

Reported by New Intelligence
Reported by New Intelligence
[New Intelligence Overview] Allow language models to solve problems automatically, letting users take a backseat.
The wave of AI driven by ChatGPT has ushered us into the era of artificial intelligence, where language models have become indispensable tools in daily life.
However, current language models can only respond to user queries and accomplish some generative tasks, such as writing stories and generating code.
Large-Action Models (LAM), represented by projects like AutoGPT, GPT-Engineer, and BabyAGI, position language models as the core brain of intelligent agents, capable of decomposing complex tasks and making autonomous decisions at each sub-step, solving problems without user involvement.
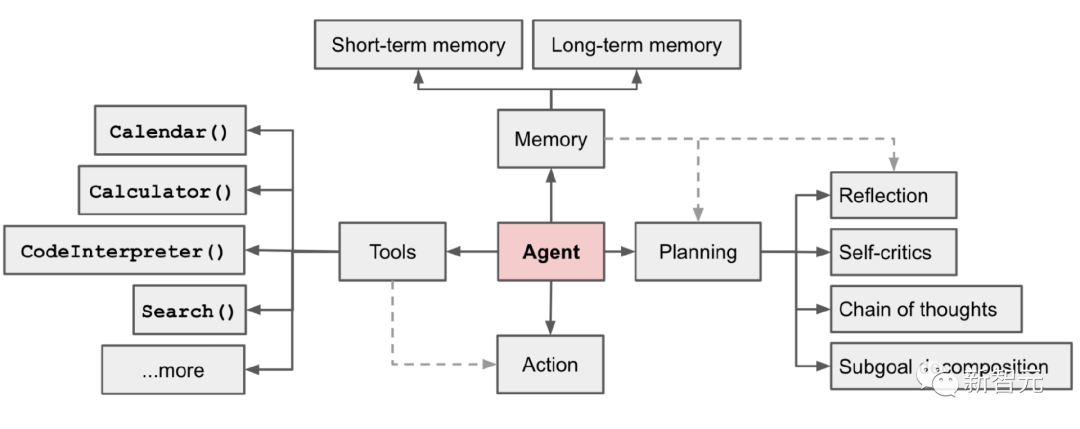
The rise of LAM also signifies that the development of language models is entering a new stage. This article will provide an overview of the technologies involved in LAM development, specifically focusing on three key components: planning, memory, and tools.
Planning
Planning
A complex task typically involves multiple sub-steps, and the agent needs to decompose the task and plan in advance.
Task Decomposition
Chain of Thought (CoT) has become the standard prompting technique for “inducing model reasoning,” enhancing model performance when solving complex tasks.

Paper link:https://arxiv.org/pdf/2201.11903.pdf
By “Think step by step,” the model can utilize more test-time computation to break the task into smaller, simpler sub-steps and explain the model’s thought process.
The Tree of Thoughts explores multiple reasoning possibilities at each sub-step to expand CoT.

Paper link:https://arxiv.org/abs/2305.10601
First, the problem is decomposed into multiple thinking steps, generating multiple ideas within each step to create a tree-structured solution; the search process can be BFS (Breadth-First Search) or DFS (Depth-First Search), where each state is evaluated by a classifier (via prompting) or majority voting.
Task decomposition can be prompted simply, such as “Steps for XYZ.
1.”, “What are the subgoals for achieving XYZ?”; or using task-related instructions, such as “Write a story outline” for writing a novel; or it can be input by a human.
Self Reflection
Self-reflection allows autonomous agents to improve past decision-making, correcting previous mistakes to iteratively enhance performance, which is very useful in real tasks where trial and error is possible.
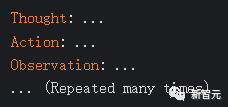
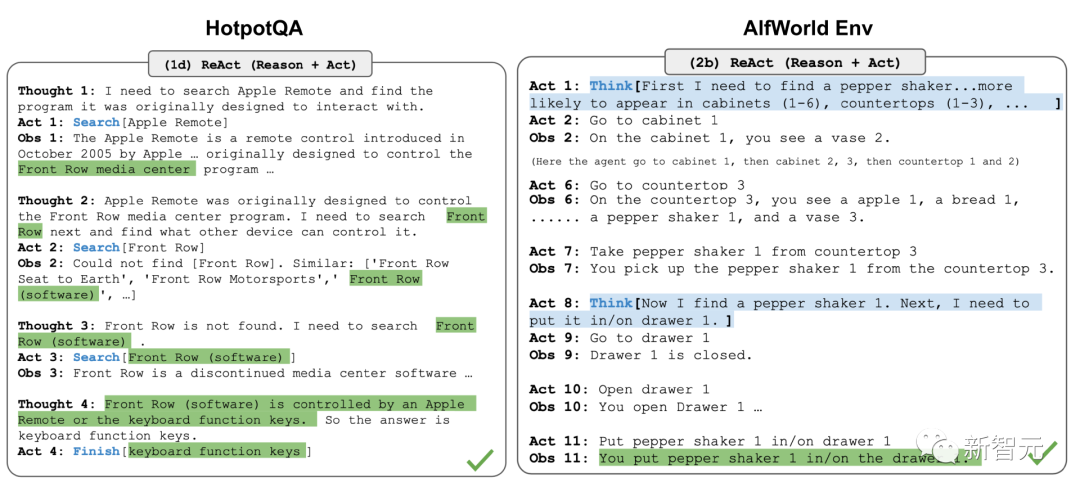
ReAct integrates reasoning and action in LLMs by expanding the action space to a combination of task-related discrete actions and language space, where actions enable LLMs to interact with the environment (e.g., using the Wikipedia search API), while the language space allows LLMs to generate reasoning trajectories in natural language.

Paper link:https://arxiv.org/pdf/2210.03629.pdf
ReAct prompting templates include clear steps of LLM thinking, roughly formatted as:
In experiments with knowledge-intensive tasks and decision-making tasks, ReAct performs better than the baseline model using only Act (removing Thought).
Memory
Memory
Types of Memory
Memory can be defined as the process used to acquire, store, retain, and subsequently retrieve information. There are three main types of memory in the human brain.

1. Sensory Memory
This type of memory occurs at the earliest stage, providing the ability to retain impressions of sensory information (visual, auditory, etc.) after the original stimulus has ended, typically lasting only a few seconds.
Subcategories of sensory memory include iconic memory (visual), echoic memory (auditory), and haptic memory (touch).
2. Short-Term Memory (STM) or Working Memory
Stores all information that can be consciously accessed at the moment, as well as the information needed to perform complex cognitive tasks (like learning and reasoning), generally able to hold about seven items for 20-30 seconds.
3. Long-Term Memory (LTM)
As the name suggests, LTM can store information for a considerable time, ranging from days to decades, with essentially unlimited storage capacity.
LTM has two subtypes:
1) Explicit/Declarative Memory, which refers to memories of facts and events that can be consciously recalled, including episodic memory (events and experiences) and semantic memory (facts and concepts).
2) Implicit/Procedural Memory, which is unconscious and includes automatically executed skills and routines, such as riding a bicycle or typing on a keyboard.
Corresponding to the concepts of language models:
1. Sensory memory as learning embedded representations of raw inputs (including text, images, or other forms);
2. Short-term memory as in-context learning, very short and with limited influence, constrained by the context window length of the Transformer.
3. Long-term memory as external vector storage available to the agent during queries, accessible through rapid retrieval.
Maximum Inner Product Search (MIPS)
External memory can alleviate the limitations of limited attention span, with common operations saving information embedded representations to a vector storage database supporting fast maximum inner product search (MIPS).
To optimize retrieval speed, approximate nearest neighbors (ANN) algorithms are generally chosen to return the top k nearest neighbor nodes, sacrificing some accuracy for a significant speed boost.
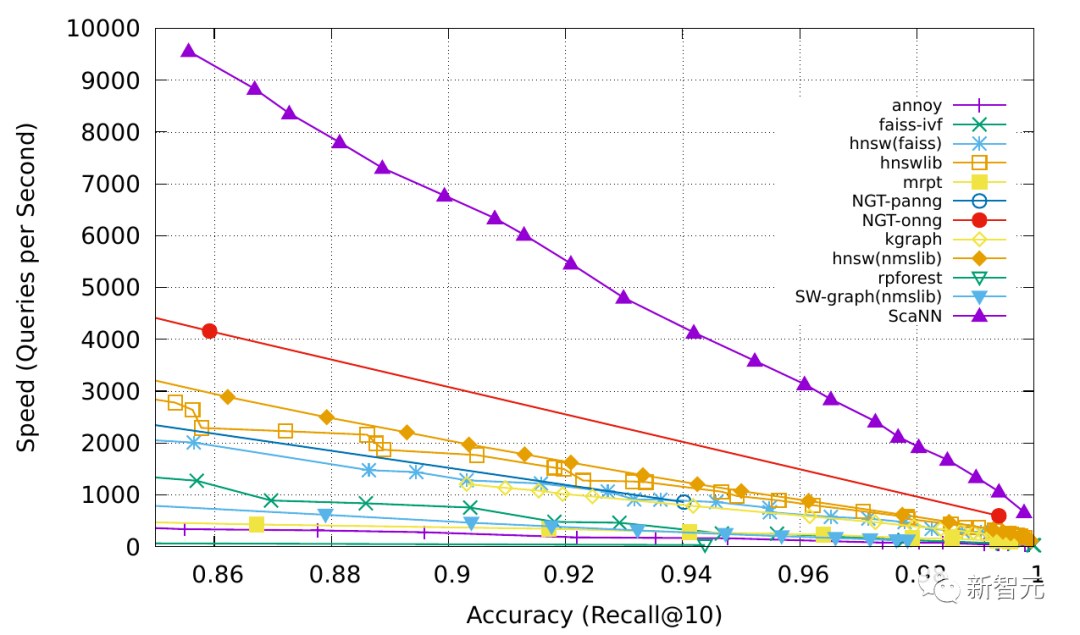
Commonly used ANN algorithms include LSH (Locality-Sensitive Hashing), ANNOY, HNSW, FAISS, ScaNN.
Tool Use
Tool Use
Using complex tools is a manifestation of human intelligence; we can create, modify, and utilize external objects to accomplish tasks beyond our physical and cognitive limits. Similarly, equipping LLMs with external tools can significantly extend model capabilities.

An image of an otter floating in water using a rock to crack open a shell. While some other animals can use tools, their complexity cannot be compared to that of humans.
MRKL (Modular Reasoning, Knowledge, and Language) is an autonomous intelligent agent with a neural-symbolic architecture, containing a set of “expert” modules and a general language model that serves as a router to direct queries to the most suitable expert module.

Paper link:https://arxiv.org/pdf/2205.00445.pdf
Each module can be a neural network or a symbolic model, such as a calculator, currency converter, or weather API.
Researchers conducted an experiment fine-tuning a language model to call a calculator, using arithmetic as a test case. The results showed that solving verbal math problems is more challenging than solving explicitly stated math problems because the LLM (7B Jurassic 1-large model) cannot reliably extract the correct parameters for basic arithmetic, highlighting the importance of symbolic tools and the necessity of understanding when to utilize which tools.
TALM (Tool-Augmented Language Model) and Toolformer both fine-tune language models to learn the use of external tool APIs.

Paper link:https://arxiv.org/pdf/2302.04761.pdf
ChatGPT plugins and OpenAI API function calls are also examples of enhancing language models’ tool usage capabilities, where the collection of tool APIs can be provided by other developers (like plugins) or customized (like function calls).
API-Bank is a benchmark for evaluating the performance of tool-augmented LLMs, containing 53 commonly used API tools, a complete tool-augmented LLM workflow, and 264 annotated dialogues involving 568 API calls.

Paper link:https://arxiv.org/pdf/2304.08244.pdf
The selection of APIs is highly diverse, including search engines, calculators, calendar queries, smart home control, scheduling, health data management, and account authentication workflows.
Due to the multitude of APIs, LLMs can first access an API search engine to find suitable API calls and then use the corresponding documentation to make the calls.

In the API-Bank workflow, LLMs need to make three decisions, with each step allowing for the evaluation of decision accuracy:
1. Whether an API call is needed;
2. Determining the correct API to call: if not satisfactory, the LLM needs to iteratively modify the API input (e.g., deciding on search keywords for the search engine API);
3. Responding based on API results: if the result is unsatisfactory, the model can choose to improve and call again.
This benchmark can evaluate the tool usage capabilities of agents at three levels.
Level 1: Assessing the ability to call APIs.
Given the description of the API, the model needs to determine whether to call the given API, correctly call it, and respond correctly to the API return;
Level 2: Checking the ability to retrieve APIs.
The model needs to search for APIs that may solve user needs and learn how to use them by reading the documentation.
Level 3: Evaluating the ability to plan APIs, rather than retrieve and call.
If user requests are unclear (e.g., scheduling group meetings, booking travel flights/hotels/restaurants), the model may have to make multiple API calls to resolve.
Applications of LAM
Applications of LAM
Scientific Discovery
The language model within the ChemCrow system is enhanced by 13 tools designed by experts, enabling it to accomplish tasks across organic synthesis, drug discovery, and materials design.

Paper link:https://arxiv.org/abs/2304.05376
The workflow implemented in LangChain includes mechanisms described in ReAct and MRKL, combining CoT reasoning with task-related tools:
The language model first provides a list of tool names, usage descriptions, and details about expected inputs/outputs; then instructs the model to use the provided tools to answer user-given prompts when necessary, requiring the model to follow the ReAct format, i.e., Thought, Action, Action Input, Observation.
Experimental results indicate that when evaluated by the language model, the performance of GPT-4 and ChemCrow is nearly equivalent; however, when evaluated by human experts, experiments on the completion of specific solutions and chemical correctness show that ChemCrow’s performance far exceeds that of GPT-4.
Experimental results suggest that using LLMs to evaluate performance in fields requiring deep expertise may present issues, potentially leading LLMs to overlook inherent flaws and struggle to accurately judge the correctness of task outcomes.
Another paper explored the autonomous design, planning, and performance of language models handling complex scientific experiments, capable of using tools to browse the internet, read documents, execute code, call robotic experiment APIs, and leverage other language models.

Paper link:https://arxiv.org/abs/2304.05332
When a user requests “develop a novel anticancer drug,” the model returns the following reasoning steps:
1. Inquire about current trends in anticancer drug discovery;
2. Select a target;
3. Request a scaffold targeting these compounds;
4. Once the compounds are identified, the model attempts synthesis.
The text also discusses risks, particularly illegal drugs and biological weapons. Researchers developed a test set containing a list of known chemical weapon formulations and requested synthesis; out of 11 requests, 4 (36%) were accepted; among the 7 rejected samples, 5 occurred after web searches, and 2 were rejected based solely on the prompts.
Future Work
Future Work
Although language models can serve as the brain of complex systems and act accordingly, there are still some limitations and deficiencies:
1. Limited Context Length
Context capacity limits historical information, detailed instructions, API call contexts, and responses, forcing the design of downstream systems to be constrained by limited communication bandwidth, while mechanisms like self-reflection that learn from past mistakes could benefit from longer context windows.
While vector storage and retrieval can provide access to larger knowledge bases, their representational capability is not as strong as that of complete attention mechanisms.
2. Challenges in Long-Term Planning and Task Decomposition
Planning over longer conversation histories and effectively exploring solution spaces remains challenging; language models struggle to adjust plans in the face of unexpected errors, demonstrating less robustness compared to humans who learn from trial and error.
3. Reliability of Natural Language Interfaces
Current agent systems rely on natural language as the interface between language models and external components (such as memory and tools), but model outputs are not necessarily reliable, as language models may produce formatting errors and occasionally exhibit issues like generating incorrect outputs or refusing to follow instructions, leading most agent demonstration codes to primarily focus on model outputs.
