
 Image Source: pixabay
Image Source: pixabay
Written by | Sun Ruichen
Edited by | Li Shanshan
Today, large pre-trained language models like ChatGPT have become well-known names. However, the algorithmic core behind GPT, the artificial neural network algorithm, has experienced an 80-year roller coaster ride. During these 80 years, apart from a few explosive moments, the theory remained dormant and neglected for most of the time, even considered a “poison” for funding.
The birth of artificial neural networks came from the brilliant combination of Peter and the renowned neurophysiologist McCulloch. However, their theory surpassed the technological level of their time and thus failed to gain widespread attention and empirical validation.
Fortunately, in the first twenty years after its inception, researchers continuously contributed to the field, evolving from the simplest mathematical models of neurons and learning algorithms to perceptron models with learning capabilities. However, challenges from other researchers and the tragic fate of one of the founders of the perceptron, Rosenblatt, led to a more than twenty-year winter for the field until the introduction of the backpropagation algorithm into the training process of artificial neural networks.
After that, following a twenty-year silence, research in artificial neural networks finally restarted. In the nearly twenty years of accumulation, convolutional neural networks and recurrent neural networks emerged sequentially.
However, the rapid development of the field in academia and industry had to wait until 17 years ago, with the breakthrough in hardware—the emergence of general-purpose computing GPU chips. Thus, today, large pre-trained language models like ChatGPT have become widely recognized.
In a sense, the success of artificial neural networks is a stroke of luck because not all research can wait for core breakthroughs and everything to be in place. In many fields, technological breakthroughs occur too early or too late, leading to slow extinction. However, within this luck, the steadfastness and persistence of the researchers involved cannot be overlooked. Thanks to their idealism, artificial neural networks have traversed their roller coaster ride of 80 years and finally achieved success.
McCulloch-Pitts Neuron
In 1941, Warren Sturgis McCulloch moved to the University of Chicago Medical School to serve as a professor of neurophysiology. Shortly after moving to Chicago, a friend introduced him to Walter Pitts. Pitts, who was pursuing his Ph.D. at the University of Chicago, shared a common interest in neuroscience and logic with McCulloch, and the two quickly became like-minded friends and partners in research. Naturally curious, Pitts had read Russell and Whitehead’s “Principia Mathematica” at the age of 12 and wrote to Russell pointing out several errors in the book. Russell appreciated the young reader’s letter and invited him to study at Cambridge University (even though Pitts was only 12 years old). However, Pitts’s family had a low level of education and could not understand his thirst for knowledge, often responding with harsh words. The relationship between Pitts and his family deteriorated, and he left home at the age of 15. From then on, Pitts became a wanderer on the University of Chicago campus, auditing his favorite university courses during the day and finding a classroom to sleep in at night. When Pitts met McCulloch, he was already a registered Ph.D. student but still had no fixed residence. Upon learning of this situation, McCulloch invited Pitts to live with him.
By the time they met, McCulloch had published several papers on the nervous system and was a well-known expert in the field. Although Pitts was still a Ph.D. student, he had already made achievements in mathematical logic and gained recognition from prominent figures in the field, including von Neumann. Despite their very different professional backgrounds, both were deeply interested in how the brain works and firmly believed that mathematical models could describe and simulate brain functions. Driven by this common belief, they collaborated on several papers and established the first artificial neural network model. Their work laid the foundation for modern artificial intelligence and machine learning, and they are recognized as pioneers in the fields of neuroscience and artificial intelligence.
In 1943, McCulloch and Pitts proposed the earliest artificial neural network model: the McCulloch-Pitts neuron model[1]. This model aimed to simulate the workings of neurons using the binary switch mechanism of “on” and “off”. The main components of the model include: input nodes that receive signals, intermediate nodes that process input signals through preset thresholds, and output nodes that generate output signals. In their paper, McCulloch and Pitts demonstrated that this simplified model could be used to implement basic logic operations (such as “and”, “or”, “not”). Additionally, the model could also solve simple problems such as pattern recognition and image processing.
Hebbian Learning
(Hebbian Learning)
In 1949, Canadian psychologist Donald Hebb published a book titled “The Organization of Behavior” and proposed the famous Hebbian Learning theory[2]. This theory posits that “neurons that fire together, wire together”, meaning that neurons exhibit synaptic plasticity (synapses are the key sites for information transmission between neurons) and that synaptic plasticity is the basis for the brain’s learning and memory functions.
A key step in machine learning theory is how to use different update algorithms to update models. When using neural network models for machine learning, the initial architecture and parameters of the model must be set. During the model training process, each input from the training dataset causes the model to update its parameters. This process requires the use of an update algorithm. The Hebbian Learning theory provided the initial update algorithm for machine learning: Δw = η x xpre x xpost. Δw represents the change in the parameters of the synaptic model, η is the learning rate, xpre is the activity level of the presynaptic neuron, and xpost is the activity level of the postsynaptic neuron.
The Hebbian update algorithm provides a theoretical basis for using artificial neural networks to mimic the behavior of the brain’s neural networks. The Hebbian learning model is an unsupervised learning model that achieves learning objectives by adjusting the strength of the connections it perceives between input data. Because of this, the Hebbian learning model is particularly adept at clustering analysis of subcategories within input data. As research into neural networks deepened, the Hebbian learning model was later found to be applicable to reinforcement learning and several other subfields.
In 1957, American psychologist Frank Rosenblatt first proposed the perceptron model and introduced the perceptron update algorithm[3]. The perceptron update algorithm extended the basis of the Hebbian update algorithm by utilizing iteration and trial-and-error processes for model training. During model training, the perceptron model calculates the difference between the predicted output value of the model and the actual measured output value for each new data point, and then uses this difference to update the coefficients in the model. The specific equation is as follows: Δw = η x (t – y) x x. After proposing the initial perceptron model, Rosenblatt continued to explore and develop theories related to the perceptron. In 1959, he successfully developed a neural computer called Mark1 that used the perceptron model to recognize English letters.
The perceptron model, like the McCulloch-Pitts neuron, is based on a biological model of neurons, receiving input signals, processing input signals, and generating output signals as its basic operating mechanism. The difference between the perceptron model and the McCulloch-Pitts neuron model is that the latter’s output signal can only be 0 or 1—exceeding a preset threshold yields 1, otherwise 0—while the perceptron model uses a linear activation function, allowing the model’s output value to vary continuously like the input signal. Additionally, the perceptron assigns coefficients to each input signal, which can affect the degree to which each input signal influences the output signal. Finally, the perceptron is a learning algorithm because its coefficients can be adjusted based on the data it encounters; whereas the McCulloch-Pitts neuron model lacks such coefficients, preventing its behavior from dynamically updating based on data feedback.
In 1962, Rosenblatt compiled years of research on the perceptron model into a book titled “Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms”. The perceptron model represented a significant advancement in artificial intelligence, as it was the first algorithmic model with learning capabilities that could autonomously learn patterns and characteristics from the data it received. Moreover, it possessed the ability to classify patterns, automatically categorizing data based on its features. Additionally, the perceptron model is relatively simple and requires fewer computational resources.
Despite its various advantages and potential, the perceptron is ultimately a relatively simplified model with many limitations. In 1969, computer scientists Marvin Minsky and Seymour Papert published the book “Perceptrons”[5]. In this book, the authors critically analyzed the perceptron model and the limitations of single-layer neural networks, including but not limited to the implementation of “XOR” logic and linear separability issues. However, both authors and Rosenblatt had already recognized that multi-layer neural networks could address the problems that single-layer networks could not solve. Unfortunately, the negative evaluations in the book had a significant impact, causing public and governmental interest in perceptron research to wane. In 1971, Rosenblatt, the proponent and primary supporter of the perceptron theory, tragically died in a sailing accident at the age of 43. Following the dual blows of the book “Perceptrons” and Rosenblatt’s death, the number of papers published related to perceptrons rapidly declined, and the development of artificial neural networks entered a “winter” period.

Perceptron Model
Image source: towardsdatascience.com
Multi-layer neural networks can solve problems that single-layer networks cannot, but they bring new challenges: updating the weights of each neuron in a multi-layer neural network involves a significant amount of precise calculations, and traditional computational methods are time-consuming and labor-intensive, resulting in poor practicality for the learning process of neural networks.
To address this issue, American sociologist and machine learning engineer Paul Werbos proposed the backpropagation algorithm in his 1974 Harvard doctoral thesis titled “Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences”[6]. The fundamental idea of this algorithm is to adjust the weights of each neuron in the neural network by propagating the error between the predicted output and the actual output back from the output layer. The essence of this algorithm is to implement training of the neural network composed of multi-layer perceptrons through backpropagation (along the negative gradient direction) based on the chain rule commonly used in calculus.
Regrettably, Werbos’s thesis did not receive sufficient attention for a long time after its publication. It wasn’t until 1985 that psychologists David Rumelhart and Geoffrey Hinton, along with computer scientist Ronald Williams, published a paper on the application of the backpropagation algorithm in neural networks[7]. This paper received significant attention in the field of artificial intelligence. The ideas presented by Rumelhart and his colleagues were essentially similar to Werbos’s, but they did not cite Werbos’s thesis, which has been criticized in recent years.
The backpropagation algorithm plays a crucial role in the development of artificial neural networks and enables the training of deep learning models. Since the backpropagation algorithm regained attention in the 1980s, it has been widely applied to train various neural networks. In addition to the original multi-layer perceptron networks, the backpropagation algorithm is also applicable to convolutional neural networks, recurrent neural networks, and more. Due to its importance, Werbos, Rumelhart, and others are regarded as pioneers in the field of neural networks.
In fact, the backpropagation algorithm is a significant achievement of the “Renaissance” period in artificial intelligence (during the 1980s and 1990s). The primary methodology during this period was parallel distributed processing, which focused on multi-layer neural networks and advocated for accelerating the training process and application of neural networks through parallel computing. This was a departure from the mainstream ideas in the field of artificial intelligence at the time, making it revolutionary. Additionally, this methodology received acclaim from scholars in various fields beyond computer science, including psychology, cognitive science, and neuroscience. Therefore, this period is often regarded as the Renaissance of artificial intelligence.
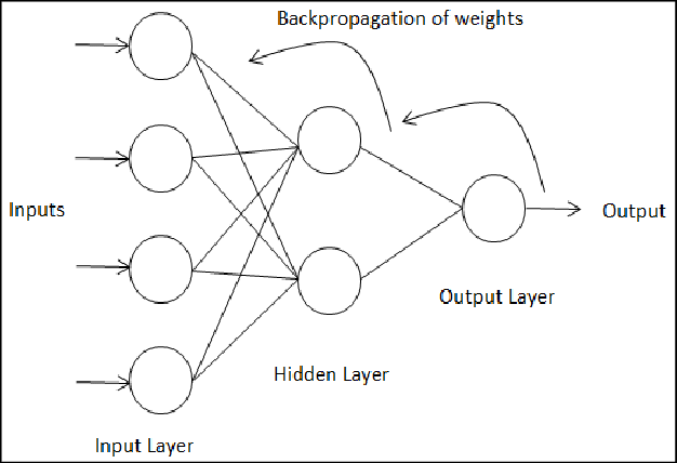
Principle of Backpropagation Algorithm
Image source: www.i2tutorials.com
Convolutional Neural Networks
(Convolutional Neural Network, CNN)
If we consider the McCulloch-Pitts neuron as the birthmark of artificial intelligence, then the United States can be said to be the birthplace of artificial neural networks. For thirty years after the birth of artificial neural networks, the United States played a leading role in the field of artificial intelligence, giving rise to key technologies such as the perceptron and the backpropagation algorithm. However, during the first “winter” of artificial intelligence, various parties in the United States, including the government and academia, lost confidence in the potential of artificial neural networks, significantly slowing support and investment in the iterative development of neural network technology. Consequently, during this “winter” that swept the United States, research in artificial neural networks in other countries came into the spotlight of historical development. Convolutional neural networks and recurrent neural networks emerged in this context.
Convolutional neural networks are a type of multi-layer neural network model that includes unique structures such as convolutional layers, pooling layers, and fully connected layers. This model uses convolutional layers to extract local features from input signals, then reduces the dimensionality and complexity of the data through pooling layers, and finally converts the data into a one-dimensional feature vector to generate output signals (typically predictions or classification results) through fully connected layers. The unique structure of convolutional neural networks makes them particularly advantageous for processing data with grid-like structures (such as images and time series).
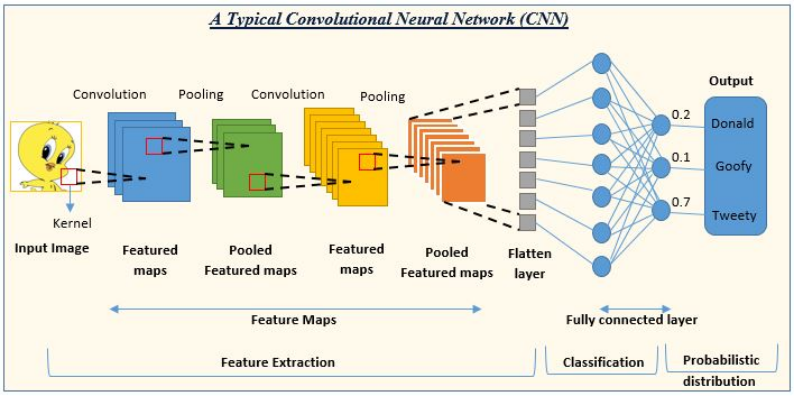 Convolutional Neural Network
Convolutional Neural Network
Image source: https://www.analyticsvidhya.com/blog/2022/01/convolutional-neural-network-an-overview/
The earliest convolutional neural network was proposed in 1980 by Japanese computer scientist Kunihiko Fukushima[8]. Fukushima’s model included convolutional layers and down-sampling layers, which are still utilized in today’s mainstream convolutional neural network structures. The only difference between Fukushima’s model and today’s convolutional neural networks is that the former did not use the backpropagation algorithm— as previously mentioned, the backpropagation algorithm did not gain attention until 1986. Due to the lack of this algorithm, Fukushima’s convolutional neural network model faced challenges similar to other multi-layer neural networks of the time, including long training times and computational complexity.
In 1989, Yann LeCun, a French computer scientist at Bell Labs, and his team proposed a convolutional neural network model named LeNet-5 and used the backpropagation algorithm for training[9]. LeCun demonstrated that this neural network could be used to recognize handwritten digits and characters. This marked the beginning of the widespread application of convolutional neural networks in image recognition.
Recurrent Neural Networks
(Recursive Neural Network, RNN)
Like convolutional neural networks, recurrent neural networks also possess unique structural characteristics. The main structural feature of these neural networks is that they have recursive relationships between layers rather than sequential relationships. Due to these special structural characteristics, recurrent neural networks are particularly well-suited for processing natural language and other text data.
In 1990, American cognitive scientist and psycholinguist Jeffrey Elman proposed the Elman network model (also known as the simplified recurrent network)[10]. The Elman network model was the first recurrent neural network, demonstrating that recurrent neural networks could maintain the sequential nature of data during training, laying the groundwork for the future application of such models in natural language processing.
Recurrent neural networks face the issue of vanishing gradients. When training neural networks using the backpropagation algorithm, the weight update gradients for layers close to the input gradually approach zero, causing these weights to change very slowly and leading to poor training results. To address this problem, in 1997, German computer scientist Sepp Hochreiter and his doctoral advisor Jürgen Schmidhuber proposed the long short-term memory network (LSTM)[11]. This model is a special type of recurrent neural network that introduces memory nodes, allowing the model to retain information over the long term, thereby alleviating the vanishing gradient problem. This model remains one of the most widely used recurrent neural network models today.
General-Purpose Computing GPU Chips
In 2006, American company NVIDIA launched the first general-purpose computing GPU (graphics processing unit) chip named CUDA (Compute Unified Device Architecture). Prior to this, GPUs were designed specifically for graphics rendering and computation, commonly used in applications related to computer graphics (such as image processing, real-time rendering of game scenes, video playback, and processing). CUDA allows for general-purpose parallel computing, enabling tasks that could only be performed by the CPU (central processing unit) to be computed by the GPU. The powerful parallel computing capabilities of GPUs allow them to execute multiple computational tasks simultaneously and perform calculations faster than CPUs, making them suitable for matrix operations. Training neural networks often requires extensive matrix and tensor computations. Before the emergence of general-purpose GPUs, the development of artificial neural networks had long been limited by the limited computational capabilities of traditional CPUs. These limitations affected both theoretical research innovation and the productization and industrialization of existing models. The advent of GPUs significantly alleviated these constraints.
In 2010, Dan Ciresan, a postdoctoral researcher on the team of Schmidhuber, achieved significant acceleration in training convolutional neural networks using GPUs[12]. However, GPUs truly gained fame in the field of artificial neural networks in 2012. That year, Canadian computer scientists Alex Krizhevsky, Ilya Sutskever, and the previously mentioned Geoffrey Hinton proposed the AlexNet model[13]. The AlexNet model is essentially a type of convolutional network. Krizhevsky and others used GPUs during model training and entered their model into a prestigious international image classification and tagging competition (ImageNet ILSVRC). Unexpectedly, their model won the championship by a large margin. The success of the AlexNet model significantly stimulated interest and attention from various sectors regarding the application of artificial neural networks in computer vision.
Generative Neural Networks and Large Language Models
Recurrent neural networks can generate text sequences word by word, making them often regarded as early generative neural network models. However, although recurrent neural networks are adept at processing and generating natural language data, they have struggled to effectively capture global information in long sequence data (making connections between distant information).
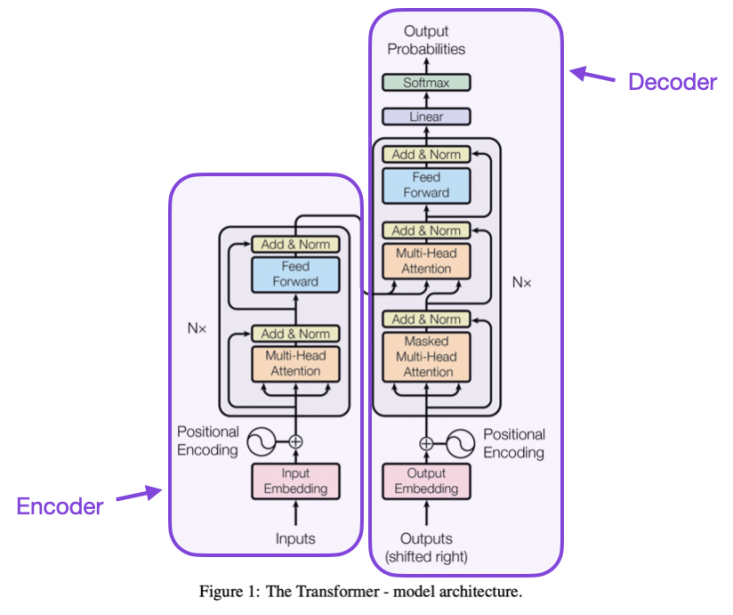
Transformer Model Image Source:[14]
In 2017, researchers at Google, led by Ashish Vaswani, proposed the transformer model[14]. This large neural network is divided into two main parts: the encoder and the decoder. The encoder processes the input sequence and further processes the encoded information through self-attention layers. Subsequently, the information is passed to the decoder, which generates the output sequence through the network structure of the decoder’s self-attention layers. The model’s significant innovation lies in the self-attention layer. The self-attention layer allows the neural network model to overcome the limitations of sequential text processing and directly capture information from different positions in the text while identifying dependencies between information from various locations. The emergence of the transformer model has had a tremendous impact on the field of natural language processing and the entire artificial intelligence domain. In just a few years, the transformer model has been widely used in various large AI models.
Among the many large language models based on the transformer structure, OpenAI’s chatbot ChatGPT is the most famous. The language model underlying ChatGPT is GPT-3.5 (Generative Pre-trained Transformer-3.5). OpenAI used a vast amount of corpus data to train this model, enabling it to possess extensive language understanding and generation capabilities, including providing information, communication, text creation, completing software code writing, and easily handling various language comprehension-related exams.
Conclusion
A few weeks ago, I participated in a volunteer event where middle school students shared lunch with researchers. During the event, I chatted with several fifteen- and sixteen-year-old students. Naturally, we talked about ChatGPT. I asked them, “Do you use ChatGPT? You can tell me the truth; I won’t tell your teachers.” One boy shyly smiled and said he couldn’t live without ChatGPT now.
80 years ago, the wandering Pitts could only imagine a mathematical model that could simulate brain functions. Today, in the world of young people, neural networks are no longer just elusive mathematical formulas; they have become ubiquitous. What will happen in the next 80 years? Will artificial neural networks develop consciousness like human neural networks? Will carbon-based brains continue to dominate silicon-based brains? Or will silicon-based brains take over?
1.Warren S. McCulloch and Walter Pitts. “A Logical Calculus of Ideas Immanent in Nervous Activity.” The Bulletin of Mathematical Biophysics, vol. 5, no. 4, 1943, pp. 115-133.
2.Donald O. Hebb. “The Organization of Behavior: A Neuropsychological Theory.” Wiley, 1949.
3.Frank Rosenblatt. “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain.” Psychological Review, vol. 65, no. 6, 1958, pp. 386-408.
4.Frank Rosenblatt. “Principles of Neurodynamics: Perceptrons and the theory of brain mechanisms.” MIT Press, 1962.
5.Marvin Minsky and Seymour Papert. “Perceptrons: An Introduction to Computational Geometry.” MIT Press, 1969.
6.Paul Werbos. “Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences.” Harvard University, 1974.
7.David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. “Learning representations by back-propagating errors.” Nature, vol. 323, no. 6088, 1986, pp. 533-536.
8.Kunihiko Fukushima. “Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.” Biological Cybernetics, vol. 36, no. 4, 1980, pp. 193-202.
9.Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE, vol. 86, no. 11, 1998, pp. 2278-2324.
10.Jeffrey L. Elman. “Finding Structure in Time.” Cognitive Science, vol. 14 1990, pp. 179-211.
11.Sepp Hochreiter and Jürgen Schmidhuber. “Long Short-Term Memory.” Neural Computation, vol. 9, no. 8, 1997, pp. 1735-1780.
12.Dan C. Ciresan, Ueli Meier, Luca Maria Gambardella, and Jürgen Schmidhuber. “Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition.” Neural Computation, vol. 22, no. 12, 2010, pp. 3207-3220.
13.Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. “ImageNet Classification with Deep Convolutional Neural Networks.” Advances in Neural Information Processing Systems, 2012, pp. 1097-1105.
14.Vaswani, Ashish, et al. “Attention is All You Need.” Advances in Neural Information Processing Systems, 2017, pp. 5998-6008.