
From | Zhihu
Author | Lucas
Column | Deep Learning and Emotion Computing
Editor | Machine Learning Algorithms and Natural Language Processing
Understanding Attention: Attention Mechanism and Its PyTorch Implementation
Bionic Brain Attention Model -> Resource Allocation
The deep learning attention mechanism is a bionic representation of the human visual attention mechanism, essentially a resource allocation mechanism. The physiological principle is that human visual attention can receive high-resolution information from a specific region of an image while perceiving surrounding areas at a lower resolution, and the viewpoint can change over time. In other words, the human eye quickly scans the global image to find the target area that needs attention, then allocates more attention to this area to gain more detailed information and suppress other useless information, thereby improving the efficiency of representation. For example, in the image below, my main focus is on the icon in the middle and the word ‘ATTENTION’, while I pay less attention to the stripes on the border, which can be a bit dizzying when glanced at.

Encoder-Decoder Framework == Sequence to Sequence Conditional Generation Framework
The Encoder-Decoder framework, also known as the sequence to sequence conditional generation framework[1], is a research model in the field of text processing. In the conventional encoder-decoder method, the first step is to encode the input sentence sequence X into a fixed-length context vector C through a neural network, which is the semantic representation of the text; the second step is for another neural network to act as a decoder, using the currently predicted words and the encoded context vector C to predict the target word sequence. During this process, the RNNs of the encoder and decoder are jointly trained, but the supervisory information only appears on the decoder RNN side, and the gradient is backpropagated to the encoder RNN side. Using LSTM for text modeling is currently a popular and effective method[2].
The most typical application of the attention mechanism is statistical machine translation. Given a task, the input is “Echt”, “Dicke”, and “Kiste” into the encoder, using RNN to represent the text as a fixed-length vector h3. However, the problem is that the current decoder only relies on the last hidden state h3 when generating y1, which is the sentence embedding. Therefore, this h3 must encode all the information in the input sentence. In reality, the traditional Encoder-Decoder model cannot achieve this function. Isn’t LSTM[3] designed to solve the long-term dependency problem? However, long short-term memory networks still have issues. We say that RNNs need to sequentially access all previous units before accessing long-term information in the current processing unit, which makes it prone to the gradient vanishing problem. LSTM is introduced to use gating to some extent to solve this issue. Indeed, LSTM, GRU, and their variants can learn a large amount of long-term information, but they can only remember relatively long information, not larger and longer ones.
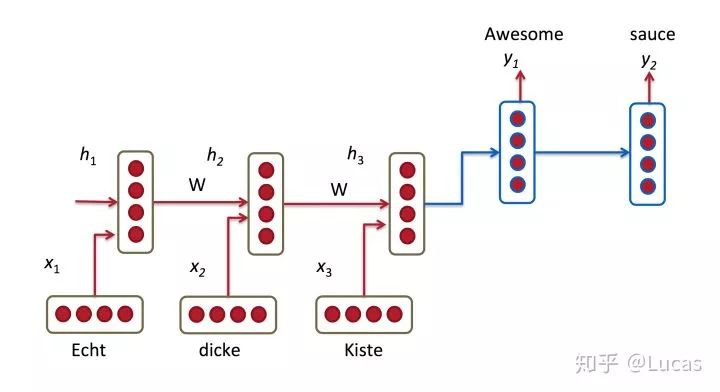
So, let’s summarize the general paradigm of the traditional encoder-decoder and its issues: the task is to translate the Chinese “我/爱/赛尔” to English. The traditional encoder-decoder first inputs the entire sentence, encodes the last word “赛尔”, and after finishing, uses RNN to generate a representation vector C for the entire sentence. During conditional generation, when translating to the second word “赛尔”, it needs to step back to find the already predicted h_1 and the context representation C, and then decode the output.
From Equal Attention to Focused Attention
In the traditional Encoder-Decoder framework: the decoder predicts the target word sequence based on the current predicted word memory encoded context vector C. This means that regardless of which word is generated, the sentence encoding representation C we use is the same. In other words, any word in the sentence has the same influence on generating a target word P_yi, which means equal attention. Clearly, this is counterintuitive. The intuition should be: when I translate a certain part, that part should focus on the original text I am translating. When translating to the first word, I should pay more attention to what the first word in the original text means. See the pseudocode and the diagram below:
P_y1 = F(E<start>,C),
P_y2 = F((E<the>,C)
P_y3 = F((E<black>,C)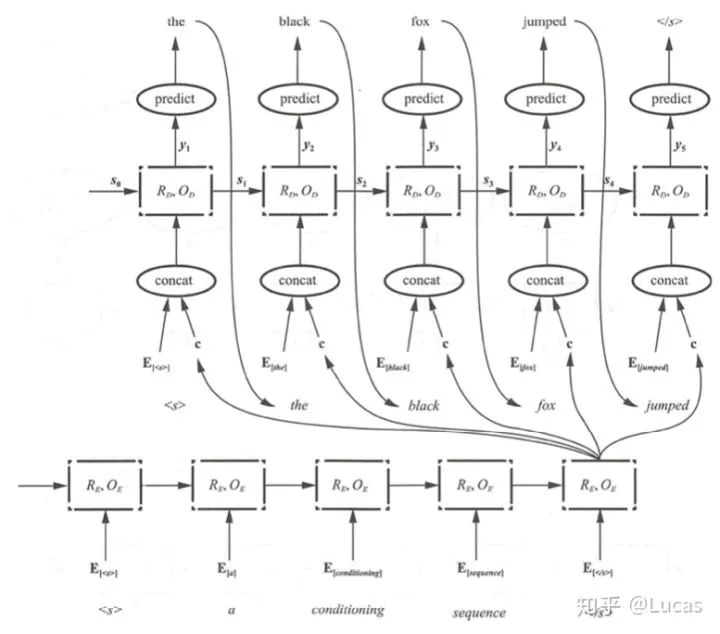
Next, observe the difference between the two diagrams above: the same context representation C is replaced with a context vector Ci that changes according to the currently generated word.
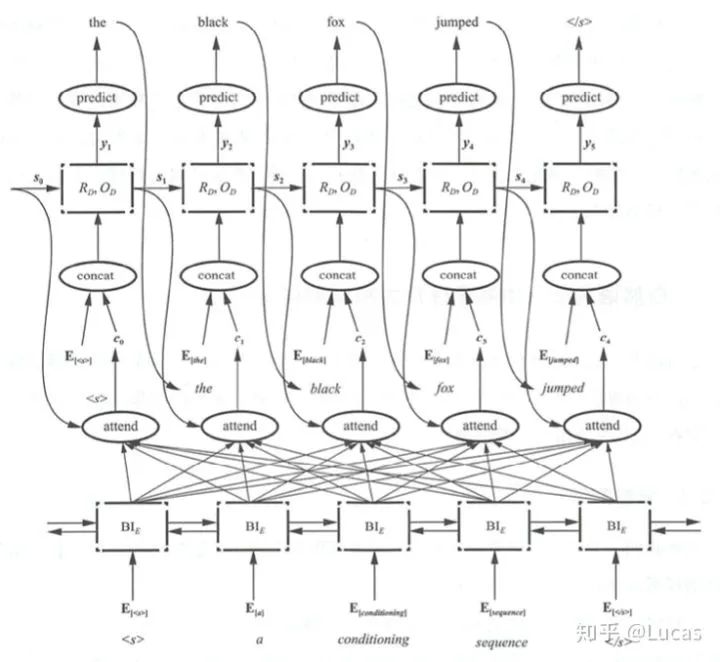
The text translation process becomes:
P_y1 = F(E<start>,C_0),
P_y2 = F((E<the>,C_1)
P_y3 = F((E<black>,C_2)Code Implementation of the Encoder-Decoder Framework[4]
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)Considering Interpretability
Traditional encoder-decoder models without attention have poor interpretability: we do not have a clear understanding of what information is encoded in the encoding vector, how to utilize this information, and the reasons behind the specific behaviors of the decoder. Structures that include the attention mechanism provide a relatively simple way for us to understand the reasoning process of the decoder and what the model is actually learning. Although it is a form of weak interpretability, it makes sense.
Confronting the Core Formula of Attention

When predicting the ith word of the target language, the weight of the jth word in the source language is . The size of the weight can be seen as a form of soft alignment information between the source and target languages.
Summary
The use of the attention method actually involves automatically acquiring semantic information from different positions in the original sentence when predicting a target word yi, and assigning a weight to the semantic information of each position, which is the “soft” alignment information, organizing this information to compute the original sentence vector representation c_i for the current word yi.
PyTorch Implementation of Attention
import torch
import torch.nn as nn
class BiLSTM_Attention(nn.Module):
def __init__(self):
super(BiLSTM_Attention, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, n_hidden, bidirectional=True)
self.out = nn.Linear(n_hidden * 2, num_classes)
# lstm_output : [batch_size, n_step, n_hidden * num_directions(=2)], F matrix
def attention_net(self, lstm_output, final_state):
hidden = final_state.view(-1, n_hidden * 2, 1) # hidden : [batch_size, n_hidden * num_directions(=2), 1(=n_layer)]
attn_weights = torch.bmm(lstm_output, hidden).squeeze(2) # attn_weights : [batch_size, n_step]
soft_attn_weights = F.softmax(attn_weights, 1)
# [batch_size, n_hidden * num_directions(=2), n_step] * [batch_size, n_step, 1] = [batch_size, n_hidden * num_directions(=2), 1]
context = torch.bmm(lstm_output.transpose(1, 2), soft_attn_weights.unsqueeze(2)).squeeze(2)
return context, soft_attn_weights.data.numpy() # context : [batch_size, n_hidden * num_directions(=2)]
def forward(self, X):
input = self.embedding(X) # input : [batch_size, len_seq, embedding_dim]
input = input.permute(1, 0, 2) # input : [len_seq, batch_size, embedding_dim]
hidden_state = Variable(torch.zeros(1*2, len(X), n_hidden)) # [num_layers(=1) * num_directions(=2), batch_size, n_hidden]
cell_state = Variable(torch.zeros(1*2, len(X), n_hidden)) # [num_layers(=1) * num_directions(=2), batch_size, n_hidden]
# final_hidden_state, final_cell_state : [num_layers(=1) * num_directions(=2), batch_size, n_hidden]
output, (final_hidden_state, final_cell_state) = self.lstm(input, (hidden_state, cell_state))
output = output.permute(1, 0, 2) # output : [batch_size, len_seq, n_hidden]
attn_output, attention = self.attention_net(output, final_hidden_state)
return self.out(attn_output), attention # model : [batch_size, num_classes], attention : [batch_size, n_step]GitHub address:
https://github.com/zy1996code/nlp_basic_model/blob/master/lstm_attention.py
References
-
^ “Neural Network Methods in Natural Language Processing”
-
^ Sequence to Sequence Learning with Neural Networks https://arxiv.org/pdf/1409.3215.pdf
-
^ LSTM Overview: Understanding Long Short-Term Memory Networks and Their PyTorch Implementation https://zhuanlan.zhihu.com/p/86876988
-
^ The Annotated Transformer https://nlp.seas.harvard.edu/2018/04/03/attention.html
—End—
Recommended for you:
What is the role of activation functions in neural networks? Is there an intuitive explanation?
How impressive is the architecture of "12306"?
Did Rao Yi report multiple scholars for academic fraud? The official response is out.
How did Alibaba withstand 100 billion in 90 seconds? You will understand after reading this article!
13 Probability Distributions You Must Know in Deep Learning