Click the “Beginner’s Guide to Vision” above, and choose to add “Star” or “Top“
Heavy content delivered promptly
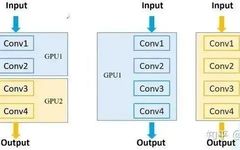
Why Use Multi-GPU Parallel Training
Common Multi-GPU Training Methods:

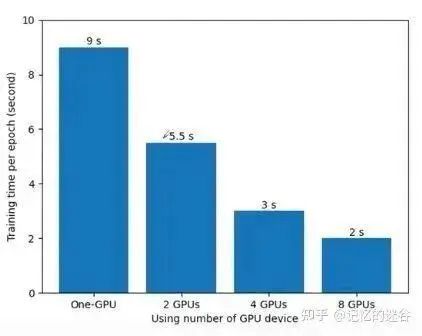
How Do Error Gradients Communicate Between Different Devices?
How Is Batch Normalization Synchronized Between Devices?

Two GPU Training Methods: DataParallel and DistributedDataParallel:
-
DataParallel is single-process multi-threaded and can only operate on a single machine. In contrast, DistributedDataParallel is multi-process and can work on a single machine or multiple machines. -
DataParallel is generally slower than DistributedDataParallel. Therefore, the mainstream method currently is DistributedDataParallel.
Common GPU Initialization Methods in PyTorch:

def init_distributed_mode(args):# If it is a multi-machine multi-GPU setup, WORLD_SIZE represents the number of machines used, RANK corresponds to which machine# If it is a single machine with multiple GPUs, WORLD_SIZE represents how many GPUs there are, RANK and LOCAL_RANK represent which GPU if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ: args.rank = int(os.environ["RANK"]) args.world_size = int(os.environ['WORLD_SIZE'])# LOCAL_RANK represents which GPU on a certain machine args.gpu = int(os.environ['LOCAL_RANK']) elif 'SLURM_PROCID' in os.environ: args.rank = int(os.environ['SLURM_PROCID']) args.gpu = args.rank % torch.cuda.device_count()else: print('Not using distributed mode') args.distributed = False args.distributed = True torch.cuda.set_device(args.gpu) # Specify which GPU to use for the current process args.dist_backend = 'nccl'# Communication backend, NCCL is recommended for NVIDIA GPUs dist.barrier() # Wait for each GPU to finish this point before continuingdef main(args):if torch.cuda.is_available() is False:raise EnvironmentError("not find GPU device for training.") # Initialize environment for each processinit_distributed_mode(args=args)rank = args.rankdevice = torch.device(args.device)batch_size = args.batch_sizenum_classes = args.num_classesweights_path = args.weightsargs.lr *= args.world_size # The learning rate should be multiplied by the number of parallel GPUs# Assign training sample indices to each rank's corresponding processtrain_sampler = torch.utils.data.distributed.DistributedSampler(train_data_set)val_sampler = torch.utils.data.distributed.DistributedSampler(val_data_set)# Form a list of sample indices for each batch of size batch_size train_batch_sampler = torch.utils.data.BatchSampler(train_sampler, batch_size, drop_last=True)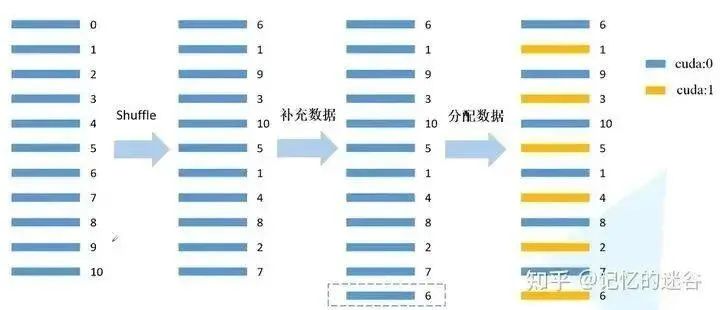
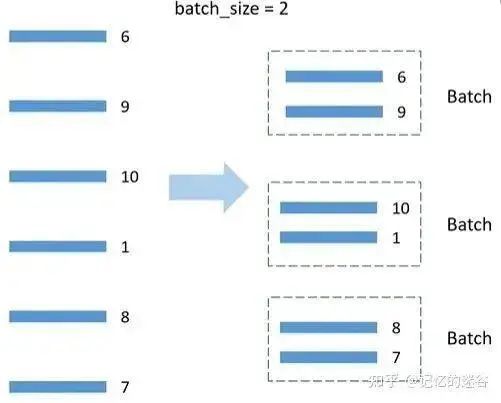
train_loader = torch.utils.data.DataLoader(train_data_set, batch_sampler=train_batch_sampler, pin_memory=True, # Directly load into memory for accelerationnum_workers=nw, collate_fn=train_data_set.collate_fn)val_loader = torch.utils.data.DataLoader(val_data_set, batch_size=batch_size, sampler=val_sampler, pin_memory=True, num_workers=nw, collate_fn=val_data_set.collate_fn)# Instantiate the model model = resnet34(num_classes=num_classes).to(device)# If pre-trained weights exist, load themif os.path.exists(weights_path): weights_dict = torch.load(weights_path, map_location=device)# Simply compare the number of weight parameters for each layer load_weights_dict = {k: v for k, v in weights_dict.items() if model.state_dict()[k].numel() == v.numel()} model.load_state_dict(load_weights_dict, strict=False)else: checkpoint_path = os.path.join(tempfile.gettempdir(), "initial_weights.pt")# If pre-trained weights do not exist, the first process should save the weights, and other processes should load the weights saved by the main process to keep the initialization weights consistentif rank == 0: torch.save(model.state_dict(), checkpoint_path) dist.barrier()# Note: Be sure to specify the map_location parameter, or it may lead to the first GPU using more resources model.load_state_dict(torch.load(checkpoint_path, map_location=device))# Whether to freeze weightsif args.freeze_layers:for name, para in model.named_parameters():# Freeze all weights except for the last fully connected layer if "fc" not in name: para.requires_grad_(False)else:# Only use SyncBatchNorm when training networks with BN structureif args.syncBN:# Training will take longer with SyncBatchNorm model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)# Convert to DDP model model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])# Use SGD + cosine annealing strategy pg = [p for p in model.parameters() if p.requires_grad] optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=0.005) lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)for epoch in range(args.epochs):train_sampler.set_epoch(epoch) mean_loss = train_one_epoch(model=model, optimizer=optimizer, data_loader=train_loader, device=device, epoch=epoch)scheduler.step()sum_num = evaluate(model=model, data_loader=val_loader, device=device)acc = sum_num / val_sampler.total_sizedef train_one_epoch(model, optimizer, data_loader, device, epoch): model.train() loss_function = torch.nn.CrossEntropyLoss() mean_loss = torch.zeros(1).to(device) optimizer.zero_grad()# Print training progress in process 0if is_main_process(): data_loader = tqdm(data_loader)for step, data in enumerate(data_loader): images, labels = data pred = model(images.to(device)) loss = loss_function(pred, labels.to(device)) loss.backward() loss = reduce_value(loss, average=True) # In single GPU, this does not work; in multi-GPU, it gets the mean of loss from all GPUs. mean_loss = (mean_loss * step + loss.detach()) / (step + 1) # update mean losses# Print average loss in process 0if is_main_process(): data_loader.desc = "[epoch {}] mean loss {}".format(epoch, round(mean_loss.item(), 3))if not torch.isfinite(loss): print('WARNING: non-finite loss, ending training ', loss) sys.exit(1) optimizer.step() optimizer.zero_grad()# Wait for all processes to finish calculatingif device != torch.device("cpu"): torch.cuda.synchronize(device)return mean_loss.item()def reduce_value(value, average=True): world_size = get_world_size()if world_size < 2: # Single GPU casereturn valuewith torch.no_grad(): dist.all_reduce(value) # Sum the value across different devicesif average: # If averaging is needed, get the mean of loss from multiple GPUsvalue /= world_sizereturn value@torch.no_grad()def evaluate(model, data_loader, device): model.eval()# Used to store the number of correctly predicted samples; each GPU calculates its own correct sample count sum_num = torch.zeros(1).to(device)# Print validation progress in process 0if is_main_process(): data_loader = tqdm(data_loader)for step, data in enumerate(data_loader): images, labels = data pred = model(images.to(device)) pred = torch.max(pred, dim=1)[1] sum_num += torch.eq(pred, labels.to(device)).sum()# Wait for all processes to finish calculatingif device != torch.device("cpu"): torch.cuda.synchronize(device) sum_num = reduce_value(sum_num, average=False) # Number of correctly predicted samplesreturn sum_num.item()if rank == 0:print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3))) tags = ["loss", "accuracy", "learning_rate"] tb_writer.add_scalar(tags[0], mean_loss, epoch) tb_writer.add_scalar(tags[1], acc, epoch) tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch) torch.save(model.module.state_dict(), "./weights/model-{}.pth".format(epoch))if rank == 0:# Remove temporary cache files if os.path.exists(checkpoint_path) is True: os.remove(checkpoint_path) dist.destroy_process_group() # Destroy the process group, freeing resources Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of "Beginner's Guide to Vision" public account to download the first Chinese version of the OpenCV extension module tutorial available online, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of "Beginner's Guide to Vision" public account to download 31 vision practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and facial recognition, helping to quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the background of "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Communication Group
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes; otherwise, you will not be approved. After successful addition, you will be invited to join related WeChat groups based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~