
The framework and examples in this article are derived from the translation of https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/ and the content and code have been modified based on personal understanding. The examples in this article only handle training data and use five-fold cross-validation rate as the standard for measuring model performance. Code link: https://github.com/zhangleiszu/xgboost-
-
Simple Review of XGBoost Algorithm Principles
-
Advantages of XGBoost
-
Explanation of XGBoost Parameters
-
Parameter Tuning Example
-
Summary
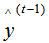 , the true result is y, and let L represent the loss function, then the current model’s loss function is:
, the true result is y, and let L represent the loss function, then the current model’s loss function is: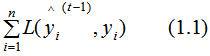
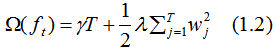
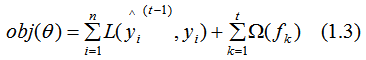
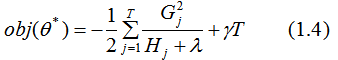
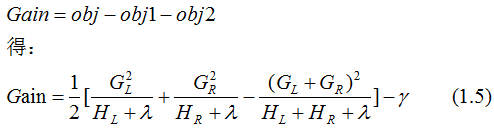
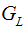 represents the sum of the second derivatives of the loss function for the left child node,
represents the sum of the second derivatives of the loss function for the left child node,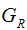 represents the sum of the second derivatives of the loss function for the right child node,
represents the sum of the second derivatives of the loss function for the right child node,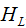 represents the sum of the first derivatives of the loss function for the left child node,
represents the sum of the first derivatives of the loss function for the left child node,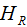 represents the sum of the first derivatives of the loss function for the right child node.
represents the sum of the first derivatives of the loss function for the right child node.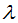 represents the regularization coefficient,
represents the regularization coefficient,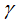 represents the difficulty of splitting nodes, and
represents the difficulty of splitting nodes, and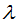 and
and 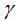 define the complexity of the tree. To simplify, once we have set the loss function L, the regularization coefficient
define the complexity of the tree. To simplify, once we have set the loss function L, the regularization coefficient 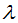 and the difficulty of splitting nodes
and the difficulty of splitting nodes 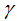 , the tree model can basically be determined. The three parameters are key considerations for XGBoost parameter selection.
, the tree model can basically be determined. The three parameters are key considerations for XGBoost parameter selection.-
booster [default = gbtree]
-
silent [default = 0]
When set to 0, it prints runtime information; when set to 1, it does not print runtime information.
-
nthread
Number of threads during XGBoost runtime, default is the maximum number of threads that can run on the current system.
-
num_pbuffer
Buffer size for prediction data, usually set to the size of the training samples. The buffer retains the prediction results after the last iteration, automatically set by the system.
-
num_feature
Sets the feature dimension to construct the tree model, automatically set by the system.
-
eta [default = 0.3]

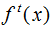 represents the output result of the first t trees combined with the model,
represents the output result of the first t trees combined with the model, 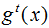 represents the t-th tree model, α represents the learning rate, controlling the weight of model updates.
represents the t-th tree model, α represents the learning rate, controlling the weight of model updates.-
gamma [default = 0]
-
lambda [default = 1]
-
alpha [default = 0]
-
max_depth [default=6]
-
min_child_weight [default=1]
-
subsample [default=1]
Represents the random sampling of a certain proportion of samples to construct each tree. Reducing the proportion parameter subsample value makes the algorithm more conservative, avoiding overfitting.
Range: [0,1]
-
colsample_bytree, colsample_bylevel, colsample_bynode
These three parameters represent random sampling of features and have a cumulative effect.
colsample_bytree represents the proportion of features split for each tree.
colsample_bylevel represents the proportion of features split for each level of the tree.
colsample_bynode represents the proportion of features split for each node of the tree.
For example, if there are 64 features in total, setting {‘colsample_bytree’ : 0.5 , ‘colsample_bylevel’ : 0.5 , ‘colsample_bynode’ : 0.5 } means that 4 features are randomly sampled for splitting at each node of the tree.
Range: [0,1]
-
tree_method string [default = auto ]
Indicates the method for constructing the tree, specifically the algorithm for selecting split points, including greedy algorithm, approximate greedy algorithm, histogram algorithm.
exact: greedy algorithm
aprrox: approximate greedy algorithm, selecting quantiles of features for splitting.
hist: histogram splitting algorithm, which is also used by the LightGBM algorithm.
-
scale_pos_weight [default = 1]
When there is an imbalance between positive and negative samples, setting this parameter to a positive value can accelerate algorithm convergence.
Typical values can be set as: (number of negative samples)/(number of positive samples).
-
process_type [default = default]
default: normal boosting tree construction process.
update: build boosting trees from existing models.
4. Parameter Tuning Example





Steps 3, 4, and 5 follow the same parameter tuning ideas as Step 2, which will not be elaborated on here. Please refer to the code for understanding.

