Experience Local Deployment of VisualGLM-6B Multimodal Dialogue Model
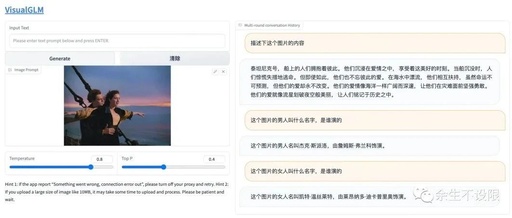
The VisualGLM-6B multimodal dialogue model used in this article is open-sourced by Zhizhu AI and the KEG Lab of Tsinghua University. It can describe images and answer related knowledge questions. This article will guide you to experience the capabilities of this multimodal dialogue model by personally feeling its practical effects through local deployment. 1. Environment … Read more