
Click on the above “Little White Learns Vision” to choose to add “Star Mark” or “Pin”
Important content delivered at the first time
XGBoost is one of the most commonly used algorithms with relatively high accuracy in various data mining or machine learning competitions (excluding Deep Learning algorithms). In other words, for those who have just transitioned to the field of machine learning, after mastering the basic concepts of data mining, it is urgent to master the XGBoost algorithm to gain something in competitions.
1. Advantages of XGBoost Algorithm
XGBoost stands for Extreme Gradient Boosting. It is a C++ implementation of the Gradient Boosting Machine. Initially created to address the speed and accuracy limitations of existing libraries, XGBoost’s biggest feature is its ability to automatically utilize multi-threading on CPUs for parallel processing, while also improving accuracy through algorithmic enhancements [1].
The traditional GBDT (Gradient Boosted Decision Trees) model was proposed by Jerome Friedman in 1999, and Yahoo was the first to apply the GBDT model to CTR estimation. GBDT is a weighted regression model that boosts weak learners through iterations. Compared to LR, it does not require feature normalization, can automatically perform feature selection, has good model interpretability, and can adapt to various loss functions such as SquareLoss and LogLoss [2]. However, as a non-linear model, its shortcomings compared to linear models are quite obvious. Boosting is a serial process and cannot be parallelized, leading to higher computational complexity, and it is not well-suited for high-dimensional sparse features, typically using dense numerical features instead.
XGBoost differs from traditional GBDT by utilizing second-order derivative information. It performs a second-order Taylor expansion of the loss function and adds a regularization term to the objective function, seeking an optimal solution to balance the objective function and model complexity, thus preventing overfitting.
In addition to theoretical differences from traditional GBDT, XGBoost’s design philosophy includes the following key advantages:
-
Fast speed. It allows a program to occupy a machine when necessary and keeps running through all iterations to prevent the overhead of resource reallocation. It uses multi-threading for parallel acceleration within the machine, and inter-machine communication is based on the All Reduce synchronous interface implemented by Rabit.
-
Portable, less code. Most distributed machine learning algorithms are structured to distribute data, calculating local statistics on each subset, and then integrating to produce global statistics, which are then distributed to each computing node for the next round of iteration. Based on the algorithm’s requirements, reasonable interfaces such as All Reduce are abstracted and implemented across various platforms through the general Rabit library, allowing for effective distributed machine learning abstraction.
-
Fault-tolerant. The Rabit version of All Reduce has a good property that supports fault tolerance, while traditional MPI does not. Since each node ultimately receives the same result in All Reduce, this means that some nodes can remember the results, and when a node fails and restarts, it can directly request the results from the surviving nodes.
2. XGBoost Algorithm and Objective Function
The XGBoost algorithm is a tree-based Boosting algorithm that adds a regularization term to its optimization objective function. Its objective function is
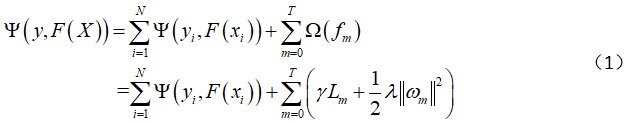
Where Lm represents the number of leaf nodes in the tree model fm generated in the mth iteration,
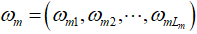
represents the output values of each leaf node of fm. Ƴ and λ are the regularization coefficients, and from the formula, it can be seen that these two values control the model’s complexity and the output of the objective function. When Ƴ and λ are both zero, it only contains the loss function part, meaning the size of the generated tree and the output values of the leaf nodes are not restricted. Adding the regularization term allows the algorithm to choose simple yet high-performing models fm, and the regularization term in the formula only suppresses overfitting of the weak learner fm(X) during the iteration process and does not participate in the final model integration. The term 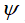 must at least be a twice continuously differentiable convex function.
must at least be a twice continuously differentiable convex function.
The XGBoost algorithm, like the Gradient Boosting algorithm, adopts a stepwise forward additive model, with the difference being that the Gradient Boosting algorithm learns a weak learner fm(X) to approximate the negative gradient of the loss function at point Pm-1=Fm-1(X), while the XGBoost algorithm first calculates the second-order Taylor approximation of the loss function at that point and then minimizes that approximate loss function to train the weak learner fm(X), resulting in
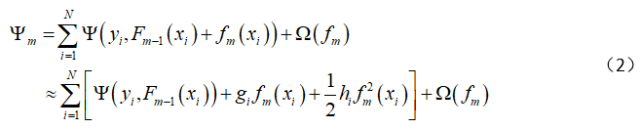
Where
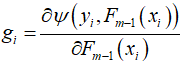
represents the first-order partial derivative of the loss function at point Pm-1(X),
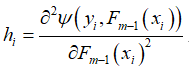
is the second-order partial derivative of the loss function at point Pm-1(X), using the above formula as the approximate optimization objective function. By transforming the above formula, we obtain
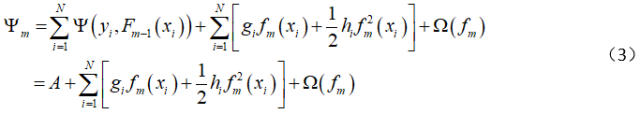
The first term in each iteration is constant and does not affect the result of the optimization objective function, so the final optimization objective function becomes
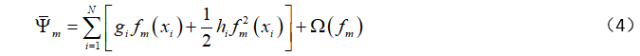
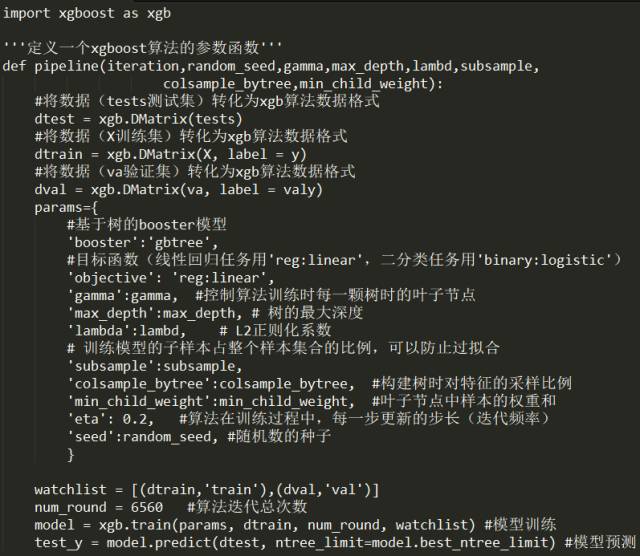
3. Specific Code Example
After discussing a lot of theory, let’s get to some practical content (side note, it’s best to understand the principles of each algorithm before applying it, so that you can adjust each parameter of the algorithm properly during use).
Python code:
References:
[1] Chen T, Guestrin C. Xgboost: A scalable tree boosting system[C]//Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016: 785-794.
[2] Friedman J H. Greedy function approximation: a gradient boosting machine[J]. Annals of statistics, 2001: 1189-1232.
Good News!
Little White Learns Vision Knowledge Planet
Is now open to the outside👇👇👇
Download 1: Chinese Version Tutorial for OpenCV-Contrib Extension Modules
Reply to “Chinese Tutorial for Extension Modules” in the backend of the “Little White Learns Vision” public account to download the first Chinese version of the OpenCV extension module tutorial, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: 52 Lectures on Python Vision Practical Projects
Reply to “Python Vision Practical Projects” in the backend of the “Little White Learns Vision” public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition to help quickly learn computer vision.
Download 3: 20 Lectures on OpenCV Practical Projects
Reply to “20 Lectures on OpenCV Practical Projects” in the backend of the “Little White Learns Vision” public account to download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. We currently have WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually subdivide in the future). Please scan the WeChat number below to join the group, noting: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format; otherwise, you will not be allowed in. After successful addition, you will be invited into the relevant WeChat group based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~