Understanding Convolutional Neural Networks (CNN)
Convolutional Neural Networks (CNN) are a type of feedforward neural network where artificial neurons can respond to a portion of the surrounding units within a coverage area, demonstrating outstanding performance in large image processing. CNN has five characteristics: 1. Local perception; 2. Parameter sharing; 3. Sampling; 4. Multiple convolutional kernels; 5. Multiple convolutional layers. The first three features are powerful tools for reducing the number of parameters in CNN.
We hope that an object will be recognized as the same object regardless of whether it is on the left or right side of the image; this characteristic is known as invariance.
To achieve translational invariance, convolutional neural networks (CNN) and other deep learning models use convolution operations in the convolutional layer, which can capture local features in the image without being affected by their position.
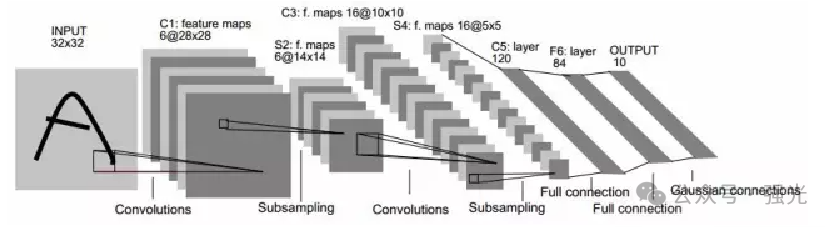
 So what exactly is a convolutional neural network? Taking handwritten digit recognition as an example, the entire recognition process is shown below:
So what exactly is a convolutional neural network? Taking handwritten digit recognition as an example, the entire recognition process is shown below:
-
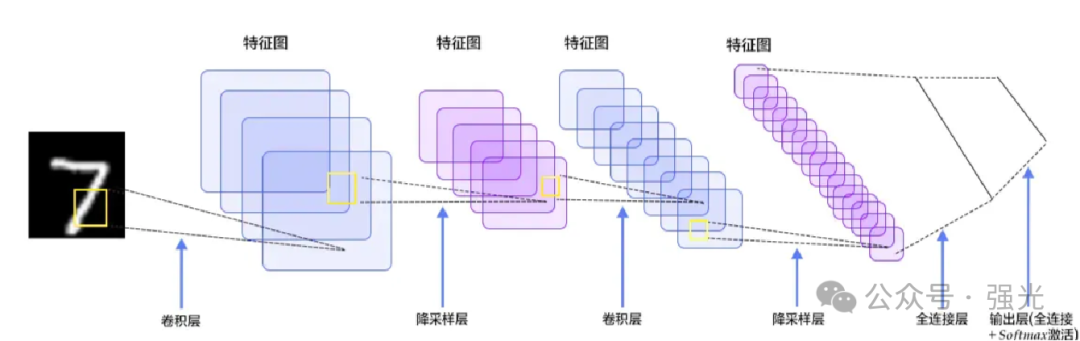
Input Layer: Inputs image and other information
-
Convolution Layer: Used to extract low-level features of the image
-
Pooling Layer: Prevents overfitting and reduces data dimensions
-
Fully Connected Layer: Summarizes the low-level features and information obtained from the convolutional and pooling layers
-
Output Layer: Produces the result with the highest probability based on the information from the fully connected layer
Network Structure
CNN consists of an alternating combination of input layer, convolutional layer, and sampling layer, followed by fully connected layer and output layer.
The input layer is generally two-dimensional, such as a 64*64 image, and can be viewed as a matrix whose size is equal to the number of pixels in the image.
The convolutional layer sequentially performs convolution operations between the matrix regions and convolutional kernels to produce a new matrix; the regions of the matrix are generated sequentially moving from the top left corner to the right or down until reaching the right or bottom boundary; there can be multiple convolutional kernels, so the original matrix will produce multiple new matrices after passing through the convolutional layer.
The sampling layer abstracts the regions of the original matrix into a numerical representation, significantly reducing the dimensionality of the features; the selection of matrix regions is the same as in the convolutional layer; methods for abstracting matrix regions into numbers include taking the maximum, minimum, or average value; the processing in the abstraction layer does not change the number of matrices but only alters the scale of the matrices.
The fully connected layer maps the matrices produced by the alternating combination of convolutional and sampling layers into a one-dimensional vector, then employs the structure and processing methods of BP neural networks.
The number of neurons in the output layer equals the number of classifications, used to represent the output values of the classifications.