OCR stands for Optical Character Recognition, which has been widely applied in the publishing industry in recent years, especially in the organization of ancient texts, reprinting of old books, and the publication of document archives. However, due to technical limitations, OCR documents often contain similar character errors. Some of these errors are very subtle and can even be passed around as misinformation. Below, I would like to share some personal insights on the spread of OCR similar character errors (mainly taking OCR Chinese character errors as examples) and strategies to address them.

Spread of Errors: From “骄做” to “骄作”
In “Who Moved My Edamame? — A Discussion on the New Trends of Similar Character Errors Caused by OCR Technology””, I provided an example of “骄做自满”. In fact, “骄做自满” is no longer an isolated case; it has become a trend in various publications.
I used the year 2000 as a boundary to compare the text layer of the dual-layer PDF in Duxiu with the corresponding text in the image layer PDF. I found that publications before 2000 mostly had “骄傲自满” in the image layer PDF, while the appearance of “骄做自满” in the image layer PDF occurred mostly after 2000. This coincides with the development timeline of OCR technology application in China’s publishing and printing industry.
In other words, due to the development of OCR technology, when “骄傲自满” was misrecognized as “骄做自满”, it began to spread “legitimately” in publications.

▲ Duxiu Search Screenshot Cai Zhizhong. Life Must Be Wonderful [M]. 2018
However, in recent years, due to improvements in the printing quality of publications and OCR technology, the phenomenon of “骄傲自满” turning into “骄做自满” has decreased. However, this recognition error has already produced a mutated variant, “骄作自满”.
For example, in a publication, the annotation for “敖惰” in “So-called Qi Qi Jia in Xiu Qi Shen, those who love them will avoid it; … those who are idle will avoid it” is as follows:
敖(ào)惰:骄作怠慢,轻视。敖:通“傲”,骄傲。

To understand the annotation for “敖惰”, we generally need to first understand the meanings of “敖” and “惰”, and then provide the overall meaning of “敖惰”. Since there is already an explanation for “骄傲”, why does “骄作” appear in the overall annotation? — This inconsistency in annotation thought is worth pondering.
I believe this may be due to the OCR recognition when the previous “骄傲怠慢” was recognized as “骄做怠慢”. The annotator or editor might have thought that “骄做怠慢” was problematic, considering it a homophonic error, and simply changed “做” to “作”, resulting in the inconsistency in the annotation thought. From “骄做到骄作”, a derivative error has already occurred.
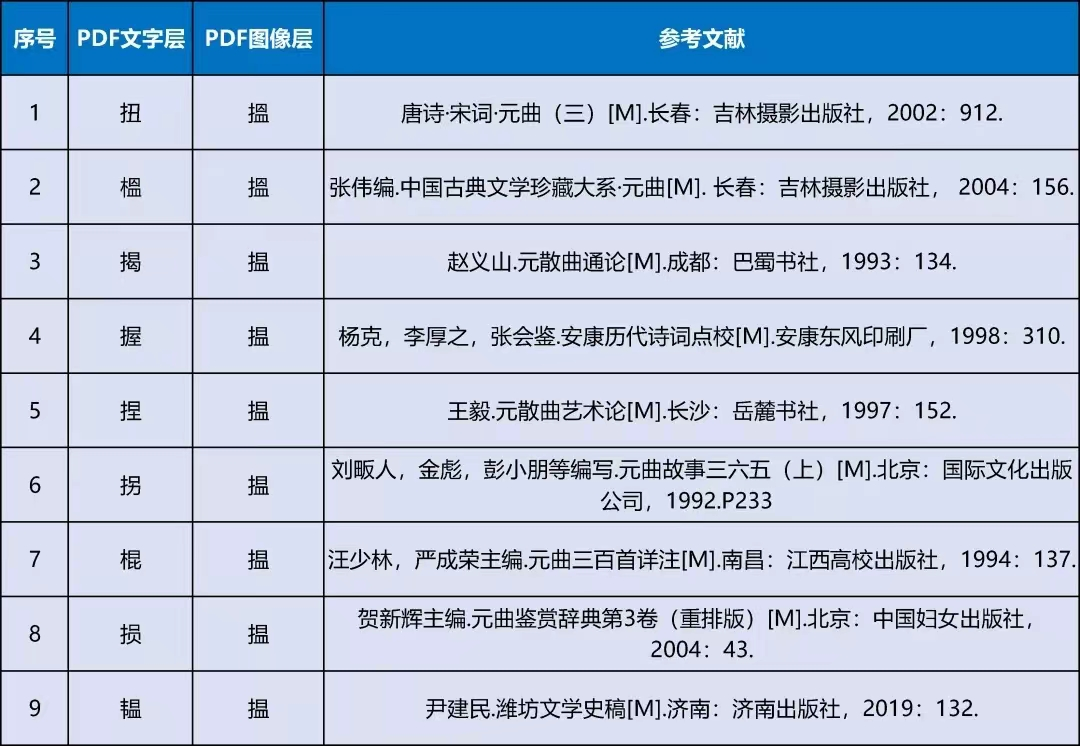
There are many similar recognition errors that can be found on Duxiu. If one is not careful when quoting, mistakes may easily occur. In Wang Tingxiu’s 【粉蝶儿】《怨别》套数中的【尧民歌】, there is a line with “Unconsciously, tears are wet and dripping, searching for/ wetting the gauze”. According to my statistics, in the search results shown on Duxiu, the recognition error of “揾(搵)” in that line has at least nine variations:
Faced with the direct and derivative problems caused by the application of OCR technology, what should editors do? Below, I will mainly discuss some strategies based on the new trends of several similar errors mentioned in the previous article.

Strategies
♦ 1. Pay attention to the characteristic of OCR technology that only looks at the “appearance” and try to select publications that are clearly printed and have clean paper for recognition.
When we recognize or evaluate a person, we often use phrases like “秀外慧中” and “才貌双全”. Such evaluations take both appearance and inner qualities into account. When we recognize characters, we generally also consider sound, shape, and meaning. Because of these multiple factors, many characters that are very similar in form are not actually categorized as similar characters by us. In a specific context, words like “相邀” and “祖逖” are easier to distinguish.
However, in OCR text recognition, each individual Chinese character’s form is compared with the forms of existing characters in the database, and the character with the highest appearance matching degree is selected as the recognition result. This is indeed a superficial approach. Therefore, if it is necessary to use OCR to input manuscripts, it is best to select publications that are clearly printed and have clean paper for recognition.
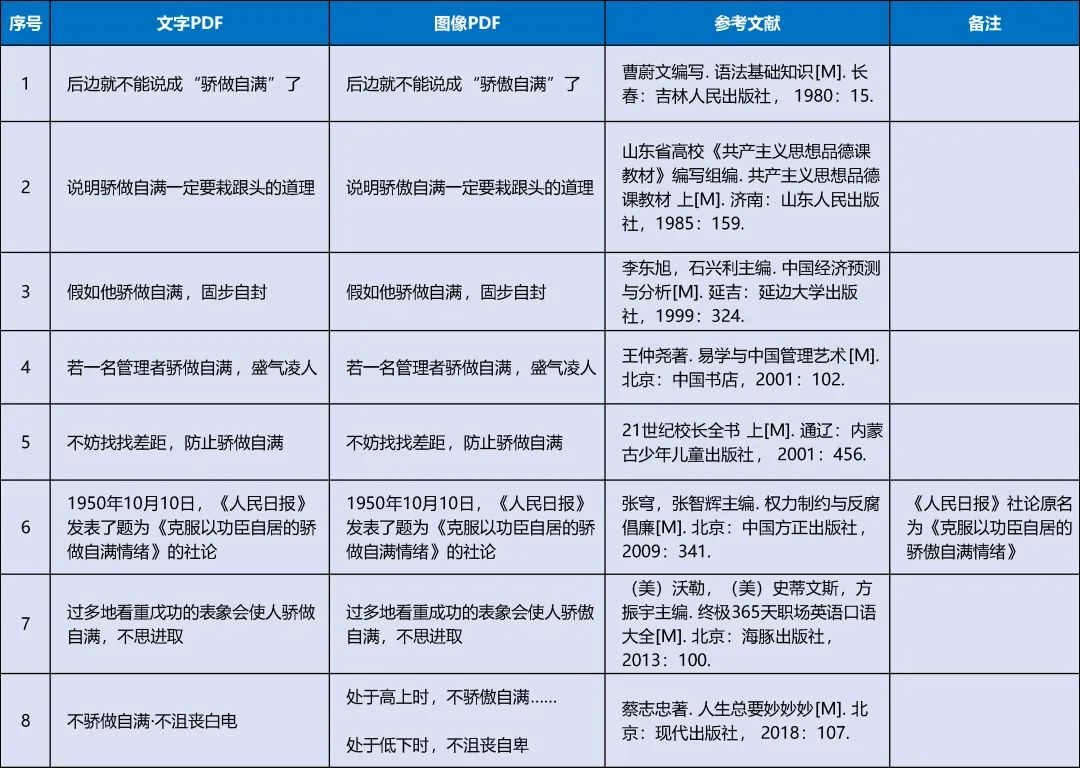
For example, in publications before 2000, although the vast majority of the original text is “骄傲自满”, many were recognized as “骄做自满”, one important reason being that some publications at that time had poor printing quality.
In contrast, many publications after 2000, if the PDF text layer is “骄做自满”, the image layer is also basically “骄做自满”. The few examples of “骄傲自满” being recognized as “骄做自满” in publications after 2000 were ones that I had to put in a lot of effort to find among the pile of search results in Duxiu, and those publications either had poor printing quality or used overly artistic fonts that did not suit OCR.

▲ Shandong Provincial University “Communist Ideology and Morality Course Teaching Materials” Compilation Group. Communist Ideology and Morality Course Teaching Materials Volume 1 [M]. Jinan: Shandong People’s Publishing House, 1985: 159. (Screenshot)

▲ Cai Zhizhong. Life Must Be Wonderful [M]. Beijing: Modern Publishing House, 2018: 107. (Screenshot)
Another example is the recognition error from the “Wen Yu Dictionary Publishing House”. Upon closely examining the original PDF, it can be seen that there is something resembling an ink spot above the character “汉”. It is this thing that changed the OCR recognition result, causing the Duxiu search page to show the unheard of “Wen Yu Dictionary Publishing House”.

▲ Wen Yu Dictionary Publishing House Duxiu Search Screenshot

▲ “Journal of Anhui University” Editorial Department. Graduate Forum 2006 Language and Literature, Journalism and Communication Volume [M]. Hefei: Anhui University Press, 2007: 31. (Screenshot)
♦ 2. Pay attention to the role of original or authoritative literature in editing and proofreading.
If the manuscript is organized after OCR recognition, it may contain some very subtle errors. Failing to verify the original text can easily lead to mistakes. For example, in the following passage:
Wang Lianzi Wen Yi, from Nanyang. During Liu Zhang’s time, he entered Shu and became the magistrate of Zizhong. When the first leader started a rebellion at Jiameng, he closed the city and did not surrender, and the first leader did not force him. After Chengdu was established early, he was appointed as the magistrate of Shifang and later transferred to Guangdu, where he had achievements. He was promoted to the Salt Supervisor, comparing the benefits of salt and iron, which benefited the people greatly and was beneficial to the national use, so he selected good talents as officials. …
—— Excerpt from “Records of the Three Kingdoms: Volume Eleven of Shu”
In this, “利人甚多” should be “利入甚多”. This error is difficult to correct without checking the original literature.
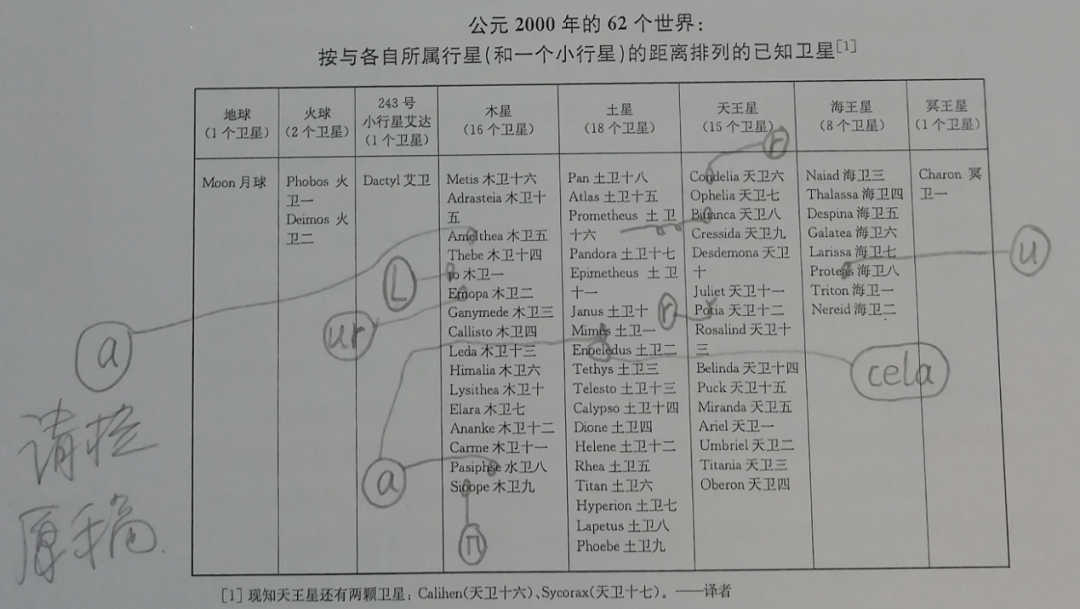
For instance, the content of the image below comes from the manuscript of the tenth chapter “The Sacred Darkness” of the book I edited, “Dim Blue Dot: Exploring Humanity’s Space Home”. If one does not have relevant astronomical knowledge and only reads through it, it is difficult to make corrections to the names of various satellites in the table.
Therefore, in the absence of relevant knowledge, the original literature serves as an important reference for editing and proofreading. Although the reference material I found differs from the version indicated by the author, it is sufficient to serve as a basis for questioning.
♦ 3. Improve review accuracy and enlarge the scale of errors — make good use of editing tools and PDFs.
When aiming to hit a target, two conditions are important: aiming more accurately and having a larger target. In the context of recognizing similar characters in OCR, it is necessary to strictly implement character shape review standards and enlarge the scale of errors — all of which should be achieved with the help of some tools.
For example, distinguishing between the characters “己” and “已” in regular script can be difficult when the font size is small on paper. However, distinguishing these two characters in a PDF is quite easy. I provide a few methods for reference:
(1) Use the search function. Place the cursor in front of the character you want to verify, enter “己” or “已” in the search dialog box, click to find the next one, and see if the “next one” found is the one behind the cursor. This is because the computer determines character shapes based on binary code standards (each character has a unique binary number), avoiding the deviations that might occur with human judgment.
(2) Zoom in on the PDF. For instance, if the small four-point font is enlarged to more than three times, it becomes quite easy to distinguish between “己” and “已”.
The above two methods are also very effective in distinguishing between similar characters that are very close in form. You can scroll down to observe the “出” and “晚” in the image below, and then read the corresponding text above (regular script, small four-point), to experience the effect of zooming in.
When using the above methods, make sure to prepare a PDF that allows for search, copy, and other functions. Before performing paper manuscript proofreading, be sure to request such a PDF from the typesetter, as this type of PDF is important for reviewing similar characters, ensuring content consistency, and content positioning.
(3) Use editing software like Heima, Founder, or Phoenix Intelligent Proofreading for verification. Specific steps are omitted.
♦ 4. Use different capacities of OCR character libraries according to the different content of planned publications to improve recognition efficiency.
Due to differences in disciplines and target audiences, various manuscripts have significantly different character quantity requirements for OCR character libraries. Users can select different libraries based on the publication target. For example, for users engaged in natural science publications and primary and secondary school teaching aids, it is recommended not to use OCR libraries that include variant characters. Reducing the size of the character library can improve software operating efficiency and help increase the accuracy of specific manuscript recognition.
The following passage comes from the original manuscript of a certain secondary school teaching aid.
The cat hasn’t come to Aunt Guan’s house for two months. One morning, the township head Jin Keji, with a pale face, stood outside the door, and as soon as the door opened, he rushed in, pulling Aunt Guan along. While running, he took out a folded, square, tofu-like hard paper and handed it to Aunt Guan, saying urgently: “Mom, don’t be afraid, the cat will come to you tonight. Give this to him and tell him this thing was exchanged for life!”
—— Excerpt from Ru Zhijuan’s “Aunt Guan”, with modifications.
The text contains two variant characters: “岀” and “晩”. Because these two characters are very similar to the standard characters “出” and “晚”, it is easy to overlook corrections without proofreading tools or special methods (such as zooming in on the PDF).

▲ Enlarged variant characters “岀” and “晩”
The presence of variant characters in the character library leads OCR to select variant characters as the final recognition result in case of slight recognition deviations, which only complicates matters! If these two variant characters were absent, the recognized result should have been the standard characters. Teaching aid manuscripts, aside from a small number of variant characters used in language teaching aids, hardly require them in other subjects. Selecting the appropriate character library based on publication content helps improve publication quality.
♦ 5. Do not modify recklessly, nor fail to modify.
After understanding the characteristics of similar character errors caused by OCR, one should also remind oneself: some issues may not necessarily be caused by OCR, and it is important to understand other possible causes of similar errors; some problems are indeed caused by OCR, and one cannot subjectively attribute them to other reasons. Below, I will provide an example for each of the above situations.
(1) In the revised draft of a certain book, the author’s cursive caused the typesetter to trip. Please look at the two images below:

▲ Author’s original manuscript screenshot

▲ Editor’s proofreading manuscript screenshot
I feel quite emotional upon seeing this error. The cursive characters “灭” and “天” are very similar, and even in a standard printed form, I would not doubt that the two could be confused due to OCR recognition issues. However, in reality, this is not the fault of OCR. The typesetter tripped, and the editor learned a lesson!
(2) While proofreading a certain paper manuscript, I discovered that a stroke of the character “别” was missing. Because I had previously encountered situations where unclear printing caused stroke loss, I assumed it was a printing issue. Later, I found it was incorrect; I used the manuscript PDF to search the entire text and found that there were 128 standard characters “别” and 3 variant characters “別”. These 3 variant characters “別” were located on two pages, over 80 pages apart, among the 128 standard characters “别”. If the proofreading process relied solely on assumptions, it would be difficult to correct.

▲ The character “別” found in the PDF
Therefore, editors should try to collect the reasons for manuscript errors as much as possible, categorizing and storing them for flexible use to accurately and quickly address questions encountered during proofreading. One must never rely excessively on a single cause to explain a particular type of error.

Conclusion
In the future, the role of OCR in changing publishing will become increasingly evident. Editors, who are closely connected with OCR technology in the publishing industry, need to make targeted preparations in understanding both the phenomena and the underlying reasons. I hope the above discussion will help improve the professional capabilities of my colleagues.
(Note: Due to typesetting technical issues, this article uses a as equivalent to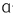 .)
.)



Typesetting丨 Zhang Yao
Proofreading丨 Yang Li Qi Lin
Operation丨 Wei Tong
Final Review丨 Zhao Yushan
More Topic Issues
Above[Scholar Q&A]Mini Program
Inquiry Sharing
(If the page is slow, you can click refresh multiple times)