
Selected fromthe Gradient
Author:Sebastian Ruder
Translated by Machine Heart
In the field of computer vision, models pre-trained on ImageNet are commonly used for various CV tasks such as object detection and semantic segmentation. In contrast, in the field of natural language processing (NLP), we typically only use pre-trained word embedding vectors to encode the relationships between words, which means there has not been a pre-training method applicable to the overall model. Sebastian Ruder suggests that language models have the potential to serve as holistic pre-trained models, capable of extracting various features of language from shallow to deep, and can be used for a wide range of NLP tasks such as machine translation, question answering systems, and automatic summarization. Ruder also demonstrates the effectiveness of using language models as pre-trained models, indicating that the ‘ImageNet’ of the NLP field is indeed on its way.
The field of natural language processing (NLP) is undergoing significant changes.
For a long time, word vectors have been the core representation technology in NLP. However, their dominance is being challenged by a series of exciting new approaches such as ELMo, ULMFiT, and OpenAI’s transformer. These methods have gained attention because they demonstrate that pre-trained language models can achieve state-of-the-art performance on a wide array of NLP tasks. These methods signal a watershed moment: their impact in NLP may be as broad as that of pre-trained ImageNet models in computer vision.
Shallow to Deep Pre-training
Pre-trained word vectors have significantly improved NLP. The language modeling approximation introduced in 2013—word2vec—was adopted for its efficiency and ease of use during a time when hardware was much slower and deep learning models were not widely supported. Since then, the standard approach to NLP projects has remained largely unchanged: word embeddings pre-processed from large amounts of unlabelled data using algorithms like word2vec and GloVe are used to initialize the first layer of neural networks, with subsequent layers trained on task-specific data. In most tasks with limited training data, this approach helps improve performance by two to three percentage points. Despite the significant impact of these pre-trained word embeddings, they have limitations: they only encapsulate prior knowledge for the first layer of the model—the rest of the network still needs to be trained from scratch.
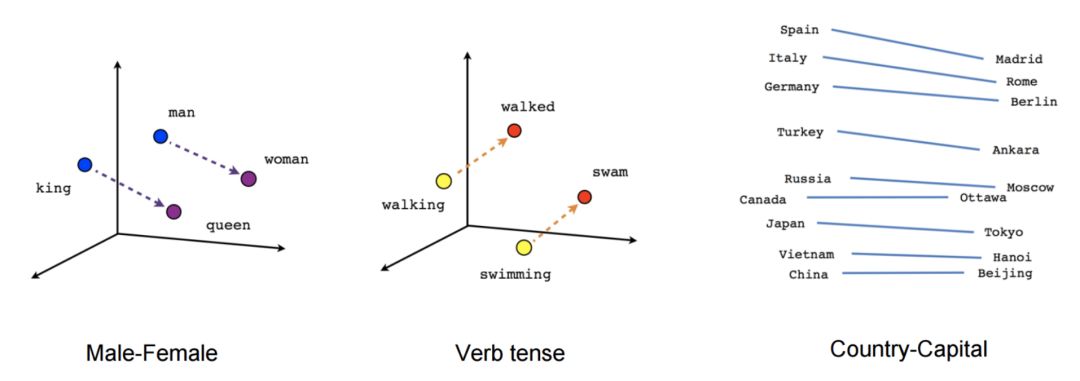
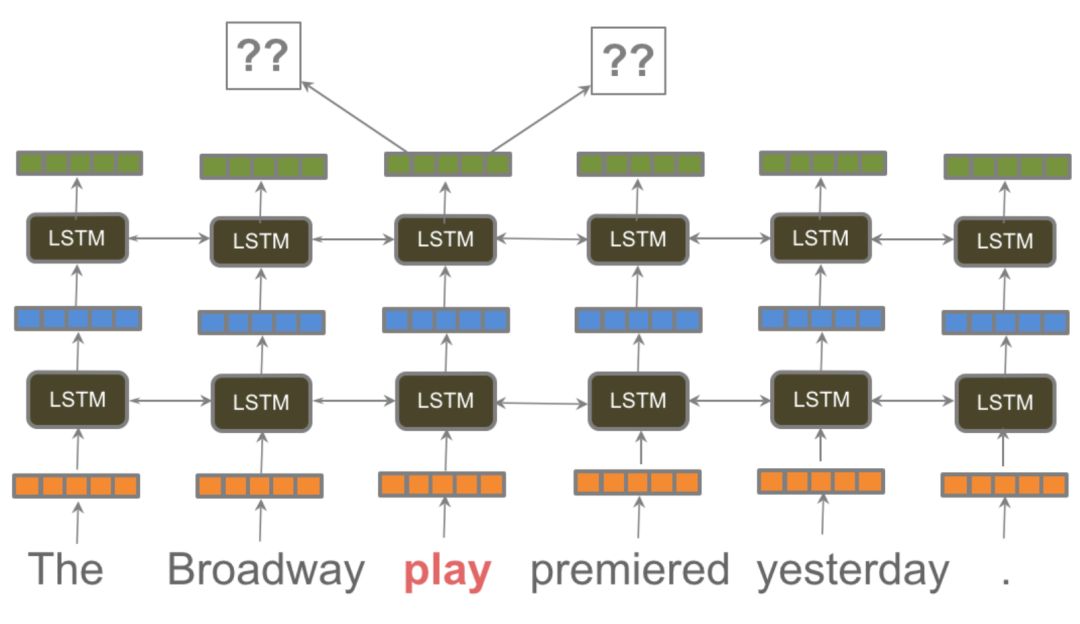
Relations captured by word2vec. (Source: TensorFlow tutorial)
Word2vec and other related methods are shallow approaches that sacrifice expressiveness for efficiency. Using word embeddings is akin to initializing a computer vision model with pre-trained representations that only encode edge information of images: they can perform well on many tasks but fail to capture higher-level information that could play a more significant role. Models initialized with word vectors need to learn from scratch not only to disambiguate but also to extract meaning from sentences composed of words. This is at the core of language understanding and requires modeling many complex linguistic phenomena such as semantic composition, polysemy, anaphora resolution, long-term dependencies, consistency, and negation. Therefore, it is not surprising that NLP models initialized with these shallow representations still require a large number of examples to achieve good performance.
The latest advancements in ULMFiT, ELMo, and OpenAI’s transformer revolve around a key paradigm shift: from merely initializing the first layer of the model to preprocessing the entire model with hierarchical representations. If learning word vectors is like learning only the edges of images, these methods are akin to learning a complete hierarchy of features, from edges to shapes, and then to high-level semantic concepts.
Interestingly, pre-training entire models to capture both low-level and high-level features has been adopted in the computer vision community for several years. In most cases, pre-trained models are trained on large datasets like ImageNet to classify images. ULMFiT, ELMo, and OpenAI’s transformer have brought the ‘ImageNet’ of natural language to the NLP community, allowing models to learn the subtle nuances of language. This is similar to how ImageNet enables pre-trained CV models to learn universally meaningful image features. In the latter parts of this article, we will draw an analogy between language modeling and ImageNet computer vision modeling and show why this approach seems so promising.
ImageNet

ImageNet Large Scale Visual Recognition Challenge. (Source: Xavier Giro-o-Nieto)
ImageNet has had a significant impact on machine learning research. This dataset was initially released in 2009 and quickly evolved into the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). In 2012, a deep neural network submitted by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton outperformed the second place by 41%, demonstrating that deep learning is a viable machine learning strategy, and this deep neural network can be said to have triggered the explosion of deep learning in machine learning research.
The success of ImageNet highlights that in the era of deep learning, data is at least as important as algorithms. The ImageNet dataset not only made the crucial deep learning capability demonstration possible in 2012 but also achieved similarly significant breakthroughs in transfer learning: researchers quickly realized that the weights learned from existing models on ImageNet could be used to initialize models on entirely different datasets, significantly improving performance. This ‘fine-tuning’ method allows for good performance even with only one positive example per category (Donahue et al., 2014).
Features trained on ILSVRC-2012 generalize to the SUN-397 dataset. (Source: Donahue et al., 2014)
Pre-trained ImageNet models have achieved state-of-the-art performance on tasks such as object recognition, semantic segmentation, human pose estimation, and video recognition. Meanwhile, they have also enabled CV applications in areas with few training examples and high annotation costs. In CV, transfer learning through pre-training on ImageNet has proven to be so effective that not using it is now considered reckless (Mahajan et al., 2018).
What’s in ImageNet?
To determine what an ImageNet-like dataset for language processing might look like, we first need to ascertain what makes ImageNet conducive to transfer learning. Past research has only revealed part of the answer: reducing the number of examples per class or the number of categories only leads to performance degradation, and fine-grained classes and more data do not always mean better results.
Rather than looking directly at the data, a more prudent approach is to explore what the models trained on the data have learned. It is well-known that the feature transfer order of deep neural networks trained on ImageNet is from the first layer to the last, from general tasks to specific tasks: lower layers learn to model low-level features such as edges, while higher layers learn to model high-level concepts such as patterns and entire parts or objects, as illustrated below. Importantly, knowledge about object edges, structures, and visual compositions is relevant to many CV tasks, revealing why these layers are transferable. Thus, a key attribute of a dataset similar to ImageNet is that it encourages models to learn features that can generalize to new tasks in the problem domain.

Visualization of information captured by different layers of GoogLeNet trained on ImageNet. (Source: Distill)
Moreover, it is challenging to further generalize why transfer learning performs so well on ImageNet. Another advantage of the ImageNet dataset might be the quality of the data. The creators of ImageNet made efforts to ensure the reliability and consistency of annotations. However, remote supervision work contrasts this, indicating that a large amount of weakly labeled data is often sufficient. In fact, Facebook researchers recently demonstrated that they could pre-train models by predicting hashtags on billions of social media images to achieve the latest accuracy on ImageNet.
While there are no more specific insights, we have two key requirements:
-
A dataset for language tasks should be sufficiently large, with approximately millions of training examples.
-
It should represent the problem space of the discipline.
ImageNet for Language Tasks
Compared to CV, NLP models are typically much shallower. Hence, feature analysis primarily focuses on the first embedding layer, with little research on the higher-level nature of transfer learning. We consider datasets that are large enough. In the current NLP landscape, several common tasks have the potential for pre-trained models.
Reading comprehension is a task that answers questions about a paragraph in natural language. The most popular dataset for this task is the Stanford Question Answering Dataset (SQuAD), which contains over 100,000 question-answer pairs and allows the model to answer a question by highlighting several words in the paragraph, as shown below:

Visualization of information captured by different layers of GoogLeNet trained on ImageNet (Rajpurkar et al., 2016, “SQuAD: 100,000+ Questions for Machine Comprehension of Text”).
Natural language inference is the task of recognizing the relationship between a piece of text and a hypothesis (entailment, contradiction, and neutral, etc.). The most popular dataset for this task is the Stanford Natural Language Inference (SNLI) Corpus, which contains 570,000 human-written English sentence pairs. Examples from this dataset are shown below.
SNLI: https://nlp.stanford.edu/projects/snli/

Example from the SNLI dataset. (Bowman et al., 2015, “A large annotated corpus for learning natural language inference”)
Machine translation, which involves converting text from one language to another, is one of the most well-studied tasks in NLP. Over the years, a large amount of training data has been accumulated for commonly used language pairs, such as 40 million English-French sentence pairs from WMT2014. Below are two example translation pairs.

French to English translation from newstest2014 (Artetxe et al., 2018, “Unsupervised Neural Machine Translation”)
Constituency parsing extracts the syntactic structure of a sentence in the form of (linearized) parse trees, as shown below. In the past, millions of weakly labeled parses were used to train sequence-to-sequence models for this task (see “Grammar as a Foreign Language”).
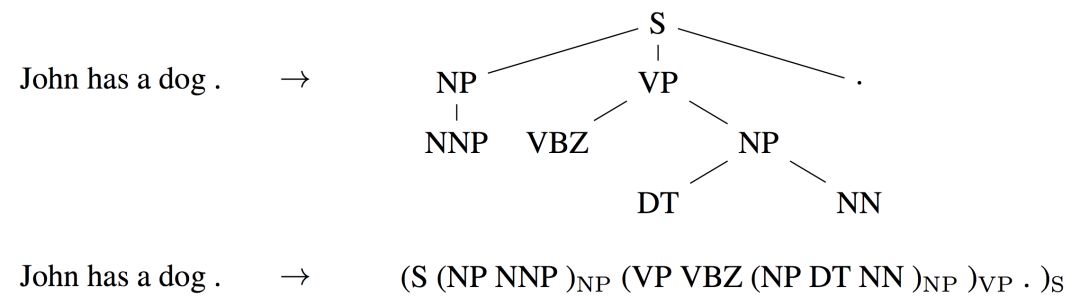
Parse trees and their linearized forms (Vinyals et al., 2015, “Grammar as a Foreign Language”)
Language modeling (LM) attempts to predict the next word given the previous one. Existing benchmark datasets comprise approximately one billion words, but since this task is unsupervised, any amount of text can be used for training. Below is an example from the commonly used WikiText-2 dataset, which consists of Wikipedia articles.

Example from the WikiText-2 language modeling dataset. (Source: Salesforce)
WikiText-2: https://einstein.ai/research/the-wikitext-long-term-dependency-language-modeling-dataset
All these tasks provide or allow the collection of a sufficient number of examples for training. In fact, the above tasks (and many others such as sentiment analysis, skip-thoughts, and autoencoders) have been used in recent months for pre-trained representations.
While any data contains certain biases, human annotations may inadvertently introduce additional information that the models will leverage. Recent studies show that current state-of-the-art models on tasks such as reading comprehension and natural language inference do not actually form a deep understanding of natural language but instead pay attention to certain cues to perform shallow pattern matching. For instance, Gururangan et al. (2018) in “Annotation Artifacts in Natural Language Inference Data” show that annotators tend to generate entailment examples by removing gender or number information and generate contradiction examples by introducing negation. By simply using these cues, models can classify hypotheses on the SNLI dataset with an accuracy of 67% without looking at the premises.
Thus, the more challenging question should be: which task is the most representative in NLP? In other words, which task allows us to learn the most about natural language understanding or relationships?
Language Modeling
To predict the most likely next word in a sentence, a model not only needs to express grammar, meaning that the grammatical form of the predicted next word must match its modifiers or verbs. Simultaneously, the model also needs to understand semantics; moreover, the most accurate models must include content such as world knowledge or common sense. For instance, thinking of an incomplete statement “The service was poor, but the food was,” to predict subsequent words like “yummy” or “delicious,” the model not only needs to remember the attributes used to describe food but also needs to recognize the conjunction “but” to introduce opposing semantics, thus the new attributes should contrast with the emotional word “poor.”
Language modeling is the last method mentioned, which has been proven to capture many language-related attributes for downstream tasks such as long-term dependencies, hierarchical relationships, and emotional semantics. Compared to unsupervised learning tasks like autoencoders, language modeling can perform very well on syntactic tasks even with a small amount of training data.
The greatest advantage of language modeling is that training data can be freely obtained from any text corpus, thus almost allowing for an unlimited amount of training data. This is significant because NLP is not limited to English; there are 4,500 languages spoken by more than 1,000 people. As a pre-training task, language modeling opens doors for previously under-supported languages, allowing us to directly use text data to train language models unsupervised and apply them to tasks such as translation and information extraction. For those rare languages that lack even unlabeled data, multilingual language modeling can first train on multiple related languages, such as cross-lingual word embeddings.
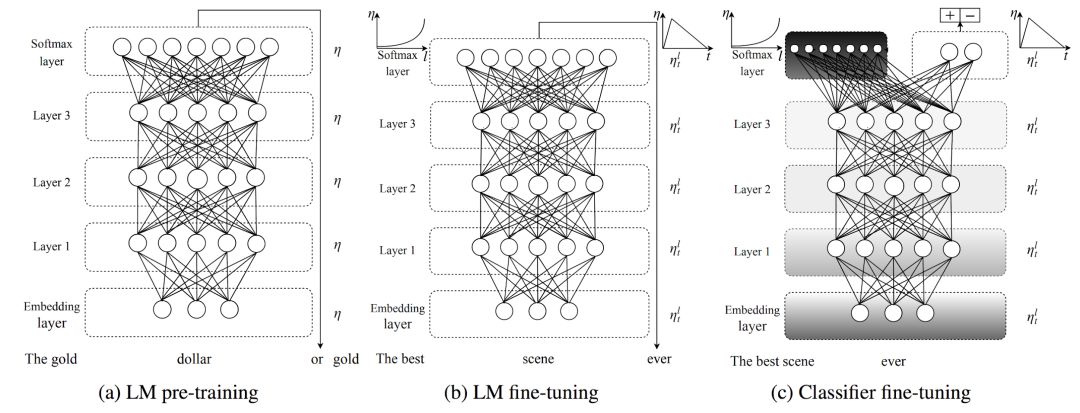
Different stages of ULMFiT (Howard and Ruder, 2018)
So far, our argument for language modeling as a pre-training task is purely conceptual. However, in recent months, we have also obtained some experimental evidence: language model embeddings (ELMo), universal language model fine-tuning (ULMiT), and OpenAI Transformer have experimentally demonstrated that language models can be used for pre-training tasks, as illustrated by ULMFiT in the figure above. All three methods use pre-trained language models to achieve state-of-the-art results on various natural language processing tasks such as text classification, question answering systems, natural language inference, coreference resolution, and sequence labeling.
In many cases, such as ELMo, using pre-trained language models as core algorithms has outperformed current state-of-the-art results by 10% to 20% on widely studied benchmarks. ELMo also won the best paper award at the NLP top conference NAACL-HLT 2018. Finally, these models demonstrate very high sample efficiency, achieving optimal performance with only a few hundred samples, and even enabling zero-shot learning.
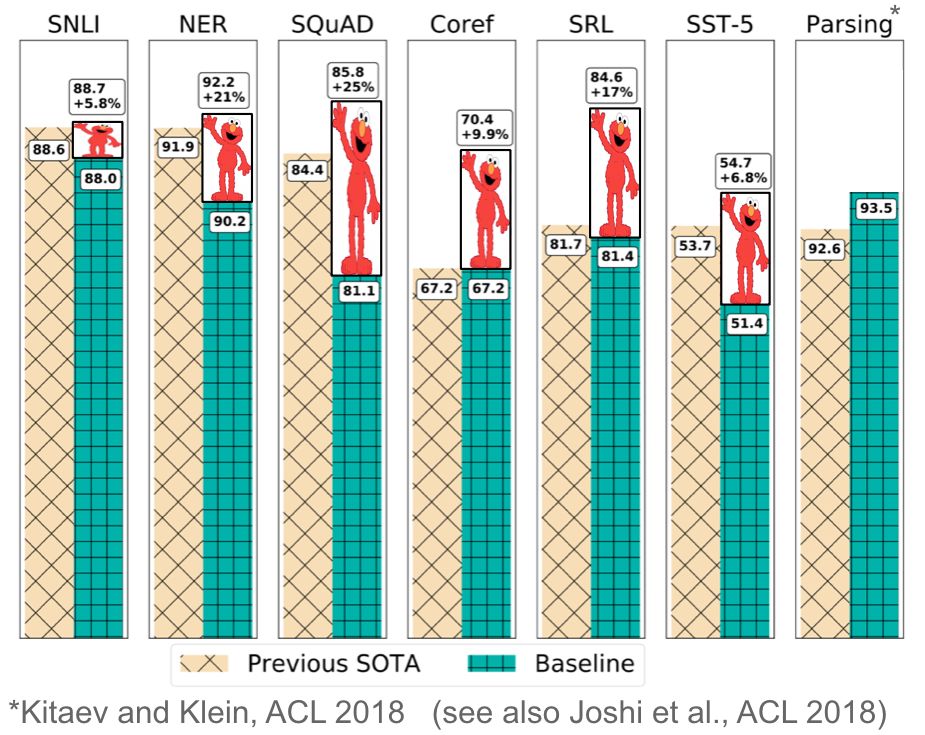
Progress achieved by ELMo on a range of NLP tasks. (Source: Matthew Peters)
Given the changes achieved at this step, NLP practitioners are likely to download pre-trained language models in a year rather than pre-trained word embeddings for their models, just as the starting point for most CV projects is now how to pre-train ImageNet models.
However, similar to word2vec, the tasks of language modeling have their inherent limitations: it serves merely as a proxy for true language understanding, and a standalone model is insufficient to capture the necessary information for specific downstream tasks. For example, to answer questions about or follow the trajectory of characters in a story, a model needs to learn to perform coreference or resolution. Moreover, language models can only capture what they have seen. Certain types of information, such as most common sense, are difficult to learn solely from text and require integration of external information.
A prominent issue is how to transfer information from a pre-trained language model to downstream tasks. There are two main paradigms: whether to use the pre-trained language model as a fixed feature extractor and integrate its representations as features into a randomly initialized model (as ELMo does), or whether to fine-tune the entire language model (as ULMFiT does). The latter is commonly used in computer vision, where the top layer or top few layers of the model are adjusted during training. While NLP models are typically shallower, thus requiring different fine-tuning techniques compared to their visual counterparts, recent pre-trained models have become deeper. I will demonstrate the role of each core component in NLP transfer learning next month, including expressive language model encoders (like deep BiLSTM or Transformer), the amount and nature of the data used for pre-training, and the methods for fine-tuning pre-trained models.
But what is the theoretical basis?
So far, our analysis has been primarily conceptual and empirical, and we still struggle to understand why models trained first on ImageNet can transfer so well to language modeling. A more formal way to consider the generalization ability of pre-trained models is based on the ‘bias learning’ model (Baxter, 2000). Suppose our problem domain covers all permutations of tasks in a specific discipline, such as computer vision—it constitutes the environment. We provide many datasets to it, allowing us to induce a series of hypothesis spaces H=H’. Our goal in bias learning is to find the bias, i.e., the hypothesis space H’∈H that can maximize performance across the entire (possibly infinite) environment.
Empirical and theoretical results in multi-task learning (Caruana, 1997; Baxter, 2000) suggest that biases learned from enough tasks may generalize to unseen tasks in the same environment. Through multi-task learning, models trained on ImageNet can learn a large number of binary classification tasks (one for each class). These tasks come from the natural, real-world image space and may be representative of many other CV tasks. Similarly, language models may induce representations that help many other tasks in the natural language domain by learning a large number of classification tasks (one for each word). However, further research is needed to theoretically better understand why language modeling seems so effective in transfer learning.
The ImageNet Era of NLP
The time for NLP to truly shift to transfer learning has come. Given the impressive experimental results of ELMo, ULMFiT, and OpenAI, this development seems to be just a matter of time, as pre-trained word embeddings will gradually become obsolete, replaced by pre-trained language models in every NLP practitioner’s toolbox. This may create more possibilities for NLP when labeled data is scarce. The old paradigm is dead, the new one is about to rise!
Original link: https://thegradient.pub/nlp-imagenet/
On July 14, Tencent will hold the Tencent Academic and Industrial Conference (TAIC) in Stockholm, inviting top AI scholars and young researchers from around the world to discuss cutting-edge AI research and applications with Tencent’s seven major business groups. Click to read the original text and participate in registration.
