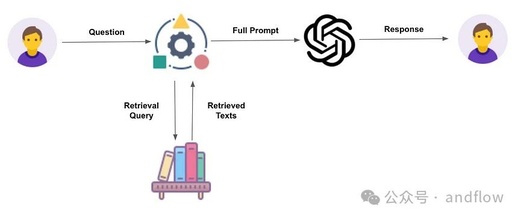
The RAG (Retrieval-Augmented Generation) model, commonly referred to as the RAG system, is widely used in large model applications. The principle of the model is quite simple: it retrieves information from a dataset based on user needs and then uses a large model for reasoning and generation.
The advantage of RAG lies in its ability to improve the accuracy and reliability of large models by providing context information from external data sources, which can be customized according to specific application scenarios and maintain data freshness without the need to retrain or fine-tune the large model.
However, RAG also encounters inaccuracies in practical applications. Next, we will further understand the principles of RAG and optimization solutions.
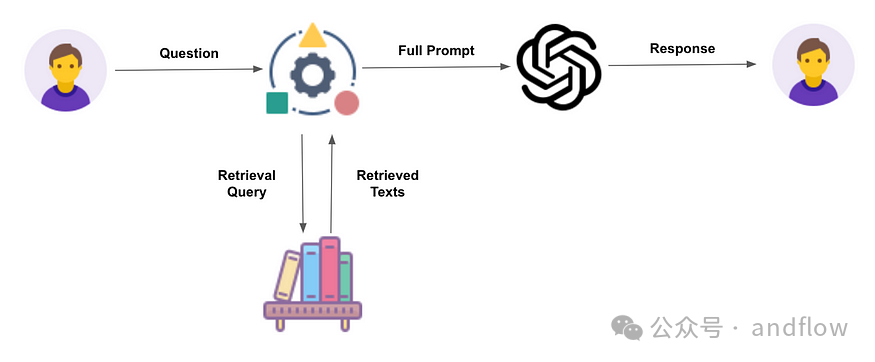
RAG can be summarized in three steps:
(1) Indexing
Indexing is the foundation for LLM to obtain accurate context and answers. Establishing an index requires first extracting and cleaning file data, such as Word, PDF, or HTML files. The content of the files is converted into standardized plain text. Since large models have context limitations, the text needs to be divided into smaller chunks. This process is called slicing. After that, an embedding model is used to convert each text chunk into a numerical vector. Finally, a vector database is used to store the text chunks and their corresponding vectors.
(2) Retrieval
In the retrieval phase, the same embedding model used in the indexing phase is employed to convert the user’s query information into vectors. Then, the similarity between the vectors and the vector chunks is compared to retrieve the top K most similar text chunks stored in the vector database.
(3) Generation
The user’s query and the retrieved chunks are applied to the Prompt template of the large model, resulting in enhanced prompts as input for the LLM.
However, in the implementation process, the effectiveness and performance of RAG need continuous tuning to achieve the desired results.
Tuning can be focused on the stages of indexing, retrieval, and generation, and optimized from aspects such as data engineering methods in the system construction process, vector databases, algorithms, models, technical architecture, effectiveness evaluation, special problem solving, continuous innovation, and legal regulations.
01
Data quality is the foundation of RAG performance, ensuring the correctness and consistency of the dataset. Avoid conflicting information that may confuse the language model and organize the data according to standards. The data cleaning process involves cleaning and converting text information that does not meet this standard to achieve usable standards.
Chunking documents is an important step in processing external data and significantly affects RAG performance. Chunking techniques include: by length, by paragraph, by token, etc. The specific method needs to be determined based on the content of the external data, as large models require a deep understanding of the business in industry applications.
For instance, if the chunk length is too small, the retrieved results may not contain enough context. If the chunk is too long, it may include too much irrelevant information, interfering with the generation of the large model.
When using chunking, mechanisms like a “sliding window” can also be utilized to increase information coverage and coherence.
Embedding models are the core technology for vectorizing information, and the quality of the model directly affects retrieval results. Generally speaking, the higher the dimension of the generated vectors, the higher the accuracy.
Well-known embedding models include: BGE, GTE, E5, Jina, Instructor, XLM-Roberta, text-embedding-ada-002, etc.
Although many general-purpose embedding models can be used directly, fine-tuning the embedding model may be significant for improving retrieval accuracy in certain domain contexts, such as specific industry terminology.
Here are the selection and application strategies for vector databases:
a) Scalability and Performance:
-
Vector databases are optimized for processing large-scale similarity searches, which is crucial for RAG systems with extensive knowledge bases.
-
Compared to traditional databases, they offer higher query efficiency, especially for nearest neighbor searches in high-dimensional spaces.
b) Selecting the Right Vector Database:
-
When selecting a vector database, consider factors such as data size, query latency requirements, and scalability needs.
-
Popular options include Faiss, Milvus, Pinecone, and Weaviate. Each has its advantages, so evaluate based on your specific use case.
-
For smaller datasets or prototypes, simpler solutions like FAISS or Annoy may suffice, while larger production systems may benefit from more robust distributed solutions like Milvus or Pinecone.
c) Indexing Strategy:
-
Experiment with different indexing algorithms (e.g., HNSW, IVF, PQ) to find the best balance between search speed and accuracy. Consider the trade-off between exact and approximate nearest neighbor search methods.
-
Select an embedding model that fits your data and task requirements. This could be a general model (like BERT) or a domain-specific model. -
Note that the dimensions of the embedding model affect storage requirements and query performance. For example, some vector databases perform better with low-dimensional embedding models.
e) Metadata and Filtering:
-
Utilize the metadata storage capabilities of vector databases to achieve robust filtering and mixed search capabilities.
-
Implement effective pre-filtering based on metadata to narrow down the search range before executing vector similarity searches.
f) Updating and Maintenance:
-
Develop a data update strategy to effectively update the database when new information is obtained.
-
Consider implementing incremental updates to avoid complete index rebuilds for minor changes.
g) Clustering and Data Organization:
-
Explore techniques like semantic clustering to organize the vector space for improved retrieval efficiency.
-
Consider hierarchical methods for very large datasets to enable effective search from coarse to fine.
h) Hybrid Search Capabilities:
-
Utilize vector databases that support hybrid search, combining vector similarity with keyword or BM 25 style matching to enhance retrieval quality.
-
Experiment with different methods to combine vector and keyword search results.
i) Monitoring and Optimization:
-
Implement comprehensive monitoring of vector database performance, including query latency, recall, and resource utilization.
-
Regularly analyze query patterns and adjust indexing strategies or hardware resources accordingly.
j) Hardware Considerations:
-
For large-scale deployments, consider the impact of hardware selection (CPU vs. GPU) on vector search performance. Evaluate cloud-hosted solutions against self-hosted options based on your scalability and management requirements.
k) Multi-modal Vector Databases:
-
For applications involving multiple data types (text, images, audio), consider vector databases that support multi-modal indexing and retrieval.
-
Explore techniques for effective combination and querying across different modalities.
l) Privacy and Security:
-
Evaluate the security of vector databases, especially in sensitive application scenarios.
-
Consider using technologies like encrypted search or federated learning to protect the privacy of the RAG system.
If document types are inconsistent or cross-domain knowledge is involved, multi-indexing can also be utilized.
Vector databases often use Approximate Nearest Neighbor (ANN) algorithms, such as Facebook Faiss (clustering), Spotify Annoy (tree), Google ScaNN (vector compression), and HNSWLIB (proximity graph). These ANN algorithms generally have adjustable parameters, such as ef, efConstruction, and maxConnections in HNSW.
In practice, the algorithm parameters are usually tuned by the database research team during benchmarking, and RAG system developers typically do not modify them.
Retrieval Phase
During the execution of RAG, the way user queries are expressed affects the retrieval of context vectors. Therefore, to search for satisfactory results, the query can be transformed, such as:
a) Rephrasing: Use a large language model (LLM) to regenerate the query information and then attempt the search again.
b) Hypothetical Document Embedding (HyDE): Use a large language model to generate hypothetical responses to search queries, then use both for retrieval.
c) Sub-queries: Break down longer queries into multiple shorter queries for separate retrieval.
During retrieval, consider whether semantic search sufficiently meets the use case needs and whether hybrid search is desired.
If hybrid search is needed, try adjusting the weighted aggregation of sparse and dense retrieval methods in the hybrid search, the alpha parameter.
Additionally, the number of retrieval results is also important. The quantity of context retrieved will affect the length of the context window.
If using a re-ranking model, consider how much context to input into the large model.
While the similarity measurement method for semantic retrieval can be set, it should be modified according to the embedding model used. For example, text-embedding-ada-002 supports cosine similarity, while multi-qa-MiniLM-l6-cos-v1 supports cosine similarity, dot product, and Euclidean distance.
The basic idea of advanced retrieval is that the blocks used for retrieval do not necessarily have to be the same as those used for generation. Ideally, smaller blocks should be used for retrieval to obtain larger context.
The retrieval strategies are as follows:
a) Sentence Window Retrieval: Not only retrieve relevant sentences but also the windows before and after the sentences.
b) Auto-Merging Retrieval: Documents are organized in a tree-like structure. During queries, separate and relevant smaller blocks can be merged into larger contexts.
Semantic search retrieves based on the similarity of context to query semantics, but “most similar” does not necessarily mean “most relevant.”
Re-ranking models (e.g., Cohere’s re-ranking model) can filter out irrelevant search results by calculating the relevance scores of each retrieved context to the query.
When using re-ranking models, it may be necessary to set the number of search results for re-ranking and how many re-ranked results to use for the LLM. The use or parameter tuning of re-ranking models should also be based on the application scenario.
03
a) Background Integration:
-
Try different methods to integrate the retrieved information (e.g., prompts, external, suffix, composition). Use clear boundaries between queries, search contexts, and model instructions.
b) Instruction Functionality:
-
Provide clear instructions on how to use the search information.
-
When using external knowledge, include guidance on citations or attribution.
c) Handling Multiple Retrieved Documents:
-
Strategize the integration of information from numerous retrieval sources.
-
Implement techniques to resolve conflicts or contradictions in the search information.
d) Dynamic Adjustment:
-
Implement adaptive prompting strategies based on the nature of the query and the retrieved information.
-
Consider using a few examples in the prompts to guide the model’s behavior.
e) Timely Calibration:
-
Regularly evaluate and optimize prompts based on output quality and user feedback.
-
Implement A/B testing to compare different prompting strategies.
Large models are the core components for content generation. There are various LLMs to choose from, which can be selected based on the application scenario, considering the characteristics of large models (e.g., open vs. proprietary models, inference costs, context length, etc.). In some specialized application scenarios, fine-tuning the LLM may also be necessary to meet needs.
Here are some strategies to consider:
a) Domain Adaptation:
Fine-tune language models on specific domain data to enhance understanding and generation in the target domain.
b) Task-specific Fine-tuning:
Develop custom datasets that simulate the RAG process (query, retrieved context, expected output) for specific use cases.
c) Retrieval-aware Training:
Explore methods to make language models more aware of the retrieval process during fine-tuning.
d) Content Generation Control:
Fine-tune models to improve control over the style, length, and content of generated outputs.
Using Efficient RAG Architectures
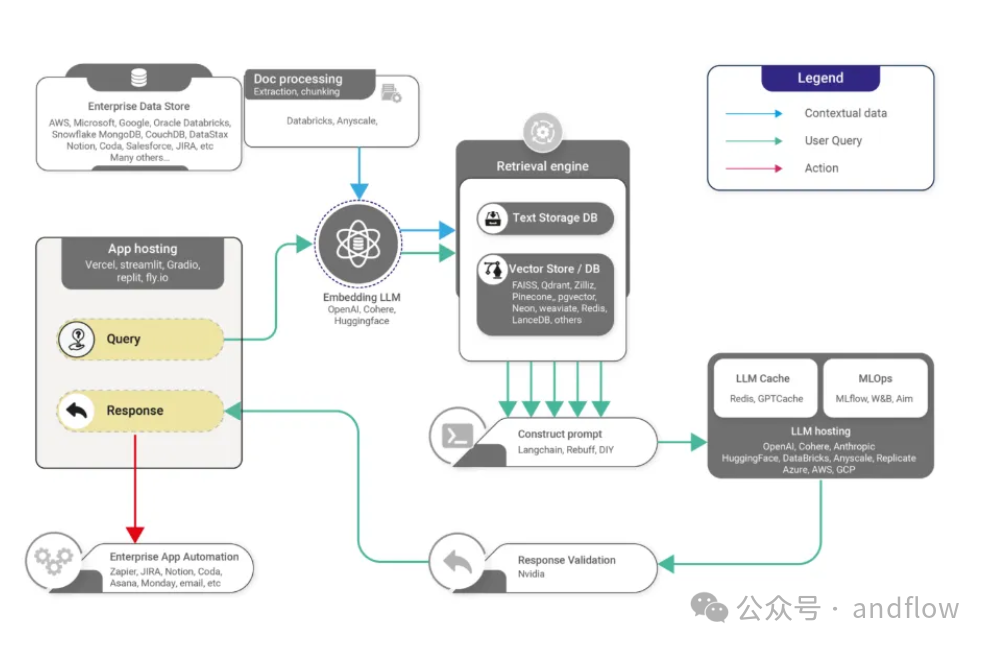
Optimizing the overall RAG architecture is crucial for practical applications. Here are some strategies to improve efficiency and scalability:
(1) Caching and Pre-computation:
Implement caching mechanisms for frequently accessed documents or query results.
(2) Asynchronous Processing:
Implement asynchronous retrieval to reduce latency in user-facing applications.
(3) Resource Management:
Implement efficient load balancing and resource allocation for different components of the RAG system.
(4) Simplifying Processes:
Identify and eliminate bottlenecks in the RAG process through performance analysis.
Use lightweight models in resource-constrained environments.
05
Evaluation and Continuous Improvement
Rigorous evaluation and continuous improvement are key to developing high-performance RAG systems. Here are some strategies to consider:
(1) Comprehensive Evaluation:
Implement a diverse set of evaluation metrics covering retrieval quality, generation quality, and overall system performance.
Consider automated metrics such as BLEU, ROUGE, perplexity, and human evaluation.
(2) Targeted Testing:
Develop dedicated test sets that challenge the RAG system (e.g., handling rare information, multi-hop reasoning).
Implement adversarial testing to identify potential issues.
(3) A/B Testing and Experiments:
Establish a robust testing framework to comprehensively compare different RAG configurations.
Implement online A/B testing for real-world performance evaluation.
(4) Feedback Loops:
Establish mechanisms to collect and incorporate user feedback for continuous improvement.
Implement active learning methods to identify areas where the system needs improvement.
06
Handling Common Challenges
Every RAG system will encounter difficult situations. Here are some strategies to address common challenges:
(1) Handling Inadequate or Irrelevant Retrieved Information:
When high-quality information cannot be retrieved, implement fallback strategies.
(2) Handling Conflicting Information:
Implement strategies for the model to identify and coordinate conflicts in retrieved information.
When a clear answer cannot be given, consider presenting multiple viewpoints.
(3) Managing Large Knowledge Bases:
Develop effective update and maintenance strategies for large or rapidly changing knowledge bases.
(4) Addressing Bias and Fairness Issues:
Implement techniques to identify and mitigate biases in the retrieval and generation components.
Regularly audit the system for fairness and representation issues.
07
Exploring New RAG Architectures
As large model applications evolve, various new RAG architectures are emerging. Here are some new approaches to consider:
(1) Multi-step Reasoning:
-
Implement iterative retrieval-generation loops for complex queries that require multi-hop reasoning.
-
Explore techniques such as chain-of-thought prompting to enhance reasoning capabilities.
(2) Hybrid Architectures:
-
Combine joint harvesting RAG with other techniques (like contextual learning or few-shot prompting) to enhance performance.
-
Explore dynamic decisions on when to rely on retrieval versus the model’s inherent knowledge.
(3) Multi-modal RAG:
-
Extend RAG to handle multi-modal inputs and outputs (e.g., text, images, audio).
-
Develop retrieval and generation strategies for cross-modal information integration.
(4) Personalized RAG:
-
Implement user-specific knowledge bases or retrieval preferences for a personalized experience.
-
Explore techniques that balance personalization with privacy considerations.
08
Being an Ethical and Responsible RAG
When implementing RAG, it is crucial to consider legal regulations and ethical implications.
Here are some key factors to focus on:
(1) Transparency and Explainability:
-
Implement mechanisms to provide insights into the retrieval process and sources of information.
-
Develop techniques to explain the reasoning behind generated outputs.
(2) Privacy and Data Protection:
-
Ensure compliance with data protection regulations when building and deploying RAG systems.
-
Implement privacy protection techniques for sensitive information in the knowledge base.
(3) Misinformation and Content Moderation:
-
Develop robust strategies to identify and address potentially harmful or misleading information in retrieved content.
-
Implement content moderation processes for user-generated content in interactive RAG systems.
(4) Ethical Use Guidelines:
-
Establish clear guidelines for the responsible development and deployment of RAG systems.
-
Stay informed about the evolving legal regulations, ethical standards, and best practices in the field.
Conclusion
This article briefly introduces the principles of RAG and methods for RAG tuning. Trade-offs and tuning can be made in areas such as data quality control, data chunking, re-ranking, retrieval optimization, RAG architecture, evaluation, and ethical impacts.
Here are some key points:
-
Data quality is paramount: The foundation of an effective RAG system lies in well-prepared, high-quality data. Invest time in thorough data cleaning, chunking, and metadata enrichment.
-
Utilize vector databases: Carefully select and configure vector databases to ensure efficient, scalable retrieval. Consider factors such as indexing strategies, embedding models, and hardware requirements.
-
Optimize retrieval: Experiment with advanced embedding techniques, hybrid retrieval methods, and contextual retrieval to enhance the relevance of retrieved information.
-
Master prompt engineering: Create clear, specific prompts that guide the model effectively in utilizing retrieved information. Regularly refine and test your prompting strategies.
-
Appropriate fine-tuning: When necessary, fine-tune language models on domain-specific or task-specific datasets that mimic the RAG process.
-
Build efficient architectures: Implement caching, asynchronous processing, and efficient resource management to create scalable RAG systems.
-
Rigorous evaluation: Combine automated metrics with human evaluation. Implement continuous testing and feedback loops for ongoing improvement.
-
Address special cases: Develop strategies for handling inadequate or conflicting information and be prepared to acknowledge uncertainty when appropriate.
-
Continuous innovation: Explore advanced architectures such as multi-step reasoning, hybrid methods, and multi-modal RAG to push the boundaries of possibilities.
-
Focus on ethics: Consider the societal impacts of RAG systems, including transparency, privacy, and strategies to mitigate potential harms.