Follow our public account to discover the beauty of CV technology
Introduction
Due to its superior capability for modeling global dependencies, the Transformer and its variants have become the primary architecture for many visual and language tasks. However, tasks like Visual Question Answering (VQA) and Referencing Expression Comprehension (REC) often require multi-modal predictions that need visual information from both macro and micro perspectives. Therefore,how to dynamically schedule global and local dependency modeling within the Transformer has become an emerging issue.
In this paper, the authors propose a routing scheme based on input samples called TRAnsformer routing (TRAR) to address this problem.In TRAR, each visual Transformer layer is equipped with routing modules that have different attention spans, allowing the model to dynamically compute corresponding attention weights based on the output of the previous step, thereby establishing an optimal routing path for each sample.
Moreover, through careful design, TRAR can reduce additional computational and memory overhead to an almost negligible level. To validate TRAR, the authors conducted extensive experiments on five benchmark datasets for VQA and REC, achieving superior performance compared to standard Transformers and a series of SOTA methods.

TRAR: Routing the Attention Spans in Transformer for Visual Question Answering
Paper link:
https://openaccess.thecvf.com/content/ICCV2021/papers/Zhou_TRAR_Routing_the_Attention_Spans_in_Transformer_for_Visual_Question_ICCV_2021_paper.pdf
Code link: https://github.com/rentainhe/TRAR-VQA/
Motivation
After the natural language processing field, Transformers have also become the preferred architecture for many vision and language (V&L) tasks. Many researchers have proposed various multi-modal networks, achieving new SOTA performances across various benchmark datasets. The tremendous success of these models is largely attributed to their excellent global dependency modeling of self-attention (SA), which can capture relationships within modalities and facilitate alignment between vision and language.
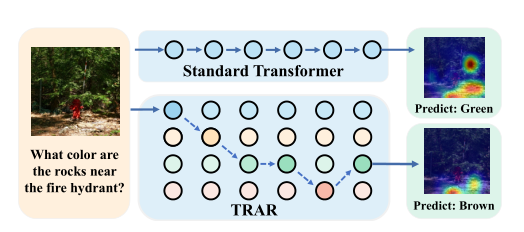
However, in some V&L tasks, such as Visual Question Answering (VQA) and Referencing Expression Comprehension (REC), multi-modal reasoning often requires visual attention from different receptive fields. As shown in the figure above, the model must not only understand the overall semantics but also capture local relationships to provide correct answers. In this case, relying solely on the global dependency modeling of SA is still insufficient to meet such demands.
To address this issue, helping Transformer networks explore different attention spans has become an emerging need. An intuitive solution is to establish a dynamic hybrid network where each layer has a set of attention modules with different receptive fields. The model can then select the appropriate path based on the given sample. However, directly applying this solution may backfire, as the additional parameters and computations will further exacerbate the computational and memory costs of the model, which is already a major drawback of Transformers.
In this paper, the authors propose a new lightweight routing scheme called Transformer Routing (TRAR), which can achieve automatic selection of attention without increasing computational and memory overhead. Specifically, TRAR equips each visual SA layer with a path controller to predict the next attention span based on the output of the previous inference step.
To tackle the redundancy of parameters and computation, TRAR views SA as a fully connected graph feature update function and constructs different adjacency masks for defined attention spans. Subsequently, the task of module path selection can be transformed into a task of mask selection, significantly reducing additional costs.
To validate the effectiveness of TRAR, the authors applied it to two multi-modal tasks (VQA and REC) and conducted extensive experiments on five benchmark datasets (VQA2.0, CLVER, RefCOCO, RefCOCO+, and RefCOCOg). Experimental results demonstrate that TRAR can achieve SOTA performance on the VQA2.0 and RefCOCOg datasets.
Method
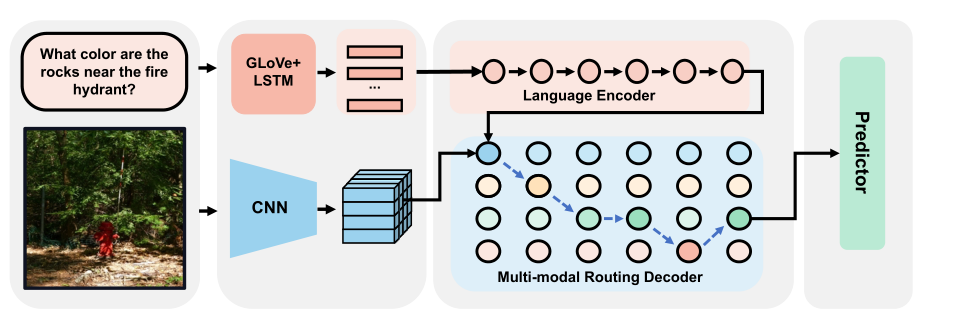
The framework of the Transformer Routing (TRAR) scheme is shown in the figure above. The different colors of the decoding layers represent visual attention of different spans. Through TRAR, the Transformer can dynamically select the visual attention span for each step, achieving the optimal reasoning path for each sample.
4.1. Routing Process
To achieve the dynamic routing objective for each example, an intuitive solution is to create a multi-branch network structure where each layer is equipped with differently configured modules. Specifically, based on the features of the previous inference step and the routing space, the output of the next inference step is obtained as follows:
where α is the path probability predicted by the path controller, which is a set of modules. During testing, α can be binarized for hard selection or kept continuous for soft routing. However, from the equation above, we can see that such a routing scheme inevitably complicates the network and significantly increases training costs.
In this case, the key is to optimize the definition of path routing to alleviate experimental burdens. The standard self-attention definition is:
We can see that SA can be viewed as a feature update function of a fully connected graph, represented as a weighted adjacency matrix. Therefore, to obtain features of different attention spans, it is sufficient to restrict the graph connections of each input element. This can be achieved by multiplying the result of the dot product by an adjacency mask, represented as follows:
where it is a binary 0/1 matrix, set to 1 if within the attention range of the target element.
Based on the above equation, the routing layer of SA can be defined as:
which can be shared between different SA layers, thus reducing the number of parameters.
However, the above formula is still computationally expensive. Therefore, the authors further simplify the module selection problem to the selection of adjacency masks, represented as:
From the above equation, we can see that additional computation and memory usage can be reduced to nearly zero, while still achieving the goal of selecting features from different attention spans.
4.2. Path Controller
In TRAR, each SA layer has a path controller that predicts the routing probabilities, i.e., module selection. Specifically, given input features, the path probabilities are defined as follows:
Here, MLP refers to a multi-layer perceptron, and AttentionPool refers to an attention-based pooling method.
4.3. Optimization
In this paper, the authors provide two types of inference methods for TRAR, namely soft routing and hard routing.
Soft routing
By applying the Softmax function, the classification selection of routing paths can be treated as a continuous differentiable operation. The Router and the entire network can then be jointly optimized end-to-end through the objective function of the specific task. During testing, features of different attention spans are dynamically combined. Since soft routing does not require additional tuning, training is relatively easier.
Hard routing
Hard routing implements binary path selection, which can further introduce specific CUDA kernels to accelerate model inference. However, classification routing makes the weights of the Router non-differentiable, and directly binarizing the results of soft routing may lead to a feature gap between training and testing. To address this issue, the authors introduce the Gumbel-Softmax Trick to achieve differentiable path routing:
4.4. Network Structure
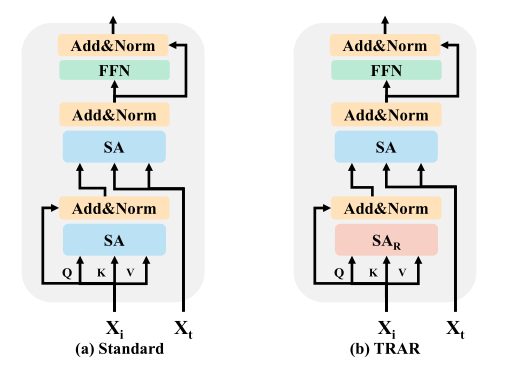
The authors built the dynamic routing network on MCAN. Specifically, similar to the standard Transformer, MCAN has six encoding layers for modeling language features extracted from LSTM, and six decoding layers for simultaneously processing visual features and cross-modal alignment. The authors replaced the visual SA modules with the routing modules proposed in this paper, as shown in the figure above.
Experiments
5.1. Ablations
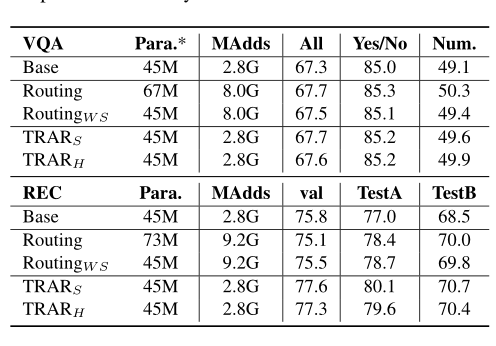
The table above shows the ablation experimental results of this method on REC and VQA tasks. It can be seen that weight sharing of the Router leads to a certain degree of performance drop, and Soft Routing performs slightly better than Hard Routing.
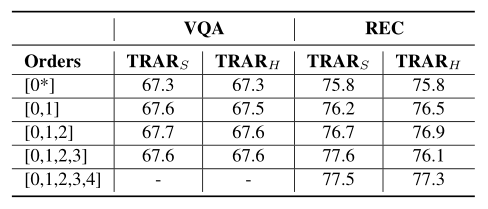
The table above shows the impact of the TRAR routing space. It can be seen that incorporating local attention masks significantly improves performance, while adding higher-order masks yields little performance gain.
5.2. Comparison with SOTA
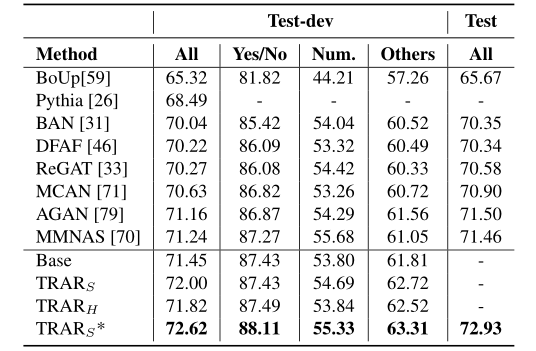
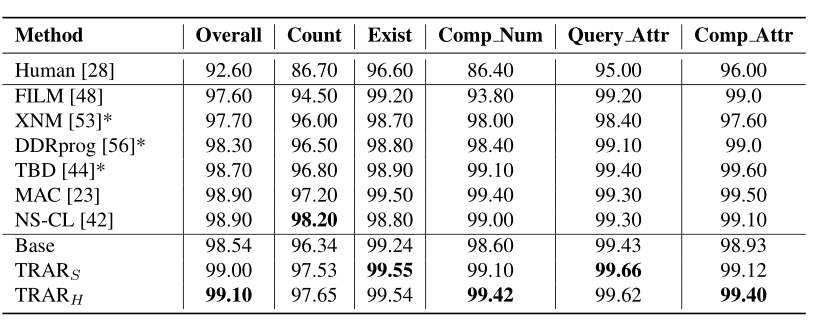
The table above shows the performance comparison of this method with SOTA methods on the VQA task based on the VQA2.0 dataset.
The table above shows the performance comparison of this method with others based on the CLEVR dataset.
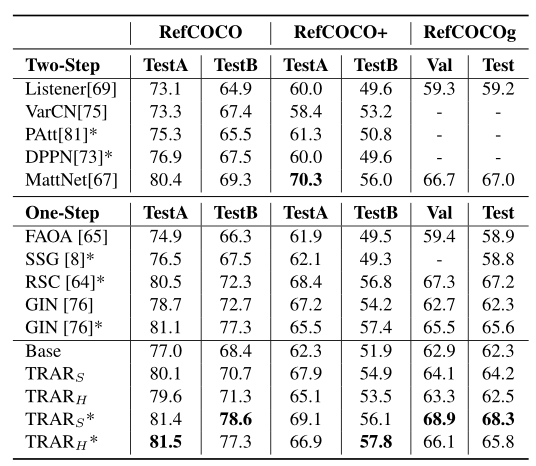
The table above shows the performance comparison of this method with SOTA methods on the REC task across three datasets.
5.3. Qualitative Analysis
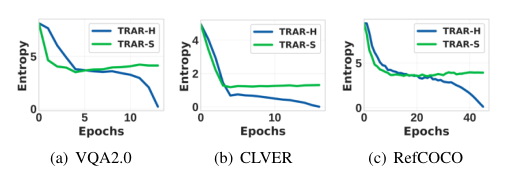
The figure above shows the changes in TRAR routing entropy when using hard routing () and soft routing ().

The figure above shows the comparison of Attention between this method and the baseline, as well as the visualization results of Attention across different tasks.
Conclusion
In this paper, the authors investigated the dependency modeling of Transformers in two vision-language tasks (i.e., VQA and REC). These two tasks typically require visual attention from different receptive fields, which standard Transformers cannot fully handle.
To this end, the authors proposed a lightweight routing scheme called Transformer Routing (TRAR) to help the model dynamically select attention spans for each sample. TRAR transforms the module selection problem into the problem of selecting attention masks, allowing additional computational and memory overhead to be negligible. To validate the effectiveness of TRAR, the authors conducted extensive experiments on five benchmark datasets, and the results confirm the superiority of TRAR.
Research Field: Operator of FightingCV public account, focusing on multi-modal content understanding, aiming to solve tasks that combine visual and language modalities, promoting the practical application of Vision-Language models.
Zhihu/Public Account:FightingCV
Welcome to join the “Transformer” group chat👇 please note:TFM