
Source丨Heart of Autonomous Driving
Editor丨Deep Blue Academy
What is Multimodal 3D Object Detection?
Multimodal 3D object detection is one of the current research hotspots in 3D object detection, mainly referring to the use of cross-modal data to improve the detection accuracy of the model. Generally speaking, multimodal data includes: image data, LiDAR data, millimeter-wave radar data, binocular depth data, etc. This article mainly focuses on summarizing and collating the RGB+LiDAR fusion 3D object detection models that are currently being researched more frequently, hoping to bring some inspiration to everyone.
Main Methods of Multimodal 3D Object Detection
(1) Decision-level Fusion
The so-called decision-level fusion generally refers to directly using the detection results of 2D/3D basic networks to provide initial positions for subsequent bounding box optimization. The advantage of decision-level fusion is that it only performs multimodal fusion on the outputs of different modalities, avoiding complex interactions on intermediate features or input point clouds, thus often being more efficient. However, it also faces certain drawbacks: because it does not rely on the depth features of camera and LiDAR sensors, these methods cannot integrate the rich semantic information of different modalities, limiting the potential of such methods.
Paper Title: CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection
Paper Address: https://arxiv.org/pdf/2009.00784.pdf
Author Affiliation: Su Pang et al., Michigan State University
Core Idea: The authors believe that for decision-level fusion, multimodal data does not need to be synchronized or aligned with other modalities, and using the detection results of both eliminates most redundant background areas, thus aiding network learning.
Method Summary:
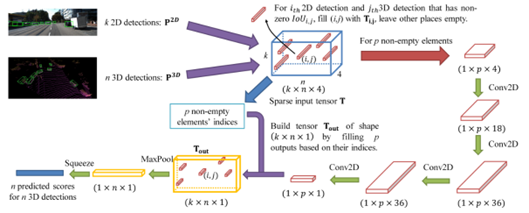
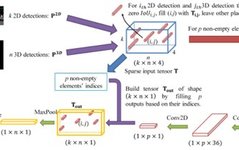
As shown in the figure above, the overall process of CLOCs can be divided into 3 steps:
-
Step 1: Input images and point clouds separately, predicting 2D detections and 3D detections; -
Step 2: Remove some candidate boxes with IoU=0, and extract features from the retained candidate boxes; -
Step 3: Obtain the final detection results.
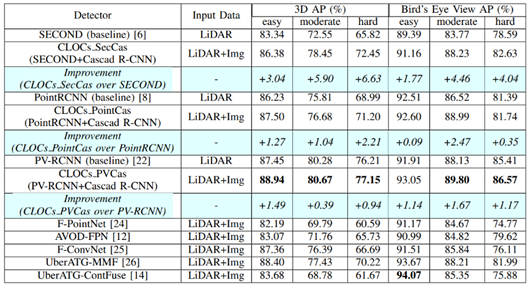
The method is relatively simple, and it can be clearly seen from Step 1 that CLOCs is a cross-modal fusion based on detection results, thus belonging to the category of decision-level fusion. The detection results on the KITTI test set are shown in the figure below, which is quite competitive among multimodal methods.
Paper Title: Frustum Pointnets for 3D Object Detection from RGB-D Data
Paper Address: https://arxiv.org/pdf/1711.08488.pdf
Author Affiliation: Charles R. Qi et al., Stanford University
Core Idea: The authors believe that using 2D object detection results to generate 3D frustum proposal regions omits direct retrieval in a large spatial area while improving the accuracy of object recognition.
Method Summary:
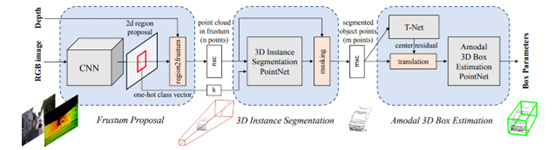
As shown in the figure above, the overall process of Frustum PointNet can be divided into 3 steps:
-
Step 1: Predict 2D Proposals through a 2D network; -
Step 2: Map the 2D Proposals into 3D frustums as suggested regions for subsequent 3D detection; -
Step 3: Conduct the general 3D detection process in the suggested regions extracted in Step 2;
Similarly, the overall idea is also quite simple and clear. From Step 1, it can be seen that Frustum PointNet uses 2D detection results to provide the initial region for 3D detection, thus greatly reducing the 3D search space. From the network process perspective, it is more concise and efficient. Meanwhile, with the initial position provided by the 2D proposal, the search position of the 3D network is also more accurate, and the overall detection performance is slightly improved, as shown in the detection results on the KITTI test set below.

(2) Feature-level Fusion
Feature-level fusion refers to the fusion of image and LiDAR features at intermediate stages of LiDAR-based 3D object detectors, such as in the backbone network, during the proposal generation phase, or in the RoI refinement phase.
1. RoI-level Fusion
RoI-level fusion typically refers to: generating 3D object proposals through a LiDAR detector, which are then mapped to multiple views, such as bird’s-eye view or RGB images. Features are then cropped from the Image and LiDAR backbone networks to obtain RoI Features, which are finally fused and input into the RoI head to output parameters for each 3D object.
Paper Title: Multi-View 3D Object Detection Network for Autonomous Driving
Paper Address: https://arxiv.org/pdf/1611.07759.pdf
Author Affiliation: Xiaozhi Chen et al., Tsinghua University
Core Idea: By using point cloud bird’s-eye view, point cloud front view, and image data for fusion, this approach reduces computational load while preserving information.
Method Summary:
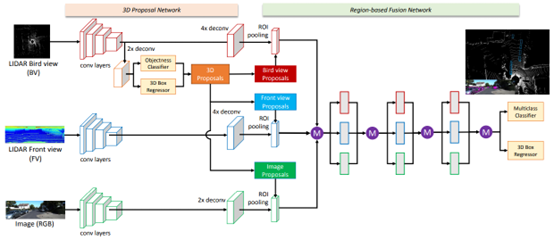
As shown in the figure above, the overall process of MV3D can be divided into 4 steps:
-
Step 1: Use convolutional networks to extract features from point cloud front view, point cloud bird’s-eye view, and image data; -
Step 2: Generate proposals in the point cloud bird’s-eye view; -
Step 3: Extract features from the generated 3D proposals in different modal data; -
Step 4: Perform fusion detection on the multimodal proposal features;
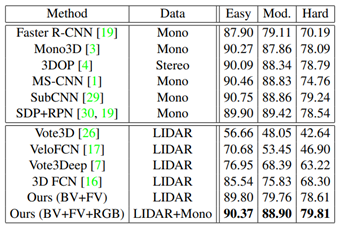
From Step 3, it can also be seen that MV3D uses the 3D detection results generated from the point cloud bird’s-eye view to extract features in different modal data, thus belonging to the RoI-level fusion method. In the KITTI test set, this multimodal fusion method also has significant advantages. Especially when image data is added, the overall network shows a notable performance improvement on the Moderate subset, as shown in the experimental results below:
Paper Title: Joint 3D Proposal Generation and Object Detection from View Aggregation
Paper Address: https://arxiv.org/pdf/1712.02294.pdf
Author Affiliation: Jason Ku et al., University of Waterloo
Core Idea: Borrowing the FPN idea to enhance detection performance through high-resolution features.
Method Summary:

As shown in the figure above, the overall process of AVOD can be divided into 4 steps:
-
Step 1: Extract features from images and bird’s-eye view separately; -
Step 2: Use the fused features to extract 3D Proposals; -
Step 3: Extract features from the generated 3D proposals in different modal data; -
Step 4: Perform fusion detection on the multimodal proposal features;
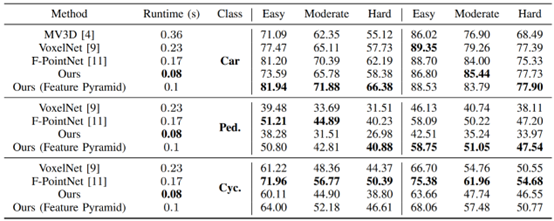
From the above steps, it can also be seen that the overall detection process is not significantly different from MV3D. The main distinguishing points are: firstly, AVOD borrows the feature extraction method from FPN, resulting in more efficient feature extraction; secondly, it designs a 10-dimensional bounding box encoding strategy, encoding through ground plane and top bottom corner center, making it more concise and efficient. The overall network performance shows good results on KITTI, especially for the Pedestrian and Cyclist categories, as shown in the figure below:
Paper Title: Cross-Modality 3D Object Detection
Paper Address: https://arxiv.org/pdf/2008.10436.pdf
Author Affiliation: Ming Zhu et al., Shanghai Jiao Tong University
Core Idea: Proposes a 2D-3D coupling loss to fully utilize image information, constraining the 3D Bounding box to be consistent with the 2D Bounding box.
Method Summary:
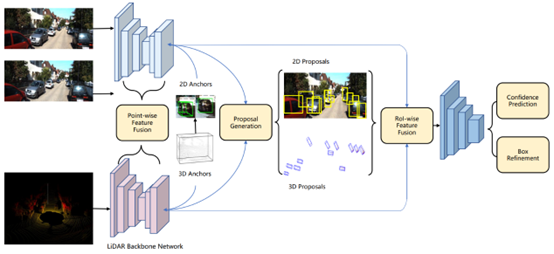
-
Step 1: Use convolutional networks to extract features from point clouds and image data separately; -
Step 2: Use the extracted features to extract 2D Proposal and 3D Proposal; -
Step 3: Apply consistency constraints to the generated 2D and 3D Proposals; -
Step 4: Perform fusion detection on the constrained proposal features;
From Step 2, it can also be seen that this method utilizes the generated 2D and 3D detection results to extract features in different modal data, thus belonging to the RoI-level fusion method. The difference in this method is that the authors propose a 2D-3D coupling loss to constrain the consistency of Proposals in the 3D and 2D scenes. This method shows a significant improvement on KITTI, as shown in the specific results below:
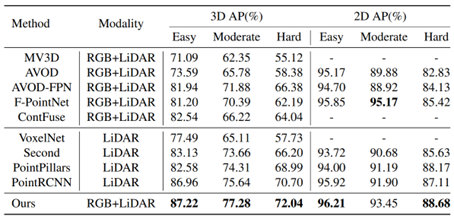
Paper Title: Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion
Paper Address: https://arxiv.org/pdf/2203.09780.pdf
Author Affiliation: Xiaopei Wu et al., Zhejiang University
Core Idea: Multimodal feature weighted fusion and cross-modal alignment issues.
Method Summary:
As shown in the figure above, the overall method can be divided into 4 steps:
-
Step 1: Use depth completion networks to map the original RGB images into 3D scenes, generating pseudo points; -
Step 2: Extract features from the original 3D point cloud and generate candidate boxes; -
Step 3: For each candidate box, extract features from both point cloud features and pseudo point cloud features; -
Step 4: Re-weight the point cloud features and pseudo point cloud features and output the final detection results;
From Step 2, it can be seen that SFD uses candidate boxes predicted from the 3D scene and extracts features in different modal data, thus belonging to the RoI-level fusion category. The difference in this method is: firstly, in the network preprocessing stage, cross-modal data augmentation is aligned, making the features more consistent; secondly, the multimodal features of the candidate boxes are weighted to output a more robust fusion feature. This method shows very superior performance on the KITTI test set, as shown in the specific experimental results below:
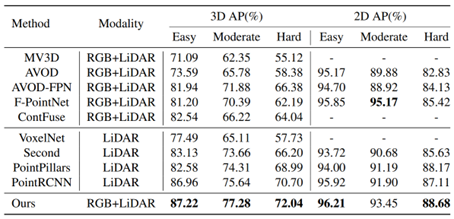
2. Point/Voxel-level Fusion
Point/Voxel-level fusion usually refers to the alignment of features from other modalities for each point or voxel box in the point cloud scene. This type of completion is often more refined and comprehensive, but it also tends to be less efficient.
Paper Title: Multi-task Multi-Sensor Fusion for 3D Object Detection
Paper Address: https://arxiv.org/pdf/2012.12397.pdf
Author Affiliation: Ming Liang et al., Uber Advanced Technologies Group
Core Idea: Pixel-point level fusion method, while adding a depth estimation module.
Method Summary:
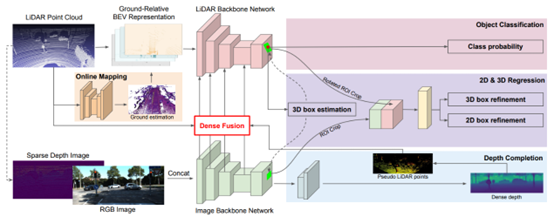
As shown in the figure above, the overall method can be divided into 4 steps:
-
Step 1: Extract features from point clouds and images separately; -
Step 2: Use the Dense Fusion module to perform feature fusion at different levels of the network; -
Step 3: Use the fused features to calculate the initial proposal; -
Step 4: Predict bounding boxes and depth maps;
From Step 2, it can be seen that MMF performs feature fusion at different stages of the base network, belonging to full scene fusion, thus can be classified as Point/Voxel-level. The subsequent detection process does not have significant areas compared to general 3D detection; it only adds a depth prediction branch for mapping calibration from image to point cloud. The authors also provide the detection results on the KITTI test set, as shown in the figure below:
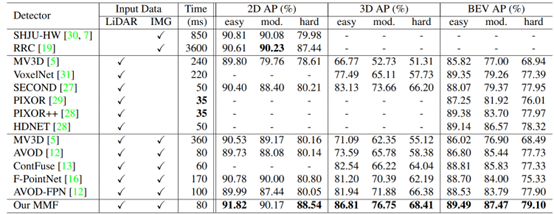
Paper Title: MVX-Net: Multimodal VoxelNet for 3D Object Detection
Paper Address: https://arxiv.org/pdf/1904.01649.pdf
Author Affiliation: Vishwanath A. Sindagi et al., Johns Hopkins University
Core Idea: Early fusion in the network to extract richer and more robust features.
Method Summary:
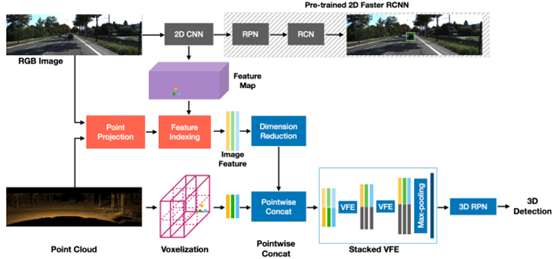
As shown in the figure above, the overall method can be divided into 3 steps:
-
Step 1: Extract features from point clouds and images separately; -
Step 2: Find the correspondence between 3D voxels and 2D images and perform corresponding feature fusion; -
Step 3: Use the fused features to predict 3D detection results;
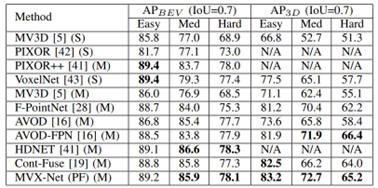
From Step 2, it can be seen that the authors also perform scene-level fusion rather than proposal/bbox fusion, thus belonging to Point/Voxel-level. The overall network framework is also relatively simple, with certain performance improvements on the KITTI test set, as shown in the figure below:
Paper Title: Pointpainting: Sequential Fusion for 3D Object Detection
Paper Address: https://arxiv.org/pdf/1911.10150.pdf
Author Affiliation: Sourabh Vora et al., nuTonomy
Core Idea: Using fine-grained image segmentation information to complete the 3D point cloud.
Method Summary:
As shown in the figure above, the overall method can be divided into 3 steps:
-
Step 1: Perform segmentation prediction on the 2D image; -
Step 2: Project the predicted segmentation results from the 2D image onto the corresponding 3D points to complete the original 3D information; -
Step 3: Use the completed 3D point cloud for prediction;
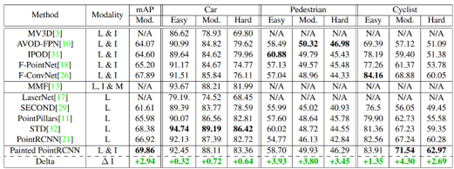
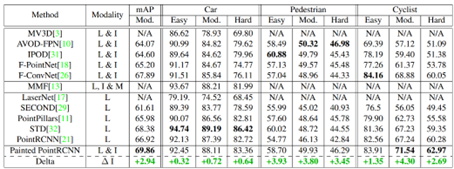
From Step 2, it can be seen that the authors attempt to complete the information for each point in the 3D scene, thus belonging to the point-level fusion method. PointPainting is a relatively classic method, and its ideas are widely applied in current 3D detection networks. Although the method is relatively simple, the performance improvement is significant, as shown in the experimental results on the KITTI test set below:
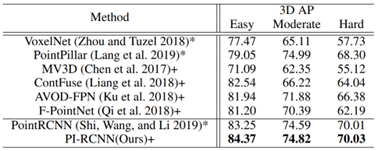
Paper Title: PI-RCNN: An Efficient Multi-Sensor 3D Object Detector with Point-based Attentive Cont-Conv Fusion Module
Paper Address: https://arxiv.org/pdf/1911.06084.pdf
Author Affiliation: Liang Xie et al., Zhejiang University
Core Idea: The alignment issue during the fusion of point clouds and images (quantization error).
Method Summary:
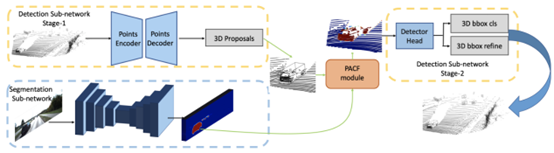
As shown in the figure above, the overall method can be divided into 4 steps:
-
Step 1: Use the original point cloud data to predict 3D candidate boxes; -
Step 2: Use the segmentation network to predict 2D segmentation results; -
Step 3: Use the PACF module to align the 2D and 3D features, reducing quantization errors; -
Step 4: Use the aligned features to predict 3D bounding boxes;
This method falls into the Point/Voxel-level category mainly because the authors search for K nearest points for each point on the point cloud in the PACF module and project them onto the segmentation feature map. Then, they use the semantic information of the neighboring points and point cloud information for feature association, outputting the final detection results. Therefore, essentially, the PI-RCNN network belongs to the Point-level fusion method, showing significant performance on the KITTI test set, as shown in the figure below:
Paper Title: EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection
Paper Address: https://arxiv.org/pdf/2007.08856.pdf
Author Affiliation: Tengteng Huang et al., Huazhong University of Science and Technology
Core Idea: Layer-wise fusion and adaptive weighted multimodal features.
Method Summary:
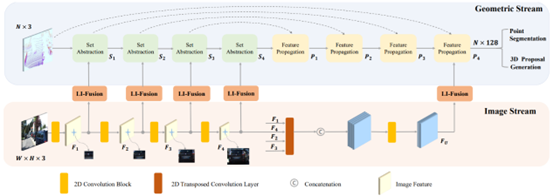
As shown in the figure above, the overall method can be divided into 4 steps:
-
Step 1: Extract image features and point cloud features separately; -
Step 2: Use the LI-Fusion module to perform layer-wise fusion of multimodal features; -
Step 3: Use the Feature Propagation module to adaptively weight the multimodal features; -
Step 4: Use the weighted features to predict 3D bounding boxes;
From Steps 2 and 3, it can be seen that the authors propose a LIDAR-guided Image Fusion (LI-fusion) module that establishes a correspondence between the original point cloud and the image in a point-wise manner, adaptively estimating the importance of the image semantic features, enhancing point cloud features with useful image features while suppressing interfering image features. EPNet shows a significant performance improvement on the KITTI test set, as shown in the figure below:
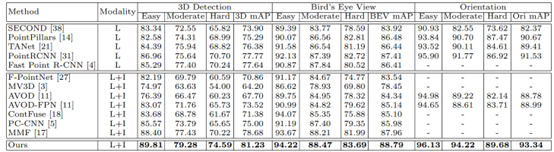
Figure 21: EPNet Experimental Result Diagram (KITTI test set)
ABOUT
关于我们
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。