This article will explain what problems CNN solves,the principles of human vision,the basic principles of CNN,The typical CNN and its practical applications in four aspects, helping you to understand Convolutional Neural Networks (CNN) in one article.
1.What Problems CNN Solves
There are two major challenges in image processing:
-
Huge Data Volume: Images are composed of pixels, and each pixel is represented by three RGB color parameters.
For a 1920×1080 pixel image, it requires processing 6 million parameters. (1920*1080*3=6220800)
-
Difficulty in Feature Retention: Traditional image processing methods struggle to retain the original image features. For example, if the position of an object in an image changes, the data processed by traditional methods will differ significantly.

CNN Solves the Problems:
-
Feature Extraction: Convolution operations extract features from images, such as edges and textures, preserving image characteristics.
-
Dimensionality Reduction: Pooling operations significantly reduce the parameter scale, achieving dimensionality reduction, greatly decreasing computational load and avoiding overfitting.
2.The Principles of Human Vision
Before we understand the principles of CNN, let’s first look at the principles of human vision.
The Nobel Prize in Physiology or Medicine 1981:
-
Winners: David Hubel, Torsten Nils Wiesel, Roger Sperry
-
Main Contributions: They discovered the information processing of the visual system, and that the visual cortex is hierarchical.
Principles of Human Vision::
-
Light Signal Perception: The original signal intake, light signals converted into neural signals.
-
Primary Visual Processing: Neural signals are transmitted to the primary visual cortex of the brain, for preliminary feature extraction, such as edges and textures.
-
Advanced Visual Processing: Information from the primary visual cortex is passed to the higher visual cortex for complex feature extraction, such as color, shape, and motion.
-
Recognition and Cognition: Matching and recognizing the input image with existing knowledge.
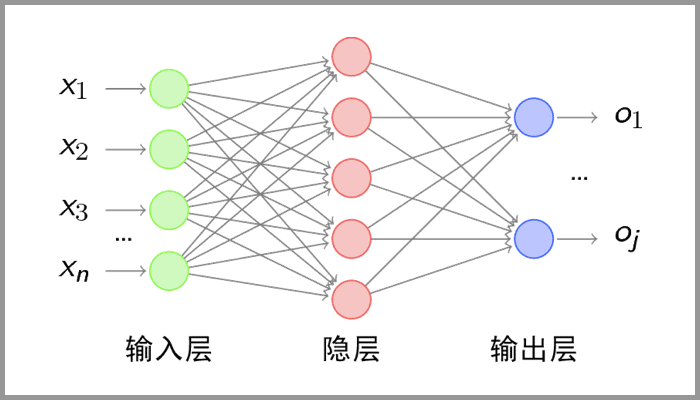
3.The Basic Principles of CNN
Components:
-
Convolutional Layer: Used to extract local features from images.
-
Pooling Layer: Used to significantly reduce parameter scale, achieving dimensionality reduction.
-
Fully Connected Layer: Used to output the desired result.
Basic Principles::
-
Convolutional Layer: Extracts local features from the image through the convolution kernel, similar to the primary visual cortex performing preliminary feature extraction.
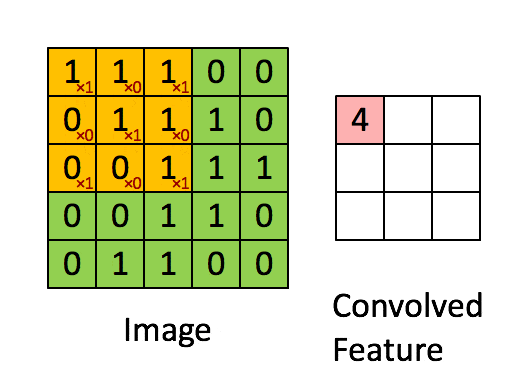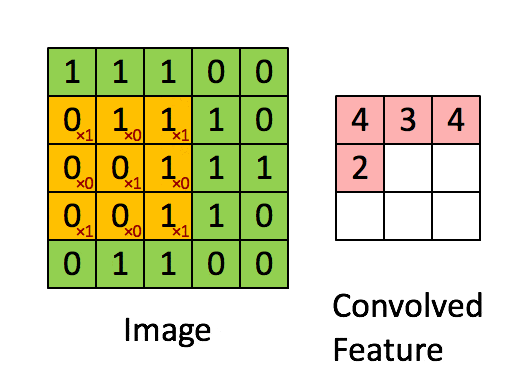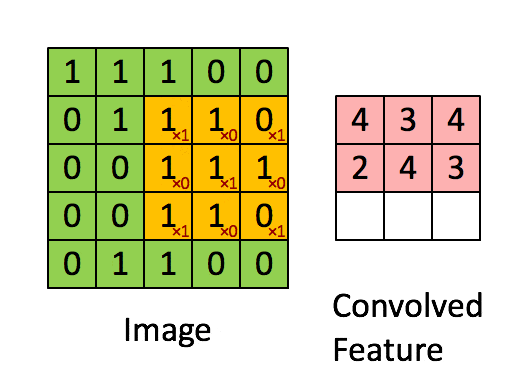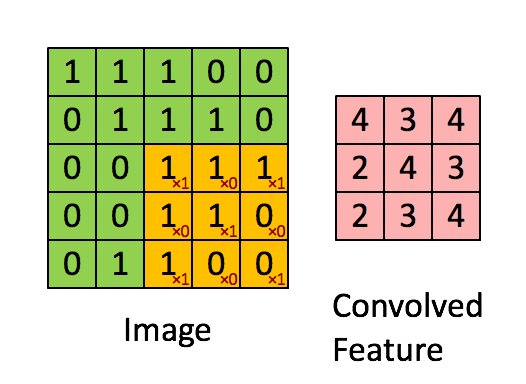
Using a filter (convolution kernel) to filter various small areas of the image to obtain the feature values of these small areas.
-
Pooling Layer: Downsampling to achieve dimensionality reduction, significantly reducing computational load and avoiding overfitting.
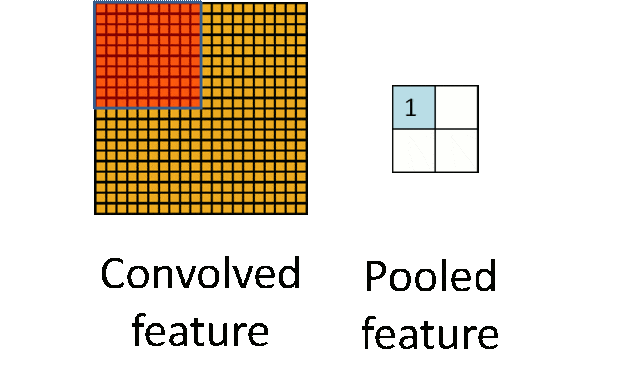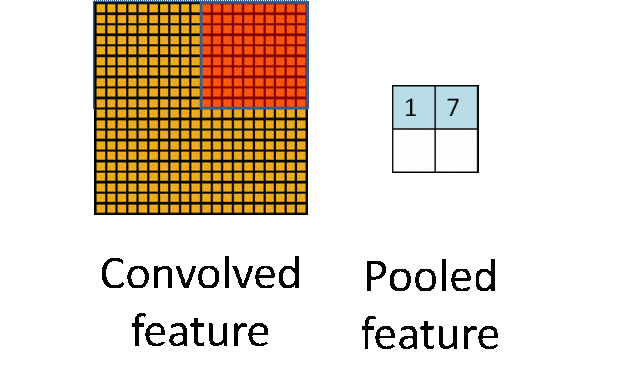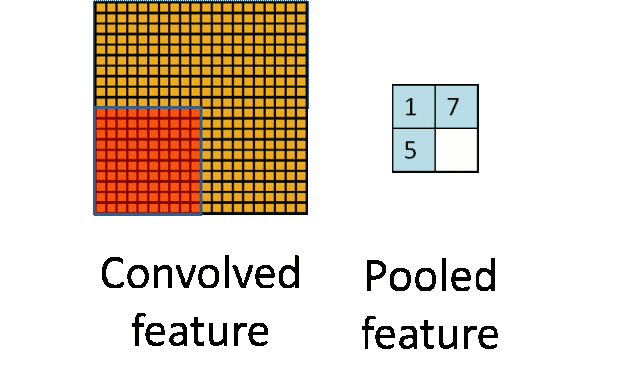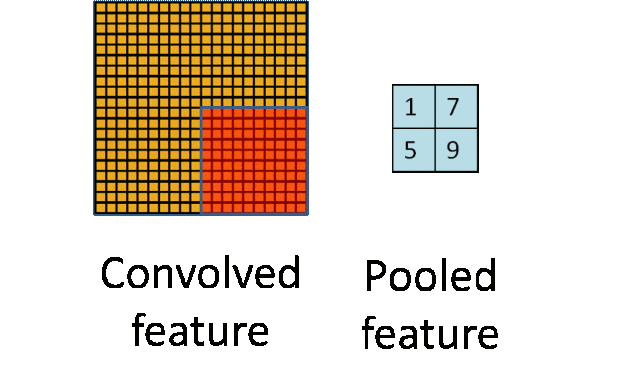
Original size is 20×20, after downsampling to 10×10, resulting in a 2×2 feature map.
-
Fully Connected Layer:: The data processed through the convolutional and pooling layers is input into the fully connected layer to obtain the final desired result.
4. Typical CNN and Practical Applications
A typical CNN is not just the three-layer structure mentioned above, but a multi-layer structure.

For example, LeNet-5 is known as the “Hello World” of convolutional neural networks. LeNet-5 was proposed by Turing Award winner Yann LeCun in 1998, to solve the problem of handwritten character recognition.
Network Structure of LeNet-5::
-
Input Layer: INPUT
-
Three Convolutional Layers:C1, C3, and C5
-
Two Pooling Layers: S2 and S4
-
One Fully Connected Layer: F6
-
Output Layer: OUTPUT
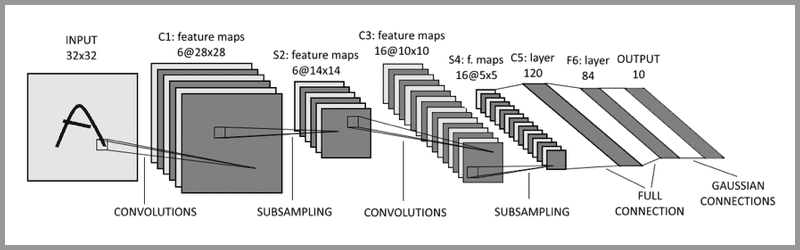
Input Layer – Convolutional Layer – Pooling Layer – Convolutional Layer – Pooling Layer – Convolutional Layer – Fully Connected Layer – Output Layer
Practical Applications::
-
Image Classification: It can save a lot of labor costs by effectively classifying images, with an accuracy rate of over 95%. Typical Scenario: Image Search.
-
Object Localization: It can locate objects in images and determine their position and size.Typical Scenario: Autonomous Driving.
-
Object Segmentation: Simply understood as pixel-level classification.Typical Scenario: Video Cropping.
-
Facial Recognition: A very widespread application that can recognize even when wearing a mask. Typical Scenario: Identity Verification.