Click on the “AIWalker” above, select “Star” or “Top” to receive important content promptly.
In the past two years, many CNN architectures have emerged, some designed manually and others developed through NAS. However, once the architecture is established, there are always some commonalities among different methods. This article discusses several recent papers from the perspective of channel redundancy.
SlimConv
paper: https://arxiv.org/abs/2003.07469, code: Not open-sourced
This is a rather interesting article that argues that feature maps in convolutional neural networks (CNNs) suffer from channel redundancy, which leads to waste of memory and computational resources. Therefore, it proposes an improvement plan from this perspective: enhancing network performance by reducing channel redundancy.
Method
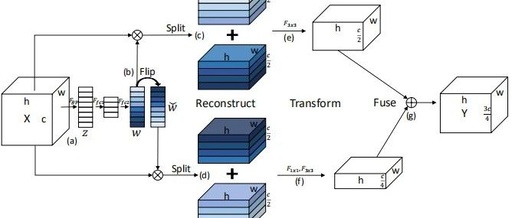
The SlimConv designed by the authors includes three main steps (Reconstruct, Transform, Fuse), allowing features to be split and reorganized more effectively. The key core of SlimConv lies in weight flipping, which can greatly enhance the diversity of features, thus aiding performance improvement. Note: The SlimConv designed by the authors is a plug-and-play module that can be easily embedded into existing network architectures for performance enhancement.
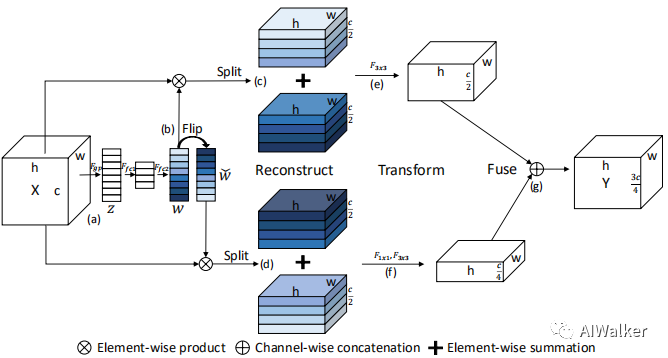
The above figure shows the architecture diagram of SlimConv designed by the authors, which includes several components:
-
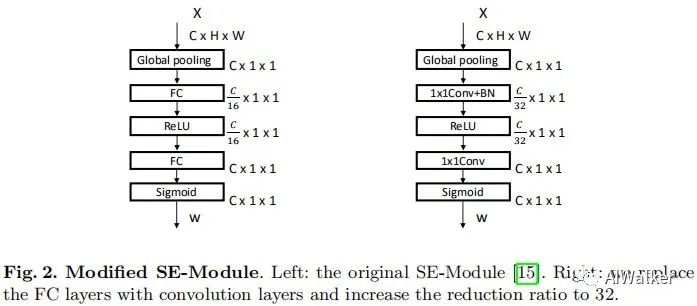
(1) Attention part: This part adopts an attention mechanism similar to SEBlock. The authors fine-tuned the original SEBlock, as shown in the figure below. It seems that there are no significant improvements: (a) replacing FC with a 1×1 convolution, but these two are equivalent; (b) the reduction is increased from 16 to 32, which should not be considered an improvement; (c) a BN layer follows the first convolution, and during inference, Conv and BN can be fused, which is also difficult to call an improvement.
-
(2) Feature reconstruction part: This part is the core improvement of the paper. The original SEBlock only has one branch for feature enhancement, while this paper has two branches of output. The upper branch is similar to the SEBlock output, while the lower branch first mirrors the attention weights and then performs attention fusion; -
(3) Feature splitting and fusion: In this part, the authors split and add-fuse the features obtained from the two branches. This has the effect of dimensionality reduction but may also lead to information loss, so the authors adopted a two-branch method. Will two branches really prevent information loss? -
(4) Feature transformation and fusion: After obtaining features from the two branches, how to fuse them? Directly concatenating or adding is definitely not feasible; if done this way, performance is likely to degrade. What if both branches use the same 3×3 convolution? I personally believe this is also not feasible, as it is difficult to ensure the diversity of features from the two branches. The authors propose that the upper branch directly applies a 3×3 convolution, while the lower branch uses a combination of 1×1 convolution + 3×3 convolution. The 1×1 convolution also has a dimensionality reduction effect, and ultimately the two branches are fused through concatenation. Default input C channels, output 3C/4 channels.
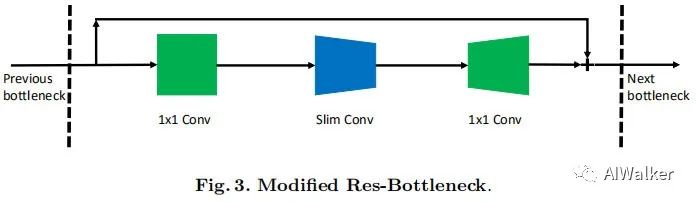
Considering the differences in input and output channel numbers of SlimConv, the so-called “plug-and-play” mentioned in the paper is not feasible. Therefore, it is necessary to fine-tune the embedded module. The above figure shows the adjustment diagram when SlimConv is embedded in ResNet’s Bottleneck. There seems to be nothing more to introduce; additionally, I would like to add another point of understanding regarding SlimConv, see how to evaluate the new plug-and-play module SlimConv?. Below are several experimental effect comparison tables.
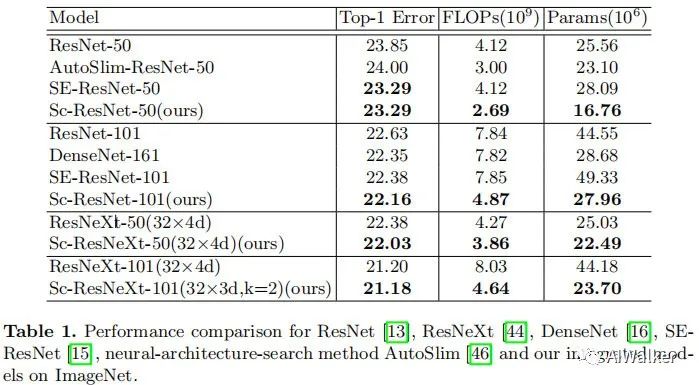
# The author did not provide code, but I have provided a Pytorch implementation for reference.
class SlimConv(nn.Module):
def __init__(self, channels=64, reduction=32):
super().__init__()
self.atten = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, channels//reduction, 1),
nn.BatchNorm2d(channels//reduction),
nn.ReLU(),
nn.Conv2d(channels//reduction, channels, 1),
nn.Sigmoid()
)
self.upper = nn.Conv2d(channels//2, channels//2, 3, 1, 1)
self.lower = nn.Sequential(
nn.Conv2d(channels//2, channels//4, 1),
nn.BatchNorm2d(channels//4),
nn.ReLU(inplace=True),
nn.Conv2d(channels//4, channels//4, 3, 1, 1)
)
def forward(self, x):
atten = self.atten(x)
upper = atten * x
upper = sum(torch.split(upper, upper.size(1)//2, dim=1))
upper = self.upper(upper)
lower = atten.flip(1) * x
lower = sum(torch.split(lower, lower.size(1)//2, dim=1))
lower = self.lower(lower)
return torch.cat([upper, lower], dim=1)
GhostNet
paper: https://arxiv.org/abs/1911.11907
code: https://github.com/iamhankai/ghostnet
This paper proposes a lightweight network architecture by Huawei Noah’s Ark. The authors also improve existing convolutions from the perspective of feature redundancy: enhancing feature diversity through simple linear transformations. They also mention that the proposed module is a “plug-and-play” type module.

Before introducing the proposed scheme, the authors first visualized the intermediate feature maps of ResNet50. They believe that there is a lot of redundancy in the features of existing networks, which affects the model’s performance. In fact, this redundancy is also a potential premise for network pruning: redundant features can be obtained from other features through linear weighting. If there is no feature redundancy, how can we ensure that the performance does not significantly decline after pruning?
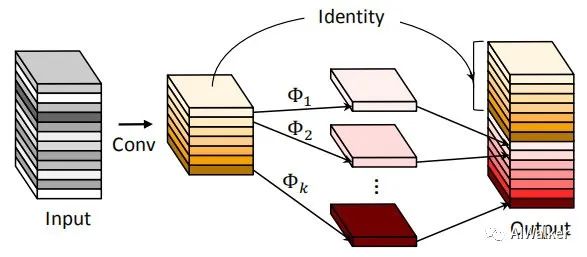
The above figure shows the Ghost module discussed by the authors, which draws on the ideas of DenseNet to enhance feature diversity through secondary linear transformations. With the above figure, there seems to be nothing more to introduce in terms of principles; interested readers are advised to refer to the original text.
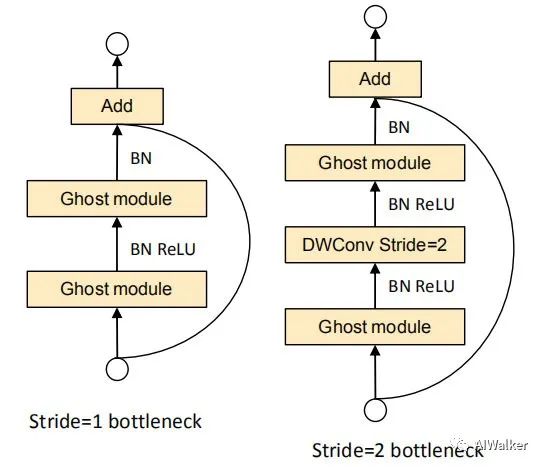
Finally, the authors show how to embed the Ghost module into ResNet, as shown in the two types of Bottleneck in the figure above.
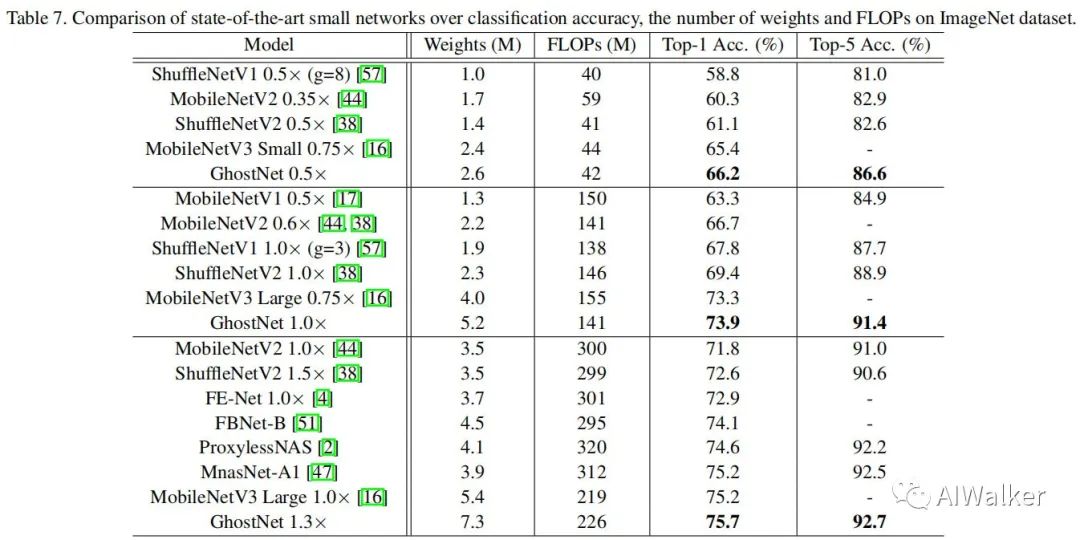
The above figure shows a performance comparison of the proposed network architecture with other lightweight networks on ImageNet, surpassing MobileNetV3. Finally, a reference implementation code in Pytorch is attached.
# copy from official pytorch version code.
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
VoVNet
vovnetv1: https://arxiv.org/abs/1904.09730
vovnetv2: https://arxiv.org/abs/1911.06667
When I saw GhostNet, I thought of a “magic modification” approach, adding more cascades and considering how to embed it into ResNet. Unfortunately, reality slapped me in the face because similar ideas had already been published. This brings us to VoVNet.
VoVNet improves upon the issues present in DenseNet by adopting a One-Shot-Aggregation approach, as shown in the figure below. This connection method of VoVNet not only retains the flexible feature representation capability of DenseNet with multi-receptive fields but also overcomes the inefficiency of dense connections (requiring only one feature aggregation). Compared to detectors based on DenseNet, detectors based on VoVNet achieve faster speeds (2x) and lower power consumption (1.6x-4.1x).
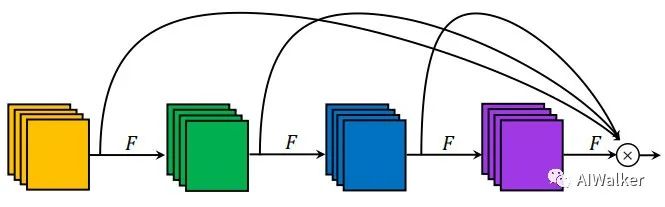
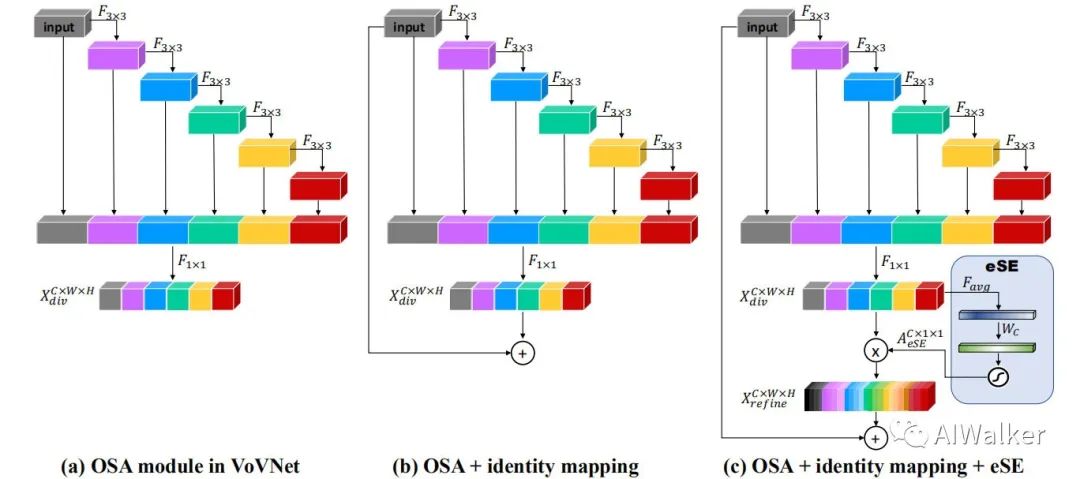
VoVNetV2 was my proposed scheme at the time, which coincidentally was also developed around the same time. Since I do not pay much attention to the object detection field, I was unaware that this method had already been published. I only found out about it a few days ago when I saw the article VoVNet: A New Backbone Network for Real-Time Object Detection by @小小将 on Zhihu, and I felt embarrassed! For an introduction to VoVNetV2, I suggest visiting @小小将’s blog; I won’t go into too much detail here, as the diagrams basically show how to code.
Welcome to follow the AIWalker public account, where you will receive exclusive deep learning experience sharing and personal insights. If you want to support Happy to continue writing, please give a thumbs up and follow!