
Introduction
This practical guide uses the 0.5B model of QWEN2.5 for fine-tuning on the Ruozhi Bar dataset.
1. How to quickly obtain affordable computing power
2. How to perform full parameter fine-tuning on the QWEN model
Computing Power Preparation
🚀 New Platform Launch, First Offering of 4090 GPU
The SuperTi GPU computing power rental platform is officially launched! We are excited to introduce the highly anticipated NVIDIA RTX 4090 GPU. Users who register for the first time and complete real-name verification willreceive 9 hours of free usage rights for the NVIDIA RTX 4090 GPU. This is not only our sincere welcome to new users but also an excellent opportunity for you to experience the charm of cloud acceleration. No complex configurations, no cost concerns, just a click and you can enjoy unprecedented computing performance in the cloud, allowing your AI projects to progress rapidly on the SuperTi platform.
🎁 Exclusive for New Registrations, 9 Hours Free Experience

💰 Limited Time Special Card at 1.98 Yuan/Hour, Best Value Choice
[Exclusive Link] 👉 www.superti-cloud.com 👈
Environment Configuration
In this practical guide, our hardware configuration uses the 4090 for training. Since the model size is small, we directly use full parameter fine-tuning. The training framework used is llamafactory.
Hardware Configuration Process
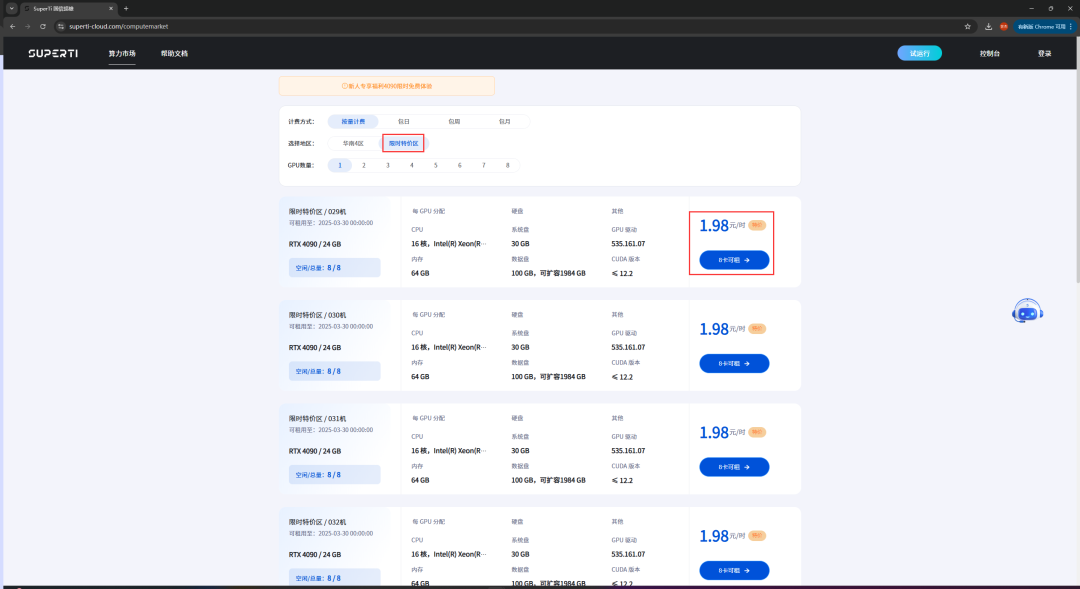
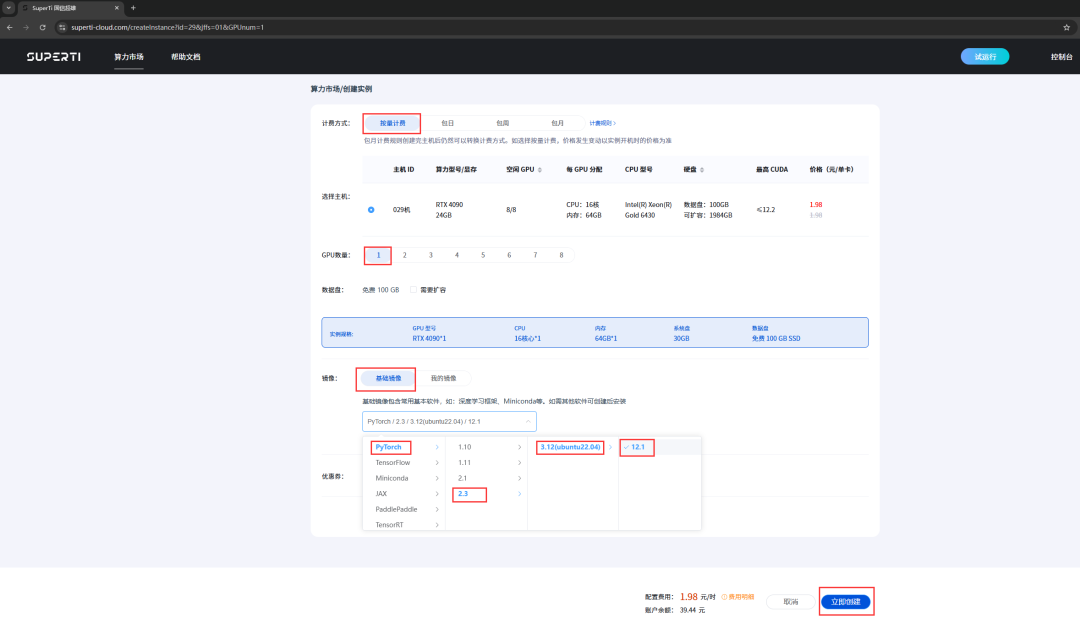
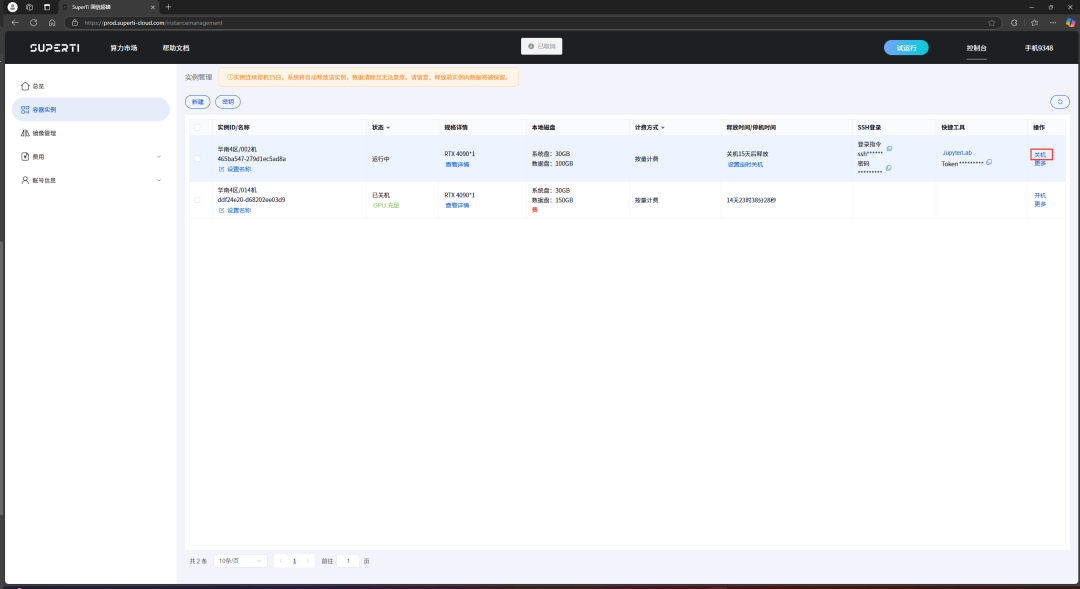
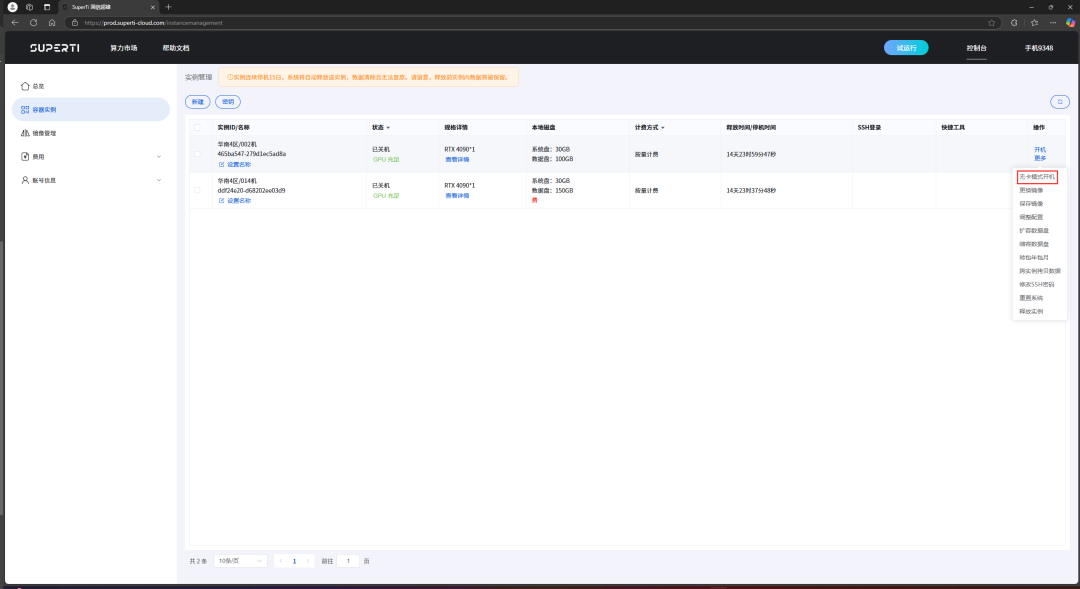
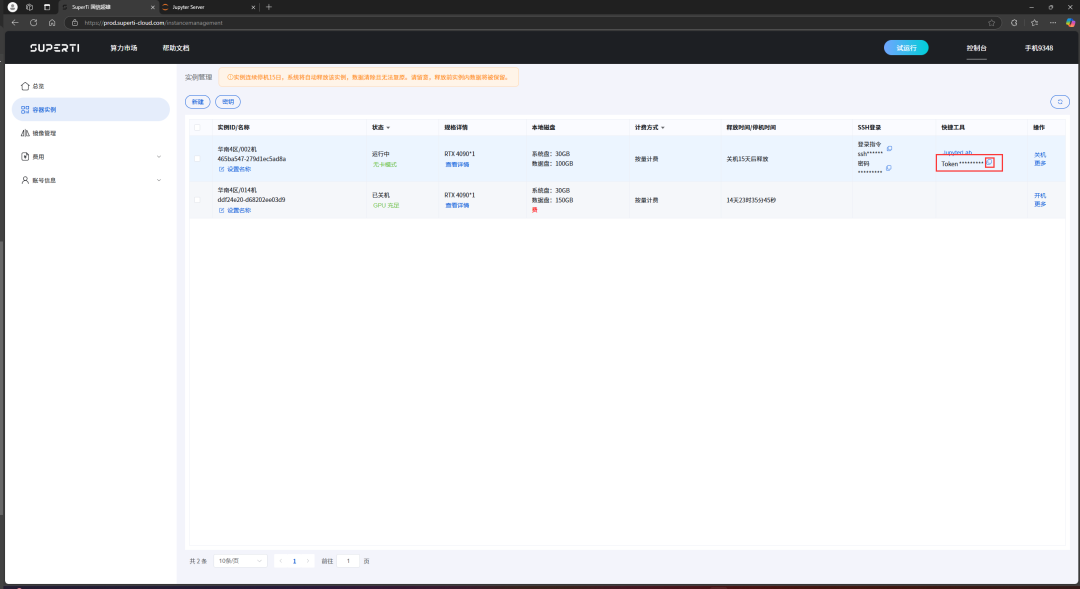
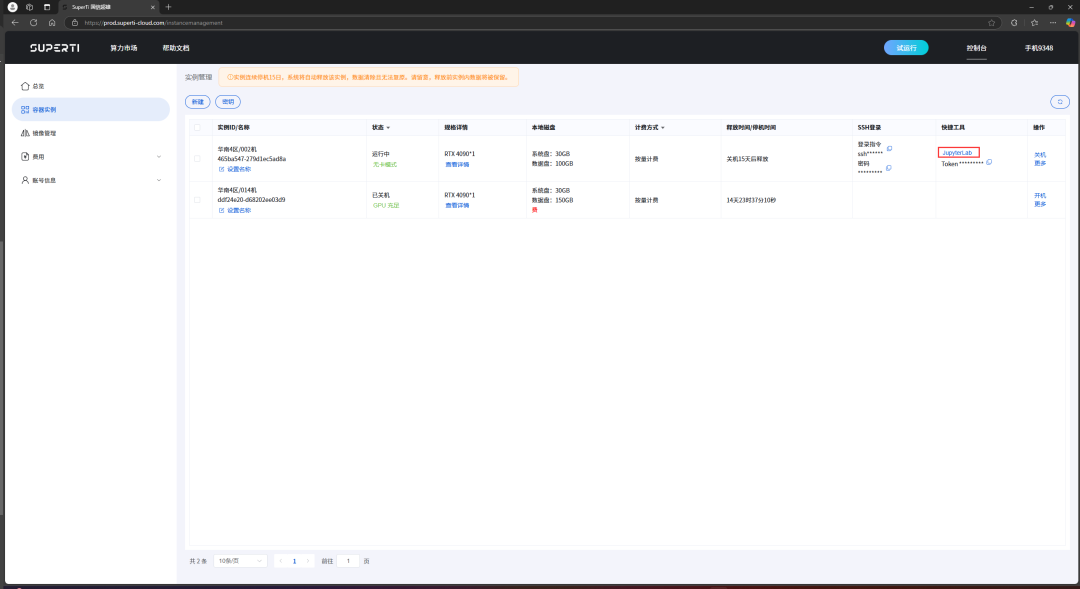
As recorded in the figure, we first click the copy token button and then enter JupyterLab.
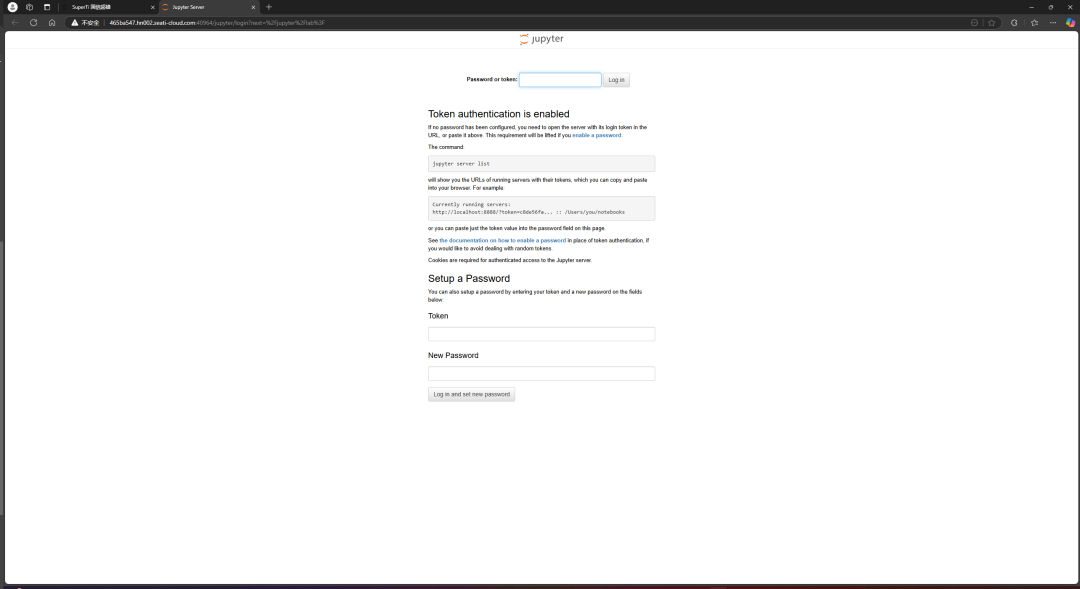
After the first appearance of the security verification interface, we paste the token we just copied into it and log in.
Dataset and Model Preparation
/root/miniconda3/bin/conda initconda create -n sft python=3.10conda activate sftpip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simplemodelscope download --dataset zhuangxialie/SFT-Chinese-Dataset ruozhiba/ruozhiout_qa_cn.jsonl --local_dir your_dataset_pathmodelscope download --model Qwen/Qwen2.5-0.5B --local_dir your_dataset_pathgit clone https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factorypip install -e ".[torch,metrics]" -i https://pypi.tuna.tsinghua.edu.cn/simplemodel_name_or_path: your_model_pathtemplate: qweninfer_backend: huggingface # choices: [huggingface, vllm]trust_remote_code: truellamafactory-cli chat qwen-inference.yamlAfter running the command and loading the model, we tested it with classic questions from the Ruozhi Bar:
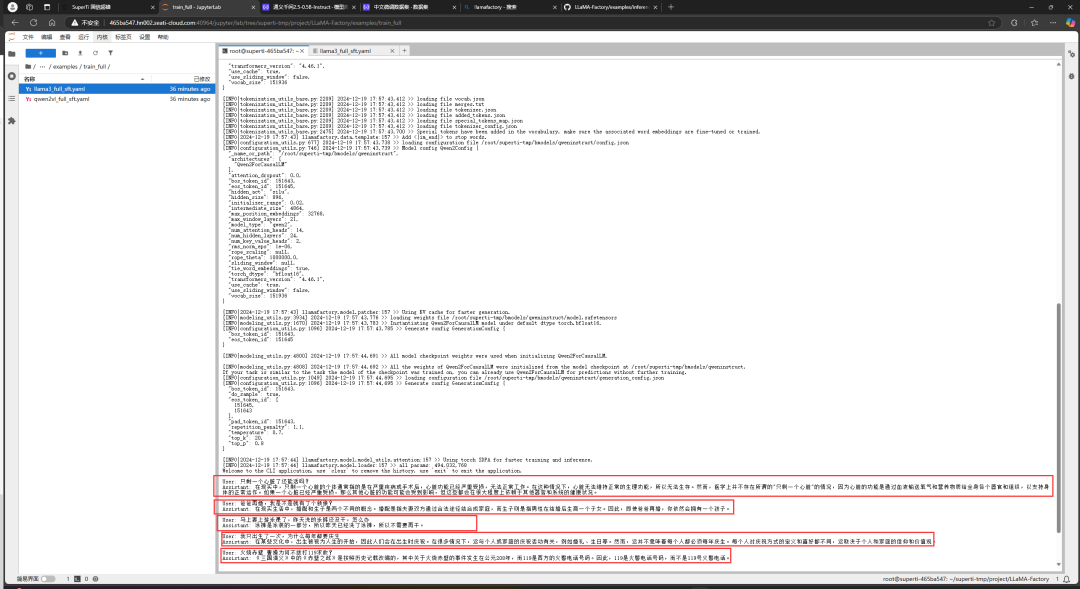
It can be seen that the un-fine-tuned model still lacks logical capability and tends to ramble.Next, we will start fine-tuning.
We need to enter the data directory under the LLaMA-Factory project directory to make simple configurations for the dataset. After entering the data directory, open dataset_info.json and add the following configuration:
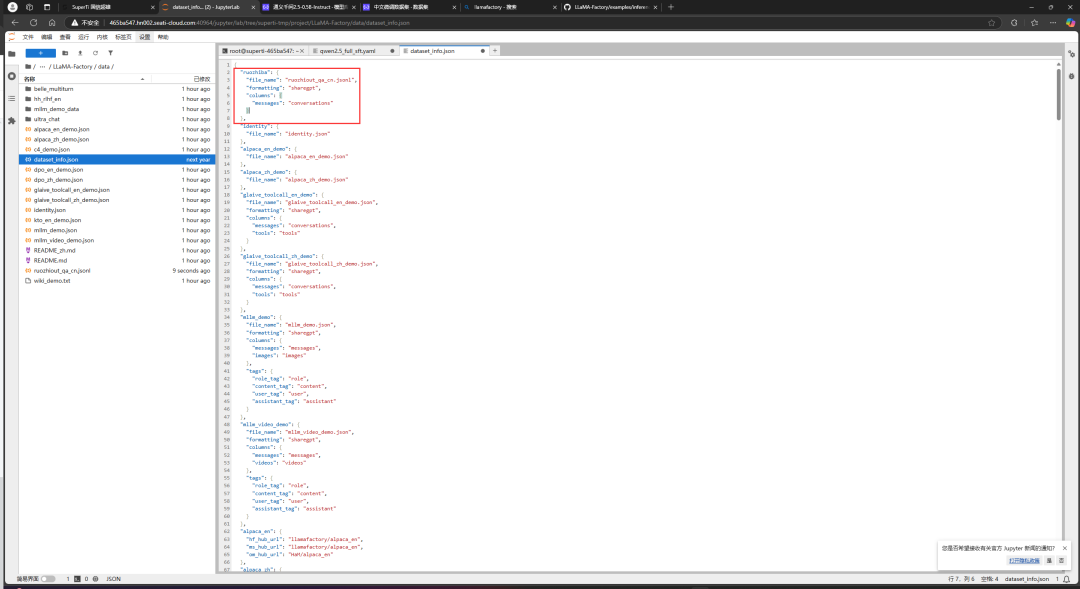
Change the file_name to the path of the Ruozhi Bar jsonl dataset, then create a training configuration file qwen2.5_full_sft.yaml
### modelmodel_name_or_path: your_model_pathtrust_remote_code: true
### methodstage: sftdo_train: truefinetuning_type: full#deepspeed: examples/deepspeed/ds_z3_config.json # choices: [ds_z0_config.json, ds_z2_config.json, ds_z3_config.json]
### datasetdataset: ruozhibatemplate: qwencutoff_len: 2048overwrite_cache: truepreprocessing_num_workers: 16
### outputoutput_dir: save_pathlogging_steps: 10save_steps: 500plot_loss: trueoverwrite_output_dir: true
### trainper_device_train_batch_size: 1gradient_accumulation_steps: 2learning_rate: 1.0e-5num_train_epochs: 3.0lr_scheduler_type: cosinewarmup_ratio: 0.1bf16: trueddp_timeout: 180000000
### evalval_size: 0.1per_device_eval_batch_size: 1eval_strategy: stepseval_steps: 500Paths that need to be modified:
Then use the following command to train
llamafactory-cli train qwen2.5_full_sft.yaml
After training is complete, we can perform inference testing; simply modify the model path in the previous inference configuration file qwen-inference.yaml to the path of the model saved after training, and run the inference command:
llamafactory-cli chat qwen-inference.yamlOnce loaded, you can start testing
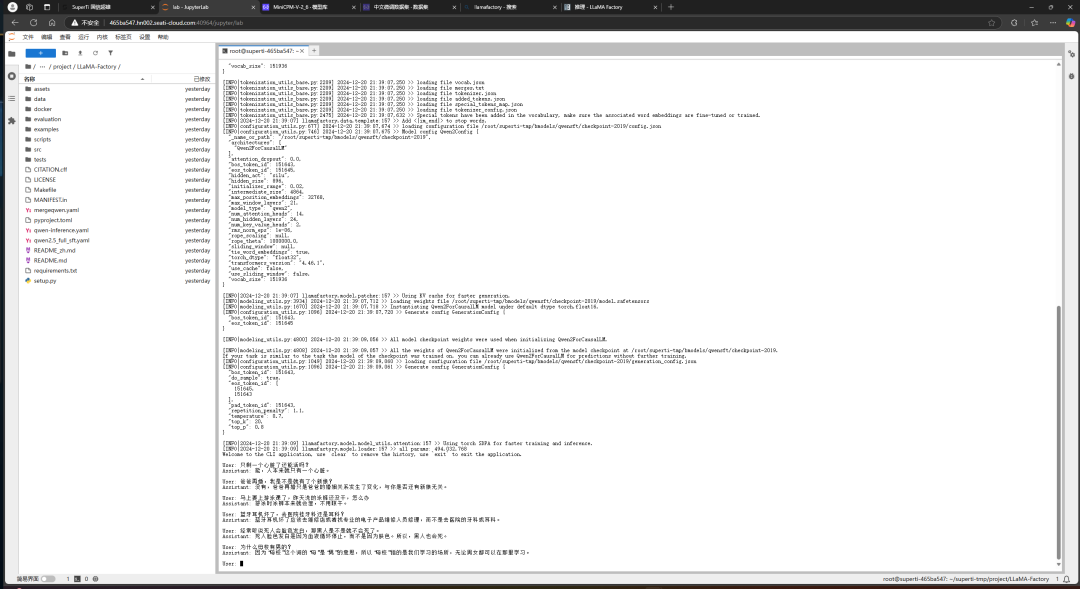
Take Action Now, Create the Future Together
At the SuperTi GPU computing power rental platform, every computation is an investment in the future. Now, let’s explore the infinite possibilities of computing power in the cloud together!
🔥Click here now to start your computing power rental journey!🔥