Click belowCard, follow the “CVer” public account
AI/CV heavy content, delivered first-hand
Introduction
University of Science and Technology of China & MSRA analyzed the characteristics of three major neural network architectures, comparing CNN, Transformer, and MLP by constructing a unified architecture called SPACH, concluding that multi-stage models are always superior to single-stage models.

A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
Paper link: https://arXiv.org/abs/2108.13002
This article presents in-depth thoughts from USTC & MSRA regarding the ongoing disputes among the three major factions of DNN: CNN, Transformer, and MLP. To analyze the characteristics of different architectures, the authors first constructed a unified architecture, SPACH, making Mixing configurable. Based on this, they discovered that multi-stage is superior to single-stage, local modeling is very important, and the complementarity of CNN and Transformer. A hybrid model combining CNN and Transformer was built based on the extracted characteristics, achieving 83.9% top-1 accuracy on the ImageNet dataset with only 63M parameters, outperforming Swin-B and CaiT-S36.
Abstract
CNN dominates the CV field, while Transformer and MLP have recently begun to lead new trends in ImageNet classification tasks.
This article conducts empirical research on these deep neural network architectures and attempts to understand their pros and cons. To ensure fairness, we first developed a unified architecture called SPACH, which uses independent modules for spatial and channel processing. Experiments based on SPACH indicate that all architectures can achieve comparable performance at moderate scales. However, as the networks scale up, they exhibit different behaviors. Based on the findings, we proposed two hybrid modules using convolution and Transformer. The proposed Hybrid-MS-S achieves 83.9% top-1 accuracy with only 63M parameters and 12.3 GFLOPs, demonstrating performance comparable to existing well-designed models.
A Unified Experimental Framework
To fairly compare the three architectures, we need a unified framework to eliminate other factors that may affect performance. Given the recently proposed MLP has a similar architecture to Transformer, we constructed a unified framework based on this and attempted to incorporate CNN.
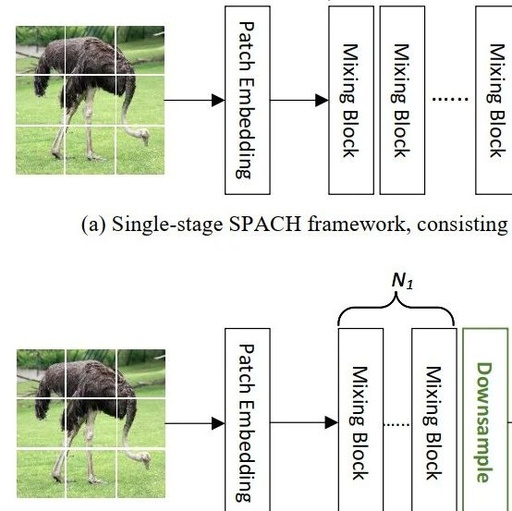
Figure a below shows a schematic of the single-stage SPACH architecture, where both ViT and MLP-Mixer adopt similar architectures, which are quite simple and mainly consist of multiple Mixing modules and necessary auxiliary modules (e.g., block embedding, GAP, and linear classifiers). Figure b below shows the structure of the Mixing module, where Spatial Mixing and Channel Mixing are executed sequentially. The name SPACH comes from the processing of Mixing: SPAtial and CHannel processing.
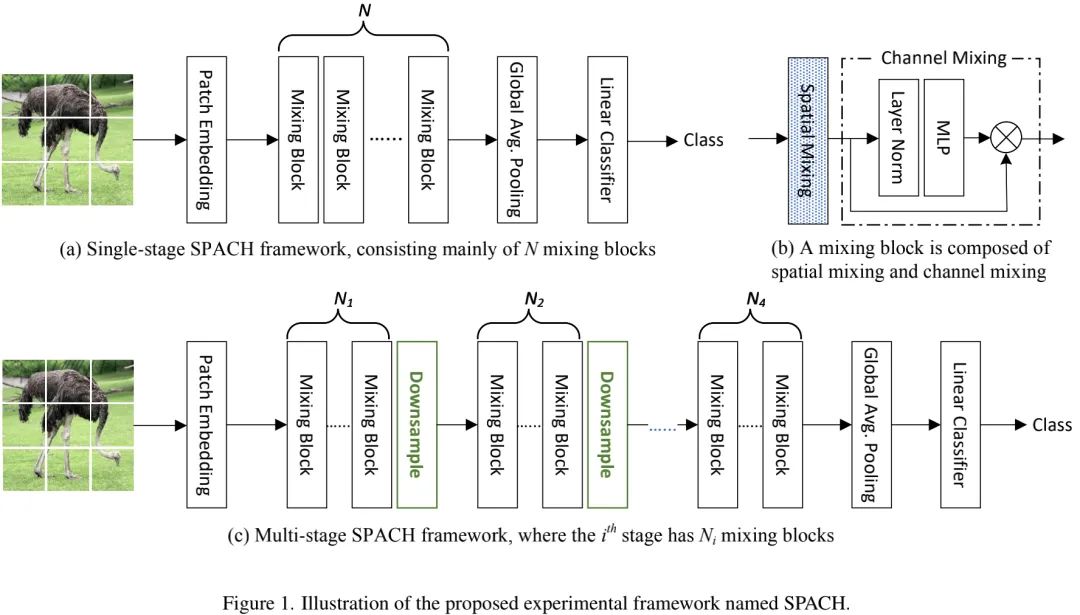
Figure c above shows a schematic of the multi-stage SPACH (SPACH-MS) architecture. Multi-stage is a crucial mechanism for improving CNN performance. Unlike the single-stage SPACH (which downsamples the input image at a large scale before processing), it maintains high resolution in the initial phase and then gradually downsamples. Specifically, SPACH-MS consists of four stages, with downsampling ratios, each stage containing Mixing modules. Due to the high computational load of Transformer and MLP on high-resolution features, we only used convolution in the first stage; furthermore, the channel dimension remains unchanged within the stage, doubling the number of channels with each downsampling.
Let the input image be represented as, SPACH first transforms it through a block embedding layer (note: p represents the block size, which is 16 in single-stage and 4 in multi-stage). After processing through multiple Mixing modules, classification is performed at the tail classification head.
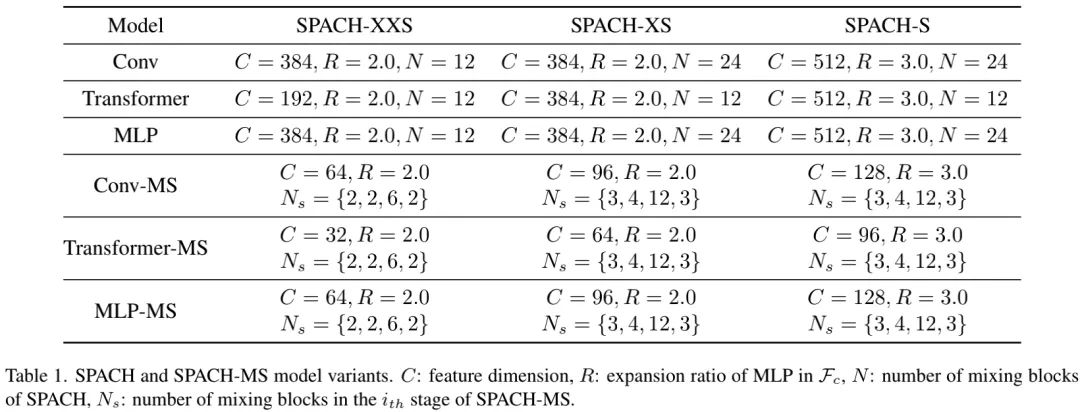
The above table provides hyperparameter information for different model configurations. By controlling the number of modules, channel numbers, and expansion ratios, three different model sizes were set: SPACH-XXS, SPACH-XS, and SPACH-S.
Mixing Block Design
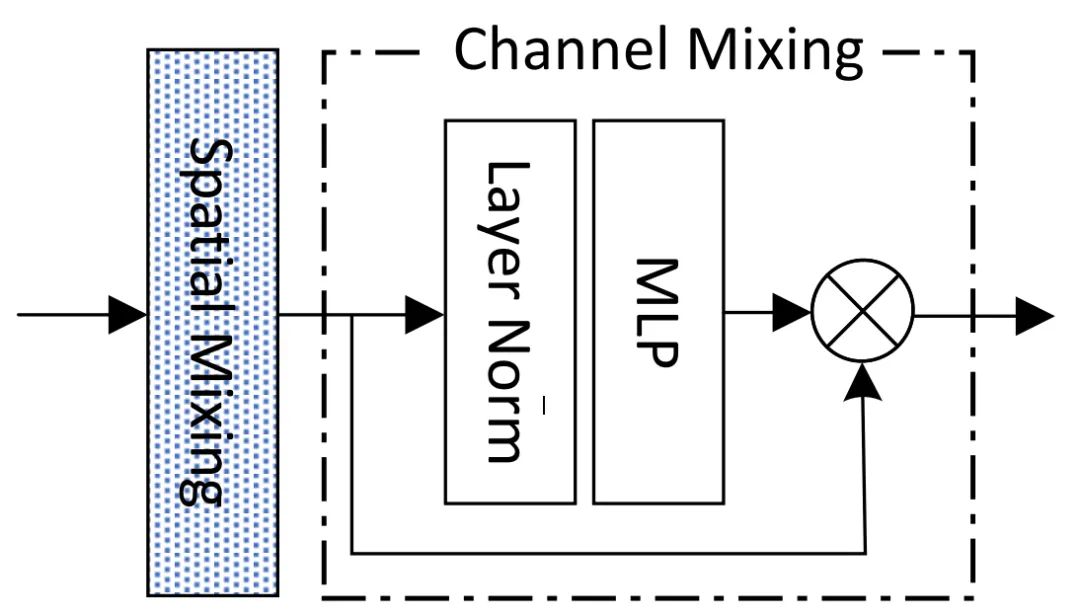
The Mixing module is a key component of the SPACH architecture, as shown in the figure above: the input features are first processed by the Spatial Mixing module and then by the Channel Mixing module. Among them: the former focuses on aggregating information from different locations, while the latter focuses on channel information fusion. Let the output be Y; we describe the Mixing module as follows:
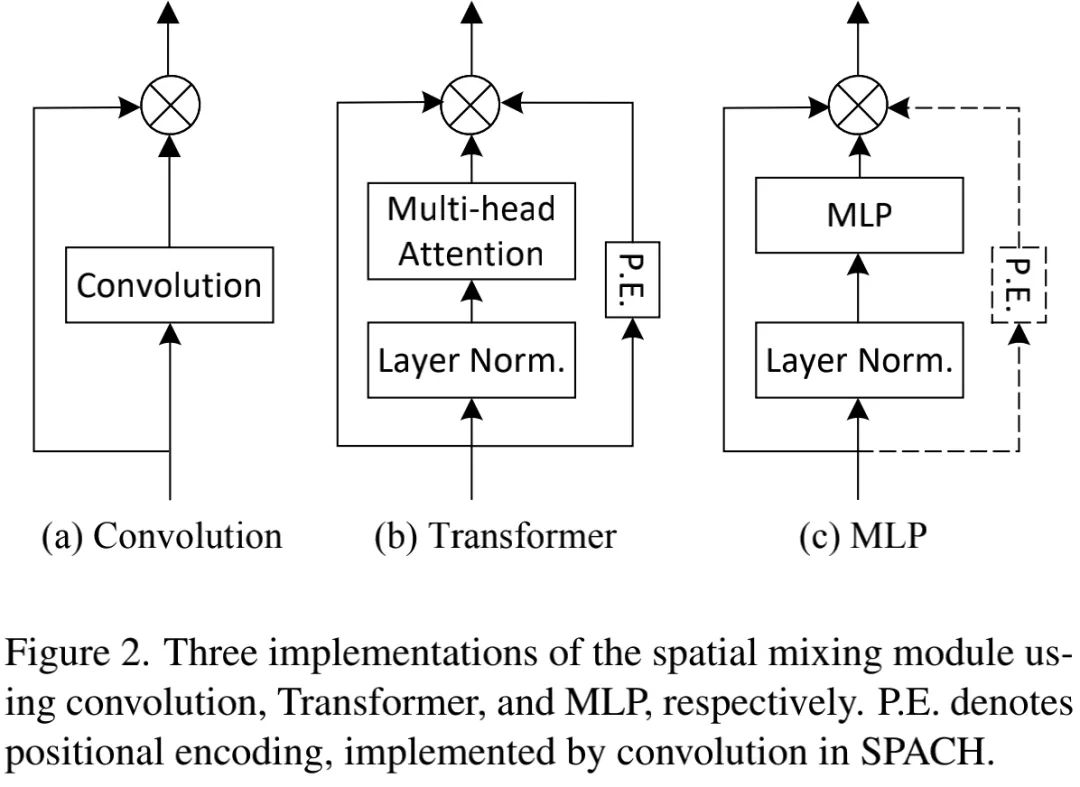
The key differences among the architectures lie in the Spatial Mixing module. We implemented three architectures using convolution, self-attention, and MLP, as shown in the figure above. Specifically:
-
Convolution: implemented using depthwise convolution;
-
Transformer: implemented using self-attention + CPE;
-
MLP: implemented using MLP + CPE.
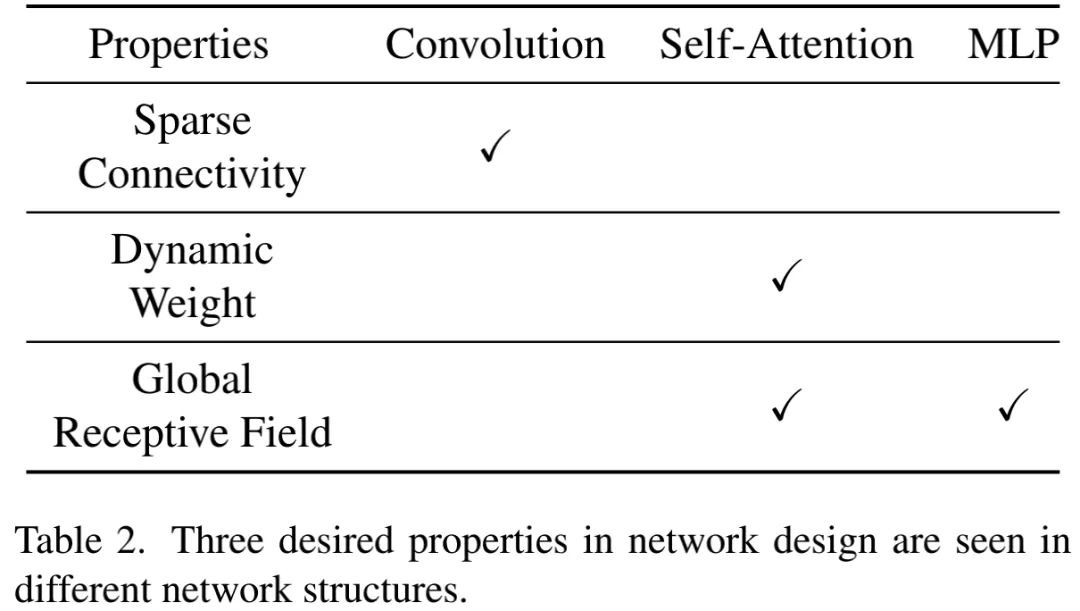
The above three implementations have different characteristics, summarized as follows:
-
The convolution structure contains only local connections, thus is computationally efficient;
-
Self-attention uses dynamic weights, thus has a larger model capacity and simultaneous global receptive field;
-
MLP also has a global receptive field but does not use dynamic weights.
In summary, the aforementioned properties have a direct impact on model performance and efficiency. We find that convolution and self-attention have complementary characteristics, making it likely to combine both to achieve all desired properties.
Empirical Studies on Mixing Blocks
Next, we will conduct a series of controlled experiments to compare the three network architectures.
Multi-stage is Superior to Single-stage
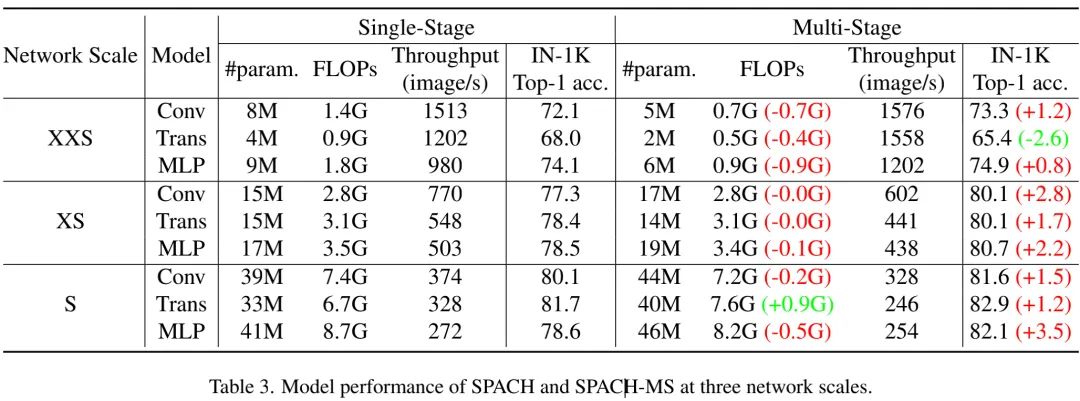
The above table compares the performance of single-stage and multi-stage SPACH models on the ImageNet classification task, showing that: for three sizes of networks and three types of network architectures, multi-stage networks consistently achieve a better complexity-accuracy balance.
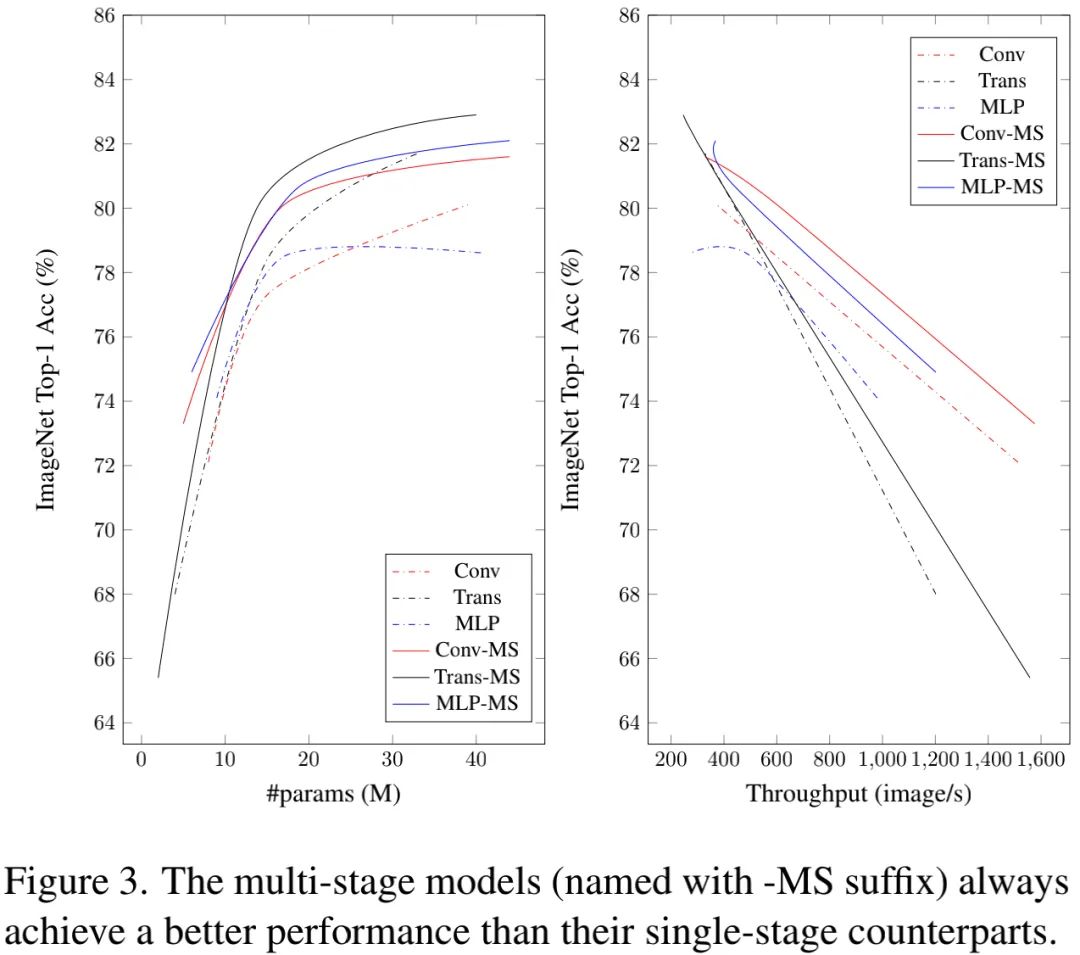
The above figure compares the relationship between image classification accuracy and parameters, throughput. It shows that: multi-stage models are always superior to single-stage models.
The findings align with some recent works, such as the multi-stage architectures Swin and TWins, which significantly outperform the single-stage architecture DeiT. Our research also suggests that the multi-stage architecture may be a key reason for its superior performance.
Local Modeling is Crucial
From the comparisons in Table3 and Figure, we can see that the convolution architecture performs comparably to Transformer; however, deep convolution only accounts for 0.3% of the total parameters and 0.5% of the FLOPs.
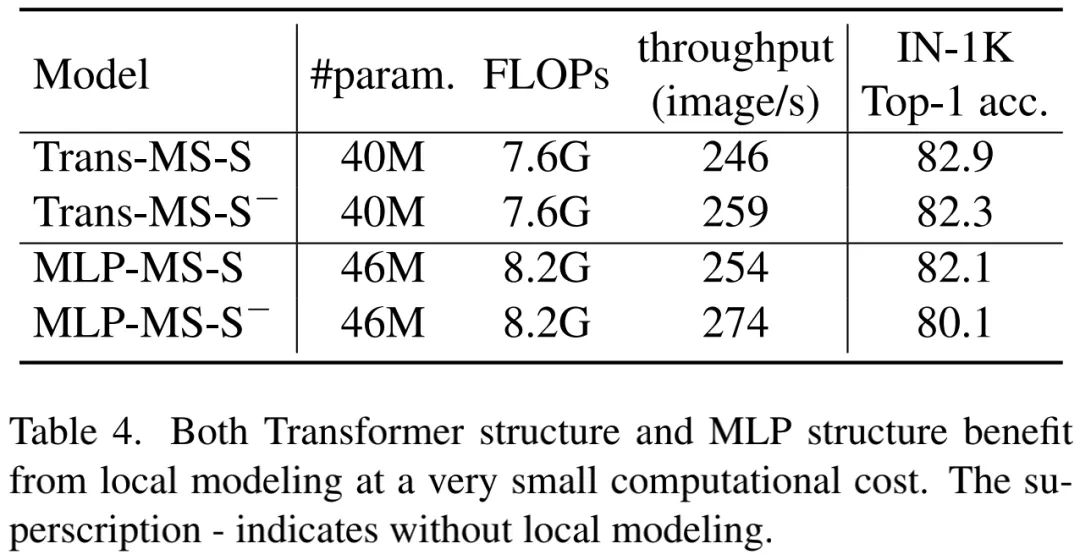
To illustrate how local modeling helps improve the performance of Transformer and MLP, we removed the convolutional branch (note: the convolutional branch refers to the CPE branch) from both structures, as shown in the above table. It can be seen that: the convolutional branch only slightly reduces throughput but significantly improves the accuracy of both models. This experiment further emphasizes the importance of local modeling.
A Detailed Analysis of MLP
Due to the excessive number of parameters, MLP suffers from serious overfitting issues. We believe that: overfitting is the main constraint preventing MLP from achieving SOTA performance. Next, we will discuss two potential mechanisms to alleviate this issue.
Multi-stage Framework The results in Table3 have shown that: multi-stage can bring performance gains, particularly for larger MLP models. For instance, compared to the single-stage scheme, MLP-MS-S achieved a 2.6% accuracy improvement. We believe that the performance gain primarily stems from the strong generalization performance of the multi-stage framework.
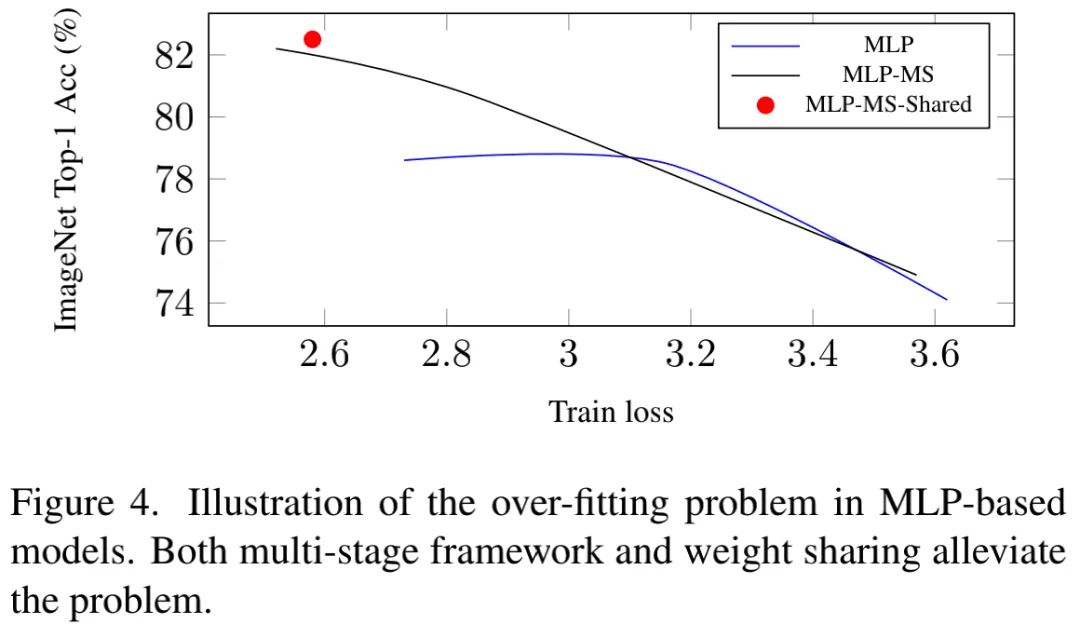
The above table presents the relationship between test accuracy and training loss, showing that overfitting issues arise when test accuracy approaches saturation. Benefiting from the multi-stage architecture, the MLP-MS-S model achieved 5.7% higher accuracy than MLP-Mixer.
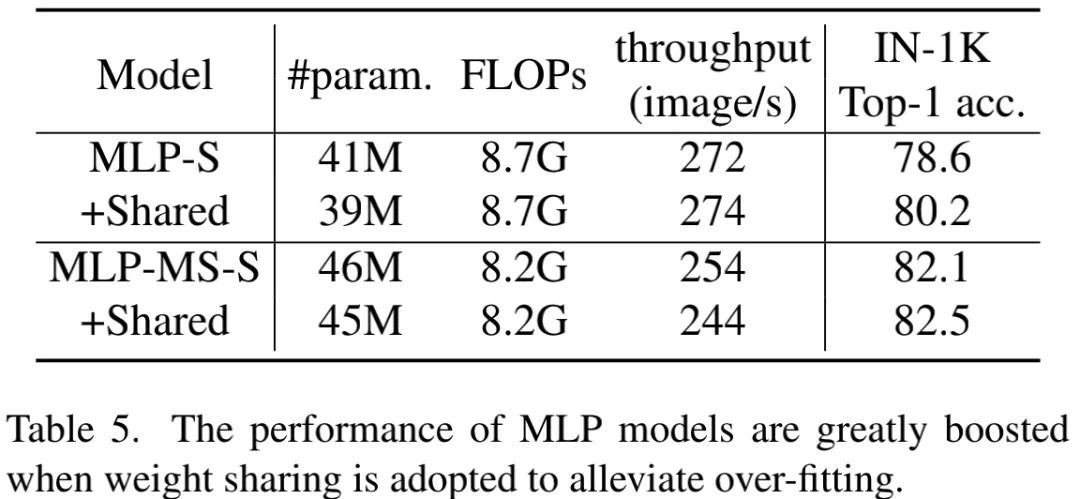
Weight Sharing We implemented weight sharing in the Spatial Mixing module. The results are shown in the table below, indicating that: introducing weight sharing in the MLP architecture can lead to significant performance improvements. The above Figure4 also validates this conclusion. Thus, if MLP can mitigate overfitting issues, it still holds competitive potential.
Convolution and Transformer are Complementary
The convolution architecture exhibits the best generalization performance, while the Transformer architecture has the largest capacity; hence, we believe that: both have complementary characteristics.
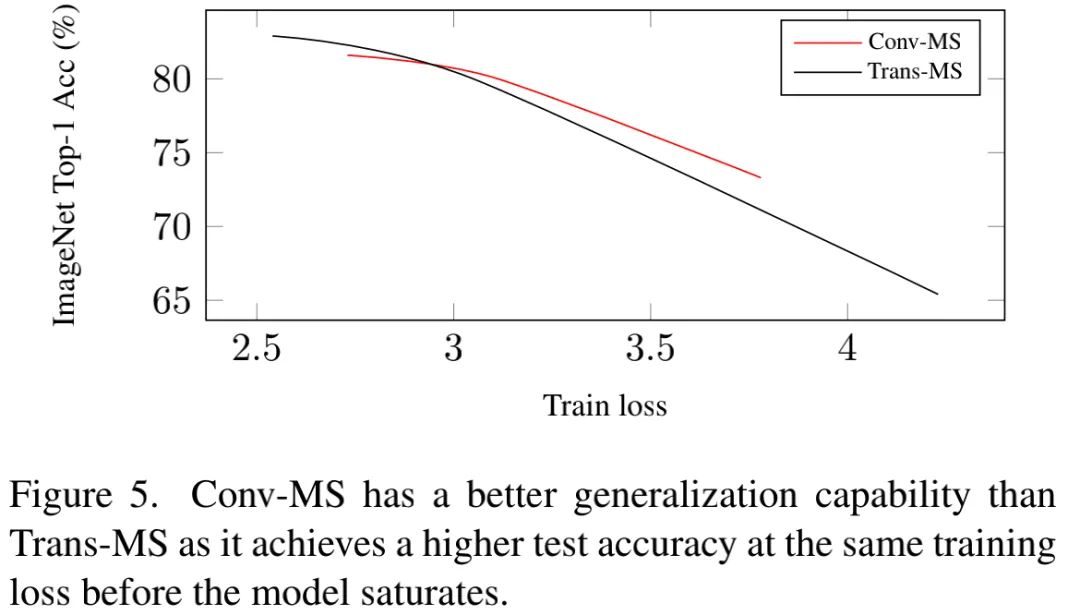
The above figure shows that before performance saturation, Conv-MS achieves higher test accuracy. This indicates that convolution models have better generalization performance, and convolution remains the best choice for lightweight models.
On the other hand, results from Figure3 and Figure5 indicate that Transformer can achieve higher accuracy than the other two structures. Considering the aforementioned structural characteristics, it is evident that sparse connections help enhance generalization performance, while dynamic weights and global receptive fields contribute to increasing model capacity.
Hybrid Models
Based on the previous findings, we constructed a hybrid model based on convolution and Transformer: using a multi-stage convolution model as the baseline, replacing certain layers with Transformer layers. Taking into account the local modeling capability of convolution and the global modeling capability of Transformer, the layer replacement choices for the hybrid model are as follows:
-
Hybrid-MS-XS: Based on Conv-MS-XS, the last 10 layers of Stage 3 and the last two layers of Stage are replaced with Transformer layers. Stages 1 and 2 remain unchanged;
-
Hybrid-MS-S: Based on Conv-MS-S, the last two layers of Stage 2, the last 10 layers of Stage 3, and the last two layers of Stage are replaced with Transformer. Stage 1 remains unchanged.
To further unleash the full potential of the hybrid model, we introduced deep-PEL in LV-ViT. Unlike default-PEL (which uses convolution), deep-PEL uses four convolutions, with kernel sizes, strides, and channel numbers set as follows. We refer to this model as Hybrid-MS-*+.
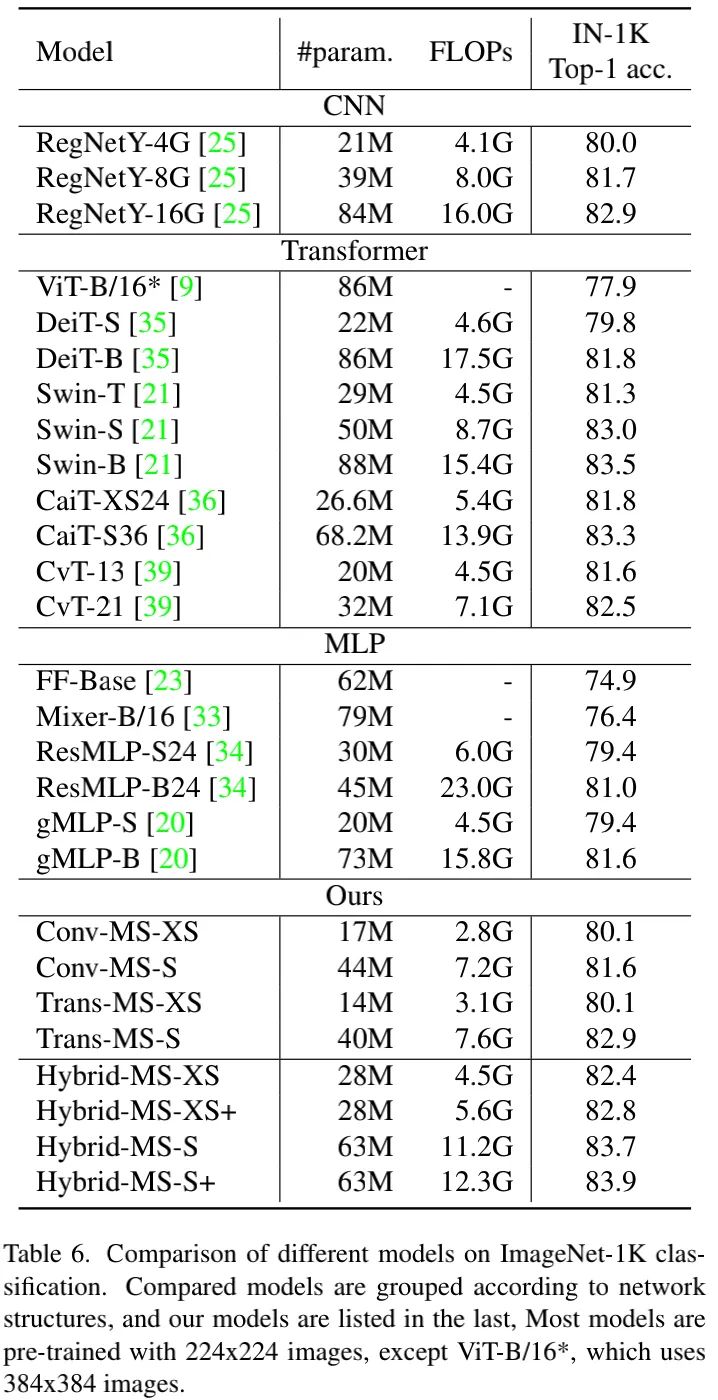
The above table presents a performance comparison between the proposed hybrid model and other models, showing that:
-
Compared to purely convolution or Transformer models, hybrid models achieve better model size-accuracy balance;
-
Hybrid-MS-XS achieved 82.4% top-1 accuracy with 28M parameters, outperforming Conv-MS-S with 44M parameters, slightly below Trans-MS-S with 40M parameters;
-
Hybrid-MS-S achieved 83.7% top-1 accuracy with 63M parameters, outperforming Trans-MS-S by 0.8%;
-
Hybrid-MS-S+ achieved 83.9% top-1 accuracy with 63M parameters, surpassing SOTA solutions Swin-B and CaiT-S36.
-
The authors believe that: Hybrid-MS-S can serve as a simple yet powerful baseline for future architecture research.
Personal Reflection
The article is lengthy and contains a lot of content, but after reading it thoroughly, I conclude: it is indeed the case. A good article, highly recommended!
In fact, before this article, there were some studies exploring the fusion and complementarity of convolution and Transformer. For example, the following two papers:
-
CMT: Convolutional Neural Networks Meet Vision Transformers
-
Early Convolutions Help Transformers See Better
However, very few articles have compared the three on the same level, analyzing their respective characteristics and complementarity issues. When I researched Transformer and MLP some time ago, I pondered: what exactly is the source of the success of Transformer and MLP in the CV field? What are their differences from Convolution? Is there mutual learnability among them? After reading this article, perhaps some of the previous questions have found answers…