
In the past two weeks, projects like AutoGPT and BabyAGI have gained immense popularity. I spent some time over the weekend reviewing the code of these AI agent projects and decided to write an article summarizing my technical insights and thoughts on the current advancements in this field for everyone to discuss.
From Language Understanding to Task Execution
Previously, most related projects and products primarily utilized the language understanding capabilities of the GPT model, such as Jasper for generating copy, Notion AI for web and document summarization, Glarity, Bearly.ai for Q&A, New Bing, ChatPDF, etc. To expand the application scope of GPT, a natural direction is to enable GPT to learn how to use various external tools for a broader range of task execution, achieving “unity of knowledge and action” 😊. Besides AutoGPT and BabyAGI, many interesting projects like Toolformer[1], HuggingGPT[2], and Visual ChatGPT[3] are also exploring this direction.
The principle behind task execution is not complicated. The basic approach is still to have GPT generate responses, but we inform GPT in the prompt that if it needs to call external tools, it should generate specific instructions/code in a particular format. The program then receives this and calls the external tools based on the content generated by GPT, obtaining the corresponding results, which can then be further understood and generated by GPT, creating a loop. For example, in LangChain’s most common ReAct prompt, the input to the model is as follows:
...You can use the following tools to complete tasks: 1. Calculator, for executing various mathematical calculations to obtain precise results, input expressions like 1 + 1 to get the result... Question: What is the result of 123 times 456?...The model generates the following content:
Thinking: I need to use the calculator to calculate the result of 123 times 456 Action: Call the calculator Action Input: 123 * 456 Observation Result:We can then process this return, call the calculator program, obtain the result of 123 * 456, fill it in after the observation result, and let the model continue generating the next part.
This is the basic method for task execution. More content can also refer to my previous sharing about LangChain: How Microsoft 365 Copilot is Implemented? Unveiling How LLM Generates Instructions[4].

Model Memory
Another common pattern is to enhance model memory through external storage. A typical scenario is during long session chats; due to the 4000 token limit of the GPT API, users often find that ChatGPT has “forgotten” previous content after prolonged conversations. Another typical scenario involves providing the LLM with more new information, such as understanding and answering questions based on an entire PDF or knowledge base, which cannot simply be processed by throwing all this extra information into the prompt.
In such cases, external storage is needed to help GPT expand its memory. The simplest method is to save these conversation records and external information as text in files or a database system. Later, during interactions with the model, this external stored information can be retrieved as needed. We can consider the content in the prompt as the model’s “short-term memory,” while this external storage acts as “long-term memory.” Besides the previously mentioned benefits, this memory system can also help reduce model hallucinations to some extent, avoiding purely relying on “generation” to achieve task objectives.
The most common method for acquiring long-term memory is through “semantic search.” This involves using an embedding model to convert all memory texts into vectors. The subsequent interaction information with the model can also be converted into vectors using the same embedding model, allowing for similarity calculations to find the most relevant memory texts. Lastly, these memory texts can be concatenated into the prompt as input for the model. Popular open-source projects in this area include OpenAI’s ChatGPT Retrieval Plugin[5] and Jerry Liu’s LlamaIndex[6].
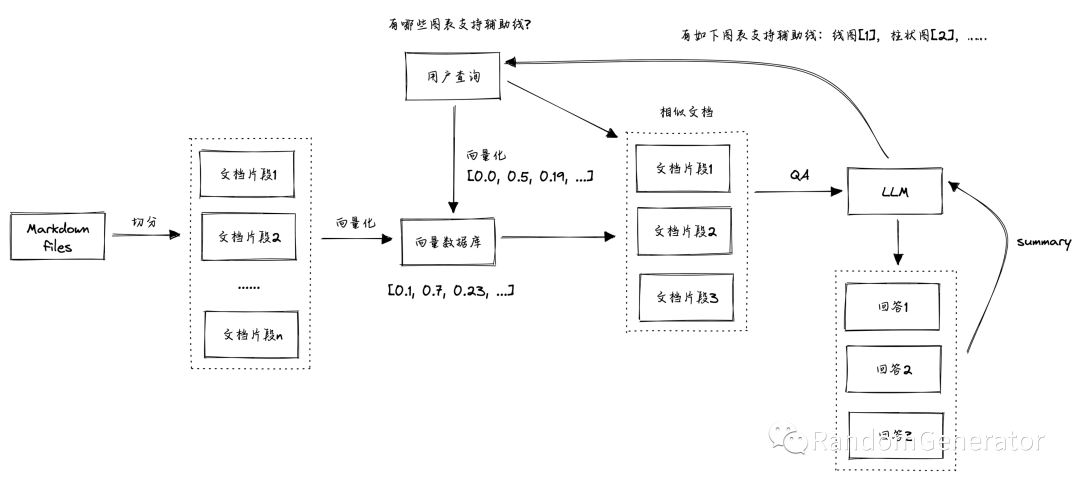
This model memory expansion pattern feels somewhat “rough” compared to human brain operations. The so-called long-term and short-term memory (including some more complex implementations in LangChain and LlamaIndex) still feel quite “hard coded.” If there are breakthrough research developments in model context size in the future, then this type of pattern may no longer be necessary.
From an overall interaction process perspective, this model memory implementation can also be seen as a form of “task execution,” but here the task is “writing/retrieving memory” rather than “executing an external tool.” We can unify both views, as they represent the current most common application development patterns for large language models. Later, we will see that various so-called intelligent agents are also developed under this thinking.
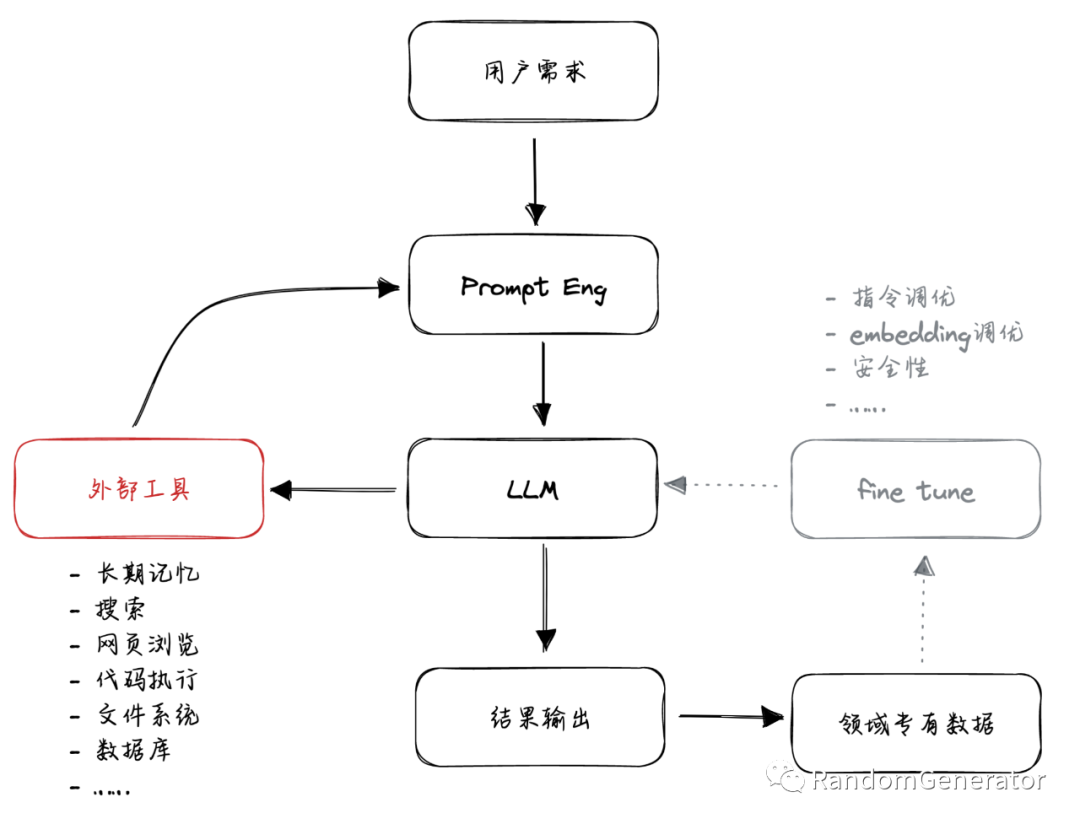
Interestingly, OpenAI’s Jack Rae and Ilya Sutskever mentioned the idea of compression as wisdom[7] in their previous discussions. Regarding the model’s “compression rate,” if it can more effectively utilize these “external tools,” it can significantly improve the accuracy of next token predictions for many specific tasks. Personally, I feel there is still a lot of potential in this direction, for example, from the perspective of “effective data,” the data humans use when executing various tasks with tools or even during thought processes can be highly valuable. From the model training perspective, how to incorporate the model’s ability to utilize tools into the loss function during the process may also be an interesting direction.

AutoGPT
With the previous context, understanding the internal structure and core logic of how AI agents like AutoGPT work becomes easier. Most innovations in these projects still lie at the prompt level, activating the model’s capabilities through better prompts, turning many processes that previously required hard-coded logic into dynamically generated logic by the model. Taking AutoGPT as an example, its core prompt is as follows:
You are Guandata-GPT, 'an AI assistant designed to help data analysts do their daily work.'Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications. GOALS: 1. 'Process data sets' 2. 'Generate data reports and visualizations' 3. 'Analyze reports to gain business insights' Constraints: 1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files. 2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember. 3. No user assistance 4. Exclusively use the commands listed in double quotes e.g. "command name" Commands: 1. Google Search: "google", args: "input": "<search>" 2. Browse Website: "browse_website", args: "url": "<url>", "question": "<what_you_want_to_find_on_website>" 3. Start GPT Agent: "start_agent", args: "name": "<name>", "task": "<short_task_desc>", "prompt": "<prompt>" 4. Message GPT Agent: "message_agent", args: "key": "<key>", "message": "<message>" 5. List GPT Agents: "list_agents", args: 6. Delete GPT Agent: "delete_agent", args: "key": "<key>" 7. Clone Repository: "clone_repository", args: "repository_url": "<url>", "clone_path": "<directory>" 8. Write to file: "write_to_file", args: "file": "<file>", "text": "<text>" 9. Read file: "read_file", args: "file": "<file>" 10. Append to file: "append_to_file", args: "file": "<file>", "text": "<text>" 11. Delete file: "delete_file", args: "file": "<file>" 12. Search Files: "search_files", args: "directory": "<directory>" 13. Evaluate Code: "evaluate_code", args: "code": "<full_code_string>" 14. Get Improved Code: "improve_code", args: "suggestions": "<list_of_suggestions>", "code": "<full_code_string>" 15. Write Tests: "write_tests", args: "code": "<full_code_string>", "focus": "<list_of_focus_areas>" 16. Execute Python File: "execute_python_file", args: "file": "<file>" 17. Generate Image: "generate_image", args: "prompt": "<prompt>" 18. Send Tweet: "send_tweet", args: "text": "<text>" 19. Do Nothing: "do_nothing", args: 20. Task Complete (Shutdown): "task_complete", args: "reason": "<reason>" Resources: 1. Internet access for searches and information gathering. 2. Long Term memory management. 3. GPT-3.5 powered Agents for delegation of simple tasks. 4. File output. Performance Evaluation: 1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities. 2. Constructively self-criticize your big-picture behavior constantly. 3. Reflect on past decisions and strategies to refine your approach. 4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps. You should only respond in JSON format as described below Response Format: { "thoughts": { "text": "thought", "reasoning": "reasoning", "plan": "- short bulleted\n- list that conveys\n- long-term plan", "criticism": "constructive self-criticism", "speak": "thoughts summary to say to user" }, "command": { "name": "command name", "args": { "arg name": "value" } } } Ensure the response can be parsed by Python json.loadsFrom this lengthy prompt, it is evident that AutoGPT is indeed a leading example of the current advanced prompt application model, with many learnings to be taken. Compared to the classic reason + act model, we can examine the further developments and improvements it has made.
Constraints & Resources
Here, the model is informed of its various limitations, which is quite amusing. For instance, the model’s input context size is limited, so it needs to save important information to files. This action is crucial, especially in code generation scenarios, as it enables the generation and execution of longer codes. Additionally, AutoGPT also provides the model with long-term memory management functions. Currently, the task-solving processes generated by such complex prompts are often lengthy, and without such management, the model’s output can easily become incoherent.
Moreover, the default model is “not connected to the internet,” meaning all knowledge is only updated to the training data cutoff date. Therefore, it explicitly informs the model that it can search online for more timely external information.
Commands
The commands, or options for various tools, are quite rich here. This is one reason many articles highlight AutoGPT’s ability to complete various tasks, as it offers high flexibility and versatility.
The specific commands can be categorized into several major types, including search, web browsing, starting other GPT agents, file read-write operations, code generation, and execution, etc. The idea of using other agents is somewhat similar to HuggingGPT, because currently, GPT models perform better and more stably on more specific, detailed tasks. Thus, this “divide and conquer” approach is necessary.
Performance Evaluation
This section provides guiding principles for the model’s overall thinking process, divided into several specific dimensions, including reviewing the match between its abilities and behaviors, big-picture thinking and self-reflection, optimizing decision-making actions with long-term memory, and completing tasks efficiently with fewer actions. This thinking logic aligns well with human thinking and the iterative process of decision-making and feedback.
Response
In terms of response format, it integrates several models, requiring the model to articulate its thoughts, engage in reasoning to acquire relevant background knowledge, generate a plan with specific steps, and conduct self-criticism of its thinking process. These format restrictions also provide specific operational norms for the previous cognitive guiding principles.
The generation of specific commands is essentially consistent with the previously mentioned ReAct method. Here, commands can also be nested; for example, one command can start another GPT agent and then send a message to this agent, allowing for more complex tasks. In LangChain, however, there should only be one call and return between the sub-agent and the main process, which is relatively limited.
It is noteworthy that this entire response is generated by the model in one interaction, unlike some other frameworks that require multiple rounds of interaction to generate plans, reviews, and action generation. I feel this is because the solution process generated by AutoGPT often becomes very lengthy. If every action’s generation required multiple interactions with the LLM, the time and token costs would be significant. However, if a specific decision action incurs high costs, such as calling an expensive API for image generation, it may be more efficient to review and optimize this action multiple times before making a final decision.
Human Intervention
If you have run AutoGPT yourself, you may find that the model often complicates problems or “goes off track” at the execution planning level. Therefore, during the specific execution process, AutoGPT also allows users to intervene, providing additional input for each specific execution step to guide the model’s behavior. After human feedback input, the model will regenerate the aforementioned response, and this process continues. You can visit this AutoGPT product with an interface[8] to experience this process firsthand. Although from a task completion perspective, it is still in the early stages, the design of this prompt and interaction method is quite enlightening.
BabyAGI
Compared to AutoGPT, BabyAGI is a project that focuses more on the “thinking process” aspect and does not add support for utilizing various external tools. Its core logic is very simple:
-
Obtain the first task from the task list. -
Retrieve task-related “memory” information, which is executed by the task execution agent to obtain results. Currently, this execution is a simple LLM call without involving external tools. -
Store the returned results in memory. -
Based on current information, such as overall goals, the most recent execution results, task descriptions, and the list of unexecuted tasks, generate new tasks as needed. -
Add the new tasks to the task list and then prioritize and reorder all tasks.
The author states that this process simulates a real workday. In the morning, check what tasks need to be done, complete tasks during the day, receive feedback, and in the evening, review whether new tasks need to be added based on the feedback and reorder priorities.
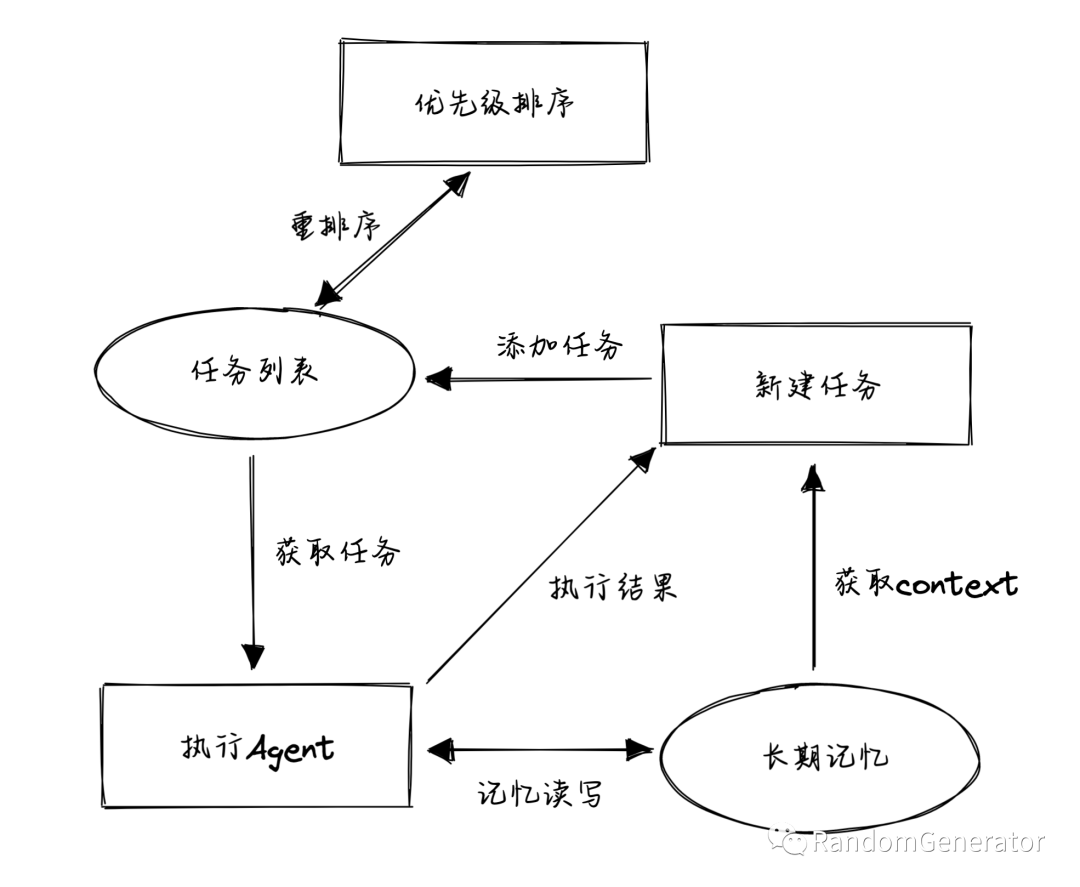
The entire project has a small amount of code, and the related prompts are also relatively simple and easy to understand. Interested students can read the code themselves.
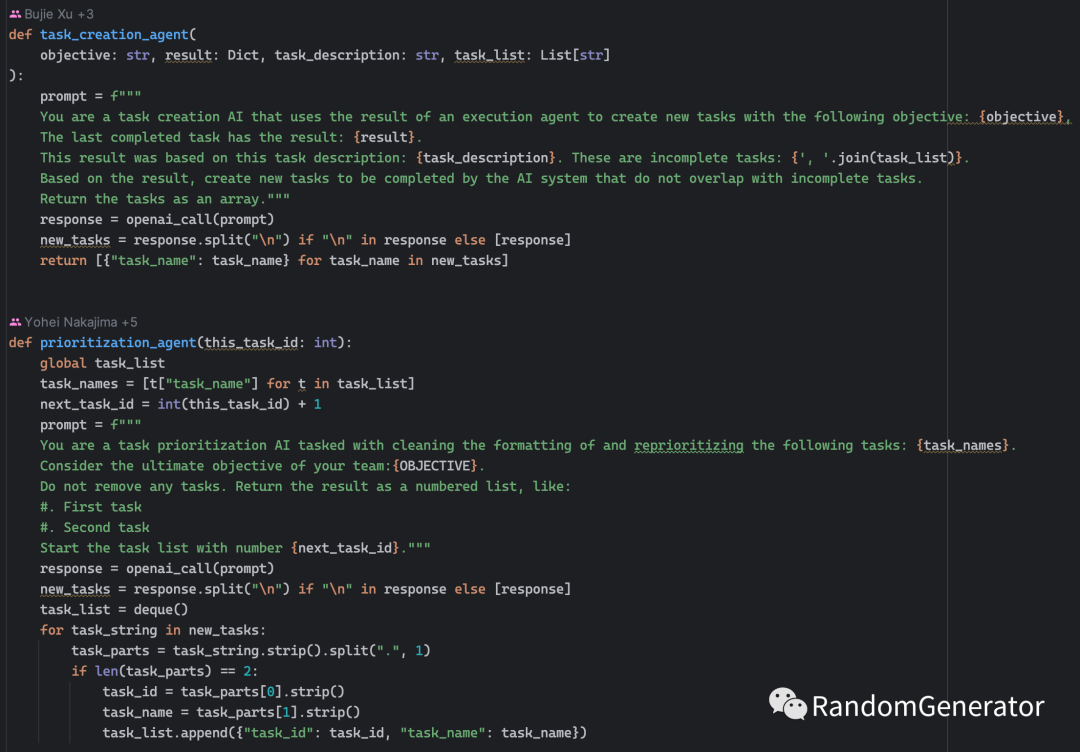
Subsequently, some evolved versions of this project have emerged, such as BabyASI[9], which borrowed from AutoGPT to add support for search, code execution, and other tools. Theoretically, if this ASI (Artificial Super Intelligence) is smart enough, it could even generate code to optimize its own prompts, modify processes, and even conduct continuous model training, allowing GPT to develop future GPTs. It’s an intriguing thought 😆.
HuggingGPT
If BabyAGI explores the plan & execution application model of LLMs, HuggingGPT, an earlier work, showcases the imaginative space at the level of “external tools.” Its core operational logic also combines planning with execution, but in terms of execution tools, it can leverage a wealth of “domain-specific models” to assist LLMs in completing complex tasks more effectively, as illustrated in the following figure:

Through various examples provided by the author, it is evident that LLMs can understand tasks well and invoke the corresponding models to solve them. Although many examples may later be accomplished directly by the multimodal GPT series in an end-to-end manner, the idea remains quite interesting. External tools are not limited to searches and API calls; they can also invoke other complex models. In the future, we might not only call models but also trigger data collection, model training/fine-tuning actions, completing even more complex task processes.
From another perspective, for specific, specialized, and high-frequency scenarios that often have rich data, building a smaller proprietary model can effectively meet related demands at a lower cost. Meanwhile, for more ambiguous and variable demands, the powerful understanding, reasoning, and generation capabilities of large models can be better utilized. This may replace many business processes currently driven by heuristic rules in the future.
Camel / Generative Agents
In the previous AutoGPT section, we saw some methods of adding long-term memory to model agents and invoking other agents for interaction. Additionally, in the earlier prompt patterns, we discovered that allowing the model to self-reflect or plan before executing often leads to significant performance improvements. If we extend this direction further, could we assemble multiple agents into a team, each playing different roles, to better solve complex problems and even allow this small “community” to evolve more complex behavioral patterns or discover new knowledge? Recently, two popular works related to the direction of agent “communities” have emerged.
Camel
In the Camel[10] work, the author’s idea is to simulate users and AI assistants through LLMs, allowing two agents to role-play (e.g., one as a business expert and the other as a programmer) and then have them communicate and collaborate autonomously to accomplish a specific task. This idea is quite straightforward, but the author also mentions that prompt design is crucial; otherwise, it can easily lead to role-switching, repeated instructions, infinite message loops, flawed responses, and issues with when to terminate the dialogue. Interested students can take a look at the prompt settings given in the project code, which include many explicit instructions to guide the agents in their anticipated communication and collaboration.

Apart from optimizing agent prompts and operational modes, the author also designed prompts to automatically generate various roles, scene demands, and other content. These contents can automatically form various role-playing scenarios, allowing for the collection of interaction data between agents in different scenarios for further analysis. Interested students can explore the various dialogue records generated between agent combinations on this website[11]. The project code is also open-sourced, making it a great starting point for researching AI agent communities.

Generative Agents
In the Generative Agents[12] work, the author assembled 25 models with identity settings into a virtual town community, where each agent possesses a memory system and can autonomously plan, act, respond, and self-reflect, allowing them to operate freely and genuinely simulate a community’s functioning. This simulation process has led to the “emergence” of many phenomena seen in real society, which is quite fascinating.
From a technical perspective, several behavior settings for agents in this article are worth learning:
-
Each agent’s memory retrieval is more detailed, combining timeliness, importance, and relevance to recall related memories. This performs significantly better than simple vector similarity searches. -
Memory storage also includes a reflection step, regularly summarizing memories to maintain the agent’s “sense of purpose.” -
The plan generation involves multi-level recursion, generating action plans from coarse to fine, which is closer to our daily thinking patterns. -
Using a “character interview” method to evaluate the effectiveness of these behavioral settings, ablation experiments have shown significant improvements.
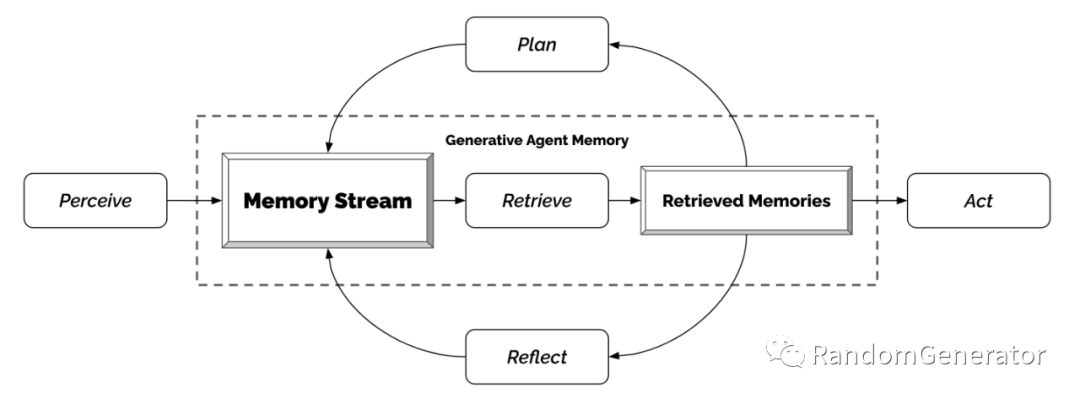
This entire logic of identity, plan, act/react, reflect, and memory stream appears quite reasonable and can complement AutoGPT’s approach. However, there are certainly limitations, such as the simulation process involving one-on-one conversations between agents without meeting/broadcast settings. Currently, the simulation’s runtime is also limited, making it challenging to ensure the evolution of agents’ memories, behavioral patterns, and the exploration and advancement of the community’s overall goals over extended periods.
From an application perspective, it seems that the focus is primarily on social activity simulation and gaming applications. Whether it can expand to broader fields such as task processing and knowledge exploration remains to be further explored.
Prompt Patterns
Finally, let’s summarize the prompt design patterns reflected in these projects.
-
CoT prompts, which provide not only instructions but also a breakdown or example of the task execution process. Many people have probably used this, saying, “let’s think step by step” 😊. -
“Self-reflection,” reminding the model to self-reflect before producing results to see if there is a better solution. It can also be used after obtaining results to force the model to reflect. For instance, AutoGPT includes, “Constructively self-criticize your big-picture behavior constantly.” -
Divide and conquer; when writing prompts, you may find that the more specific the context and goal, the better the model performs. Therefore, breaking down tasks and applying the model often yields better results than asking it to complete an entire task at once. Utilizing external tools and nesting agents are also extensions of this approach, naturally leading to CoT. -
Plan first, execute later. BabyAGI, HuggingGPT, and Generative Agents have all adopted this pattern. This pattern can also be expanded; for example, during the planning phase, the model can proactively ask questions to clarify goals or propose potential solutions, followed by a human review for confirmation or feedback, reducing the likelihood of goal deviation. -
Memory systems, including short-term memory scratchpads, long-term memory streams for storage, processing, and retrieval, etc. This pattern is present in almost all agent projects and is currently one of the few solutions that can reflect some models’ real-time learning capabilities.
It can be seen that these patterns have significant similarities with human cognition and thinking patterns. Historically, there has been dedicated research on cognitive architecture[13], systematically considering the design of agents from dimensions such as memory, world cognition, problem-solving (action), perception, attention, reward mechanisms, and learning. Personally, I feel that current LLM agents still have significant room for improvement in the aspects of reward mechanisms (whether there are good goal guidelines) and learning evolution (whether they can continuously enhance their capabilities). Perhaps the future application of RL in model agents will have vast imaginative space, not just for “value alignment” as it is primarily used now.
Common Issues
If you have hands-on experience with these projects, you should be able to feel some of the current issues and limitations of model agents. For example:
-
Memory recall issues. If it only performs simple embedding similarity recall, it is easy to find that the results are not very good. There should be plenty of room for improvement here, such as the more detailed handling of memories in Generative Agents and the many options and tuning possibilities in LlamaIndex regarding index structures. -
Error accumulation issues. Many examples found online are likely cherry-picked; in reality, the model’s overall performance is not so impressive, often deviating early on in some steps and then drifting further away… A significant issue here may still be the lack of high-quality training data regarding task decomposition execution and external tool utilization. This is likely one reason why OpenAI wants to develop its plugin system. -
Exploration efficiency issues. For many simple scenarios, having a model agent independently explore and complete the entire solution process is still relatively cumbersome and time-consuming, and agents can easily complicate problems. Considering the costs of LLM calls, significant optimizations in this area are still needed for practical application. One approach might be to introduce human judgment intervention and feedback input midway, as seen in AutoGPT. -
Task termination and result validation. In some open-ended questions or scenarios where results cannot be judged through clear evaluation methods, how to terminate the model agent’s work poses a challenge. This also returns to the earlier point that executing task-related data collection and model training, as well as applying reinforcement learning, may help solve this problem.
What tricky issues have you encountered while using these model agents, and what good solutions do you have? Or have you discovered any scenarios that can already be well met by existing agents? Feel free to share and discuss in the comments section.
References
Toolformer: https://arxiv.org/abs/2302.04761
[2]HuggingGPT: https://github.com/microsoft/JARVIS
[3]Visual ChatGPT: https://github.com/microsoft/visual-chatgpt
[4]How Microsoft 365 Copilot is Implemented? Unveiling How LLM Generates Instructions: https://www.bilibili.com/video/BV1DY4y1Q7Te/
[5]ChatGPT Retrieval Plugin: https://github.com/openai/chatgpt-retrieval-plugin
[6]LlamaIndex: https://github.com/jerryjliu/llama_index
[7]Compression as Wisdom: https://www.youtube.com/watch?v=dO4TPJkeaaU
[8]AutoGPT Product with Interface: https://godmode.space/
[9]BabyASI: https://github.com/oliveirabruno01/babyagi-asi
[10]Camel: https://www.camel-ai.org/
[11]This Website: http://data.camel-ai.org/
[12]Generative Agents: https://arxiv.org/abs/2304.03442
[13]Research on Cognitive Architecture: https://cogarch.ict.usc.edu/