

1 Introduction
A knowledge graph is a semantic network composed of nodes and edges. Nodes can be entities, such as a person or a book, or abstract concepts, such as artificial intelligence or knowledge graphs. Edges can represent attributes of entities, such as names or book titles, or relationships between entities, such as friends or spouses. The early concept of knowledge graphs originated from Tim Berners-Lee, the father of the web, who proposed the Semantic Web in 1998. Its initial ideal was to transform the text-linked World Wide Web into an entity-linked semantic web.
In 1989, Tim Berners-Lee proposed constructing a global “link-centric” information system (Linked Information System). Anyone could link their documents into it by adding links. He believed that a link-centric and graph-based organizational method was more suitable for the open system of the internet than a tree-based hierarchical organization. This idea was gradually realized and evolved into today’s World Wide Web.
In 1994, Tim Berners-Lee further proposed that the web should not merely be about linking web pages. In fact, the web pages describe entities in the real world and concepts in the human brain. The links between web pages inherently contain semantics, which represent the relationships between these entities or concepts. However, machines cannot effectively recognize the semantics contained in web pages. In 1998, he introduced the concept of the Semantic Web. The Semantic Web still relies on graph and link-based organization, but the nodes in the graph represent not just web pages but entities in the objective world (such as people, organizations, locations, etc.), and hyperlinks have also been enhanced with semantic descriptions, specifically indicating the relationships between entities (such as birthplace, founder, etc.). Compared to the traditional web, the essence of the Semantic Web is the internet of knowledge or the web of things.
After the introduction of the Semantic Web, a large number of emerging semantic knowledge bases appeared. For example, Freebase serves as the backend for Google Knowledge Graph, DBPedia and Yago serve as backends for IBM Watson, True Knowledge serves as the backend for Amazon Alexa, Wolfram Alpha serves as the backend for Apple’s Siri, and Schema.ORG aims to become the world’s largest open knowledge base, WikiData. Notably, in 2010, Google acquired the early semantic web company MetaWeb and used its developed Freebase as one of the data foundations, officially launching the search engine service called Knowledge Graph in 2012. Subsequently, knowledge graphs have played an increasingly important role in many fields, including semantic search, intelligent question answering, assisted language understanding, assisted big data analysis, enhancing the interpretability of machine learning, and combining graph convolution with image classification.
As shown in Figure 1, in essence, knowledge graphs aim to identify, discover, and infer complex relationships between things and concepts from data; they are computable models of relationships between things. The construction of knowledge graphs involves various technologies such as knowledge modeling, relationship extraction, graph storage, relationship reasoning, and entity merging, while the application of knowledge graphs encompasses multiple fields like semantic search, intelligent question answering, language understanding, and decision analysis. Effectively constructing and utilizing knowledge graphs requires a systematic integration of technologies related to knowledge representation, databases, natural language processing, and machine learning. This article attempts to summarize the connotations and extensions of knowledge graphs from the perspective of information system engineering, core technical elements and processes, and analyzes the development trends in several related fields, including intelligent question answering, language understanding, intelligent reasoning, databases, recommendation systems, and blockchain.
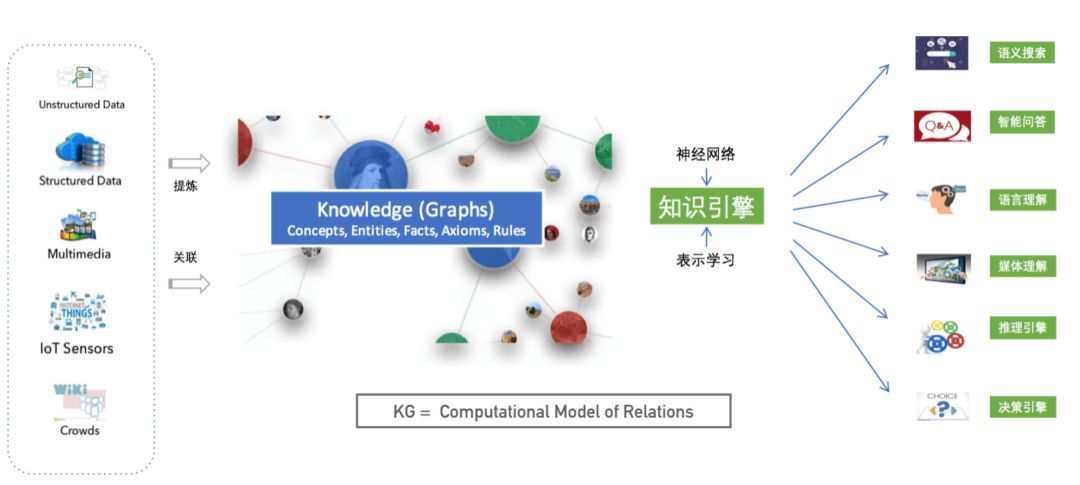
Figure 1 Knowledge Graph: A Computable Model of Relationships
2 Knowledge Graph from the Perspective of Information System Engineering
2.1 Scalable Development of Knowledge Graphs
Knowledge graphs are not a sudden new technology but rather the result of the historical interplay and development of many related technologies, including semantic networks, knowledge representation, ontology, Semantic Web, and natural language processing, possessing technical genes from multiple fields, such as the web, artificial intelligence, and natural language processing. From the early history of artificial intelligence development, the Semantic Web is the result of the fusion of traditional artificial intelligence and the web, applying knowledge representation and reasoning on the web; RDF/OWL are standardized knowledge representation languages designed for the web; and knowledge graphs can be seen as a simplified commercial implementation of the Semantic Web.
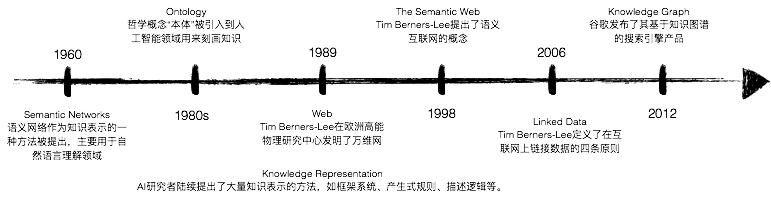
Figure 2 From Semantic Network to Knowledge Graph
In the early development of artificial intelligence, the symbolism school focused on simulating human cognition, studying how to use computer symbols to represent knowledge in the human brain and simulate the reasoning process of the mind; the connectionism school focused on simulating the physiological structure of the human brain through artificial neural networks. Symbolism has always been at the core of artificial intelligence research. In recent years, with the massive accumulation of data and significant improvements in computing power, deep learning has achieved breakthroughs in perception processing, such as vision and hearing, and has succeeded in fields like Go, game theory, and machine translation, positioning artificial neural networks and machine learning at the core of artificial intelligence research. Deep learning excels in processing perception, recognition, and judgment, helping to build intelligent AI. However, it still struggles with simulating human thought processes, handling common knowledge and reasoning, and understanding human language.
The core focus of symbolism is knowledge representation and reasoning (KRR). As early as 1960, cognitive scientist Allan M. Collins proposed using semantic networks to study semantic memory in the human brain. WordNet is a typical semantic network that defines semantic relationships between nouns, verbs, adjectives, and adverbs, such as the entailment relationship between verbs (e.g., “snoring” entails “sleeping”). WordNet is widely used in natural language processing fields such as semantic disambiguation.
In 1970, with the proposal and commercialization of expert systems, the construction of knowledge bases and knowledge representation received more attention. The basic idea of expert systems is that experts make decisions based on knowledge in their brains, so the core of artificial intelligence should be to represent this knowledge using computer symbols and to mimic the human brain’s processing of knowledge through reasoning machines. According to the perspective of expert systems, a computer system should consist of a knowledge base and a reasoning machine, rather than being composed of functions or procedural code. Early expert systems primarily used knowledge representation methods such as frame-based languages and production rules. Frame-based languages were mainly used to describe categories, individuals, attributes, and relationships in the objective world and were widely applied in assisting natural language understanding. Production rules were mainly used to describe IF-THEN logical structures, suitable for depicting procedural knowledge.
Knowledge graphs differ significantly from the knowledge engineering of traditional expert systems. Unlike traditional expert systems that mainly relied on experts to manually acquire knowledge, modern knowledge graphs are characterized by their massive scale, which cannot be constructed solely through manual input. Traditional knowledge bases, such as the common sense knowledge base Cyc, created by Douglas Lenat since 1984, contained only 7 million factual descriptions (Assertions). WordNet mainly relied on linguistic experts to define semantic relationships between nouns, verbs, adjectives, and adverbs, and currently contains about 200,000 semantic relationships. The well-known artificial intelligence expert Marvin Minsky started constructing the ConceptNet common sense knowledge base in 1999, relying on internet crowdsourcing, expert creation, and gamification methods, but the early ConceptNet had a scale in the millions, and the latest ConceptNet 5.0 contains only 28 million RDF triple relationship descriptions. Modern knowledge graphs, such as those from Google and Baidu, already contain over hundreds of billions of triples, and Alibaba’s knowledge graph, released in August 2017, containing only core product data, has also reached the tens of billions level. DBpedia contains about 3 billion RDF triples, the multilingual encyclopedic semantic network BabelNet contains 1.9 billion RDF triples, Yago 3.0 contains 130 million triples, and Wikidata already includes 42.65 million data entries, with the number of tuples reaching the tens of billions level. As of now, the Open Link Data project has counted 2,973 valid datasets, totaling approximately 149.4 billion triples.
The requirements for knowledge scale in modern knowledge graphs stem from the challenge of “knowledge completeness.” Von Neumann estimated that the total knowledge in an individual’s brain requires 2.4*10^20 bits for storage. The objective world contains countless entities, and the subjective world of humans includes countless concepts that cannot be quantified. These entities and concepts have numerous complex relationships, leading most knowledge graphs to face the dilemma of incomplete knowledge. In practical application scenarios, knowledge incompleteness is also the primary challenge faced by most semantic search, intelligent question answering, and knowledge-assisted decision analysis systems.
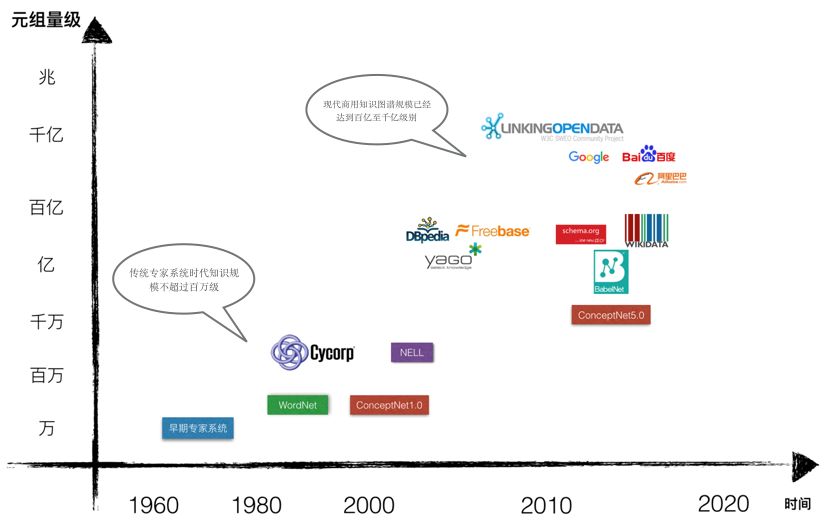
Figure 3 Scalable Development of Modern Knowledge Graphs
2.2 System Engineering of Scalable Knowledge Graphs
The engineering of scalable knowledge graphs requires a systematic integration of various technical means. As shown in Figure 4, the core processes of knowledge graph engineering include: knowledge modeling, knowledge extraction, knowledge fusion, knowledge reasoning, knowledge retrieval, and knowledge analysis. The general technical process includes: first determining the knowledge representation model, then selecting different knowledge acquisition methods based on data sources to import knowledge, and subsequently utilizing knowledge reasoning, knowledge fusion, and knowledge mining technologies to enhance the quality of the constructed knowledge graph. Finally, design different knowledge access and presentation methods according to scene requirements, such as semantic search, question-answer interaction, and graph visualization analysis. Below is a brief overview of the core technological elements of these technical processes.
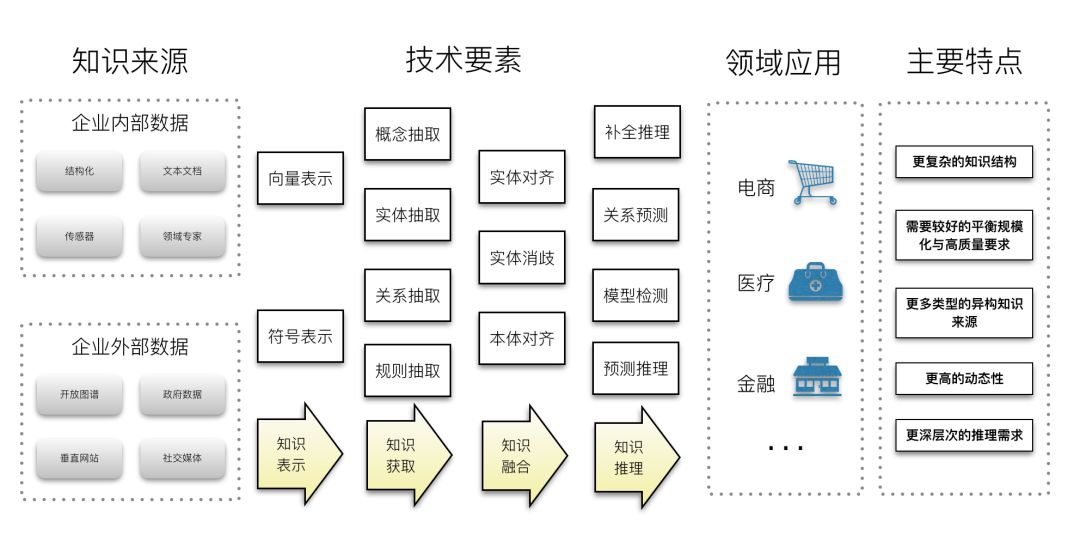
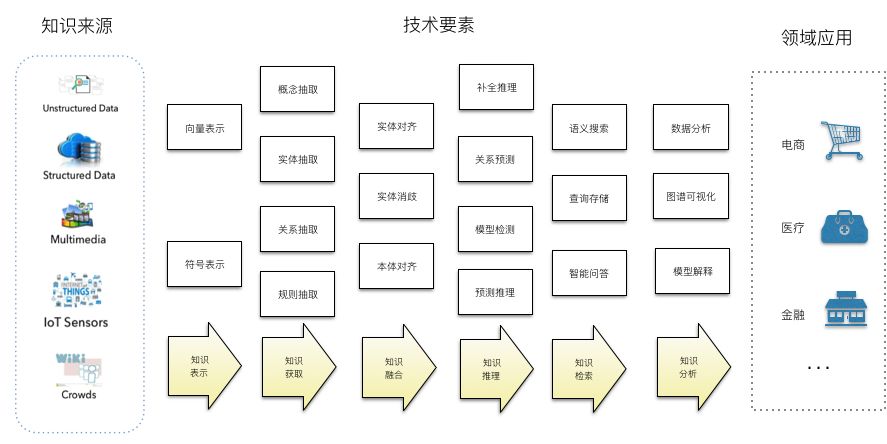
Figure 4 System Engineering of Scalable Knowledge Graphs
● Knowledge Sources
Knowledge graph data can be obtained from various sources, including text, structured databases, multimedia data, sensor data, and human crowdsourcing. Each type of data source requires a combination of different technical means to be transformed into knowledge. For example, for text data sources, various natural language processing technologies (entity recognition, entity linking, relationship extraction, event extraction, etc.) are needed to extract knowledge from text.
Structured databases, such as various relational databases, are also one of the most commonly used data sources. Typically, existing structured databases cannot be used directly as knowledge graphs and need to be transformed into knowledge graphs through semantic mapping between structured data and ontology models, followed by the development of semantic translation tools. Additionally, techniques like entity disambiguation, data fusion, and knowledge linking are required to enhance the standardization level of data and improve the relationships between data.
Semantic technologies are also used to semantically process data generated by sensors. This includes abstracting IoT devices, defining semantically compliant data interfaces, semantically encapsulating sensor data, and adding contextual semantic descriptions to sensor data.
Human crowdsourcing is an important means to obtain high-quality knowledge graphs. For example, WikiData and Schema.org are typical knowledge crowdsourcing techniques. Additionally, semantic annotation tools can be developed to assist humans in knowledge acquisition for various media data, including text and images.
● Knowledge Representation and Schema Engineering
Knowledge representation refers to the methods and technologies used to describe and represent human knowledge in computer symbols to support machine reasoning. Knowledge representation determines the output goals of graph construction, namely the semantic description framework of the knowledge graph (Description Framework), Schema and ontology, knowledge exchange syntax, and entity naming and ID systems.
The basic description framework defines the basic data model and logical structure of the knowledge graph, such as W3C’s RDF (Resource Description Framework). Schema and ontology define the class sets, attribute sets, relationship sets, and vocabulary sets of the knowledge graph. The exchange syntax defines the physical formats in which knowledge actually exists, such as Turtle and JSON. The entity naming and ID system defines the naming principles and unique identification specifications for entities.
In terms of knowledge types in knowledge graphs, they include: vocabulary, entities, relationships, events, taxonomies, and rules. Vocabulary-level knowledge centers around words and defines relationships between words, such as WordNet and ConceptNet. Entity-level knowledge centers around entities and defines relationships between entities, describing the terminology system of entities. Events are a type of composite entity.
W3C’s RDF uses triples as the basic data model, with its basic logical structure consisting of subject, predicate, and object. Although the expression of different knowledge bases may vary, they essentially contain elements related to entities, attributes of entities, and relationships between entities.
● Knowledge Extraction
Knowledge extraction can be divided into tasks such as concept extraction, entity recognition, relationship extraction, event extraction, and rule extraction. Traditional expert systems primarily relied on manual input by experts, making it difficult to scale. The construction of modern knowledge graphs usually relies on existing structured data resources to form a foundational dataset, followed by automated knowledge extraction and knowledge graph completion technologies to further expand the knowledge graph from various data sources, and human crowdsourcing to further enhance the quality of the knowledge graph.
Structured and text data are currently the main sources of knowledge. Knowledge is generally obtained from structured databases using existing D2R tools, such as Triplify, D2RServer, OpenLink, SparqlMap, Ontop, etc. Knowledge extraction from text primarily includes entity recognition and relationship extraction. Taking relationship extraction as an example, typical methods can be categorized into: feature-template-based methods, kernel-function-based supervised learning methods, remote supervision methods, and deep learning-based supervised or remote supervision methods.
● Knowledge Fusion
When constructing a knowledge graph, knowledge inputs can be obtained from third-party knowledge base products or existing structured data. For instance, the Linked Open Data project periodically publishes its accumulated and organized semantic knowledge data, which includes general knowledge bases like DBpedia and Yago, as well as domain-specific knowledge base products such as MusicBrainz and DrugBank. When multiple knowledge graphs are fused or external relational databases are merged into the ontology knowledge base, two levels of issues need to be addressed: A. Fusion at the schema level, integrating the newly acquired ontology into the existing ontology library and merging new and old ontologies; B. Fusion at the data level, including the alignment of entities, attributes, relationships, and categories, primarily addressing how to avoid conflicts between instances and relationships, leading to unnecessary redundancy.
Data-level fusion refers to the merging of entity and relationship (including attribute) tuples, primarily involving entity matching (or alignment). Since some entities in knowledge bases may have the same meaning but different identifiers, these entities need to be merged. Additionally, new entities and relationships must be validated and evaluated to ensure the consistency and accuracy of the knowledge graph’s content. This is typically done by assigning credibility values to newly added knowledge during the evaluation process, which is then used for filtering and merging knowledge. The entity alignment task includes entity disambiguation and co-reference resolution, which determine whether entities with the same name in the knowledge base represent different meanings and whether other named entities in the knowledge base represent the same meaning. Entity disambiguation is specifically used to resolve ambiguities arising from entities with the same name, usually employing clustering methods. The key issue is how to define the similarity between entity objects and their referring items, with common methods including spatial vector models, semantic models, social network models, encyclopedic knowledge models, and incremental evidence models. Some recent works utilize knowledge graph embedding methods for entity alignment and introduce human-machine collaboration to improve the quality of entity alignment.
Ontologies refer to schema definitions, conceptual models, and axiom definitions in specific domains, aiming to bridge the gaps of lexical heterogeneity and semantic ambiguity, achieving consensus in communication. This consensus is often reached through a repetitive process, where each iteration is a modification of the consensus. Therefore, ontology alignment typically leads to the evolution and change of consensus patterns. One of the main issues in ontology alignment can also be transformed into how to manage this evolution and change.
● Knowledge Graph Completion
Common knowledge graph completion methods include ontology reasoning-based completion methods, such as description logic-based reasoning, and related reasoning engine implementations. This reasoning primarily targets TBox, i.e., the concept layer, and can also be used to complete entity-level relationships.
Another category of knowledge completion algorithms is based on graph structures and relationship path features, such as PRA algorithms that obtain path features through random walks, SFE algorithms based on subgraph structures, and PRA algorithms based on hierarchical random walk models. These algorithms share the common feature of extracting features through paths between two entity nodes and the surrounding structure of the graph, reducing the complexity of feature extraction through random walks, and then overlaying linear learning models for relation prediction. Such algorithms rely on the richness of graph structures and paths.
More commonly, completion implementations are based on representation learning and knowledge graph embedding for link prediction. Simple models include the previously mentioned basic translation models, combination models, and neuron models. Such simple embedding models generally only achieve single-step reasoning. More complex models, such as those introducing random walk models in vector spaces, represent paths alongside entities and relationships within the same vector space for completion.
Text information is also used to assist in knowledge graph completion. For example, methods like Jointly(w), Jointly(z), DKRL, TEKE, and SSP align entities from text with entities in structured graphs, leveraging the semantic information from both sides to assist in relation prediction or extraction. These models typically consist of three parts: a triple decoder that converts entities and relations in the knowledge graph into low-dimensional vectors, a text decoder that learns vector representations of entities (words) from text corpora, and a joint decoder that ensures that entity/relation and word embedding vectors are located in the same space while integrating entity and word vectors.
● Knowledge Retrieval and Knowledge Analysis
Knowledge retrieval based on knowledge graphs primarily includes semantic retrieval and intelligent question answering. Traditional search engines rely on hyperlinks between web pages to achieve web searches, while semantic search directly searches for entities, such as people, organizations, and locations. These entities may come from various information resources, including text, images, videos, audio, and IoT devices. Knowledge graphs and semantic technologies provide descriptions of classifications, attributes, and relationships regarding these entities, allowing search engines to index and search for entities directly.
Knowledge graphs and semantic technologies are also used to assist in data analysis and decision-making. For instance, the big data company PLANTIR enhances the correlations between data by integrating multiple data sources through ontology fusion and knowledge graphs and semantic technologies, enabling users to conduct more intuitive graph-based data association mining and analysis. In recent years, descriptive data analysis has received increasing attention. Descriptive data analysis refers to methods that rely on the semantic descriptions of data themselves for analysis. Unlike computational data analysis, which primarily focuses on establishing various data analysis models like deep neural networks, descriptive data analysis emphasizes pre-extracting the semantics of data, establishing logical relationships between data, and using logical reasoning methods (such as DATALOG) for data analysis.
3 Development Trends and Outlook
3.1 System Engineering Thinking of Knowledge Graphs
Knowledge graphs can be viewed as a new type of information system infrastructure. From a data perspective, knowledge graphs require a more standardized semantics to enhance the quality of enterprise data, using the concept of linked data to improve the correlations between enterprise data. The ultimate goal is to gradually refine unstructured, loosely correlated raw data into structured, highly correlated high-quality knowledge. Every enterprise should regard knowledge graphs as a continuously constructed information system infrastructure oriented towards data.
From a technical perspective, the construction of knowledge graphs involves multiple technologies, including knowledge representation, relationship extraction, graph data storage, data fusion, and reasoning completion. The utilization of knowledge graphs encompasses various aspects such as semantic search, knowledge question answering, automated reasoning, knowledge-driven language and visual understanding, and descriptive data analysis. Effectively constructing and utilizing knowledge graphs requires a systematic and comprehensive use of technologies from related fields, such as knowledge representation, natural language processing, machine learning, graph databases, and multimedia processing, rather than relying on a single technology from one field. Therefore, a future development trend is that the construction and utilization of knowledge graphs should emphasize systematic thinking.
3.2 Large-Scale Knowledge Graph Embedding and Differentiable Reasoning Based on Representation Learning
The demand for scaling knowledge graphs has gradually led to changes in knowledge representation technology in multiple aspects: 1) shifting from a strong logic-centered approach to enhancing semantic expression capabilities as needed; 2) transitioning from a focus on TBox conceptual knowledge to a greater emphasis on ABox factual knowledge; 3) evolving from discrete symbolic logic representations to continuous vector space representations.
Although knowledge graph embedding based on continuous vector representations has gained increasing attention, it still faces significant challenges in practical applications. These include: A. The training and storage computing problems of embedding extremely large-scale knowledge graphs; B. The information loss issues and insufficient training of few-sample data during the embedding process. For problem A, more consideration is required to combine database technology and big data storage technology to address performance issues posed by large-scale knowledge graphs, rather than solely focusing on the scale of parameters. For problem B, there is a need to incorporate more logical rules and prior knowledge to guide the training process of knowledge graph embeddings.
Another development trend is learning-based differentiable reasoning. Differentiable reasoning parameterizes the elements relied upon in reasoning through statistical learning, making the reasoning process differentiable. Differentiable reasoning typically requires simultaneous learning of both structure and parameters, resulting in high complexity and difficulty. However, once realized, its significance lies in the ability to summarize and induce reasoning processes from large amounts of data, and these reasoning processes summarized from big data can be used to generate new knowledge.
3.3 Few-Sample and Unsupervised Knowledge Acquisition
The demand for large-scale construction of knowledge graphs brings several changes to knowledge acquisition: 1) shifting from single manual acquisition to more reliance on big data and machine learning for automated knowledge extraction; 2) transitioning from single sources to a comprehensive approach that integrates structured, semi-structured, text, sensor, and other sources, achieving joint knowledge acquisition through multi-task integration; 3) evolving from reliance on a few experts to crowdsourcing knowledge acquisition from internet communities.
The large-scale demand for automated knowledge acquisition poses higher requirements. Future main development trends include: 1) integrating deep learning with remote supervision to reduce the reliance of automated extraction on feature engineering and supervised data; 2) using reinforcement learning to reduce noise in extraction and lessen dependence on labeled data; 3) integrating various types of data for joint knowledge extraction through multi-task learning; 4) organically combining human crowdsourcing to improve the quality of knowledge extraction and strengthen supervisory signals. Achieving a good balance between human and automated extraction, minimizing the reliance of machines on labeled data and feature engineering while integrating knowledge from multiple sources for joint extraction, especially developing few-sample, unsupervised, and self-supervised methods, will be key factors in achieving large-scale knowledge acquisition in the future.
3.4 Blockchain and Decentralized Knowledge Graphs
The early concepts of the Semantic Web actually encompass three aspects: the interconnection of knowledge, decentralized architecture, and the trustworthiness of knowledge. Knowledge graphs, to some extent, realize the concept of “knowledge interconnection.” However, there are still no good solutions for decentralized architecture and knowledge trustworthiness.
Regarding decentralization, compared to the currently mostly centralized storage of knowledge graphs, the Semantic Web emphasizes that knowledge is interconnected and linked in a decentralized manner, with knowledge publishers retaining complete control. In recent years, research institutions and enterprises both domestically and internationally have begun exploring the use of blockchain technology to achieve decentralized knowledge interconnection. This includes decentralized entity ID management, terminology and entity naming management based on distributed ledgers, knowledge traceability, knowledge signing, and permission management based on distributed ledgers.
The trustworthiness and authenticity of knowledge is also a challenge faced by many knowledge graph projects. Due to the wide-ranging sources of knowledge graph data, and the need to measure the trustworthiness of knowledge at the entity and fact levels, effectively managing, tracking, and authenticating the vast number of facts in knowledge graphs has become an important application direction for blockchain technology in the field of knowledge graphs.
Additionally, incorporating knowledge graphs into smart contracts can help address the current lack of inherent knowledge in smart contracts. For instance, PCHAIN introduces a knowledge graph Oracle mechanism to resolve the issue of traditional smart contracts lacking a closed data loop.
4 Conclusion
The internet has facilitated the aggregation of big data, which in turn has promoted advancements in artificial intelligence algorithms. New data and new algorithms provide a new technical foundation and development conditions for the large-scale construction of knowledge graphs, leading to significant changes in the sources, methods, and technologies used in knowledge graph construction. As a form of knowledge, knowledge graphs have increasingly demonstrated their value in various areas, including semantic search, intelligent question answering, data analysis, natural language understanding, visual understanding, and interconnection of IoT devices. The AI wave is intensifying, and the underlying knowledge graph sector is gradually gaining traction, though it is not yet crowded. However, as an inevitable path to the future, it is destined to rise to prominence.