Biomimetic Brain Attention Model -> Resource Allocation
The deep learning attention mechanism is a biomimetic of the human visual attention mechanism, essentially a resource allocation mechanism. The physiological principle is that human visual attention can receive high-resolution information from a specific area in an image while perceiving its surrounding areas at a lower resolution, and the focus can change over time. In other words, the human eye quickly scans the global image to find the target area that requires attention and allocates more attention to that area to gain more detailed information while suppressing other irrelevant information, thus improving the efficiency of representation. For example, in the image below, my main focus is on the icon in the middle and the word ATTENTION, while I pay little attention to the stripes on the border, which makes me feel a bit dizzy.

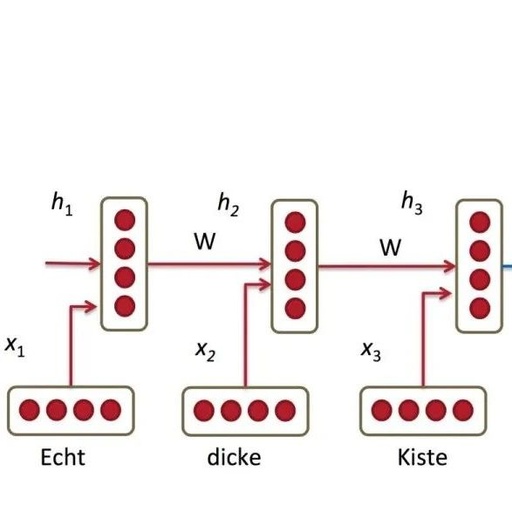
Encoder-Decoder Framework == Sequence to Sequence Conditional Generation Framework
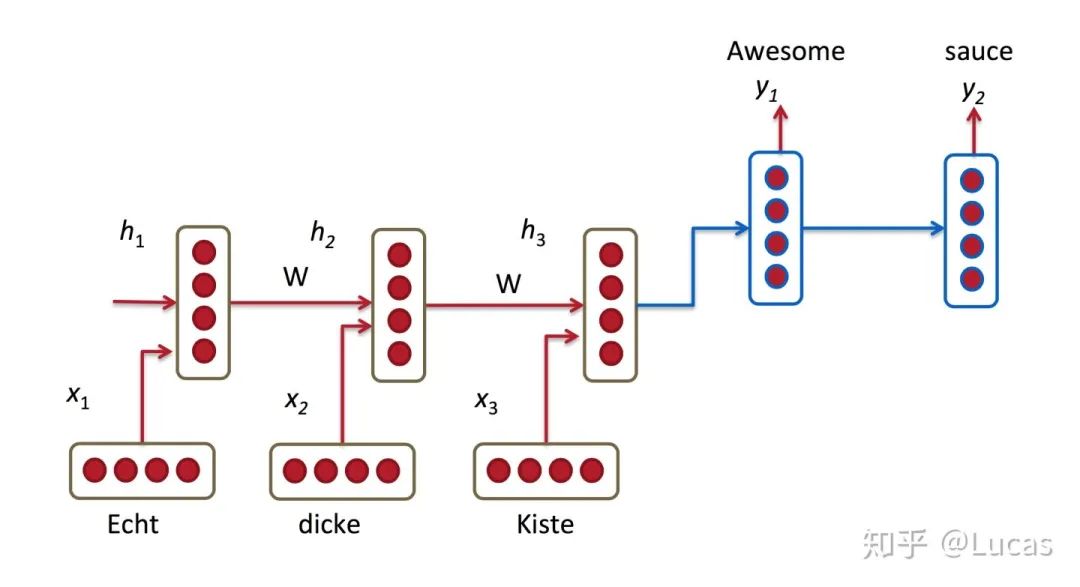
From Equal Attention to Focused Attention
P_y1 = F(E<start>,C),P_y2 = F((E<the>,C)P_y3 = F((E<black>,C)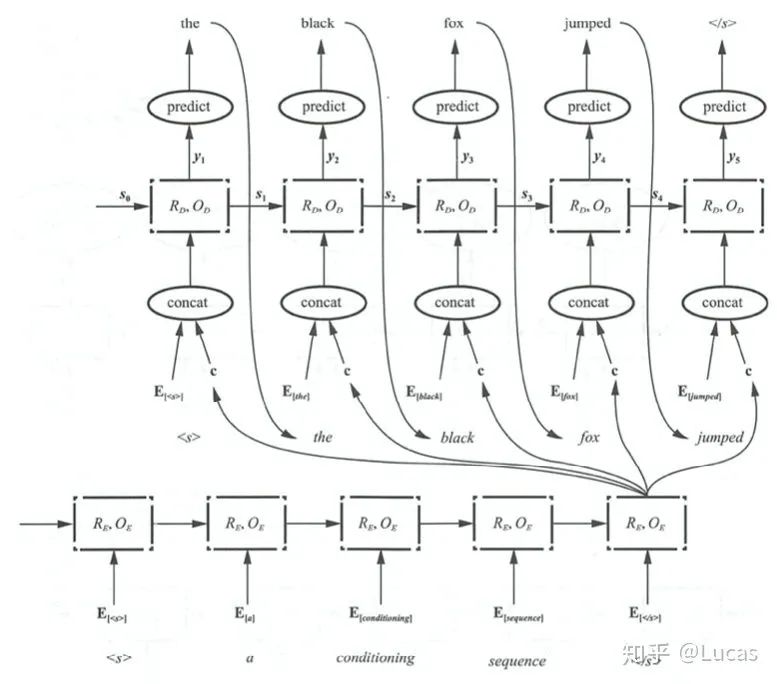
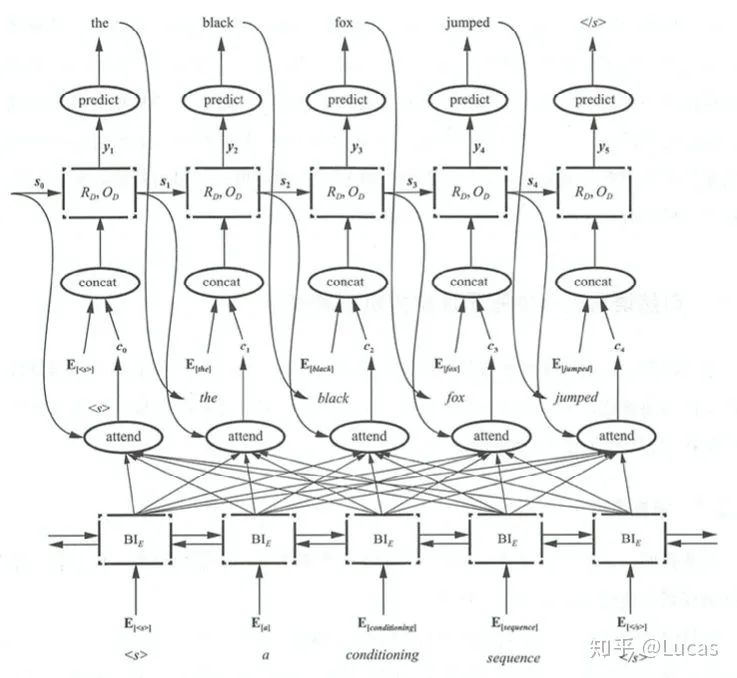
P_y1 = F(E<start>,C_0),P_y2 = F((E<the>,C_1)P_y3 = F((E<black>,C_2)Encoder-Decoder framework code implementation[4]class EncoderDecoder(nn.Module): """ A standard Encoder-Decoder architecture. Base for this and many other models. """ def __init__(self, encoder, decoder, src_embed, tgt_embed, generator): super(EncoderDecoder, self).__init__() self.encoder = encoder self.decoder = decoder self.src_embed = src_embed self.tgt_embed = tgt_embed self.generator = generator def forward(self, src, tgt, src_mask, tgt_mask): "Take in and process masked src and target sequences." return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask) def encode(self, src, src_mask): return self.encoder(self.src_embed(src), src_mask) def decode(self, memory, src_mask, tgt, tgt_mask): return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)Confronting the Core Formula of Attention

 , the size of the weight can be seen as a form of soft alignment information between the source and target languages.
, the size of the weight can be seen as a form of soft alignment information between the source and target languages.Summary
Attention's PyTorch Application Implementationimport torchimport torch.nn as nnclass BiLSTM_Attention(nn.Module): def __init__(self): super(BiLSTM_Attention, self).__init__() self.embedding = nn.Embedding(vocab_size, embedding_dim) self.lstm = nn.LSTM(embedding_dim, n_hidden, bidirectional=True) self.out = nn.Linear(n_hidden * 2, num_classes) # lstm_output : [batch_size, n_step, n_hidden * num_directions(=2)], F matrix def attention_net(self, lstm_output, final_state): hidden = final_state.view(-1, n_hidden * 2, 1) # hidden : [batch_size, n_hidden * num_directions(=2), 1(=n_layer)] attn_weights = torch.bmm(lstm_output, hidden).squeeze(2) # attn_weights : [batch_size, n_step] soft_attn_weights = F.softmax(attn_weights, 1) # [batch_size, n_hidden * num_directions(=2), n_step] * [batch_size, n_step, 1] = [batch_size, n_hidden * num_directions(=2), 1] context = torch.bmm(lstm_output.transpose(1, 2), soft_attn_weights.unsqueeze(2)).squeeze(2) return context, soft_attn_weights.data.numpy() # context : [batch_size, n_hidden * num_directions(=2)] def forward(self, X): input = self.embedding(X) # input : [batch_size, len_seq, embedding_dim] input = input.permute(1, 0, 2) # input : [len_seq, batch_size, embedding_dim] hidden_state = Variable(torch.zeros(1*2, len(X), n_hidden)) # [num_layers(=1) * num_directions(=2), batch_size, n_hidden] cell_state = Variable(torch.zeros(1*2, len(X), n_hidden)) # [num_layers(=1) * num_directions(=2), batch_size, n_hidden] # final_hidden_state, final_cell_state : [num_layers(=1) * num_directions(=2), batch_size, n_hidden] output, (final_hidden_state, final_cell_state) = self.lstm(input, (hidden_state, cell_state)) output = output.permute(1, 0, 2) # output : [batch_size, len_seq, n_hidden] attn_output, attention = self.attention_net(output, final_hidden_state) return self.out(attn_output), attention # model : [batch_size, num_classes], attention : [batch_size, n_step]References
Author: Lucas
Address: https://www.zhihu.com/people/lucas_zhang


Recommended Historical Articles
-
Incredible! A Chinese PhD Visualized the Entire CNN, Every Detail Clearly Seen!
-
Nature Published Oxford PhD’s Suggestions: 20 Things I Wish I Knew at the Beginning of My PhD
-
Shen Xiangyang, Hua Gang: Three Levels, Four Stages, and Ten Questions for Reading Research Papers
-
How to View the Disappearance of Algorithm Positions in the Fall Recruitment of 2021?
-
Exclusive Interpretation | ExprGAN: Expression Editing Based on Intensity Control
-
Exclusive Interpretation | BP Algorithm from a Matrix Perspective
-
Exclusive Interpretation | Deep Interpretation of Capsule Networks
-
Exclusive Interpretation | Adversarial Attacks Under Fisher Information Metrics
-
Paper Interpretation | Overview of Recent Research on Knowledge Graphs
-
Did Your Graduation Thesis Pass? “How to Write a Graduation Thesis?”
-
Kalman Filtering Series – Derivation of Classic Kalman Filtering
-
A Legendary Algorithm SIFT Patent Expires!
-
Past, Present, and Future of Human Pose Estimation
-
2018-2019 Annual Top 10 Reviews
-
Advice for New Researchers: Just Reading Papers Will Not Improve Your Skills; You Must Read Books, Read Books, Read Books!
Share, Like, and Follow, Give a Triple Hit!