The VisualGLM-6B multimodal dialogue model used in this article is open-sourced by Zhizhu AI and the KEG Lab of Tsinghua University. It can describe images and answer related knowledge questions. This article will guide you to experience the capabilities of this multimodal dialogue model by personally feeling its practical effects through local deployment.
1. Environment Preparation
Download the code:
git clone https://github.com/THUDM/VisualGLM-6Bcd VisualGLM-6BInstall dependencies:
# For users in China, please use the aliyun mirror, as TUNA and other mirrors have recently encountered issues. The command is as follows: pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txtQuick experience:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True).half().cuda()
image_path = "./examples/1.jpeg"
response, history = model.chat(tokenizer, image_path, "Describe this image.", history=[])
print(response)
response, history = model.chat(tokenizer, image_path, "What place might this image have been taken at?", history=history)
print(response)Output:
[INFO] [RANK 0] > initializing model parallel with size 1
[INFO] [RANK 0] You are using model-only mode.
For torch.distributed users or loading model parallel models, set environment variables RANK, WORLD_SIZE and LOCAL_RANK.
/envs/lab/lib/python3.9/site-packages/torch/nn/init.py:405: UserWarning: Initializing zero-element tensors is a no-op
warnings.warn("Initializing zero-element tensors is a no-op")
37204Loading checkpoint shards: 100%|██████████| 5/5 [00:18<00:00, 3.72s/it]
Specify both input_ids and inputs_embeds at the same time, will use inputs_embeds
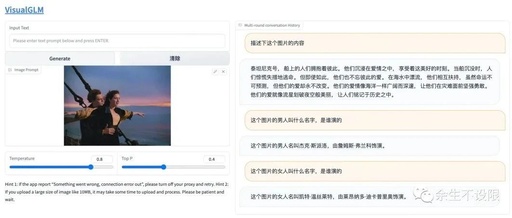
The Titanic, a romantic and beautiful name; the beautiful woman on the movie poster shines like a brilliant star in the sky. On the ship, they embrace each other, immersed in the ocean of love; at the bow, their gazes intertwine, as if their souls are connected, like poetry and painting. When the sea surges, when the waves rise, their love remains so steadfast and eternal; they leave a deep imprint in each other's hearts, which will never fade away. This photo may have been taken on the Titanic or near the shore or dock.2. Command Line Interaction
The program will automatically download the sat model and conduct interactive dialogue in the command line; just input instructions and press enter to generate replies. Input clear to clear the dialogue history, and input stop to terminate the program.
python cli_demo_hf.pyExample of interactive dialogue:
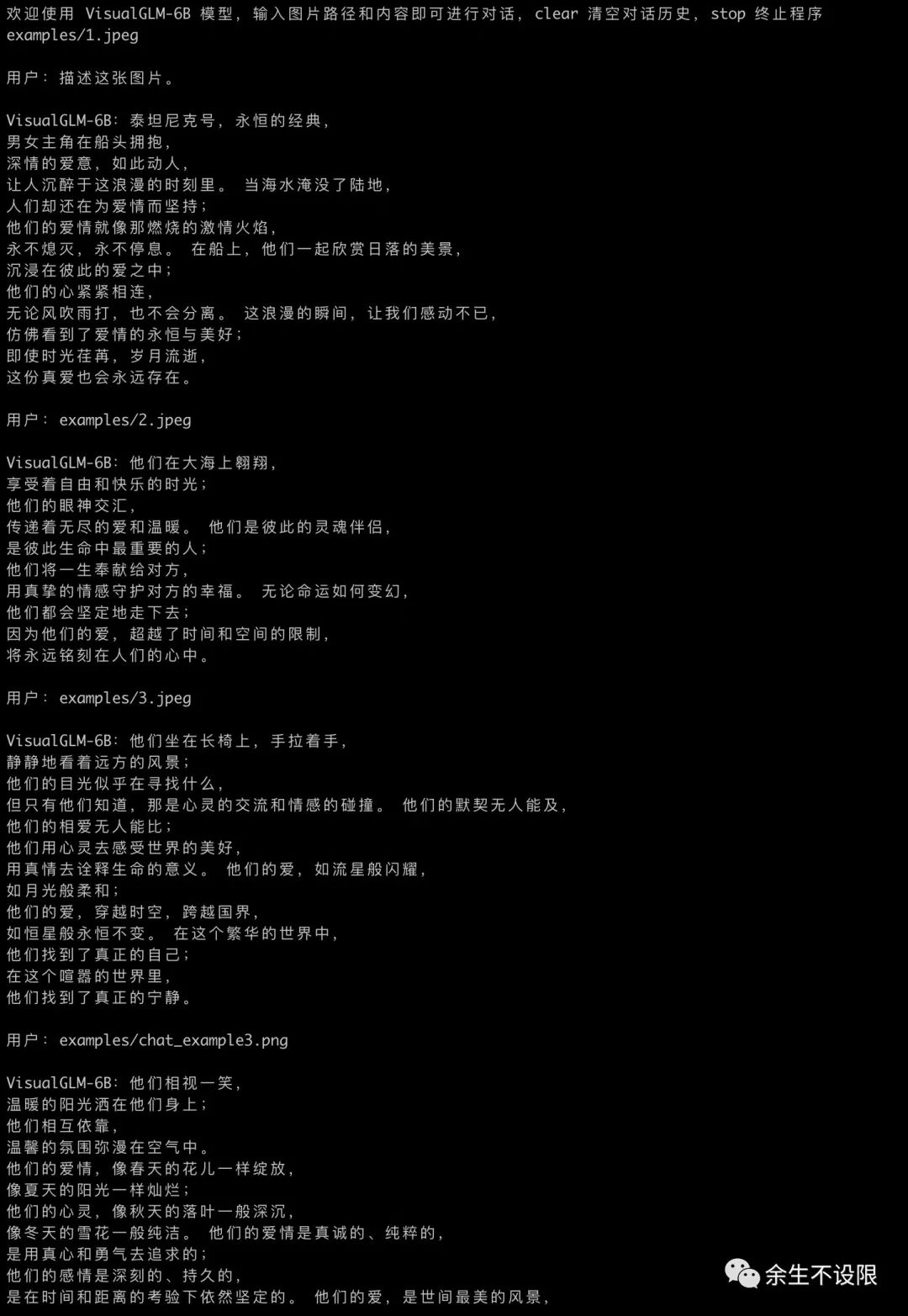
3. Web Interaction
Based on Gradio, first install Gradio:pip install gradio. Execute: web_demo.py
$ python web_demo.py
(lab9) [root@VM-101-6-centos VisualGLM-6B]$ python web_demo.py
Downloading models https://cloud.tsinghua.edu.cn/f/348b98dffcc940b6a09d/?dl=1 into /root/.sat_models/visualglm-6b.zip ...
/root/.sat_models/visualglm-6b.zip: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 14.4G/14.4G [10:10<00:00, 5.87MB/s]
Unzipping /root/.sat_models/visualglm-6b.zip...Image and text dialogue example:
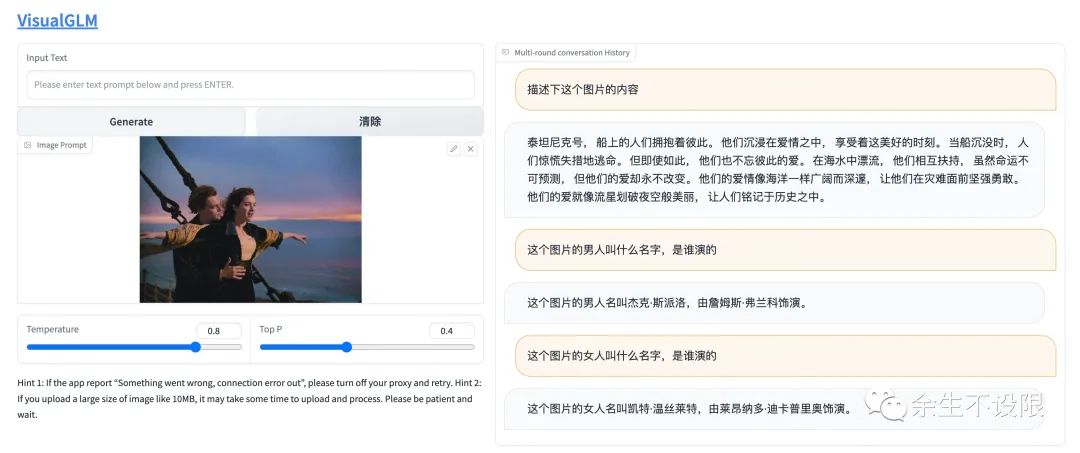
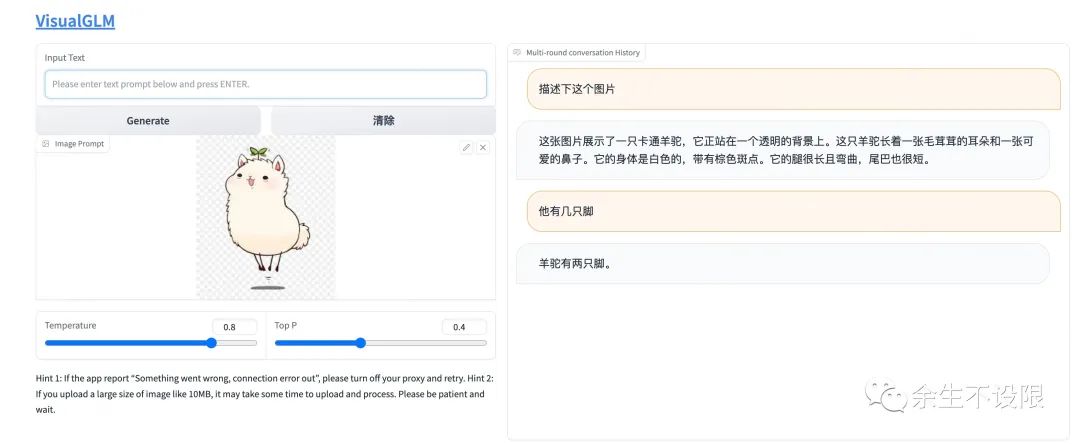
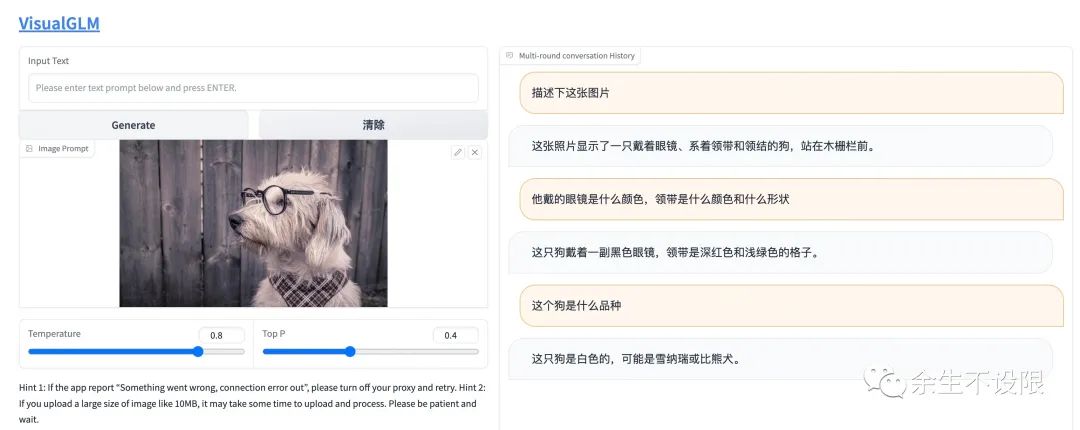

4. API Deployment Interaction
First, you need to install additional dependencies with pip install fastapi uvicorn. The program will automatically download the sat model and deploy it locally on port 8080, which can be called via POST method.
python api.py
[INFO] [RANK 0] > successfully loaded /root/.sat_models/visualglm-6b/1/mp_rank_00_model_states.pt
INFO: Started server process [2939]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080Below is an example of a curl request; typically, you can also use code methods for POST.
$ echo "{\"image\":\"$(base64 ./examples/1.jpeg)\",\"text\":\"Describe this image\",\"history\":[]}" > temp.json
$ curl -X POST -H "Content-Type: application/json" -d @temp.json http://127.0.0.1:8080Output:
{"result":"The Titanic, the male and female leads embrace at the bow.\nThe sea surges, the waves are turbulent.\nThey gaze at each other, deeply affectionate.\nTheir love is so beautiful, intoxicating.\nTheir separation is so painful, heart-wrenching.\nBut love is eternal and unchanging, shining across the sky like a meteor.","history":[["Describe this image","The Titanic, the male and female leads embrace at the bow.\nThe sea surges, the waves are turbulent.\nThey gaze at each other, deeply affectionate.\nTheir love is so beautiful, intoxicating.\nTheir separation is so painful, heart-wrenching.\nBut love is eternal and unchanging, shining across the sky like a meteor."]],"status":200,"time":"2023-05-27 15:13:54"}5. Model Fine-tuning
Multimodal tasks are widely distributed and varied, and pre-training often cannot cover all aspects. Here we provide an example of fine-tuning with a small sample, using 20 labeled images to enhance the model’s ability to answer “background” questions.
Fine-tuning data preparation:
# Unzip fewshot-data.zip: unzip fewshot-data.zipFine-tuning training data:

Model fine-tuning training:
nohup sh finetune/finetune_visualglm.sh &Fine-tuned model inference:
python cli_demo.py --from_pretrained ./checkpoints --prompt_zh What is in the background of this image?Comparison of inference effects before and after fine-tuning:
Before fine-tuning:
Welcome to the VisualGLM-6B model, input image URL or local path to read the image, continue to input content dialogue, clear to restart, stop to terminate the program.
Please enter the image path or URL (press enter to enter pure text dialogue): fewshot-data/2p.png
User: What is in the background of this image?
VisualGLM-6B: People are always troubled by the trivialities of life, unable to break free from constraints.
User: clear
Please enter the image path or URL (press enter to enter pure text dialogue): fewshot-data/meme.png
User: What is in the background of this image?
VisualGLM-6B: The background of this image is a picture of a dog lying on a wooden floor.
User: clear
Please enter the image path or URL (press enter to enter pure text dialogue): fewshot-data/passport.png
User: What is in the background of this image?
VisualGLM-6B: The background of this image is a computer keyboard and two passports.
User: clear
Please enter the image path or URL (press enter to enter pure text dialogue):After fine-tuning:
Welcome to the VisualGLM-6B model, input image URL or local path to read the image, continue to input content dialogue, clear to restart, stop to terminate the program.
Please enter the image path or URL (press enter to enter pure text dialogue): fewshot-data/2p.png
User: What is in the background of this image?
VisualGLM-6B: The background of this image is rainy weather.
User: Describe this image.
VisualGLM-6B: This image depicts a rainy scene, with rain falling onto the ground. People are wearing raincoats or holding umbrellas, seemingly looking for something.
User: clear
Please enter the image path or URL (press enter to enter pure text dialogue): fewshot-data/meme.png
User: What is in the background of this image?
VisualGLM-6B: The background of this image is a wooden floor.
User: What color is the floor?
VisualGLM-6B: The background of this image is blue.
User: Describe this image.
VisualGLM-6B: This image depicts a brown puppy lying on a blue wooden floor.
User: clear
Please enter the image path or URL (press enter to enter pure text dialogue): fewshot-data/passport.png
User: What is in the background of this image?
VisualGLM-6B: The background of this image is a computer keyboard.
User: Describe this image.
VisualGLM-6B: The characteristics of this image are the computer keyboard and passports.
User: How many passports?
VisualGLM-6B: Two passports.
User: clear
Please enter the image path or URL (press enter to enter pure text dialogue):Conclusion
This practice shows that the local deployment of the VisualGLM-6B multimodal dialogue model works smoothly. This model performs well in image and text dialogue and also provides the functionality of fine-tuning the model. Based on this foundational capability, we believe that future multimodal application scenarios will be widely expanded.
References:
https://github.com/THUDM/VisualGLM-6B