
https://arxiv.org/pdf/2501.09136
Overview of Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) represents a significant advancement in the field of artificial intelligence by combining the generative capabilities of Large Language Models (LLMs) with real-time data retrieval. While LLMs excel in natural language processing, their reliance on static pre-trained data often results in outdated or incomplete responses.
RAG achieves contextually accurate and up-to-date outputs by dynamically retrieving relevant external information and incorporating it into the generation process.
The Core Components of RAG
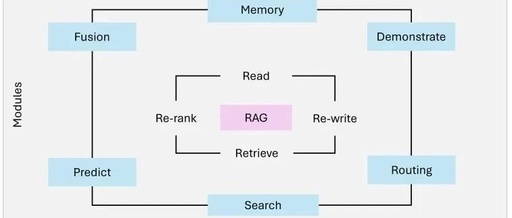
The architecture of a RAG system integrates three main components (Figure 1):
• Retrieval: Responsible for querying external data sources such as knowledge bases, APIs, or vector databases. Advanced retrievers utilize dense vector search and Transformer models to enhance retrieval accuracy and semantic relevance.
• Augmentation: Processes the retrieved data, extracting and summarizing the most relevant information to fit the query context.
• Generation: Combines the retrieved information with the pre-trained knowledge of LLMs to generate coherent and contextually relevant responses.
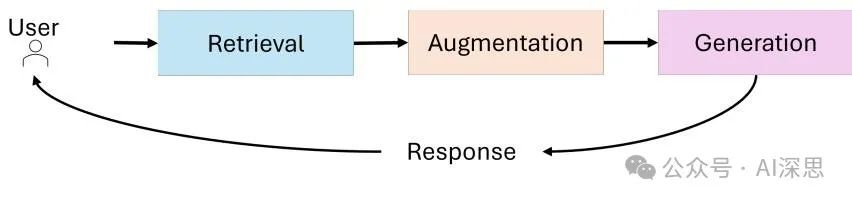
Figure 1: Core Components of RAG
The Evolution of the RAG Paradigm
The field of Retrieval-Augmented Generation (RAG) has evolved with the increasing complexity of real-world applications, which demand higher standards for contextual accuracy, scalability, and multi-step reasoning. Starting from simple keyword retrieval, RAG has developed into complex, modular, and adaptive systems capable of integrating multiple data sources and autonomous decision-making processes.
This evolution highlights the need for RAG systems to efficiently handle complex queries.
This article explores the evolution of the RAG paradigm, including naive RAG, advanced RAG, modular RAG, graph RAG, and agentic RAG, along with their defining features, advantages, and limitations. By understanding these paradigm evolutions, readers can better grasp the advancements in retrieval and generation capabilities and their applications across various domains.
Naive RAG
Naive RAG [23] represents the foundational implementation of retrieval-augmented generation. Figure 2 illustrates the simple retrieval-reading workflow of naive RAG, focusing on keyword retrieval and static datasets. These systems rely on simple keyword retrieval techniques (such as TF-IDF and BM25) to retrieve documents from static datasets.
The retrieved documents are then used to enhance the generative capabilities of the language model.
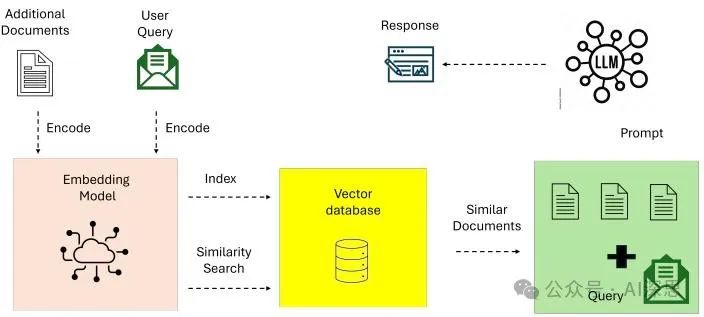
Figure 2: Overview of Naive RAG
Naive RAG is characterized by its simplicity and ease of implementation, suitable for tasks involving factual queries with lower contextual complexity. However, it has several limitations:
• Lack of Context Awareness: Retrieved documents often fail to capture the semantic nuances of the query due to reliance on lexical matching rather than semantic understanding.
• Fragmented Output: The lack of advanced preprocessing or context integration often leads to disjointed or overly generic responses.
• Scalability Issues: Keyword retrieval techniques struggle to identify the most relevant information when dealing with large datasets.
Despite these limitations, naive RAG systems provide a crucial proof of concept for the integration of retrieval and generation, laying the foundation for more complex paradigms.
Advanced RAG
Advanced RAG [23] systems overcome the limitations of naive RAG by introducing semantic understanding and enhanced retrieval techniques. Figure 3 illustrates the semantic enhancement and iterative, context-aware pipeline of retrieval in advanced RAG. These systems utilize dense retrieval models (such as Dense Passage Retrieval – DPR) and neural ranking algorithms to improve retrieval accuracy.
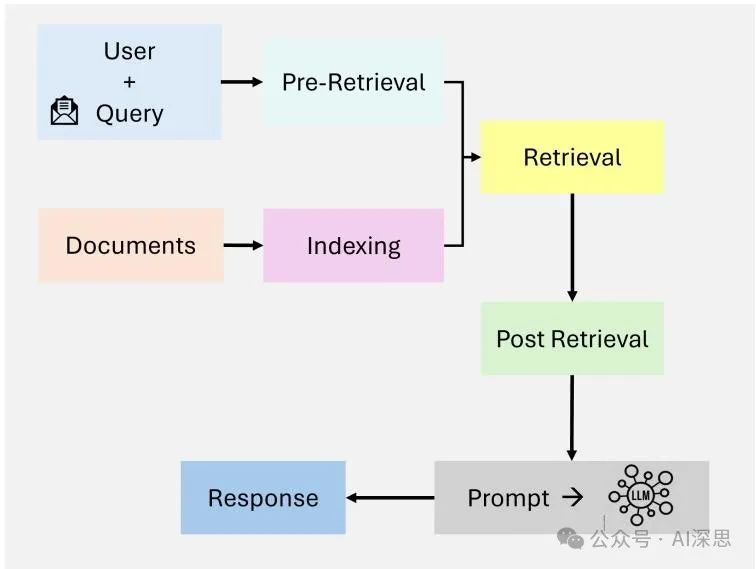
Figure 3: Overview of Advanced RAG
Key features of advanced RAG include:
• Dense Vector Search: Queries and documents are represented in a high-dimensional vector space, enabling better semantic alignment between user queries and retrieved documents.
• Context Re-ranking: Neural models re-rank retrieved documents, prioritizing the most relevant contextual information.
• Iterative Retrieval: Advanced RAG introduces a multi-hop retrieval mechanism, allowing complex queries to reason across multiple documents.
These improvements make advanced RAG suitable for applications requiring high precision and nuanced understanding, such as research synthesis and personalized recommendations. However, issues such as high computational overhead and limited scalability still exist, especially when dealing with large datasets or multi-step queries.
Modular RAG
Modular RAG [23] represents the latest evolution of the RAG paradigm, emphasizing flexibility and customization. These systems decompose the retrieval and generation pipeline into independent, reusable components, enabling domain-specific optimization and task adaptability.
Figure 4 illustrates the modular architecture, showcasing hybrid retrieval strategies, composable pipelines, and external tool integration.
Key innovations of modular RAG include:
• Hybrid Retrieval Strategies: Combining sparse retrieval methods (such as Sparse Encoder-BM25) with dense retrieval techniques (such as DPR – Dense Passage Retrieval) to improve accuracy across various query types.
• Tool Integration: Introducing external APIs, databases, or computational tools to handle specific tasks, such as real-time data analysis or domain-specific computations.
• Composable Pipelines: Modular RAG allows for independent replacement, enhancement, or reconfiguration of retrievers, generators, and other components to adapt to specific use cases.
For example, a modular RAG system designed for financial analysis could retrieve real-time stock prices via API, analyze historical trends using dense retrieval, and generate actionable investment insights through customized language models. This modularity and customization make modular RAG suitable for complex multi-domain tasks, providing scalability and precision.
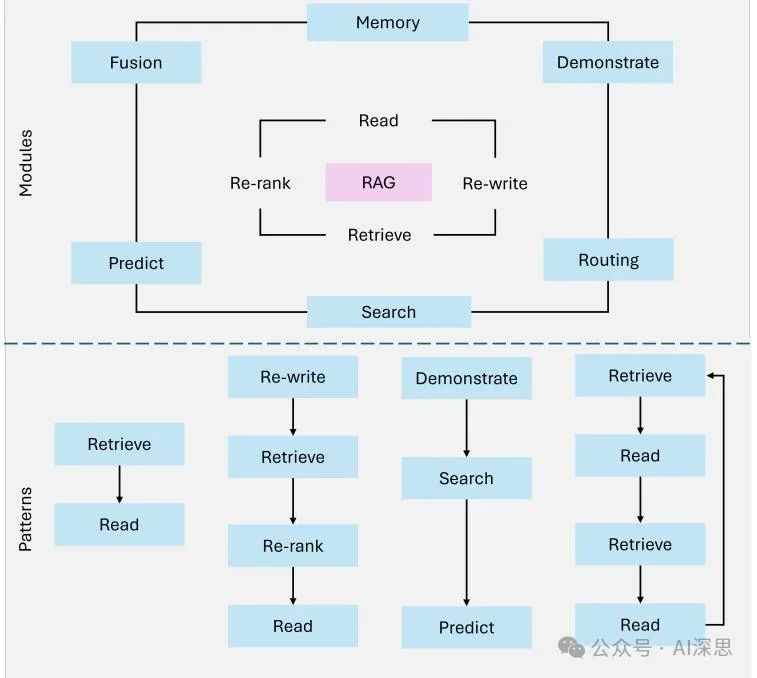
Figure 4: Overview of Modular RAG
Graph RAG
Graph RAG [19] extends traditional retrieval-augmented generation systems by integrating graph-structured data, as shown in Figure 5. These systems leverage relationships and hierarchies in graph data to enhance multi-hop reasoning and contextual richness. By introducing graph-structured retrieval, graph RAG can generate richer and more accurate outputs, particularly for tasks requiring relational understanding.
Key features of graph RAG include:
• Node Connections: Capturing and reasoning about relationships between entities.
• Hierarchical Knowledge Management: Handling structured and unstructured data through graph-structured hierarchies.
• Contextual Richness: Utilizing graph-structured paths to add relational understanding.
However, graph RAG also has some limitations:
• Limited Scalability: The reliance on graph structures may limit scalability, especially in cases with extensive data sources.
• Data Dependency: High-quality graph data is crucial for meaningful outputs, limiting its application in unstructured or poorly labeled datasets.
• Integration Complexity: Integrating graph data with unstructured retrieval systems increases design and implementation complexity.
Graph RAG is particularly suited for applications requiring reasoning about structured relationships, such as medical diagnosis, legal research, and other fields.
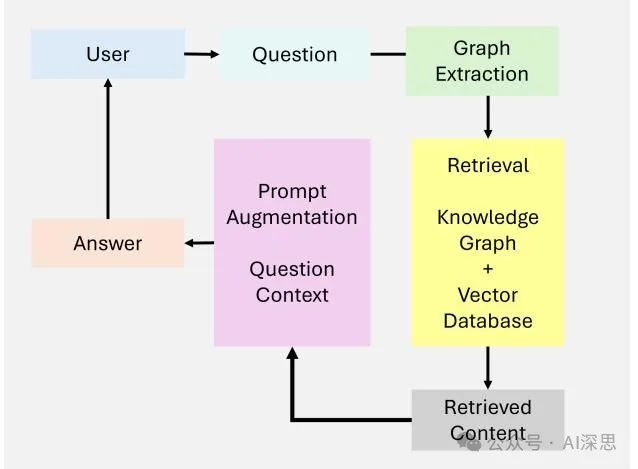
Figure 5: Overview of Graph RAG
Agentic RAG
Agentic RAG introduces autonomous agents capable of dynamic decision-making and workflow optimization, marking a paradigm shift. Unlike static systems, agentic RAG employs iterative improvements and adaptive retrieval strategies to tackle complex, real-time, and multi-domain queries.
This paradigm leverages the modular characteristics of the retrieval and generation processes while introducing agent autonomy.
Key features of agentic RAG include:
• Autonomous Decision-Making: Agents independently assess and manage retrieval strategies based on query complexity.
• Iterative Improvements: Introducing feedback loops to enhance retrieval accuracy and response relevance.
• Workflow Optimization: Dynamically coordinating tasks for greater efficiency in real-time applications.
Despite the advancements, agentic RAG still faces challenges:
• Coordination Complexity: Managing interactions between agents requires complex coordination mechanisms.
• Computational Overhead: Utilizing multiple agents increases resource demands in complex workflows.
• Scalability Limitations: While scalable, the dynamic nature of the system may consume significant computational resources under high query loads.
Agentic RAG excels in domains such as customer service, financial analysis, and adaptive learning platforms, where dynamic adaptability and contextual accuracy are paramount.
Challenges and Limitations of Traditional RAG Systems
Traditional retrieval-augmented generation (RAG) systems significantly extend the capabilities of large language models (LLMs) by integrating real-time data retrieval. However, these systems still face several critical challenges that limit their effectiveness in complex, real-world applications.
The most notable limitations focus on contextual integration, multi-step reasoning, and scalability and latency issues.
Contextual Integration
Even when RAG systems successfully retrieve relevant information, they often struggle to integrate it seamlessly into the generated responses. The static nature of the retrieval pipeline and limited context awareness lead to fragmented, inconsistent, or overly generic outputs.
Example: A query like “What are the latest advancements in Alzheimer’s disease research and their implications for early treatment?” may yield relevant research papers and medical guidelines. However, traditional RAG systems often fail to synthesize these findings into a coherent explanation that connects new treatments to specific patient situations.
Similarly, for a query “What are the best sustainable practices for small-scale agriculture in arid regions?”, traditional systems may retrieve documents on general agricultural methods but overlook critical sustainable practices tailored to arid environments.
Multi-Step Reasoning
Many real-world queries require iterative or multi-hop reasoning—retrieving and synthesizing information across multiple steps. Traditional RAG systems often struggle to improve retrieval based on intermediate insights or user feedback, resulting in incomplete or fragmented responses.
Example: A complex query like “How can the lessons from renewable energy policies in Europe be applied to developing countries, and what are the potential economic impacts?” requires coordinating various types of information, including policy data, contextualization for developing regions, and economic analysis.
Traditional RAG systems often fail to integrate these disparate elements into a coherent response.
Scalability and Latency Issues
As the number of external data sources increases, querying and ranking large datasets becomes increasingly computationally intensive. This leads to significant latency, undermining the system’s ability to provide timely responses in real-time applications.
Example: In time-sensitive environments such as financial analysis or real-time customer service, the delays caused by querying multiple databases or processing large document sets can undermine the overall utility of the system. For instance, delays in retrieving market trends in high-frequency trading can lead to missed opportunities.
Agentic RAG: A Paradigm Shift
Traditional RAG systems often struggle to handle dynamic, multi-step reasoning, and complex real-world tasks due to their static workflows and limited adaptability. These limitations have driven the integration of agent intelligence, resulting in agentic RAG.
By introducing autonomous agents capable of dynamic decision-making, iterative reasoning, and adaptive retrieval strategies, agentic RAG overcomes the inherent limitations of earlier paradigms built on modular foundations. This evolution enables more complex, multi-domain tasks to be resolved with greater precision and contextual understanding, positioning agentic RAG as a cornerstone for next-generation AI applications.
Notably, agentic RAG systems reduce latency by optimizing workflows and iteratively improving outputs, addressing the scalability and effectiveness challenges that have historically plagued traditional RAG.
Planning
Planning is a key design pattern in agent workflows that enables agents to autonomously break down complex tasks into smaller, more manageable subtasks. This capability is crucial for multi-step reasoning and iterative problem-solving in dynamic and uncertain scenarios, as shown in Figure 8.
By leveraging planning, agents can dynamically determine the sequence of steps needed to achieve a larger goal. This adaptability allows agents to handle tasks that cannot be predefined, ensuring flexibility in decision-making. While planning is powerful, its outcomes may be less predictable compared to deterministic workflows such as reflection.
Planning is particularly well-suited for tasks requiring dynamic adaptation, where predefined workflows often fall short. As technology advances, its innovative application potential across various domains will continue to grow.
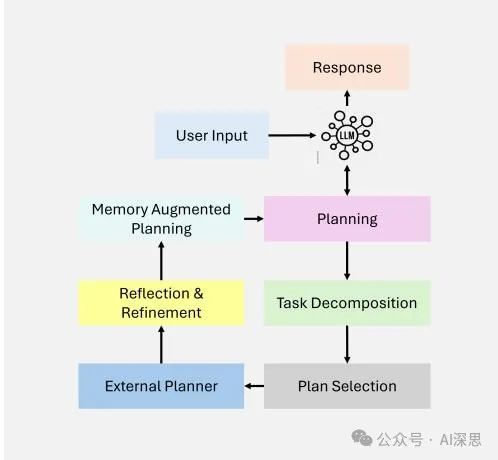
Figure 8: Overview of Agent Planning
Tool Use
Tool Use enables agents to extend their capabilities by interacting with external tools, APIs, or computational resources, as shown in Figure 9. This pattern allows agents to retrieve information, perform computations, and manipulate data, surpassing their pre-trained knowledge.
By dynamically integrating tools into workflows, agents can adapt to complex tasks and provide more accurate and contextually relevant outputs.
Tool Use is widely adopted in modern agent workflows, including applications for information retrieval, computational reasoning, and interaction with external systems. With the emergence of function calling capabilities in GPT-4 and systems capable of managing numerous tools, significant advancements have been made in implementing this pattern.
These advancements facilitate complex agents’ autonomous selection and execution of the most relevant tools within their workflows.
Despite significantly enhancing agent workflows, Tool Use still faces challenges in optimizing tool selection, especially when numerous options are available. Techniques inspired by retrieval-augmented generation (RAG), such as heuristic-based tool selection methods, have been proposed to address this issue.
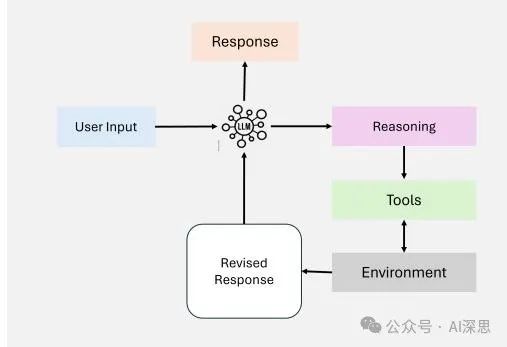
Figure 9: Overview of Tool Use
Multi-Agent
Multi-agent collaboration [16] is a key design pattern in agent workflows that enables task specialization and parallel processing. Agents communicate and share intermediate results, ensuring that the overall workflow remains efficient and coherent.
By assigning subtasks to specialized agents, this pattern enhances scalability and adaptability in complex workflows. Multi-agent systems allow developers to decompose complex tasks into smaller, manageable subtasks assigned to different agents.
This approach not only improves task performance but also provides a robust framework for managing complex interactions. Each agent has its memory and workflow, which can include tool use, reflection, or planning, enabling dynamic and collaborative problem-solving (see Figure 10).
Despite the immense potential of multi-agent collaboration, it is a less predictable design pattern compared to more mature workflow patterns (such as Reflection and Tool Use). However, emerging frameworks such as AutoGen, Crew AI, and LangGraph are providing new avenues for effective multi-agent solutions.
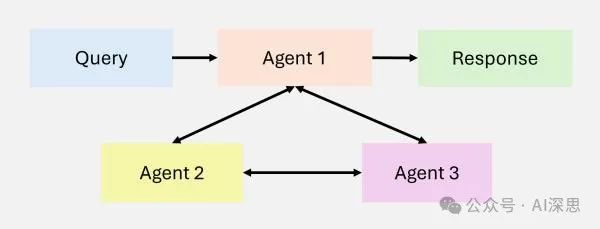
Figure 10: Overview of Multi-Agent Collaboration
These patterns are foundational to the success of Agentic RAG systems, enabling them to dynamically adapt retrieval and generation workflows to meet the demands of diverse and dynamic environments. By leveraging these patterns, agents can handle iterative, context-aware tasks that surpass the capabilities of traditional RAG systems.
Agent-G: A Graph-Augmented Retrieval-Generation Framework Based on Agents
Agent-G [8] introduces a novel agent architecture that combines graph knowledge bases with unstructured document retrieval. By integrating structured and unstructured data sources, this framework enhances retrieval-augmented generation (RAG) systems, improving reasoning capabilities and retrieval accuracy.
Agent-G employs a modular retriever bank, dynamic agent interactions, and feedback loops to ensure high-quality outputs, as shown in Figure 16.
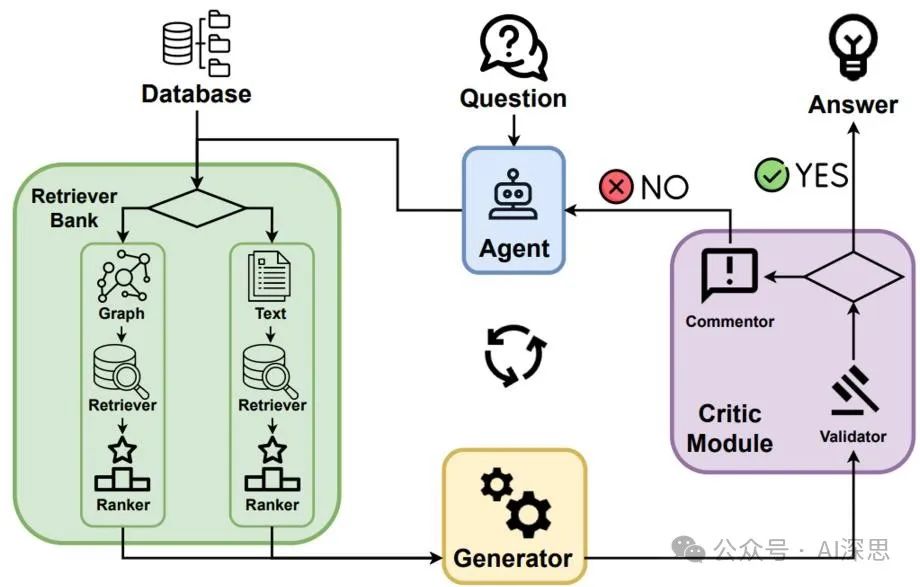
Agent-G: A Graph-Augmented Retrieval-Generation Framework Based on Agents [8]
The Core Concept of Agent-G
The core of Agent-G lies in its ability to dynamically assign retrieval tasks to specialized agents, leveraging graph knowledge bases and textual documents. Agent-G adjusts its retrieval strategy based on query requirements:
• Graph Knowledge Base: Utilizing structured data to extract relationships, hierarchies, and connections (e.g., disease-symptom mapping in the medical field).
• Unstructured Documents: Traditional text retrieval systems provide contextual information to supplement graph data.
• Critique Module: Evaluating the relevance and quality of retrieved information to ensure consistency with the query.
• Feedback Loop: Optimizing retrieval and synthesis through iterative validation and re-querying.
The Workflow
The Agent-G system operates based on four main components:
1. Retriever Bank:
• A set of modular agents specialized in retrieving graph-structured or unstructured data.
• Agents dynamically select relevant sources based on query requirements.
2. Critique Module:
• Validating the relevance and quality of retrieved data.
• Marking low-confidence results for re-retrieval or refinement.
3. Dynamic Agent Interaction:
• Task-specific agents collaborate to integrate different types of data.
• Ensuring consistent retrieval and synthesis between graph and text sources.
4. LLM Integration:
• Integrating validated data into coherent responses.
• Iterative feedback from the critique module ensures consistency with query intent.
Key Features and Advantages
• Enhanced Reasoning: Combining structured relationships from graphs and contextual information from unstructured documents.
• Dynamic Adaptability: Adjusting retrieval strategies dynamically based on query requirements.
• Improved Accuracy: The critique module reduces the risk of irrelevant or low-quality data in responses.
• Scalable Modularity: Supporting the addition of new agents for specific tasks, enhancing scalability.
Use Case: Medical Diagnosis
Prompt: What are the common symptoms of type 2 diabetes, and how are they related to heart disease?
The System Workflow (Agent-G Workflow):
1. Query Reception and Assignment: The system receives the query and identifies the need to combine graph-structured and unstructured data to comprehensively answer the question.
2. Graph Retriever:
• Extracting the relationship between type 2 diabetes and heart disease from the medical knowledge graph.
• Identifying shared risk factors (such as obesity and hypertension) by exploring graph hierarchies and relationships.
3. Document Retriever:
• Retrieving descriptions of type 2 diabetes symptoms (such as polydipsia, polyuria, and fatigue) from medical literature.
• Adding contextual information to supplement insights from graph-structured data.
4. Critique Module:
• Evaluating the relevance and quality of the retrieved graph and document data.
• Marking low-confidence results for refinement or re-querying.
5. Response Synthesis: The large language model synthesizes the validated data from the graph and document retrievers into coherent responses, ensuring consistency with query intent.
Response:
*Synthesis Response*: “Symptoms of type 2 diabetes include polydipsia, polyuria, and fatigue. Studies indicate a 50% correlation between diabetes and heart disease, primarily through shared risk factors such as obesity and hypertension.”
GeAR: Graph-Augmented Agents for Retrieval-Augmented Generation
GeAR [36] introduces an agent framework that enhances traditional retrieval-augmented generation (RAG) systems by incorporating graph retrieval mechanisms. By leveraging graph expansion techniques and agent architectures, GeAR addresses challenges in multi-hop retrieval scenarios, improving the system’s ability to handle complex queries, as shown in Figure 17.
The Core Concept of GeAR
GeAR enhances RAG performance through two main innovations:
• Graph Expansion: Enhancing traditional base retrievers (such as BM25) by incorporating graph-structured data into the retrieval process, enabling the system to capture complex relationships and dependencies between entities.
• Agent Architecture: Utilizing graph expansion to manage retrieval tasks with an agent architecture, allowing for dynamic and autonomous decision-making during the retrieval process.
The Workflow
The GeAR system operates through the following components:
1. Graph Expansion Module:
• Integrating graph-structured data into the retrieval process, allowing the system to consider relationships between entities during retrieval.
• Enhancing the base retriever’s ability to handle multi-hop queries by expanding the search space to include connected entities.
2. Agent Retrieval:
• Managing the retrieval process using an agent architecture, dynamically selecting and combining retrieval strategies based on query complexity.
• Agents can autonomously decide to use graph expansion retrieval paths to improve the relevance and accuracy of retrieved information.
3. LLM Integration:
• Combining information enriched by graph expansion with the capabilities of large language models to generate coherent and contextually relevant responses.
• Ensuring that the generation process is influenced by both unstructured documents and structured graph data.
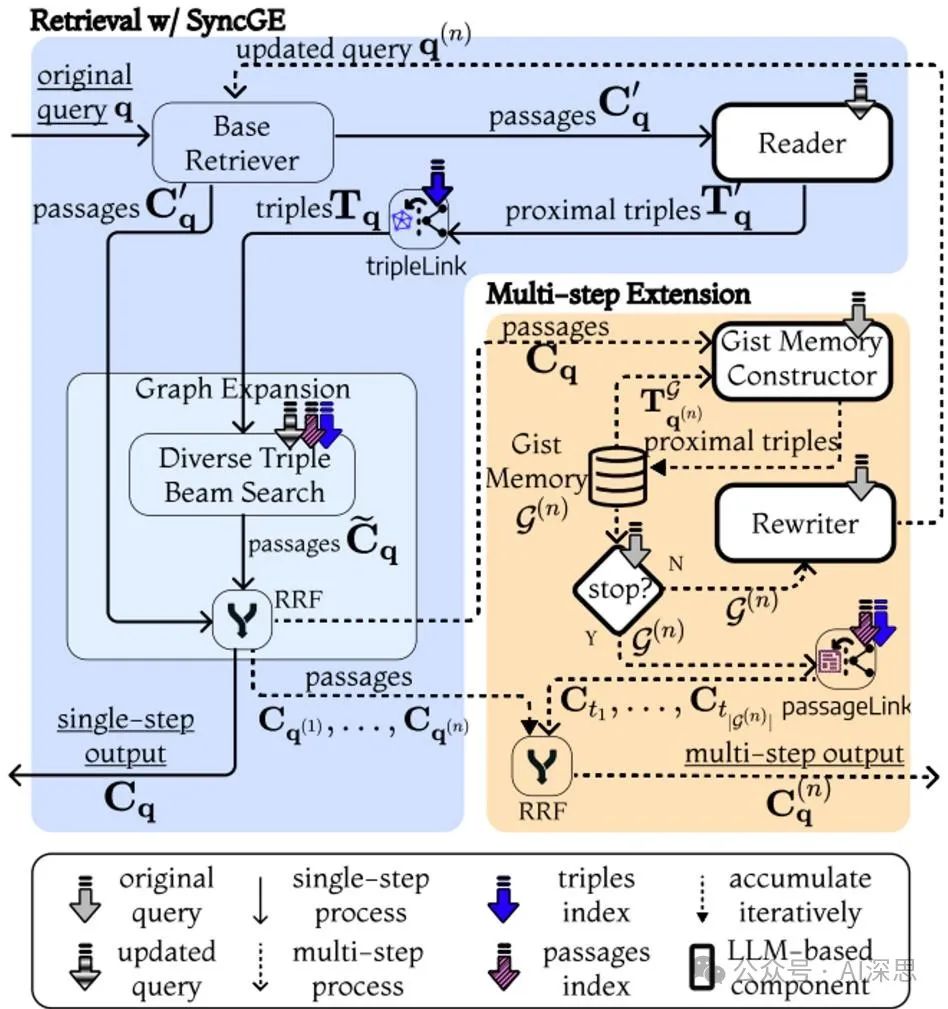
Figure 17: GeAR: Graph-Augmented Agents for Retrieval-Augmented Generation [36]
Key Features and Advantages
• Enhanced Multi-Hop Retrieval: The graph expansion of GeAR enables the system to handle complex queries requiring reasoning across multiple interrelated pieces of information.
• Agent Decision-Making: The agent architecture allows for dynamic and autonomous selection of retrieval strategies, improving efficiency and relevance.
• Improved Accuracy: By integrating structured graph data, GeAR enhances the accuracy of retrieved information, leading to more precise and contextually appropriate responses.
• Scalability: The modular nature of the agent architecture allows for the integration of additional retrieval strategies and data sources as needed.
Use Case: Multi-Hop Question Answering
Prompt: Which author influenced J.K. Rowling’s mentor?
The System Workflow (GeAR Workflow):
1. Top-Level Agent: Assessing the multi-hop nature of the query and determining the need to combine graph expansion and document retrieval to answer the question.
2. Graph Expansion Module:
• Identifying J.K. Rowling’s mentor as the key entity in the query.
• Tracing the literary influences of that mentor by exploring literary relationships in the graph-structured data.
3. Agent Retrieval:
• Agents autonomously select graph expansion retrieval paths to gather relevant information about the mentor’s influences.
• Integrating additional context by querying text data sources about the mentor and their influences.
4. Response Synthesis: Using the large language model to generate accurate responses reflecting the complex relationships in the query.
Response:
*Synthesis Response*: “J.K. Rowling’s mentor [Mentor’s Name] was significantly influenced by [Author’s Name], who is known for [Notable Works or Genres]. This connection highlights the multi-layered relationships in literary history, where influential ideas are often passed through multiple generations of authors.”
Agent-Based Document Workflows in Agent-Augmented Retrieval Generation
Agent-Based Document Workflows (ADW) [37] extend the traditional retrieval-augmented generation (RAG) paradigm by implementing end-to-end automation of knowledge work. These workflows coordinate complex document-centric processes, integrating document parsing, retrieval, reasoning, and structured output, using intelligent agents (see Figure 18).
ADW systems address the limitations of intelligent document processing (IDP) and RAG by maintaining state, coordinating multi-step workflows, and applying domain-specific logic to documents.
The Workflow
1. Document Parsing and Information Structuring:
• Using enterprise-grade tools (such as LlamaParse) to parse documents and extract relevant data fields such as invoice numbers, dates, vendor information, item details, and payment terms.
• Organizing structured data for downstream processing.
2. Cross-Process State Maintenance:
• The system maintains the state of the document context, ensuring consistency and relevance in multi-step workflows.
• Tracking the progress of documents through various processing stages.
3. Knowledge Retrieval:
• Retrieving relevant references from external knowledge bases (such as LlamaCloud) or vector indices.
• Retrieving real-time, domain-specific guidelines to enhance decision-making.
4. Agent-Based Orchestration:
• Intelligent agents apply business rules, perform multi-hop reasoning, and generate actionable recommendations.
• Coordinating parsers, retrievers, and external APIs for seamless integration.
5. Actionable Output Generation:
• Output presented in structured format, tailored for specific use cases.
• Integrating recommendations and extracted insights into concise and actionable reports.
Figure 18: Agent-Based Document Workflows (ADW) [37]
Use Case: Invoice Payment Workflow
Prompt: Generate a payment recommendation report based on the submitted invoice and relevant vendor contract terms.
The System Workflow (ADW Workflow):
1. Parsing the invoice to extract key details, such as invoice number, date, vendor information, item details, and payment terms.
2. Retrieving the corresponding vendor contract to verify payment terms and identify any applicable discounts or compliance requirements.
3. Generating a payment recommendation report, including the original payable amount, potential early payment discounts, budget impact analysis, and strategic payment actions.
Response:
Comprehensive Response: “The amount of $15,000.00 for invoice INV-2025-045 has been processed. If paid by April 10, 2025, a 2% early payment discount can be applied, reducing the payable amount to $14,700.00.
Since the subtotal exceeds $10,000.00, a 5% bulk order discount has been applied. Early payment is recommended to save 2% and ensure timely allocation of funds to support the upcoming project phase.”
Key Features and Advantages
• State Maintenance: Tracking document context and workflow stages to ensure consistency throughout the process.
• Multi-Step Orchestration: Handling complex workflows involving multiple components and external tools.
• Domain-Specific Intelligence: Applying customized business rules and guidelines to generate precise recommendations.
• Scalability: Supporting large-scale document processing through modular and dynamic agent integration.
• Enhanced Productivity: Automating repetitive tasks while augmenting human expertise in decision-making.
Benchmarks and Datasets
Current benchmarks and datasets provide valuable insights for evaluating retrieval-augmented generation (RAG) systems, including those with agent and graph augmentation capabilities. While some benchmarks are specifically designed for RAG, others have been adapted to test the performance of retrieval, reasoning, and generation capabilities across various scenarios.
Datasets are crucial for testing the retrieval, reasoning, and generation components of RAG systems. Table 3 discusses several key datasets for RAG evaluation based on downstream tasks.
Benchmarks play a critical role in standardizing the evaluation of RAG systems by providing structured tasks and metrics. Here are some particularly relevant benchmarks:
• BEIR (Benchmarking Information Retrieval): A versatile benchmarking framework for evaluating embedding models across various information retrieval tasks, covering datasets from 17 different domains, including bioinformatics, finance, and question answering.
• MS MARCO (Microsoft Machine Reading Comprehension): Focused on passage ranking and question answering, widely used for dense retrieval tasks in RAG systems.
• TREC (Text REtrieval Conference, Deep Learning Track): Provides datasets for passage and document retrieval, emphasizing the quality of ranking models in retrieval pipelines.
• MuSiQue (Multihop Sequential Questioning): A multi-hop reasoning benchmark involving multiple documents, highlighting the importance of retrieving and synthesizing information from unrelated contexts.
• 2WikiMultihopQA: A dataset designed for multi-hop question answering tasks over two Wikipedia articles, focusing on the ability to connect knowledge across multiple sources.
• AgentG (Agentic RAG for Knowledge Fusion): A benchmark specifically designed for agent RAG tasks, evaluating the ability to dynamically synthesize information across multiple knowledge bases.
• HotpotQA: A multi-hop question answering benchmark requiring retrieval and reasoning in interconnected contexts, making it well-suited for evaluating complex RAG workflows.
• RAGBench: A large-scale, interpretable benchmark containing 100,000 examples across diverse industry domains, using the TRACe evaluation framework for actionable RAG metrics assessment.
• BERGEN (Benchmarking Retrieval-Augmented Generation): A systematic benchmark for standard experimental libraries for evaluating RAG systems.
• FlashRAG Toolkit: Implements 12 RAG methods and includes 32 benchmark datasets, supporting efficient and standardized RAG evaluation.
• GNN-RAG: This benchmark evaluates graph-augmented RAG systems on tasks such as node-level and edge-level predictions, focusing on retrieval quality and reasoning performance in knowledge graph question answering (KGQA).
Table 3: Downstream Tasks and Datasets for RAG Evaluation (Adapted from [23])
Retrieval-Augmented Generation in Large Language Models
This article explores the application of Retrieval-Augmented Generation (RAG) in Large Language Models (LLMs). RAG combines retrieval and generation methods by retrieving relevant information from external knowledge bases and then using that information to generate more accurate and relevant answers.
Agentic RAG
Agentic RAG is an enhanced RAG approach that introduces the concept of agents, allowing the model to manage and utilize retrieved information more intelligently. This method improves the quality of generation through iteration and self-feedback.
Experimental results show that Agentic RAG outperforms traditional RAG methods across multiple benchmarks. For example, on the MS MARCO dataset, the accuracy of Agentic RAG improved by 15%.
Adaptive RAG
Adaptive RAG is another improved RAG method that can dynamically adjust retrieval strategies based on the complexity of the questions. This method enhances the model’s adaptability and accuracy by learning the best retrieval methods for questions of varying complexities.
Experiments on the COVID-QA dataset indicate that Adaptive RAG’s accuracy improved by 10% over traditional RAG.
Experimental Results
This article verifies the effectiveness of these methods through multiple benchmarks. The specific results are as follows:
• MS MARCO: The accuracy of Agentic RAG improved by 15%.
• COVID-QA: The accuracy of Adaptive RAG improved by 10%.
• FEVER: The accuracy of Agentic RAG improved by 8%.
These results indicate that the introduction of agents and adaptive mechanisms significantly enhances the performance of RAG methods in large language models.