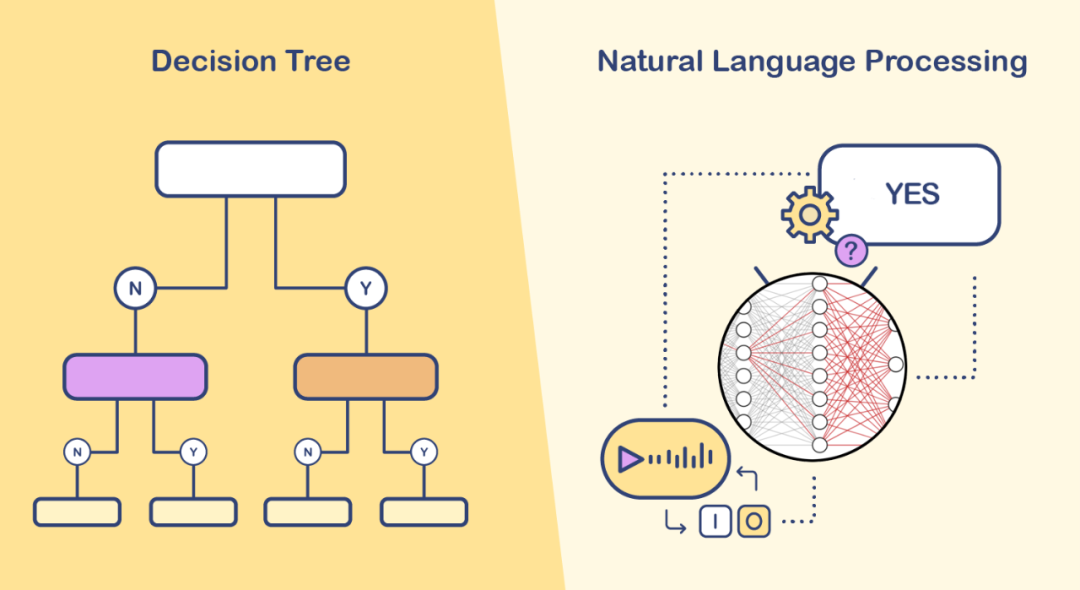
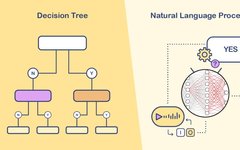
Figure 1: Rule-based chatbots typically use “if-else” statements or similar techniques to match preset questions and answers, while chatbots like ChatGPT generate natural responses in real-time through pre-trained large language models.
History of Generative AI Development
As big data and computing power continue to grow, people have begun to expect computers to create content and generate innovative ideas like humans. This has led to the rise of generative AI technology, which enables computers to mimic human creativity and brings us more innovation and development.
The history of generative AI dates back to the 1950s and 60s when researchers began using probability theory and information theory to establish language models. These models could transform input text data into probability distributions and then generate new text based on those distributions (Figure 2).
Figure 2: Research on language models began even before the advent of artificial intelligence. For example, the Markov chain proposed by Markov in 1906 can be applied in various fields and can be considered a simple language model.
In the 1990s, with the development of neural network technology, generative AI entered a new phase. Neural networks can automatically learn the underlying structure and patterns of text data through training and can use these patterns to generate new text. One well-known generative model is the Recurrent Neural Network (RNN)-based language model, which can predict the next word in a sentence and use it as input to predict subsequent words, thereby generating coherent text.
In recent years, with further advancements in deep learning technology, generative AI has made significant progress. Notable models have emerged, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), Diffusion Models, and Transformer models. These models can generate high-quality images, videos, audio, and natural language text, having a tremendous impact across many application domains such as natural language processing, computer vision, and audio processing.
Workflow of Generative AI
The basic principle of generative AI is to use probabilistic models or neural network models to learn the structure and patterns of existing data and generate new data based on these structures and patterns.
1. Model Training
First, a generative AI model needs to be trained using a large amount of training data. During the training process, the generative AI model learns the probability distribution and structure of the input data, which can be text, images, audio, or video.
2. Model Selection
After training, an appropriate model needs to be selected to generate new data. Different types of data require different models for generation. For example, natural language text can be generated using RNN or LSTM models, while images can be generated using GANs, VAEs, or diffusion models (Figure 3).
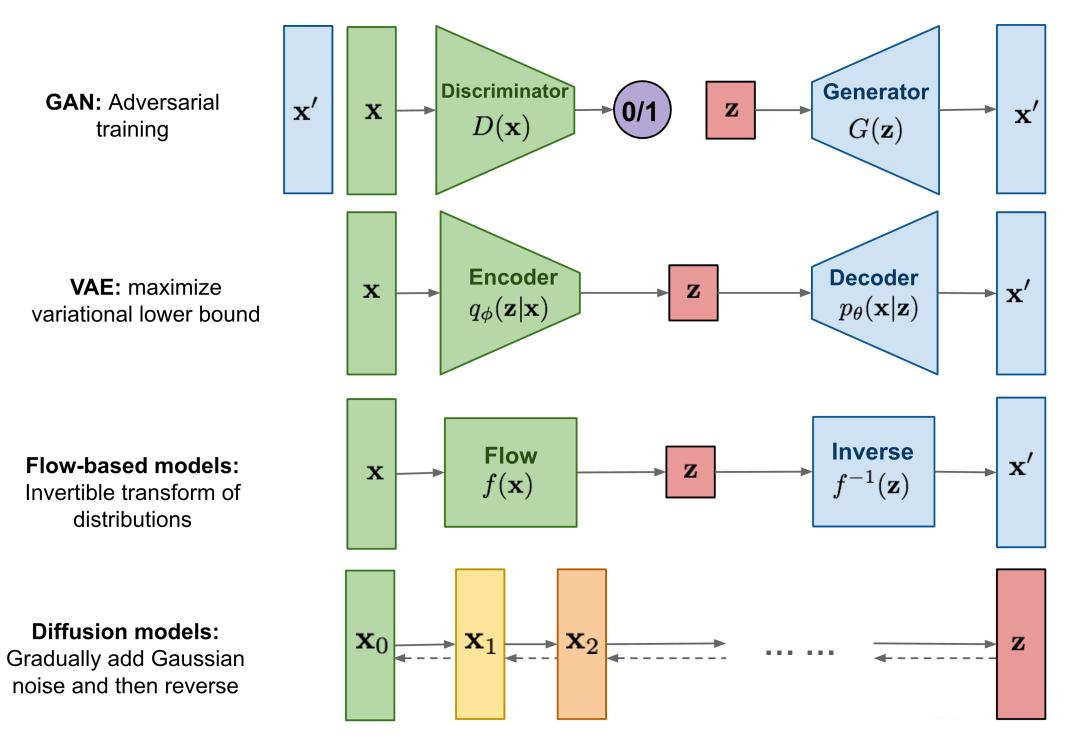
Figure 3: Comparison of different types of generative models.
3. Data Generation
Once the appropriate model is selected, it can be used to generate new data. The generation of new data usually occurs through random sampling or conditional sampling. Random sampling refers to generating new data by randomly sampling from the probability distribution learned by the model, while conditional sampling refers to generating new data by sampling from the learned conditional distribution under specific input conditions.
4. Evaluation of Generated Results
The newly generated data needs to be evaluated to determine if it meets expectations. Evaluating the quality of generated results is an open question and can be based on objective metrics or rely on human subjective feelings. For example, natural language text can be evaluated based on grammatical correctness, coherence, and meaningfulness, while images can be assessed based on visual quality and realism.
5. Model Adjustment
Based on the evaluation of the generated results, the model can be adjusted and optimized to improve the quality of the generated results. Methods for adjusting the model typically include increasing training data, adjusting model parameters, and optimizing model structures.
Overall, the workflow of generative AI is an iterative process that requires continuous model adjustments and evaluations of generated results to achieve better generation outcomes. This is from the generative perspective; if viewed from the client’s operational perspective, the process is much simpler (Figure 4).
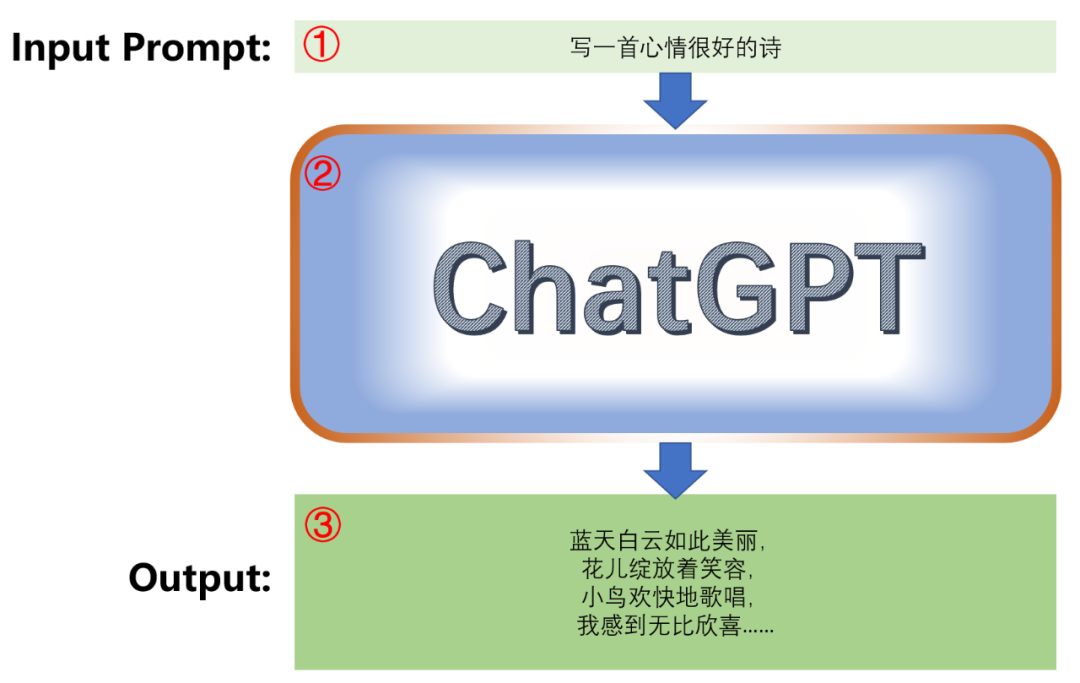
Step 1: The user inputs condition settings, such as keywords, themes, or contextual information for the desired content. This is popularly referred to as a prompt.
Step 2: Wait for the server-side model to process.
Step 3: Retrieve the generated content returned by the server-side model.
Figure 4: The user’s input is processed by the trained language model, ultimately outputting entirely new text.
Generative Adversarial Networks (GAN)
Having gained a preliminary understanding of generative AI, we will now introduce several key technologies in its development process. First is Generative Adversarial Networks (GANs), a deep learning model proposed by Ian Goodfellow and others at the University of Montreal in 2014. In the following years, GAN models rapidly developed and became mainstream in AI art generation. In 2018, NVIDIA released StyleGAN based on GAN models, allowing users to create beautiful landscapes and portraits simply by scribbling a few strokes, attracting significant attention. In 2019, a website called “This Person Does Not Exist” took AI art to a new height, automatically generating indistinguishable human-face images with each refresh, stunning users with its realism and having a massive impact on the field of image generation.
Today, many interesting applications of GAN can be found online. For example, GANpaint allows users to see multiple beautiful images generated by AI (Figure 5, http://gandissect.res.ibm.com/ganpaint.html).
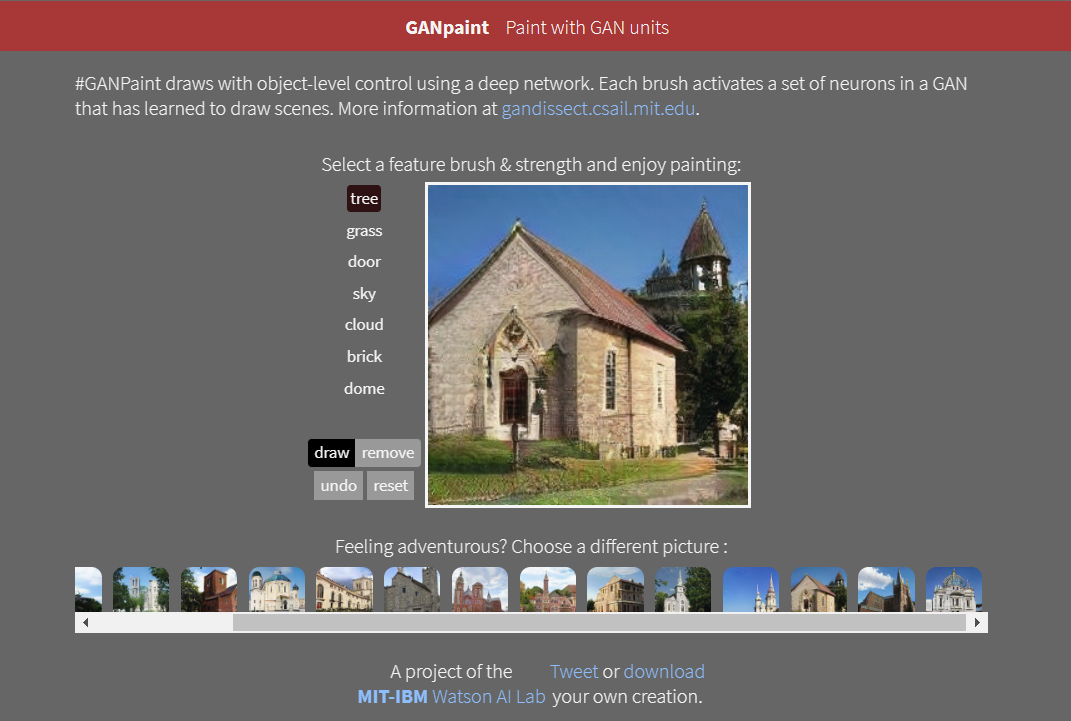
Figure 5: GANpaint, an AI painting tool based on GAN models.
The left side of the image provides painting elements such as tree, grass, door, sky, cloud, brick, and dome, each corresponding to a set of 20 neurons. Below are operation modes like draw and remove. By selecting a painting element, setting it to draw mode, and freely scribbling on the canvas, users can add that element to the current scene. There is no need to worry about “ruining” the painting, as it will intelligently compute and ensure the integrity of the canvas. Conversely, if the remove mode is set, it will eliminate relevant elements from the scene. The implementation principles of this tool are detailed at https://gandissect.csail.mit.edu.
GAN consists of two neural networks: the generator and the discriminator. The generator is responsible for generating fake data that resembles real data (such as real human photos), while the discriminator distinguishes between real and fake data. These two neural networks are trained through a game-like process, where the generator attempts to deceive the discriminator, and the discriminator strives to differentiate between real and fake data. During training, the generator gradually learns to produce more realistic fake data, while the discriminator learns to better distinguish between real and fake data. When the fake data generated by the generator can “fool” the discriminator, it indicates that the generator has learned to produce data similar to real data (Figure 6).
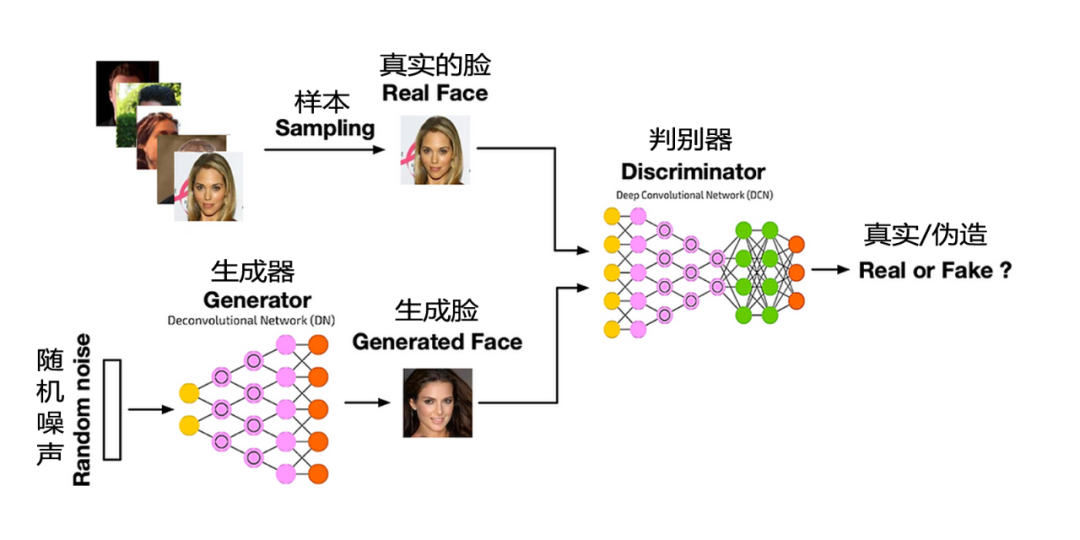
Figure 6: The generator and discriminator in a GAN engage in a game-like process.
As illustrated, the workflow of the GAN generator is roughly as follows:
1. Random noise input: The generator takes a random noise vector as input, typically a high-dimensional vector based on some probability distribution.
2. Generating images through neural networks: The generator uses deep neural networks to map the noise vector to the generated image space and outputs the generated image. This process can be viewed as converting an abstract high-dimensional noise vector into a concrete image representation.
3. Evaluating the generated image: The generated image is assessed by the discriminator.
4. Optimizing the generator: If the image produced by the generator is deemed real by the discriminator, the generator is considered to have produced a high-quality image. The goal of the generator is to iteratively improve its generated images to better match the real data distribution.
5. End of training: Through constant training iterations, the generator gradually enhances its generation capability, ultimately producing high-quality images.
The GAN discriminator is a binary classifier whose goal is to separate the data generated by the generator from real data, evaluating whether the generated image resembles real data. Its workflow is as follows:
1. Receiving input data: The discriminator inputs images generated by the generator or real data into the neural network.
2. Feature extraction: The discriminator maps the input data to a set of feature vectors through a series of convolutional layers, pooling layers, and activation functions.
3. Binary classification: The discriminator uses a Sigmoid function (an activation function) to map the feature vector to a value between 0 and 1, indicating the probability that the input data belongs to the real data. If the discriminator judges that the input data belongs to real data, it outputs a probability value close to 1; if it judges that the input data belongs to data generated by the generator, it outputs a probability value close to 0.
4. Optimizing the discriminator: The discriminator continuously trains and iterates to optimize its distinguishing ability, allowing it to more accurately separate images generated by the generator from real data, thereby driving the generator’s generation capability to improve.
GANs are not only used in image generation but can also handle other types of data (such as text), demonstrating outstanding performance in various fields including natural language processing, finance, medicine, and game development. Of course, the artistic expression of GANs is perhaps the most famous. In 2018, the French art collective Obvious used a GAN named Eerie AI to create the portrait “Edmond de Belamy” (Figure 7), a virtual portrait that does not exist, which was successfully auctioned for over $400,000, sparking widespread discussion in society. The series of portrait works created alongside “Edmond de Belamy” consists of 11 pieces, known as the “Belamy Family” (Figure 8).

Figure 7: The portrait “Edmond de Belamy” created using GAN, trained on 15,000 portrait artworks from the 14th to 20th centuries.
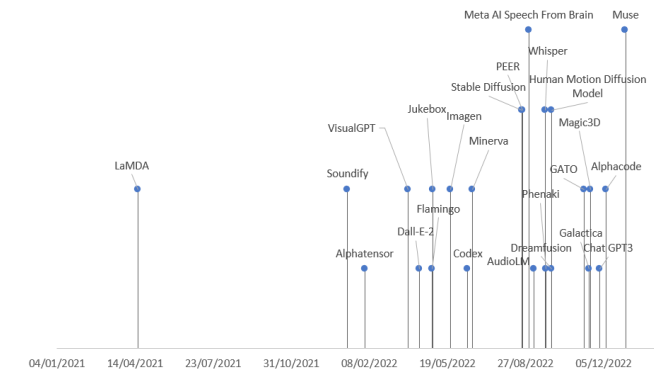
Figure 8: The “Belamy Family” series of portraits.
Diffusion Models
Before GANs, the effects of AI painting were primarily abstract, garnering little attention. The emergence of GANs brought realistic painting effects that amazed many, but even then, AI painting remained popular only in niche circles. It wasn’t until the arrival of OpenAI’s DALL-E in 2021 and the subsequent release of its upgraded version DALL-E 2 that AI painting truly entered the public eye, becoming a sensation online. This is partly because DALL-E 2’s painting effects can rival those of professional artists, and partly because its user interface is incredibly simple: users only need to input natural language text describing the painting content to receive corresponding exquisite artworks. The OpenAI blog provides vivid examples, such as entering the text prompt: “an illustration of baby daikon radish in a tutu walking a dog,” which yields a series of creative illustrations (Figure 9).

Figure 9: Combining elements such as a baby daikon radish, a dog, and a tutu to create a surreal illustration.
After DALL-E, similar large AI painting models have surged, such as Stable Diffusion and Midjourney. Here, we can experience the charm of Stable Diffusion online. First, open the webpage https://replicate.com/stability-ai/stable-diffusion, then input a painting prompt in the Prompt box, such as “山外青山楼外楼,国画”. However, since international AI models have limited support for Chinese, we can translate the prompt into English: “Hill outside Castle peak building outside building, traditional Chinese painting,” and submit it to receive a decent artwork (Figure 10).
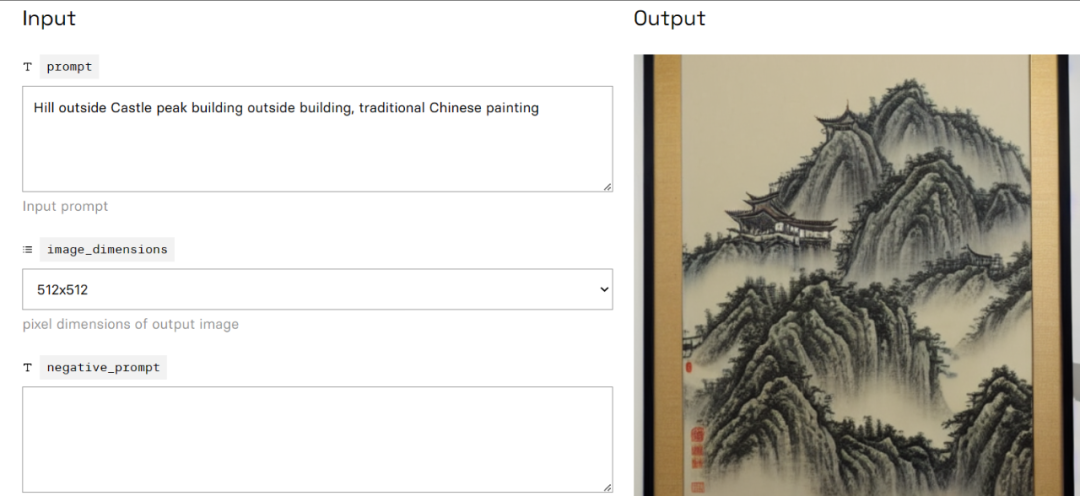
Figure 10: A painting corresponding to the classical Chinese poem “山外青山楼外楼”.
We can also try another website (https://huggingface.co/spaces/stabilityai/stable-diffusion), which is also based on Stable Diffusion. By inputting the same prompt, we can get four sample artworks that look quite impressive (Figure 11).

Figure 11: AI painting in the style of traditional Chinese art.
The aforementioned DALL-E/DALL-E 2, Stable Diffusion, Midjourney, and Disco Diffusion share a commonality: they are all based on Diffusion Models. The idea behind diffusion models originates from non-equilibrium thermodynamics, defining a Markov diffusion step chain that gradually adds random noise to data, then learns to reverse the diffusion process to construct the desired data samples from the noise (Figure 12).

Figure 12: The Markov chain of forward (adding) and reverse (removing) diffusion processes generating samples (DDPM, Ho et al. 2020).
Diffusion models have several variants, with well-known ones including Denoising Diffusion Probabilistic Models (DDPM), Diffusion Probabilistic Models (DPM), and Noise-Conditioned Score Networks (NCSN). All of these are based on a continuous diffusion process to generate samples, but they differ in sampling methods, noise parameter adjustments, and denoising processes. Each model has its limitations and assumptions, which may affect their performance on certain tasks.
Currently, diffusion models are dominating AI painting applications, far surpassing GANs. However, both models have their pros and cons in the field of image generation. Diffusion models are slower and require more iterations but can produce higher quality and more realistic visual effects. GANs are faster and more efficient but tend to yield lower image quality.
Text to Image Technology
Recently, the wave of AI painting has been significantly propelled by text-to-image technology. Previously, even the most advanced AI painting tools required users to manually operate the brush (even if it was just drawing a few rudimentary shapes). However, since DALL-E, ordinary users can simply input text descriptions, and the AI will automatically create paintings, making it remarkably convenient and allowing AI painting to gain widespread popularity.
Any user-friendly feature is backed by a significant amount of work and complex technology, and text-to-image is no exception. For instance, to recognize the images corresponding to user-inputted text, OpenAI applied a pre-trained model called CLIP (Contrastive Language–Image Pre-training) in addition to the image generation function (Figure 13).
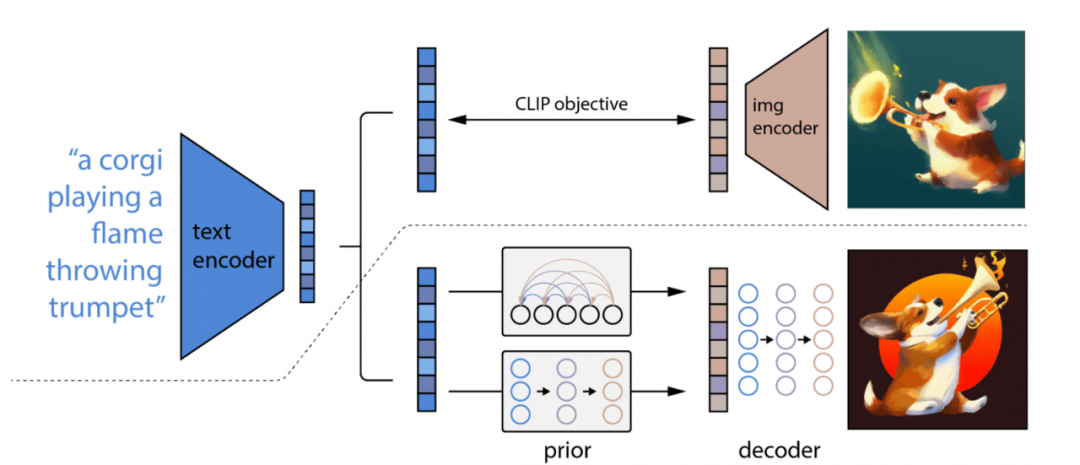
Figure 13: Above the dashed line is the training process of the CLIP model, establishing a joint representation space for text and images. Below the dashed line is the text-to-image generation process, adjusting the diffusion decoder that produces the final image through CLIP text embeddings. Note: The CLIP model is frozen during the training process of image generation (Ramesh et al. 2022).
No technology is developed overnight, and text-to-image technology is also the result of years of development. It has undergone the following processes:
In the late 1990s, some early text generation models, such as n-gram models and Recurrent Neural Networks (RNNs), began to be applied in natural language processing, but these models could not directly generate images.
In 2005, Hinton and others proposed the Deep Belief Network (DBN) model, which could learn the complex relationships between input text and images, thus achieving text-to-image conversion.
In 2014, Reed and others proposed a text-to-image generation method based on GANs, which was the first to apply GANs to the image generation field and achieved some degree of text-to-image conversion.
In 2015, a conditional GAN-based text-to-image generation method emerged, which could generate images that matched the input text description and exhibited better generation quality and diversity.
In 2016, Reed and others proposed a text-to-image generation method based on Convolutional Neural Networks (CNNs) and RNNs, capable of generating high-resolution realistic images.
In 2018, Google introduced a text-to-image generation method based on Transformer models, which could generate high-quality images from input text, achieving good results across multiple tasks.
In recent years, with continuous advancements and optimizations in deep learning technology, text-to-image generation methods based on GANs, VAEs, Transformers, and others have been continuously improved and expanded, achieving higher generation quality and diversity, and being widely applied in e-commerce, advertising, and artistic creation.
Future Development Trends of Generative AI
Generative AI is a highly complex technology that involves multiple fields such as deep learning, natural language processing, computer vision, reinforcement learning, and probability theory. Therefore, it faces many challenges and limitations. Below are the main challenges faced by generative AI and future development trends.
1. Data Quality Issues
Generative AI requires a large amount of high-quality data for training, but real-world data often contains noise, biases, and errors, posing many challenges for generative AI. To address this issue, future efforts need to focus on developing and improving data cleaning and preprocessing technologies to enhance data quality and usability.
2. Computational Resource Limitations
Generative AI requires substantial computational resources for training and inference, which presents challenges in practical applications. To tackle this, future advancements need to focus on developing efficient computing and algorithm optimization technologies to improve the efficiency and performance of generative AI.
3. Explainability Issues
The black-box nature of generative AI makes it difficult to understand and explain their working principles, limiting their usability and reliability in practical applications. To solve this, future efforts should focus on developing explainable generative AI technologies to enhance their transparency and comprehensibility.
4. Multi-modal and Cross-modal Generation Issues
Future generative AI needs to further develop multi-modal and cross-modal generation technologies to support the generation of various data types, including text, images, audio, and video.
5. Legal and Ethical Issues
Generative AI may present issues related to copyright, privacy, and ethics, necessitating enhanced legal and ethical considerations and constraints when applying generative AI to ensure its legal and ethical use.
In summary, generative AI remains a rapidly evolving and innovating field, facing many challenges and opportunities. Through continuous research and development, we can expect generative AI to be applied in more fields, bringing greater value and change to humanity. Additionally, generative AI encompasses a wide range of fields and rich content, and a short article is insufficient to cover its entirety. Finally, we present several comprehensive classification diagrams of generative AI, hoping to provide some reference for those who wish to delve deeper into the subject.
CF
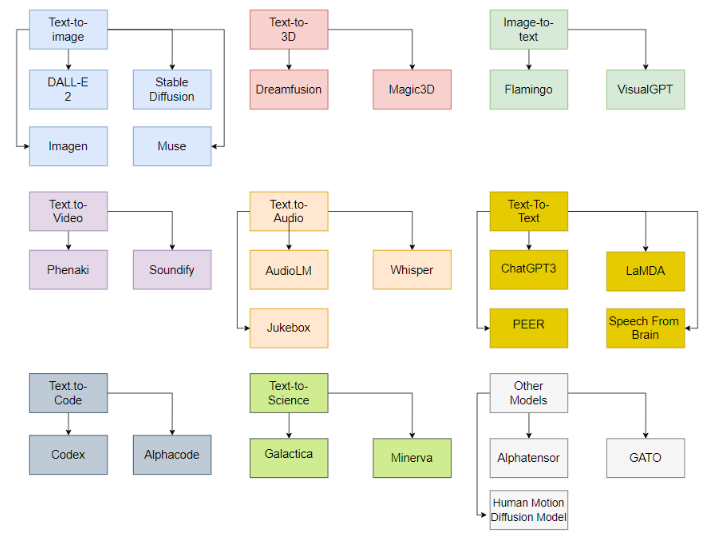
Figure 14: Classification of generative AI models based on input and generation format (source: arXiv:2301.04655v1).
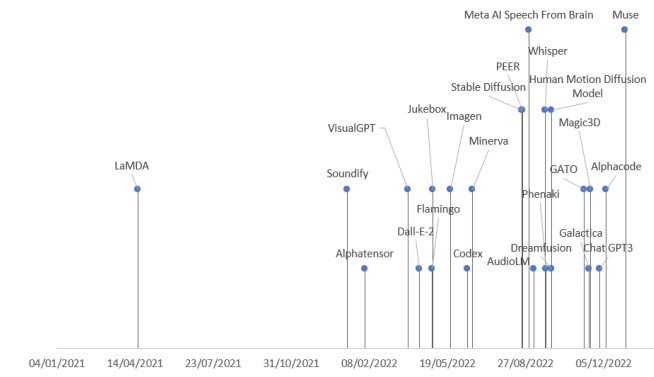
Figure 15: Timeline of representative products of generative AI, with the exception of LaMDA released in 2021 and Muse released in 2023, all others were launched in 2022 (source: arXiv:2301.04655v1).
Originally published in Computer Enthusiast, Issue 24, December 15, 2022.
END
For more exciting content, please stay tuned…
