
The ‘Ears’ of Artificial Intelligence – Speech Recognition
By Wang Xuan
Speech Recognition
Speech recognition is an important component of future artificial intelligence. Imagine if computers couldn’t even “understand” speech; how could they be considered intelligent? In recent years, several major companies have been continuously acquiring firms—Apple acquired Siri, Facebook acquired Wit.ai, and China Mobile invested in iFlytek, pushing speech recognition to the forefront of public discourse. In addition, major companies are also continuously launching their own voice assistants: Microsoft introduced Cortana, Google released the chat application Allo, Baidu launched Baidu Voice, and countless startups have launched their own voice assistants based on speech recognition technology.
The purpose of speech recognition is to enable computers to understand what humans say. To achieve this, several steps are usually required—preprocessing, feature extraction, feature matching, and language model training. Let’s explore each step.
Preprocessing
We know that speech exists in the form of sound waves. Preprocessing first requires filtering out noise signals from the audio, then detecting the start and end of the speech signal, and finally segmenting the speech into frames. Here, let’s emphasize segmentation. We all know that video is formed by rapidly playing a series of images, such as when we watch a movie; we are actually seeing 24 images per second. In contrast, audio signals are continuous, so they need to be artificially divided into smaller segments for subsequent processing, such as every 10 milliseconds (1,000 milliseconds = 1 second), meaning a 5-second sentence will be divided into 500 segments.
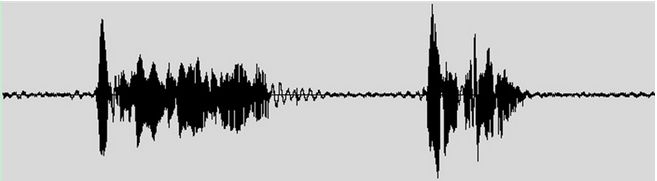
▲Figure 1: Waveform of Speech Signal
Feature Extraction
Feature extraction is the process by which a computer derives the essential information from each small segment of the speech spectrum using algorithms. The feature extraction algorithm must calculate the key data of the spectrum and also exhibit strong stability to resist external interference. After extraction, multiple small segment spectra corresponding to one word will be described in vector form. For example, if the computer hears the user say “weather,” it will represent this word as a vector like “(13, 4, 10), (40, 17, 5)”; of course, the actual number of required digits will be much larger.
Feature Matching
During system construction, a feature database is established, which can be visualized as describing the pronunciation of each word with several vectors. The vector generation method is the same as that used in feature extraction. The speech signal to be recognized is compared with the database. Even the same person reading the same word twice will show variations, so the recognition result is a probability value. Continuing from the previous example, the database can be thought of as a dictionary that stores the numerical descriptions of all words, such as “weather – (12, 4, 10), (40, 16, 5)”; “sweet – (9, 4, 10), (25, 17, 8)”; and “morning – (45, 76, 22), (7, 45, 1)”. The computer looks up the dictionary and compares the differences between each group of numbers, ultimately concluding that the probability of hearing the word “weather” is 90%, “sweet” is 53%, and “morning” is 0.1%. Usually, the one with the highest probability is considered the recognition result.
Language Model Training
The main purpose of language model training is to teach the computer grammar and semantics, which are used to narrow down the options during feature matching. Currently, most speech recognition is based on the assumption that the user’s description aligns with normal speaking habits, so the model defines which words can follow the previously recognized word. For example, if three separate words are recognized, the result might be “chocolate,” “fly,” and “gemstone,” but when they are part of a sentence, the computer automatically corrects the result to “chocolate is very delicious.”
From an effectiveness perspective, speech recognition has gone through three stages: independent word recognition (which is independent word recognition for English), phrase recognition, and context-based semantic recognition.
Independent word recognition refers to the ability of the computer to accurately identify the pronunciation when the user says “fu” and organize the possible corresponding Chinese characters, such as “付,” “复,” “负,” “富,” etc.
Phrase recognition means that when the user says “bao fu,” the computer can eliminate unreasonable combinations like “爆付” or “鲍复” and recognize that the user is likely referring to “报复,” “抱负,” or “暴富.”
Contextual speech recognition occurs when the computer, upon hearing “bao fu,” relates to the entire sentence spoken by the user or even previous content to infer which word the user specifically meant. If the context mentioned hatred, the recognition result would be “报复”; if the context mentioned money, the most likely result would be “暴富.”
Apple’s acquisition history aligns perfectly with these three stages. In 2010, Apple acquired Siri and released the Siri voice assistant on the iPhone 4S, but the user experience at that time was poor. Then, in 2013, Apple acquired Novauris, a company with excellent phrase recognition technology. Finally, in 2015, Apple acquired VocallQ, which is particularly good at processing complex commands and can infer what users want to express based on context.
Speech recognition is classified into specific speaker recognition and non-specific speaker recognition based on the requirements of the speaker.
Specific speaker recognition refers to a speech recognition system designed to recognize the voice of a specific user. In this case, the audio samples in the database come from the user themselves, so the language habits, speed, and tone of speech in the database are consistent with the user, significantly improving recognition accuracy. The downside is that the system can only be used by that individual, and the recognition performance decreases significantly when recognizing others’ voices. Additionally, the system needs the user’s voice samples to improve the database.
Non-specific speaker recognition uses a universal system available to all users, which lowers the user threshold and enhances system promotion. However, the downside is that the recognition accuracy is not as high as that of specific speaker recognition systems, which is understandable since dedicated systems are generally better than generic ones. Currently, most speech recognition systems are non-specific speaker recognition systems.
Speech recognition can also be classified based on the speaking style into isolated word recognition and continuous speech recognition.
Isolated word recognition means that the speaker only says one word at a time, and the system can only recognize one word at a time. This has the advantage that when a person says only one word, the pronunciation can be clearer and less affected by context. Moreover, the computational load required for isolated word recognition is lower, and the matching templates are clear, which means isolated word recognition can achieve a high recognition rate. Typically, command word recognition is based on isolated word recognition; for example, a user of Google Glass can issue the command “ok glass” and the system will interpret the following spoken words as commands for the glasses, such as when the user says “take a picture,” the glasses will automatically take a photo using the front camera.

▲Figure 2: Google Glass Smart Glasses
Continuous speech recognition means that the user speaks at a normal speed and in a conversational manner, and the system recognizes what the user wants to express. This recognition method requires the system to have strong computational capabilities, and the accuracy of recognition is not as high as that of isolated word recognition. However, because continuous speech recognition aligns with normal speaking habits, it is bound to be the development direction of the future, and good algorithms can already improve the recognition of each word through contextual associations.
Currently, many companies have launched voice assistants based on speech recognition technology to assist in operating electronic devices or act as secretaries for reminders. Here are a few examples; interested readers can try them out themselves.
Cortana on Windows 10 is a relatively mature voice assistant, allowing users to issue commands to the computer with a wide range of functionalities.
Set Calendar Reminders
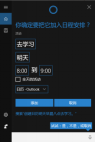 Cortana can automatically set calendar reminders based on spoken content. For instance, if the user says, “Create a calendar event for studying tomorrow morning at eight,” Cortana can identify the key points: the date is tomorrow, the time is eight, and the content is studying, while asking the user if they want to add this information to the schedule. If the user replies “yes,” the system records the information, and if there is an error, the user can say “no” to modify it.
Cortana can automatically set calendar reminders based on spoken content. For instance, if the user says, “Create a calendar event for studying tomorrow morning at eight,” Cortana can identify the key points: the date is tomorrow, the time is eight, and the content is studying, while asking the user if they want to add this information to the schedule. If the user replies “yes,” the system records the information, and if there is an error, the user can say “no” to modify it.
Open Applications
 When users need to open an installed program, they can directly say commands like “Open QQ,” and the computer will automatically open QQ, saving users from searching their cluttered desktop for the application.
When users need to open an installed program, they can directly say commands like “Open QQ,” and the computer will automatically open QQ, saving users from searching their cluttered desktop for the application.
Query Functions
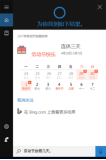 Cortana can also accept queries; for instance, if the user says, “How many days off for Labor Day?” Cortana will automatically open the calendar and display the dates for Labor Day.
Cortana can also accept queries; for instance, if the user says, “How many days off for Labor Day?” Cortana will automatically open the calendar and display the dates for Labor Day.
Calculator
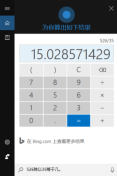 Cortana can also invoke certain built-in Windows features; for example, if the user says, “What is 526 divided by 35?” Cortana will automatically open the calculator and compute the result.
Cortana can also invoke certain built-in Windows features; for example, if the user says, “What is 526 divided by 35?” Cortana will automatically open the calculator and compute the result.
The above are examples of the applications of Cortana, and now let’s introduce the features of iFlytek’s Lingxi voice assistant.
Auto Dialing and Sending Messages
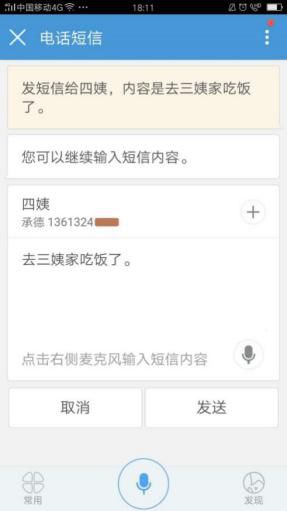 Voice-activated dialing is no longer a novelty; almost all voice assistants support this feature. Users only need to say, “Call XX,” and the phone will automatically dial the number. In addition to dialing numbers, sending text messages and creating reminders can also be achieved through the voice assistant. Users simply say, “Send a message to XX, content is XXX,” and the phone will automatically send the content to the corresponding contact.
Voice-activated dialing is no longer a novelty; almost all voice assistants support this feature. Users only need to say, “Call XX,” and the phone will automatically dial the number. In addition to dialing numbers, sending text messages and creating reminders can also be achieved through the voice assistant. Users simply say, “Send a message to XX, content is XXX,” and the phone will automatically send the content to the corresponding contact.
Set Alarms
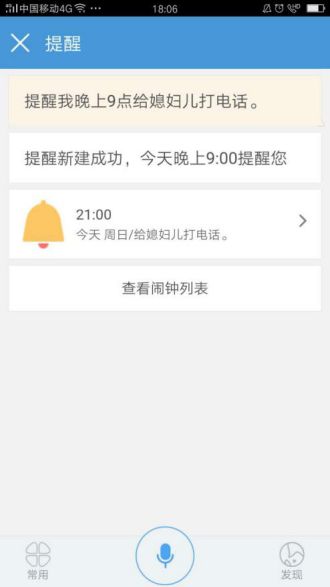 Similar to setting reminders on a computer, users only need to say, “Remind me to call my wife at 9 PM,” and the phone will automatically set an alarm for 9 PM with a note to call the wife. If the user does not specify a date, it defaults to today; if it is already past 9 PM, the system defaults to the next day. No more worrying about forgetting to call the wife and having to kneel on a washboard.
Similar to setting reminders on a computer, users only need to say, “Remind me to call my wife at 9 PM,” and the phone will automatically set an alarm for 9 PM with a note to call the wife. If the user does not specify a date, it defaults to today; if it is already past 9 PM, the system defaults to the next day. No more worrying about forgetting to call the wife and having to kneel on a washboard.
Play Music
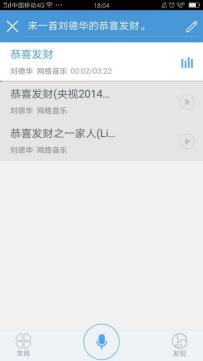 Users can directly ask the voice assistant to play music. If the user does not have the corresponding song stored locally, the voice assistant can find and play the song online. For example, if the user says, “Play ‘Congratulations’ by Andy Lau,” the voice assistant can automatically find and play that song. In addition to these functions, users can also use the voice assistant for navigation, translation, and other tasks.
Users can directly ask the voice assistant to play music. If the user does not have the corresponding song stored locally, the voice assistant can find and play the song online. For example, if the user says, “Play ‘Congratulations’ by Andy Lau,” the voice assistant can automatically find and play that song. In addition to these functions, users can also use the voice assistant for navigation, translation, and other tasks.
As major companies launch voice assistant software, they have also opened some speech recognition function interfaces. Taking iFlytek as an example, users can log into the official website to download the SDK and documentation required for speech recognition, including free access to features like speech dictation, speech synthesis, and command word recognition for individual users. Anyone with a basic programming background can use these SDKs to customize a wide range of personalized functions, such as linking to databases, creating voice memos, and using speech to remember where items were placed. For instance, if a user says while tidying up, “I put the old wallet in the innermost part of the bedside cabinet,” when the user later forgets where the old wallet is, they can simply ask, “Where is the old wallet?” and receive the answer, “In the innermost part of the bedside cabinet.”
As the “ears” of artificial intelligence, speech recognition not only completes the work of hearing but also performs part of the brain’s function in analyzing the meaning of speech, taking on some of the roles of the artificial intelligence brain. Its corresponding technology has important applications in human-computer dialogue and information processing. In the future, speech recognition will develop towards popularization and convenience, allowing users to express what they want without needing to conform to the language habits that computers easily understand. Moreover, with the prevalence of smart home appliances, users will be able to “command” devices in their homes through speech, as if they have an invisible butler by their side.