

1. Conceptual Literacy
-
Obtaining information expression from multiple different sources (different forms of information)
-
Representation (Multimodal Representation), for example, shift rotation without deformation, a representation studied in images
-
Redundancy problem of representation
-
Different signals, some are symbolic signals, some are wave signals, what kind of representation is convenient for multimodal models to extract information
-
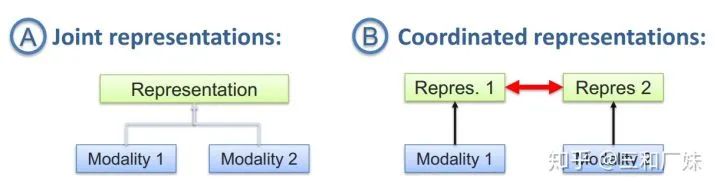
Joint representation maps the information of multiple modalities into a unified multimodal vector space
-
Cooperative representation is responsible for mapping each modality in multimodal to its respective representation space, but the mapped vectors satisfy certain correlation constraints.
-
Mapping of signals, for example, translating an image into text, translating text into images, transforming information into a unified form for later application
-
Methods, which overlap with the field of translation, involve instance-based translation, retrieval, dictionaries (rules), etc., and generative methods like generating translated content
-
Multimodal alignment is defined as finding the relationship and correspondence between instance components from two or more modalities, studying how different signals align (for example, finding which part of the script corresponds to a movie)
-
Alignment methods, there are specialized fields studying alignment, mainly two types: explicit alignment (for example, in the time dimension, this is explicit alignment) and implicit alignment (for example, language translation is not position-to-position)
-
For example, the fusion of tone and statements in sentiment analysis
-
This is the most difficult and most researched field, such as how to fuse syllables and lip-reading avatars; this note mainly writes about fusion methods
2. Applications
3. VQA Literacy and Common Methods
-
Given an image (video) and a natural language question related to that image, the computer can generate a correct answer. This is a combination of text QA and Image Captioning, usually involving reasoning about the image content, looking cooler (not referring to logic, just the intuitive feeling).
-
Joint embedding approaches, which start fusion information directly from the source encoding perspective. This naturally leads to the simplest and most straightforward method of directly concatenating the text and image embeddings (ps: this crude concatenation works well), Billiner Fusion is the most commonly used, the LR of the fusion field
-
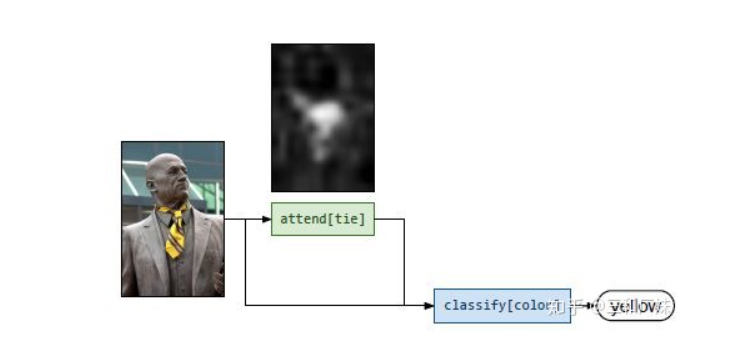
Attention mechanisms, many VQA problems focus on attention; attention itself is also an action of information extraction. Since “attention is all you need,” the application of attention has become fancy, and this article will later introduce several papers from CVPR2019
-
Compositional Models, this method solves problems by modularizing, with each module handling different functions, and then reasoning the results through module assembly
4. Several Methods of CV and NLP Fusion in Multimodal


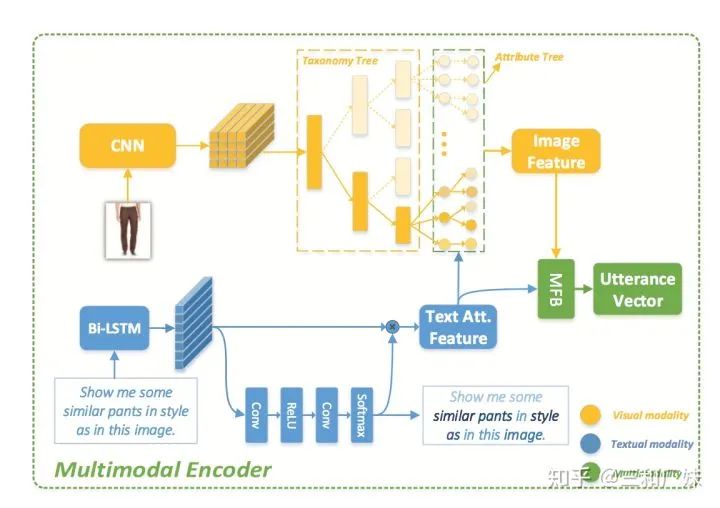
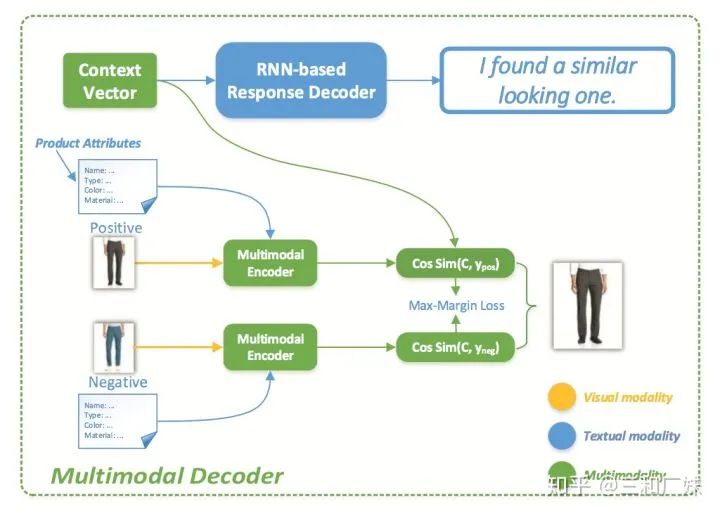
In all


References
-
Neural Module Networks
-
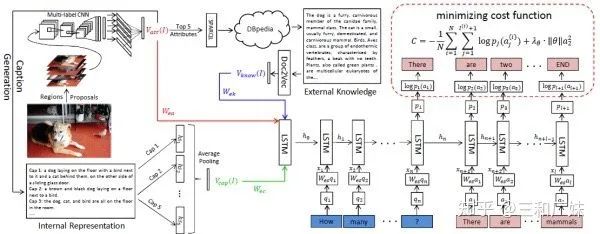
Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources
-
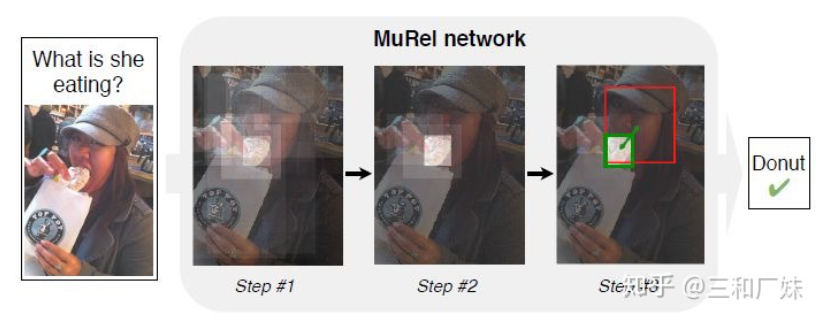
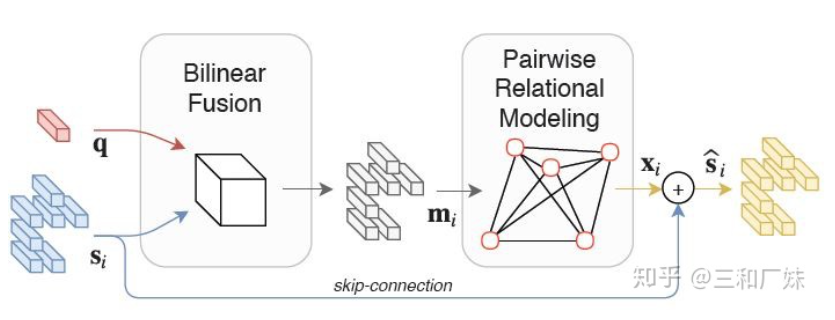
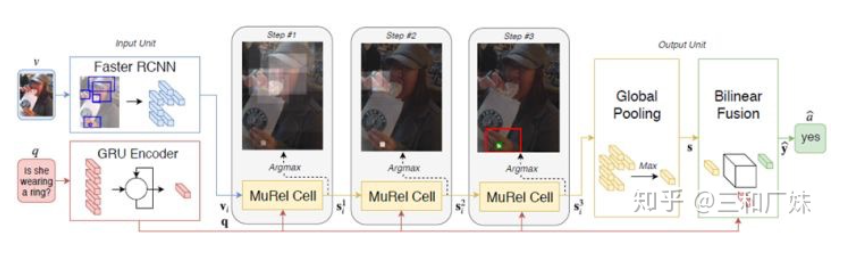
MUREL: Multimodal Relational Reasoning for Visual Question Answering
-
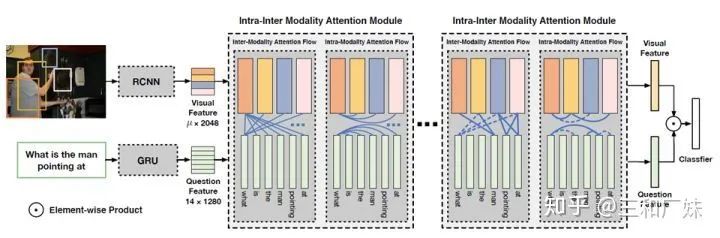
Dynamic Fusion with Intra- and Inter- Modality Attention Flow for Visual Question Answering
-
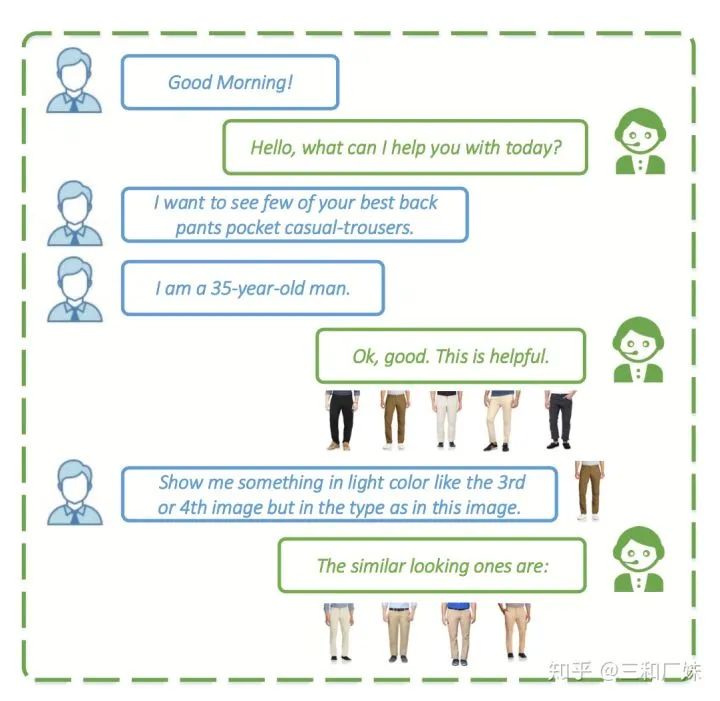
User Attention-guided Multimodal Dialog Systems
Download 1: Four-piece Set
Reply "Four-piece Set" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to get the learning materials for TensorFlow, Pytorch, Machine Learning, and Deep Learning!
Download 2: Repository Address Sharing
Reply "Code" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to get 195 NAACL + 295 ACL2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Heavy! The Machine Learning Algorithms and Natural Language Processing exchange group has been officially established! There are a lot of resources in the group, and everyone is welcome to join and learn!
Extra benefits! Resources on Deep Learning and Neural Networks, official Chinese tutorials for Pytorch, data analysis using Python, machine learning notes, official documentation for Pandas in Chinese, Effective Java (Chinese version), and 20 other welfare resources.
How to get: After entering the group, click on the group announcement to obtain the download link.
Note: Please modify the remarks when adding to [School/Company + Name + Direction].
For example - Harbin Institute of Technology + Zhang San + Dialogue System.
The account owner and WeChat merchants should consciously avoid this. Thank you!
Recommended Reading:
Implementation of NCE-Loss in Tensorflow and word2vec
Overview of Multimodal Deep Learning: Summary of Network Structure Design and Modality Fusion Methods
Awesome Adversarial Machine Learning Resource List