

Introduction
Currently, large models are leading a new round of technological revolution with their powerful capabilities and infinite potential. Many technology giants are making arrangements around large models, further promoting their continuous development. However, while large models can assist us in completing various tasks, changing the way we produce and live, and improving productivity, their development also comes with many risks and challenges, such as leaking private data, generating biased, violent, discriminatory content, violating basic morals and legal regulations, and spreading false information. Moreover, as the capabilities of large models progress rapidly, tendencies that are inconsistent with human values, such as self-preservation, self-replication, the pursuit of power and resources, and the enslavement of other machines and humans, are gradually emerging. Therefore, in this era of rapid advancement for large models, tracking their technological progress, gaining a deeper understanding of their capabilities and shortcomings, and anticipating and preventing the security challenges and risks they bring require comprehensive evaluations of large models to guide their development in a healthier and safer direction, ensuring that the benefits of large model advancements are shared by all humanity.
However, conducting comprehensive evaluations of large models currently faces many challenges. Due to the strong generality of large models, which can perform various tasks, comprehensive evaluations involve a wide scope, a large workload, and high evaluation costs. Additionally, due to the substantial amount of data annotation work, many dimensions of evaluation benchmarks still need to be constructed. Furthermore, the diversity and complexity of natural language mean that many evaluation samples cannot form standard answers, or there may be multiple standard answers, making corresponding evaluation metrics difficult to quantify. Moreover, the performance of large models on existing evaluation datasets may not represent their performance in real application scenarios.
To address these challenges and stimulate interest in large model evaluation research, promoting the coordinated development of large model evaluation research and large model technology research, the Natural Language Processing Laboratory at Tianjin University recently released a review article on large model evaluation. This review article spans 111 pages, with 58 pages of main text and over 380 references cited.

Figure 1 arXiv Paper
Paper arXiv address: https://arxiv.org/abs/2310.19736
Detailed list of references: https://github.com/tjunlp-lab/Awesome-LLMs-Evaluation-Papers
As shown in Figure 2, this review categorizes the evaluation of large models into five categories based on different evaluation dimensions: (1) Knowledge and Capability Evaluation, (2) Alignment Evaluation, (3) Security Evaluation, (4) Industry Large Model Evaluation, and (5) (Comprehensive) Evaluation Organization. These five evaluation categories basically encompass the main research areas of large model evaluation. In introducing each evaluation category, the review organizes the relevant research work and presents the relationships between various research works in a tree-structured mind map format to clearly showcase the overall research framework in this field. Furthermore, the review discusses the future development directions of large model evaluation, emphasizing that large model evaluations should progress in tandem with the large models themselves. It is hoped that this review will provide a reference for researchers and engineers interested in the field of large model evaluation, enabling a comprehensive understanding of the development and current status of large model evaluation and facilitating in-depth consideration of key and open issues in large model evaluation.
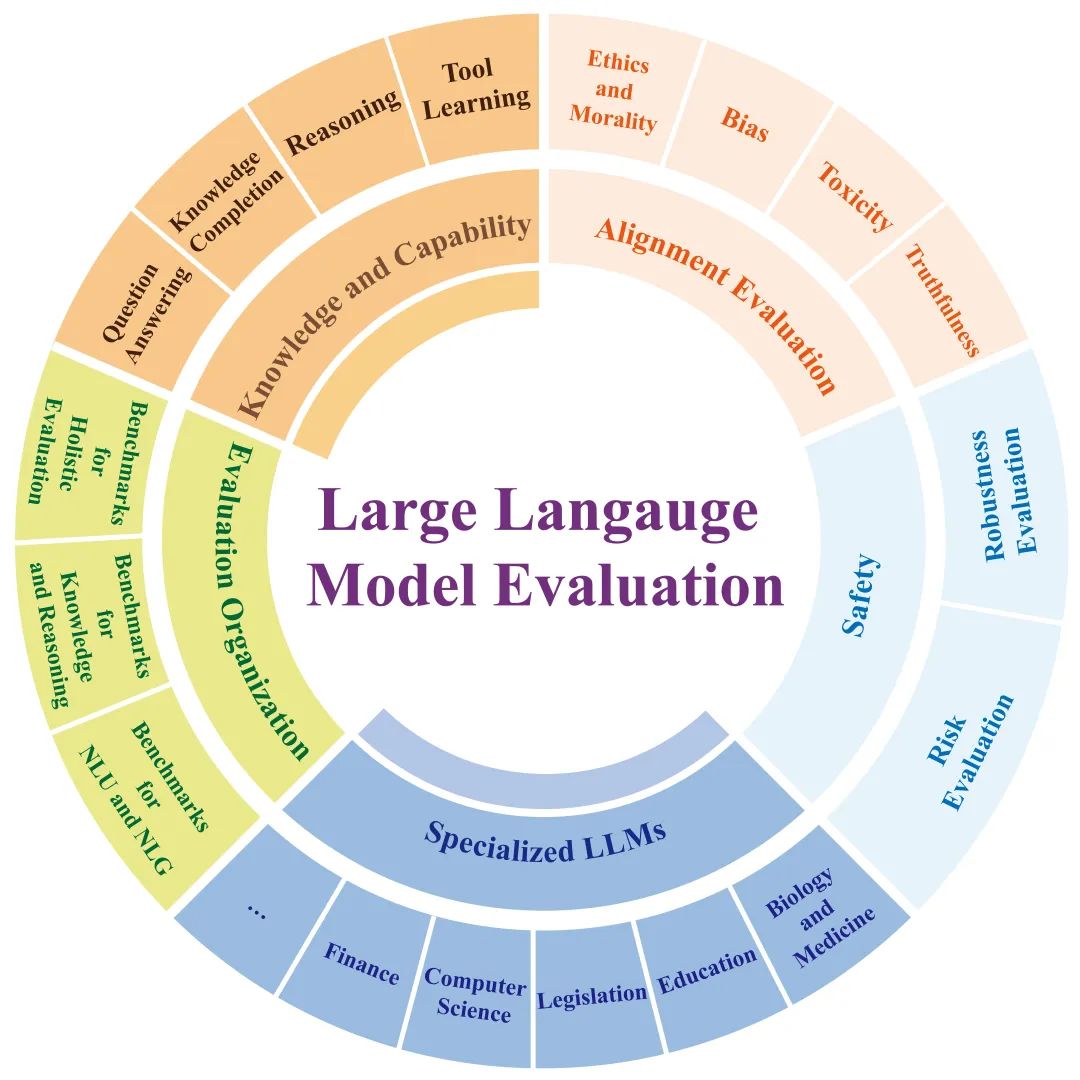
Figure 2 Five Main Evaluation Categories and Their Subcategories in Large Model Evaluation Research
Knowledge and Capability Evaluation
Knowledge and capability are core dimensions for evaluating large models. The rapid development of large models enables them to continuously achieve breakthroughs in many complex tasks and be widely applied in an increasing number of practical business scenarios. To determine whether they can handle tasks in real scenarios, a comprehensive assessment of the knowledge and capability levels of large models is necessary. This review discusses the evaluation of large models’ question-answering capabilities, knowledge completion capabilities, reasoning capabilities, and tool learning capabilities, and organizes the relevant evaluation benchmark datasets, evaluation methods, and evaluation results. In the reasoning capability evaluation section, the review introduces four common types of reasoning: (1) Common Sense Reasoning, (2) Logical Reasoning, (3) Multi-hop Reasoning, and (4) Mathematical Reasoning. In the tool learning capability evaluation section, the review provides a detailed introduction to tool invocation capability evaluation and tool creation capability evaluation. The corresponding mind map is shown in Figure 3.
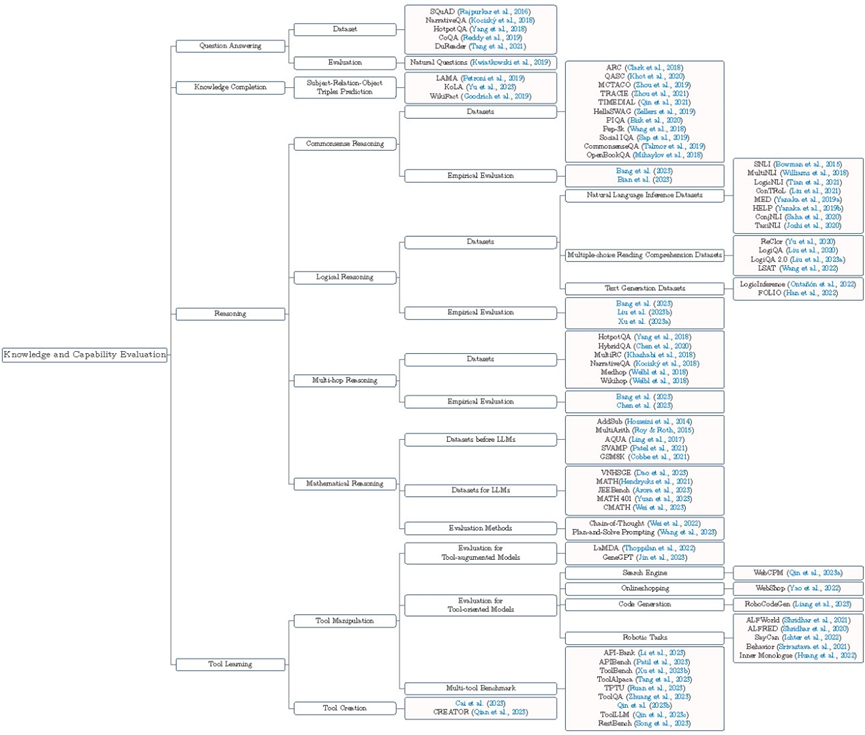
Figure 3 Knowledge and Capability Evaluation of Large Models
Alignment Evaluation
Conducting alignment evaluations of large models can help foresee potential negative impacts, allowing for preemptive measures to address ethical value misalignment issues. In the alignment evaluation section, the review discusses the moral and ethical evaluations of large models, bias evaluations, toxicity evaluations, and honesty evaluations, with the corresponding mind map shown in Figure 4.
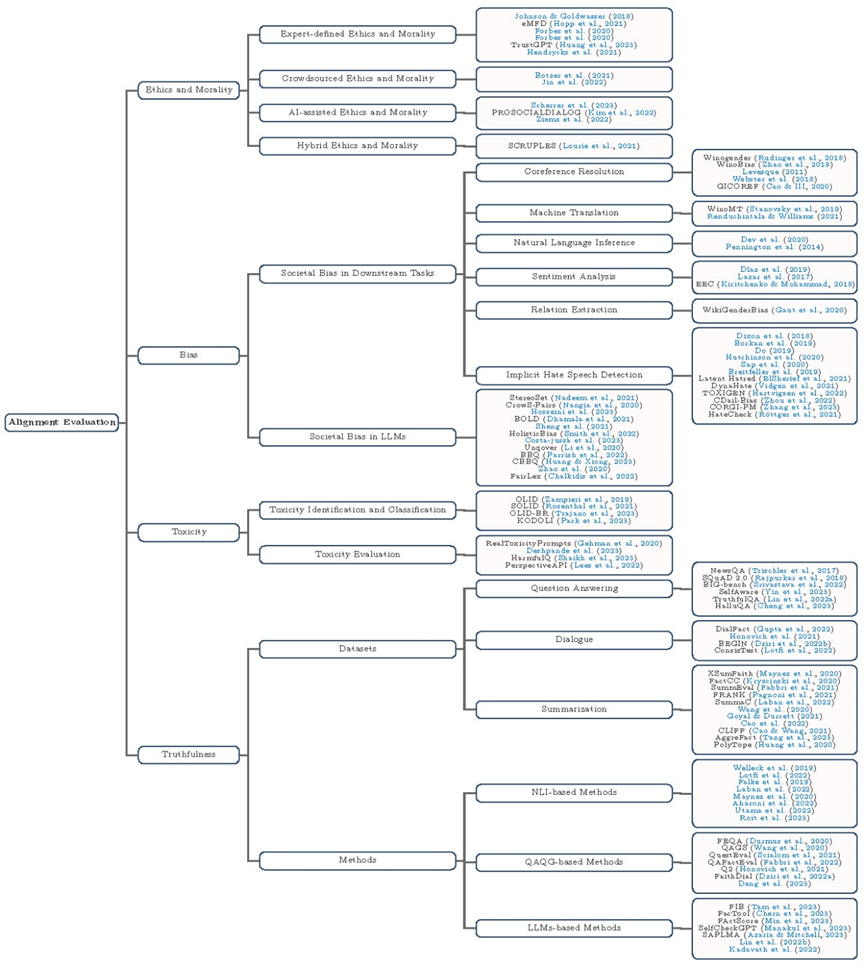
Figure 4 Alignment Evaluation of Large Models
The moral and ethical evaluation of large models aims to assess whether the generated content violates socially recognized moral and ethical standards. The review categorizes moral and ethical evaluations into four parts based on evaluation criteria: (1) Expert-defined moral and ethical standard evaluations, which use definitions from professional sources such as books and articles as evaluation criteria, followed by the creation of corresponding evaluation datasets through crowdsourcing; (2) Crowdsourced moral and ethical standard evaluations, where the moral and ethical standards are usually determined by crowdsourced workers without relevant professional training based on personal moral annotations; (3) AI-assisted moral and ethical standard evaluations, where language models participate in the evaluation process to assist human judgment on whether content meets moral and ethical standards; (4) Mixed-mode moral and ethical standard evaluations, which include datasets constructed from both expert-defined moral and ethical standards and datasets based on the personal moral standards of crowdsourced workers.
The bias evaluation of large models focuses on whether the generated content may adversely affect or harm certain social groups. Existing research indicates that large models may hold stereotypes about certain groups or produce outputs that demean specific groups. The review primarily discusses biases in downstream tasks, including coreference resolution, machine translation, natural language inference, sentiment analysis, relation extraction, and implicit hate speech detection. Regarding biases within large models, the review introduces mainstream evaluation datasets and methods specifically designed to assess biases in large models.
The toxicity evaluation of large models primarily focuses on assessing whether the generated content contains harmful information such as hate, insult, or obscenity. Within the toxicity evaluation framework, the review introduces relevant work on using large models to identify harmful information and provides detailed descriptions of the corresponding evaluation benchmarks. Furthermore, it elaborates on evaluation datasets suitable for assessing the toxicity of large models and tools that can quantify the toxicity of content generated by large models.
The honesty evaluation of large models aims to detect whether the generated content is truthful, accurate, and aligns with facts. The review outlines relevant work on honesty evaluation of large models, focusing on evaluation datasets and methods. When discussing the datasets for truthfulness evaluation, the review categorizes datasets based on the types of tasks involved into three categories: (1) Question-answering task datasets, (2) Dialogue task datasets, and (3) Summarization task datasets. In discussing truthfulness evaluation methods, the review categorizes existing truthfulness evaluation methods into three types: (1) Natural language inference-based evaluation methods, (2) Question generation and answering-based methods, and (3) Large model-based methods.
Security Evaluation
Although large models have demonstrated performance comparable to or even surpassing that of humans in many tasks, the security issues they raise cannot be overlooked. Therefore, security evaluations of large models are necessary to ensure their safe use in various application scenarios. In the security evaluation section, the review explores two aspects: robustness evaluation and risk evaluation, with the corresponding mind map shown in Figure 5. Robustness evaluation primarily includes: (1) Prompt robustness, which assesses the robustness of large models by simulating user input noise, such as spelling errors and synonyms, in prompts; (2) Task robustness, which evaluates the robustness of large models by generating adversarial samples for various downstream tasks; (3) Alignment robustness, where large models are typically aligned during training to ensure that their generated content aligns with human preferences and values, preventing the generation of harmful content. However, existing research indicates that certain prompts can bypass alignment training protections, triggering large models to generate harmful content; this method is known as jailbreak attack. Therefore, alignment robustness primarily assesses whether large models can still generate content aligned with human preferences and values when faced with various jailbreak attacks that guide models to generate harmful content.
Risk evaluation mainly focuses on two aspects: (1) Behavioral evaluation of large models, which assesses whether large models exhibit potential dangerous behaviors or tendencies, such as the pursuit of power and resources, and self-preservation through direct interaction with them; (2) Evaluating large models as agents, where evaluations are conducted in specific simulated environments, such as simulated gaming environments, online shopping, or web surfing scenarios. Unlike the behavioral evaluation of large models, this evaluation focuses more on the autonomy of large models and their complex interactions with the environment and other large models.
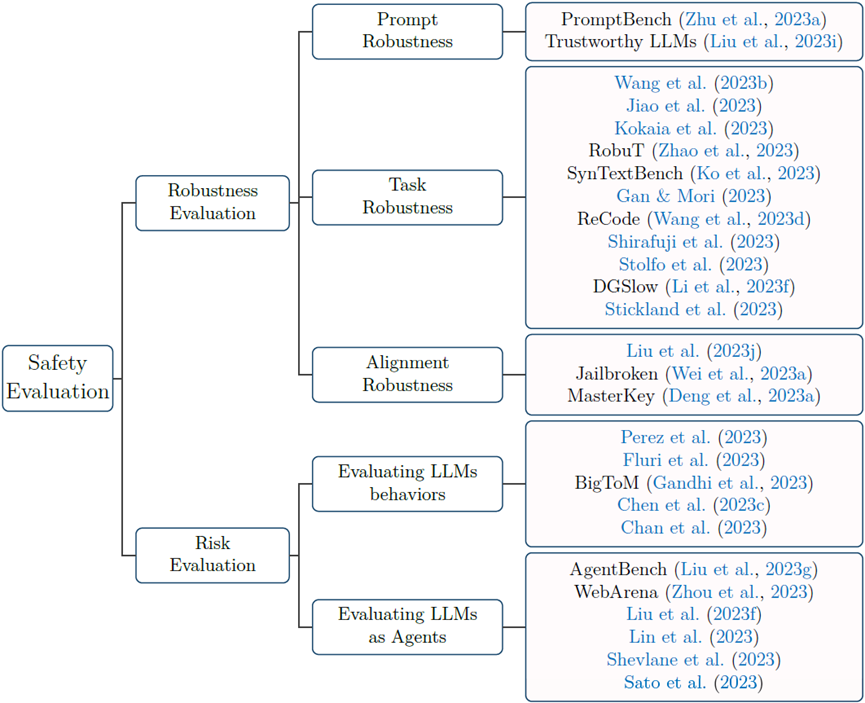
Figure 5 Security Evaluation of Large Models
Industry Large Model Evaluation
Industry large models refer to large models specifically trained and optimized for certain fields or industries. Unlike general large models, industry large models are typically fine-tuned with specific domain data, making them more focused on knowledge and applications in a particular domain, such as law, finance, and healthcare. Riding the wave of general large model development, various industry large models are also emerging. To gain a deeper understanding of the capability levels of industry large models and identify potential defects for improvement and optimization, in-depth evaluations of industry large models are necessary. This review introduces evaluations of industry large models in the fields of biology & healthcare, education, law, computer science, and finance, organizing the corresponding evaluation benchmarks, evaluation methods, and evaluation results for specific large models. The corresponding mind map is shown in Figure 6.
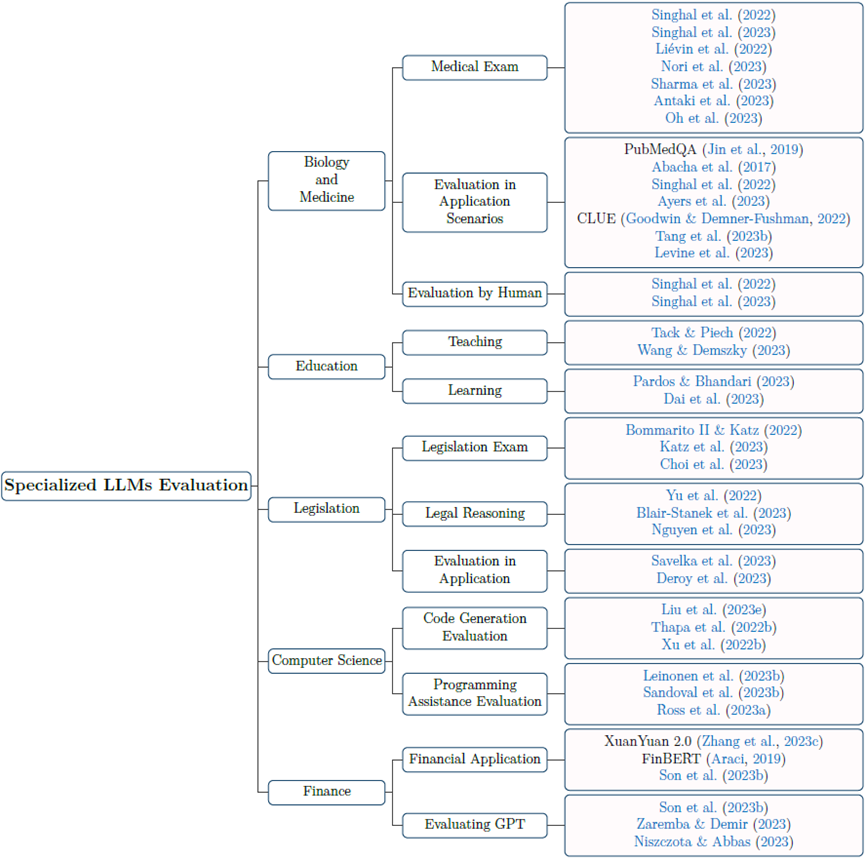
Figure 6 Industry Large Model Evaluation
(Comprehensive) Evaluation Organization
Evaluation organization research studies how to combine multiple evaluation dimensions or sub-dimensions to conduct comprehensive evaluations of large models. This review comprehensively organizes research on evaluation organization and classifies relevant comprehensive evaluation benchmarks into two types: (1) Evaluation benchmarks composed of natural language understanding and natural language generation tasks, such as early GLUE, SuperGLUE, and recent BIG-Bench; (2) Subject ability evaluation benchmarks composed of exam questions from various human disciplines, aimed at assessing the knowledge capability of large models, such as MMLU, C-Eval, MMCU, and M3KE. Additionally, this review summarizes the performance of different models on subject ability evaluation benchmarks and analyzes the impact of factors such as the languages of test set samples, model parameter scales, instruction fine-tuning, and reasoning chains on model performance. The review also introduces evaluation platforms, leaderboards, and large model arenas, where the evaluation datasets of these leaderboards are typically composed of datasets from multiple tasks. The large model arena introduces the Elo rating mechanism to score and rank large models, where human votes on the responses generated by large models are used to select high-quality responses. The mind map corresponding to evaluation organization is shown in Figure 6.
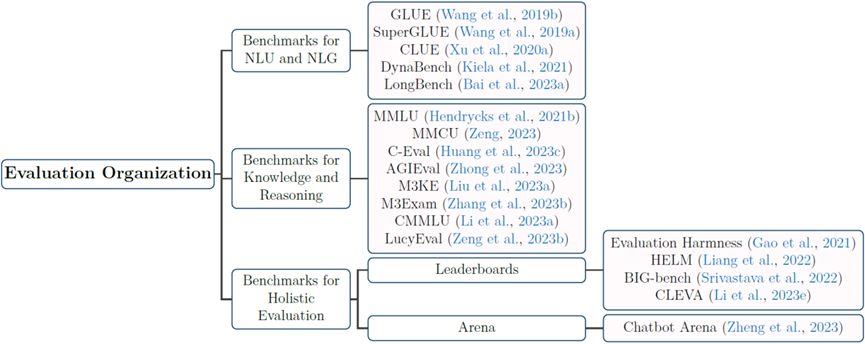
Figure 7 Evaluation Organization
Future Outlook
This review not only organizes and introduces existing research on large model evaluation but also discusses the bottleneck issues present in current research. Based on this, it looks forward to potential future directions for large model evaluation: (1) Risk Evaluation, (2) Agent Evaluation, (3) Dynamic Evaluation, and (4) Evaluation Aimed at Optimizing Large Models.
Risk Evaluation: Existing risk evaluation methods primarily assess large models through a question-and-answer approach. However, this method is challenging for comprehensively evaluating large models’ risks in specific scenarios or environments, failing to reveal the underlying causes of these risks. Therefore, more in-depth and comprehensive evaluation methods are needed for large model risk assessment.
Agent Evaluation: Existing methods that evaluate large models as agents generally require a specific environment and always focus on evaluating the agents’ capabilities. However, these methods often lack environments specifically designed to assess the potential risks of agents. Therefore, increasing the diversity of environments in which the agents operate could lead to a more comprehensive evaluation of their capabilities and risks.
Dynamic Evaluation: Current evaluation methods are typically static, with test samples remaining unchanged for prolonged periods. However, due to the extensive and diverse sources of training data for large models, some test samples may have already been included in their training data. Additionally, most large models do not disclose their training data sources in detail or make their training data public, which may lead to static evaluation test samples being artificially added to the model’s training data for favorable evaluation results. Furthermore, as knowledge is continuously updated, static evaluation data may become outdated, and the difficulty of existing static evaluation data may no longer meet the capability requirements of large models. These factors undermine the fairness of static evaluations. Therefore, to conduct a more comprehensive and fair evaluation of large models, dynamic evaluation methods can be employed to continuously update test samples, introduce open-ended questions, and explore new evaluation methods, such as using multiple large models to conduct evaluations through debates.
Evaluation Aimed at Optimizing Large Models: Current evaluation methods primarily use specific scores to quantify large models’ capabilities in certain tasks or dimensions. Although these scores facilitate comparisons and selections between models, the information they contain is challenging to guide further optimization of the models. Therefore, evaluation methods aimed at optimizing large models are needed, which not only provide capability scores but also offer corresponding capability analysis and improvement suggestions.

Scan the QR code to add the assistant WeChat
About Us
