Follow our public account to discover the beauty of CV technology
This article is reprinted from Machine Heart.
In recent years, image generation models based on Diffusion Models have emerged one after another, showcasing stunning generation effects. However, existing research model code frameworks suffer from excessive fragmentation, lacking a unified framework system, leading to issues such as “difficult transfer,” “high thresholds,” and “poor quality” in code implementation.
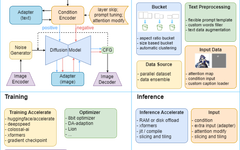
To address this, the Human-Computer-Object Intelligent Integration Laboratory (HCP Lab) at Sun Yat-sen University has built the HCP-Diffusion framework, systematically implementing model fine-tuning, personalized training, inference optimization, and image editing algorithms based on diffusion models, as shown in Figure 1.
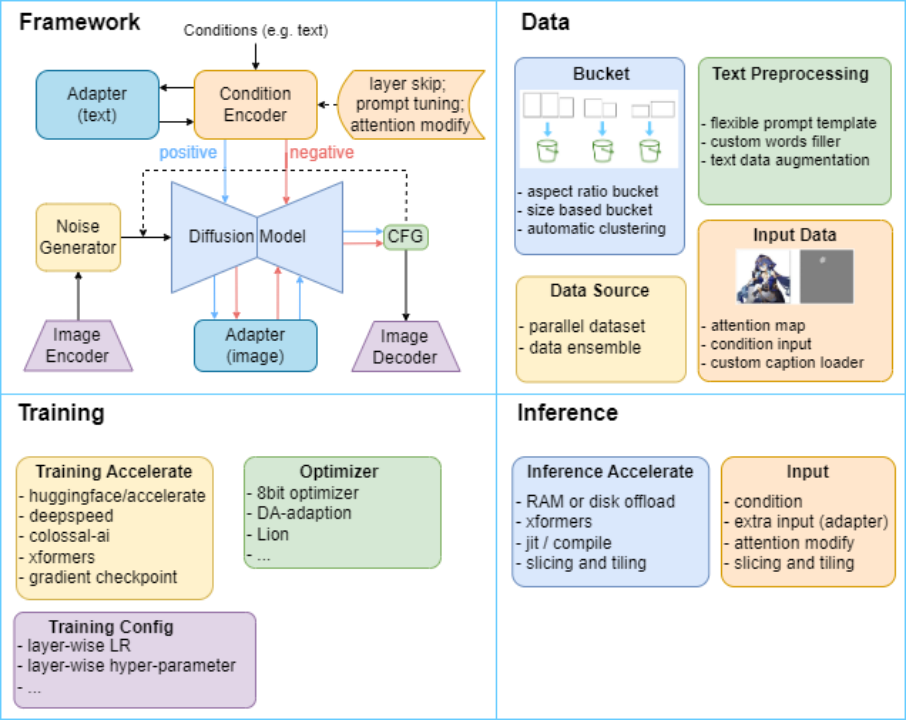
Figure 1 HCP-Diffusion framework structure diagram, unifying existing diffusion-related methods through a unified framework, providing various modular training and inference optimization methods.
HCP-Diffusion improves the flexibility and scalability of the framework significantly by coordinating various components and algorithms through uniformly formatted configuration files. Developers can combine algorithms like building blocks without having to repeatedly implement code details.
For example, based on HCP-Diffusion, we can deploy and combine various common algorithms such as LoRA, DreamArtist, and ControlNet simply by modifying the configuration file. This not only lowers the threshold for innovation but also allows the framework to be compatible with various customized designs.
-
HCP-Diffusion code tool: https://github.com/7eu7d7/HCP-Diffusion -
HCP-Diffusion graphical interface: https://github.com/7eu7d7/HCP-Diffusion-webui
HCP-Diffusion: Feature Module Introduction
Framework Features
HCP-Diffusion modularizes the currently mainstream diffusion training algorithm framework, achieving the generality of the framework, with the main features as follows:
-
Unified architecture: Building a unified code framework for diffusion series models -
Operator plugins: Supporting operators and algorithms for data, training, inference, and performance optimization, such as deepspeed, colossal-AI, and offload for acceleration optimization -
One-click configuration: Diffusion series models can be implemented by modifying configuration files with high flexibility -
One-click training: Provides a Web UI for one-click training and inference
Data Module
HCP-Diffusion supports defining multiple parallel datasets, each of which can use different image sizes and annotation formats. Each training iteration will draw one batch from each dataset for training, as shown in Figure 2. In addition, each dataset can configure multiple data sources, supporting txt, json, yaml, and other annotation formats or custom annotation formats, with a highly flexible data preprocessing and loading mechanism.
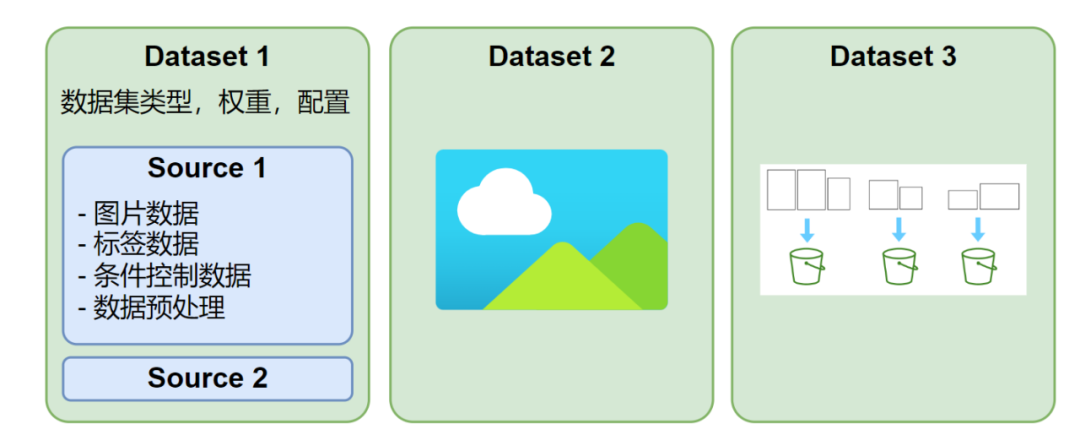
Figure 2 Dataset structure schematic diagram
The dataset processing part provides an aspect ratio bucket with automatic clustering, supporting the processing of datasets with varying image sizes. Users do not need to perform additional processing and alignment on dataset sizes; the framework will automatically choose the optimal grouping method based on the aspect ratio or resolution. This technology significantly lowers the threshold for data processing, optimizing user experience and allowing developers to focus more on the innovation of the algorithms themselves.
For image data preprocessing, the framework is also compatible with various image processing libraries such as torch vision and albumentations. Users can directly configure preprocessing methods in the configuration file as needed, or extend custom image processing methods based on this.
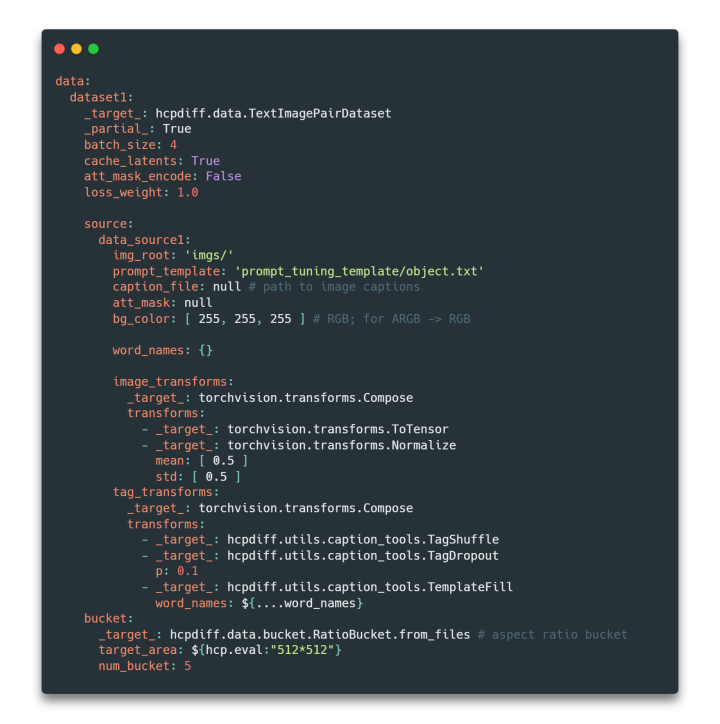
Figure 3 Example of dataset configuration file
In terms of text annotation, HCP-Diffusion designs a flexible and clear prompt template specification that supports a variety of complex training methods and data annotations. It applies the embedding word vectors and category descriptions corresponding to the special characters in the brackets of the word_names in the source directory of the above configuration file, making it compatible with models such as DreamBooth and DreamArtist.

Figure 4 Prompt template
Moreover, for text annotations, various text enhancement methods such as TagDropout for sentence erasure or TagShuffle for sentence shuffling are provided, which can reduce the overfitting problem between image and text data, making the generated images more diverse.
Model Framework Modules
HCP-Diffusion modularizes the currently mainstream diffusion training algorithm framework, achieving the generality of the framework. Specifically, Image Encoder and Image Decoder complete the encoding and decoding of images, Noise Generator generates noise for the forward process, Diffusion Model implements the diffusion process, Condition Encoder encodes the generation conditions, Adapter fine-tunes the model to align with downstream tasks, and positive and negative dual channels represent the control generation of images.

Figure 5 Example configuration for model structure (model plugins, custom words, etc.)
As shown in Figure 5, HCP-Diffusion can implement various mainstream training algorithms such as LoRA, ControlNet, and DreamArtist through simple combinations in the configuration file. It also supports the combination of the above algorithms, such as training LoRA and Textual Inversion simultaneously, binding exclusive trigger words for LoRA, etc. Additionally, through the plugin module, any plugin can be easily customized, and it is compatible with all mainstream methods. Through this modularization, HCP-Diffusion has achieved the framework construction for any mainstream algorithm, lowering the development threshold and promoting collaborative innovation of models.
HCP-Diffusion unifies various adapter-class algorithms such as LoRA and ControlNet into model plugins. By defining some common model plugin base classes, all such algorithms can be treated uniformly, reducing user and development costs and unifying all adapter-class algorithms.
The framework provides four types of plugins to easily support all mainstream algorithms:
+ SinglePluginBlock: A single-layer plugin that changes the output based on the input of that layer, such as the LoRA series. Supports regular expression (re: prefix) to define the insertion layer, does not support pre_hook: prefix.
+ PluginBlock: Both input and output layers have only one, such as defining residual connections. Supports regular expression (re: prefix) to define the insertion layer, both input and output layers support pre_hook: prefix.
+ MultiPluginBlock: Both input and output layers can have multiple, such as ControlNet. Does not support regular expression (re: prefix), both input and output layers support pre_hook: prefix.
+ WrapPluginBlock: Replaces a certain layer of the original model, treating the original layer of the model as an object of this class. Supports regular expression (re: prefix) to define the replacement layer, does not support pre_hook: prefix.
Training and Inference Modules

Figure 6 Custom optimizer configuration
The configuration files in HCP-Diffusion support defining python objects, which are automatically instantiated at runtime. This design allows developers to easily integrate any pip-installable custom modules, such as custom optimizers, loss functions, noise samplers, etc., without modifying the framework code, as shown in the above figure. The structure of the configuration file is clear, easy to understand, and has strong reproducibility, helping to smoothly connect academic research and engineering deployment.
Acceleration Optimization Support
HCP-Diffusion supports various training optimization frameworks such as Accelerate, DeepSpeed, and Colossal-AI, which can significantly reduce GPU memory usage during training and speed up training. It supports EMA operations, which can further improve the generation effect and generalization of the model. During the inference stage, it supports model offload and VAE tiling operations, requiring as little as 1GB of GPU memory to complete image generation.

Figure 7 Modular configuration file
Through the above simple file configuration, you can complete model configuration without spending a lot of effort searching for relevant framework resources, as shown in the above figure. The modular design of HCP-Diffusion completely separates model method definitions, training logic, inference logic, etc., allowing users to focus better on the methods themselves when configuring models without considering the logic of training and inference parts. At the same time, HCP-Diffusion has provided framework configuration examples for most mainstream algorithms; you can achieve deployment by modifying only a few parameters.
HCP-Diffusion: Web UI Image Interface
In addition to directly modifying configuration files, HCP-Diffusion has provided a corresponding Web UI image interface, including image generation, model training, and other modules to enhance user experience, significantly lowering the learning threshold of the framework and accelerating the transformation of algorithms from theory to practice.
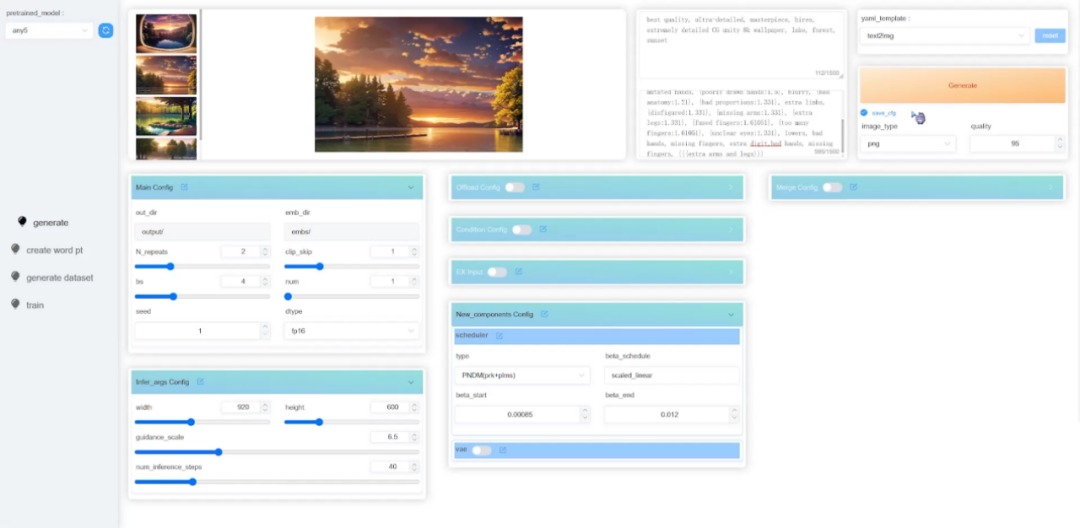
Figure 8 HCP-Diffusion Web UI image interface
Laboratory Introduction The Human-Computer-Object Intelligent Integration Laboratory (HCP Lab) at Sun Yat-sen University was founded by Professor Lin Jing in 2010. In recent years, it has achieved rich academic results in multimodal content understanding, causal and cognitive reasoning, and embodied learning, winning several domestic and international science and technology awards and best paper awards. It is committed to creating product-level AI technologies and platforms. Laboratory website: http://www.sysu-hcp.net

END
