
Follow Our Official Account to Discover the Beauty of CV Technology
The latest work from the Peking University team demonstrates that diffusion models can also achieve drag-and-drop image editing!
With just a click, you can make a snow mountain grow taller:

Or make the sun rise:

This is DragonDiffusion, brought to you by Professor Zhang Jian’s team at Peking University, under the VILLA (Visual-Information Intelligent Learning LAB), in collaboration with the Tencent ARC Lab and the Peking University Shenzhen Graduate School – Tujian Intelligent AIGC Joint Laboratory.
It can be understood as a variant of DragGAN.
DragGAN has now exceeded 30,000 stars on GitHub, with its underlying model based on GAN (Generative Adversarial Network).
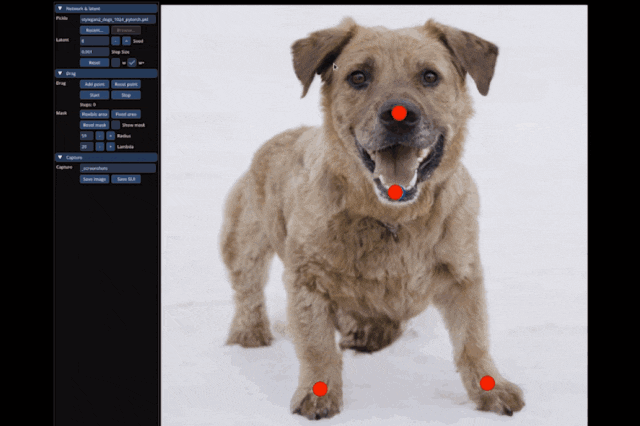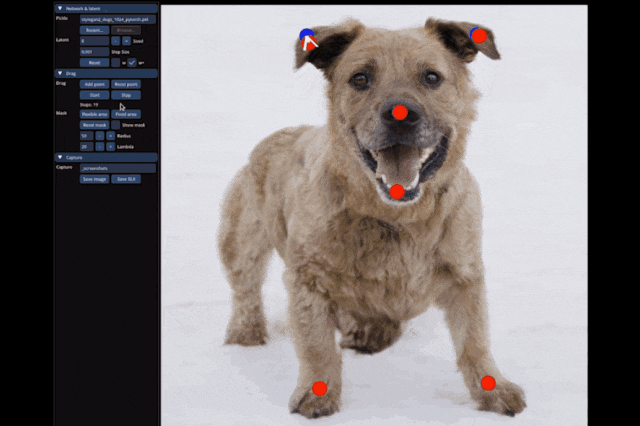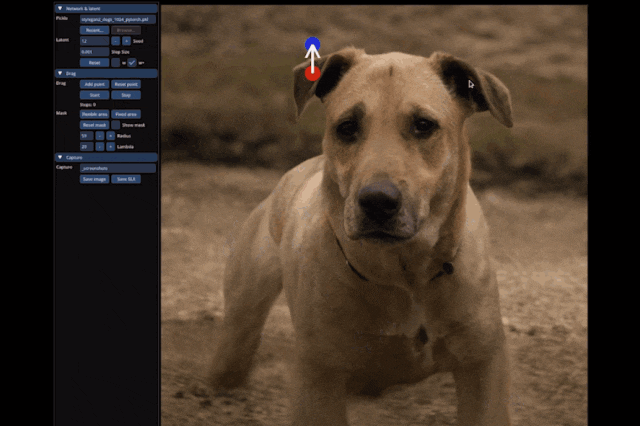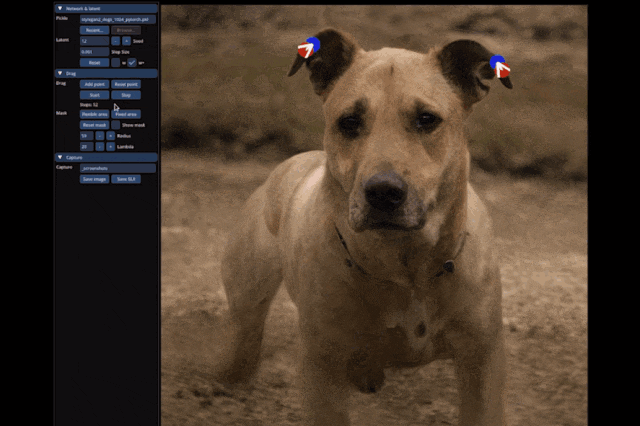
Historically, GANs have had shortcomings in generalization ability and image generation quality.
This is precisely the strength of diffusion models.
Thus, Professor Zhang Jian’s team has extended the DragGAN paradigm to the diffusion model.
This achievement topped the Zhihu hot list upon its release.
Some have commented that this solves the issue of certain deficiencies in images generated by Stable Diffusion, allowing for effective controlled redrawing. 
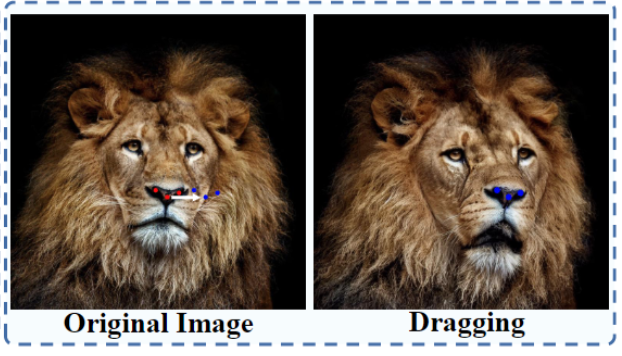
Turning a Lion’s Head in a Photo
Dragon Diffusion can also alter the shape of a car’s front:

Make a sofa gradually longer:

Or manually slim a face:

It can also replace objects in photos, like putting a donut into another image:

Or turning a lion’s head:
The method framework includes two branches: the guidance branch and the generation branch.
First, the image to be edited is represented in the diffusion latent space through the reverse process of diffusion, serving as input for both branches.
In the guidance branch, the original image is reconstructed, injecting information from the original image into the generation branch below.
The generation branch’s role is to edit the original image with guided information while maintaining consistency with the original content.
Based on the strong correspondence of intermediate features in the diffusion model, DragonDiffusion transforms the latent variables of both branches into the feature domain using the same UNet denoiser at each diffusion step.
Then, two masks are used to calibrate the position of the dragged content in both the original and edited images, constraining the content to appear in the designated area.
The paper measures the similarity between the two regions using cosine distance and normalizes this similarity:
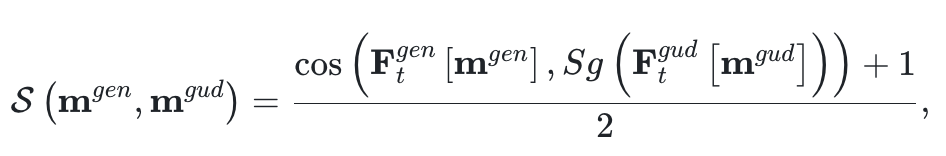
In addition to constraining the changes in edited content, consistency with the original image in unedited areas must also be maintained. This is similarly constrained through the similarity of corresponding regions. Ultimately, the total loss function is designed as:
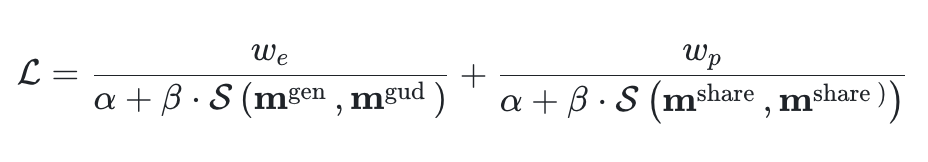
Regarding the injection of editing information, the paper views the conditional diffusion process as a joint score function through score-based diffusion:
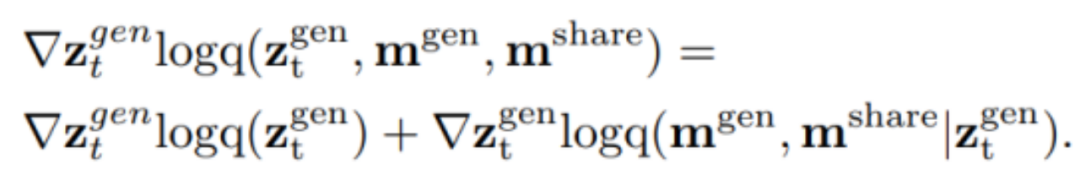
The editing signal is transformed into gradients through a score function based on strong feature correspondence, updating the latent variables in the diffusion process.
To balance semantic and graphical alignment, the authors introduce a multi-scale guidance alignment design based on this guiding strategy.
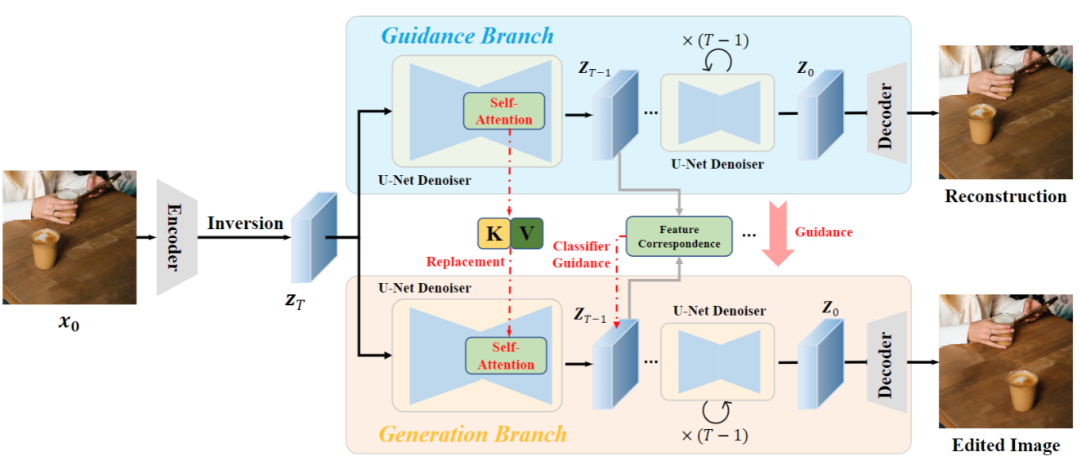
Furthermore, to further ensure consistency between the edited results and the original image, the DragonDiffusion method incorporates a cross-branch self-attention mechanism.
The specific approach involves replacing the Key and Value in the generation branch’s self-attention module with those from the guidance branch, thereby injecting reference information at the feature level.
Ultimately, the proposed method, due to its efficient design, offers various editing modes for generated and real images.
This includes moving objects within images, resizing objects, replacing object appearances, and dragging image content.
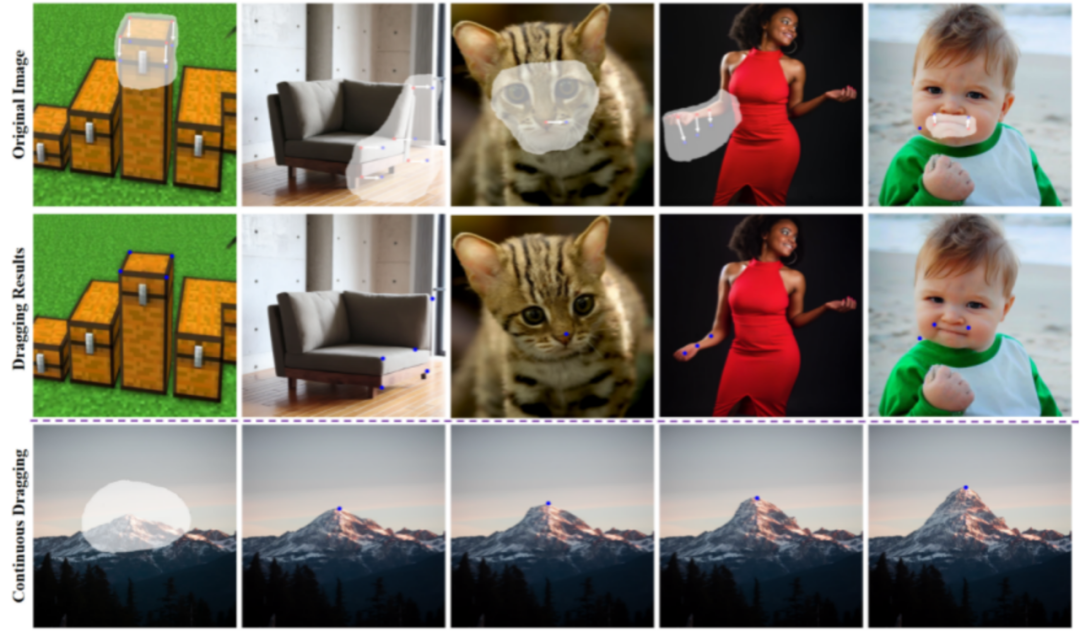
In this method, all content editing and saving signals come from the image itself, requiring no fine-tuning or training of additional modules, simplifying the editing process.
Researchers found in experiments that the first layer of the neural network was too shallow to accurately reconstruct images. However, if reconstruction was done at the fourth layer, it would be too deep, yielding poor results as well. The best effects were observed at the second/third layers.

Compared to other methods, Dragon Diffusion also shows better results in removal effects.

From Peking University’s Zhang Jian Team and Others
This achievement was jointly brought by Professor Zhang Jian’s team at Peking University, Tencent ARC Lab, and the Peking University Shenzhen Graduate School – Tujian Intelligent AIGC Joint Laboratory.
Professor Zhang Jian’s team previously led the development of T2I-Adapter, which allows for precise control over content generated by diffusion models.
It has garnered over 2,000 stars on GitHub.
This technology has been used officially by Stable Diffusion as the core control technology for the doodle generation tool, Stable Doodle.

The Tujian Intelligent AIGC Joint Laboratory established in collaboration with Peking University Shenzhen Graduate School has recently achieved breakthrough technological results in various fields such as image editing generation and legal AI products.
Just weeks ago, the Peking University-Tujian AIGC Joint Laboratory launched the large language model product, ChatLaw, which topped the Zhihu hot search, generating millions of exposures and sparking social discussions.
The joint laboratory will focus on multimodal large models centered on CV, continuing to delve into the ChatKnowledge large model behind ChatLaw to address hallucination issues, privatization, and data security in vertical fields like law and finance.
It is reported that the laboratory will soon launch an original large model that benchmarks against Stable Diffusion.
-
Paper Address: https://arxiv.org/abs/2307.02421 -
Project Homepage: https://mc-e.github.io/project/DragonDiffusion/

END
