Big Data Digest authorized reprint from Data Pai THU
Translation: Wang Weili, Zhang Yihao
In our programming journey, we always turn to the most advanced architectures.
Thanks to deep learning frameworks such as PyTorch, Keras, and TensorFlow, implementing advanced architectures has become easier. These deep learning frameworks provide a simple way to implement complex model architectures and algorithms without requiring extensive expertise and programming skills. In summary, this is a goldmine for data science.
In this article, we will use the PyTorch framework, which is known for its fast computational capabilities. Therefore, we will introduce the key points for solving text classification problems. Then we will implement our first text classifier in the PyTorch framework!
Tip: Before continuing, it is recommended to read this article first.
A Beginner-Friendly Guide to PyTorch and How it Works from Scratch:
https://www.analyticsvidhya.com/blog/2019/09/introduction-to-pytorch-from-scratch/?utm_source=blog&utm_medium=building-image-classification-models-cnn-pytorch
Why Use PyTorch to Solve Text Classification Problems?
Before we dive into the professional concepts, let’s quickly get familiar with the PyTorch framework. The basic data unit in PyTorch is the Tensor, similar to numpy arrays in Python. The two most important advantages of using PyTorch are:
-
Dynamic networks – the network structure can change during training
-
Multi-GPU distributed training
I’m sure you’re wondering – why do we use PyTorch to handle text data? Next, let’s discuss some incredible features of PyTorch that set it apart from other frameworks, especially when dealing with text data.
Handling Out of Vocabulary Words
Text classification models are trained on text datasets of fixed data size. However, during inference, some words may not be covered in the vocabulary, known as Out of Vocabulary words.
Ignoring Out of Vocabulary words can lead to information loss, making it an important issue. To address this, PyTorch supports replacing rare words in the training dataset with an unknown token, helping us handle the Out of Vocabulary words problem.
Additionally, PyTorch provides methods for handling variable-length sequences.
Handling Variable-Length Text Sequences
Have you heard that Recurrent Neural Networks (RNNs) are used to solve variable-length sequences? Are you wondering how it works? PyTorch offers a useful ‘Packed Padding Sequence’ to implement dynamic RNNs.
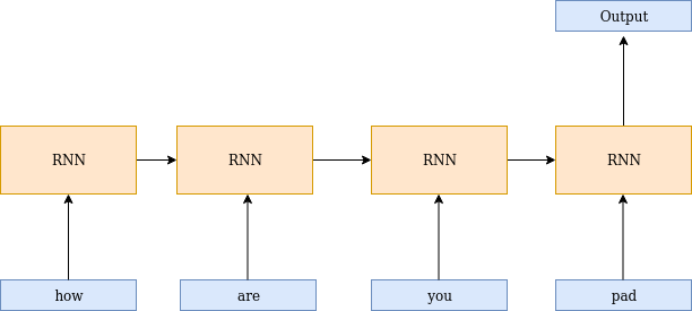
Padding is the process of adding extra tokens at the beginning or end of a sentence. Since each sentence has a different number of words, we input sentences of varying lengths, adding padding tokens to make them equal in length.
As most frameworks support static networks, meaning the model framework remains unchanged during training, padding is necessary. Although padding solves the variable-length sequence problem, it introduces a new issue – padding tokens add new information/data; I will explain this with a simple diagram.
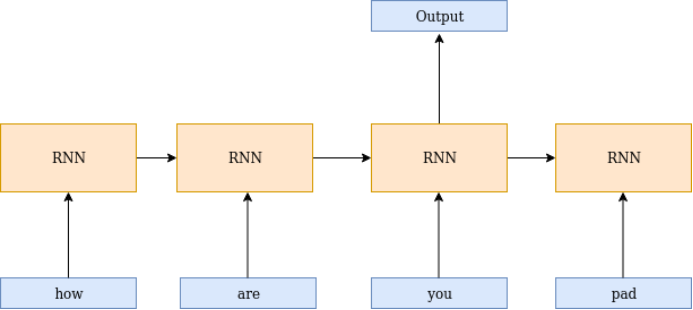
In the diagram below, the last word represents a padding token, but it also influences the output process. This issue can be handled by PyTorch’s Packed Padding Sequence.
Packed padding ignores the padding token parts. These values will never appear in the RNN’s training process, helping us build dynamic RNNs.
Packaging and Pre-trained Models
PyTorch is launching advanced frameworks. Hugging Face’s Transformers library provides over 32 advanced frameworks for Natural Language Understanding and Natural Language Generation.
Moreover, PyTorch also offers some pre-trained models that can solve text-to-language, object detection, and other problems with minimal code.
Can you believe it? These are some very useful features of PyTorch. Now let’s use PyTorch to solve the text classification problem.
Understanding the Problem Context
As part of this article, we will explore a very interesting problem.
Quora wants to track “insincere” questions on their platform to ensure users feel safe while sharing knowledge. In this case, an insincere question is defined as one that is intended to make a statement rather than seek useful answers. To break this down further, here are some features that indicate a specific question is insincere:
-
-
Derogatory or inflammatory;
-
-
Exploitive (incest, bestiality, pedophilia) for shock value rather than seeking genuine answers.
The training set includes the above-mentioned questions, along with a label indicating whether it is insincere (target=1 means insincere). There is noise in the basic facts, meaning the training set is not perfect. Our task is to identify whether a given question is “insincere”.
https://drive.google.com/open?id=1fcip8PgsrX7m4AFgvUPLaac5pZ79mpwX
Now it’s time to write our own text classification model using PyTorch.
Implementing Text Classification
First, import all the packages needed for modeling. Here’s a simple overview of the packages we will use:
-
The Torch package is used to define tensors and mathematical operations on tensors;
-
The TorchText package is the NLP library in PyTorch, containing some preprocessing scripts and common NLP datasets.
To ensure reproducibility, I specified a seed value. Due to the randomness of deep learning models, different results may occur during execution, so specifying a seed value is crucial.
Now let’s look at how to preprocess text using fields. There are two field objects – Field and LabelField. Let’s quickly understand their differences:
-
Field: A Field object from the data module, used to describe the preprocessing steps for each column in the dataset;
-
LabelField: LabelField is a special case of Field used only for classification tasks. It is only used to set the unk_token and sequential, both of which default to None.
Before using Field, let’s take a look at its different parameters and purposes:
-
Tokenize: Defines the tokenization method; here we use the spacy tokenizer as it employs a new tokenization algorithm;
-
Lower: Converts text to lowercase;
-
Batch_first: The first dimension of input and output is generally the batch size.
Then, create a list of tuples, where each tuple contains a column name and the second value is the field object. Additionally, arrange the tuples in the order of the columns in the CSV file, using (None, None) to indicate when we ignore a column. Read in the necessary columns – question and label.
fields = [(None, None), ('text', TEXT), ('label', LABEL)]
In this code block, I loaded the custom dataset by defining field objects. Now let’s split the dataset into training and validation data.
Preparing Input and Output Sequences
The next step is to build the vocabulary for the text and convert them into integer sequences. The vocabulary contains all unique words in the text, with each word assigned an index. Here are the parameters:
-
min_freq: Words in the vocabulary with a frequency below this parameter value will be mapped to the unknown token;
-
Two special tokens, an unknown token and a padding token, are added to the vocabulary: The unknown token is used to handle Out Of Vocabulary words; the padding token is used to make input sequences equal in length.
We build the vocabulary and initialize word embeddings using pre-trained word vectors. If you want to randomly initialize word embeddings, you can ignore the vector parameters.
Next, prepare the batches for training the model. The BucketIterator forms batches in a way that minimizes padding.
Now we need to define the model architecture to solve this binary classification problem. The nn module in Torch is the foundational module for all models. This means every model must be a subclass of the nn module.
I defined two functions, init and forward. Let me explain the application scenarios for these two functions.
-
init: The init function is automatically called when initializing an instance of the class. Therefore, it is also called the constructor. Parameters for the class need to be initialized in the constructor, and we need to define the layers that the model will use;
-
forward: The forward function defines the computational steps for the forward propagation of inputs.
Finally, let’s understand the details and parameters of each layer.
Embedding Layer: For any NLP-related task, word embeddings are crucial as they apply numerical representations of words. The embedding layer obtains a query table where each row represents a word embedding. The embedding layer can convert integer sequences that represent text into dense vector matrices. Two important parameters for the embedding layer:
-
num_embeddings: The number of words in the query table;
-
embedding_dim: The dimensionality of the vector representing a word.
LSTM: LSTM is a variant of RNN that can learn long-term dependencies. Here are some important parameters you should know about LSTM:
-
input_size: The dimensionality of the input vector;
-
hidden_size: The number of nodes in the hidden layer;
-
num_layers: The number of layers in the network;
-
batch_first: If set to True, the input and output tensor formats are (batch, seq, feature);
-
dropout: The default value is 0; if set to non-zero, the output results of each LSTM layer will go to the dropout layer, dropping the corresponding proportion of neurons with the probability of the dropout parameter;
-
bidirection: If True, the LSTM is bidirectional.
Linear Layer: The linear layer refers to the dense layer, with two important parameters:
-
in_features: The number of input features;
-
out_features: The number of nodes in the hidden layer.
Packed Padding: As discussed earlier, packed padding is used for dynamic RNNs. If packed padding is not used, the padded input will also be processed by the RNN, returning the hidden state of the padded elements. However, packed padding is a great wrapper that does not expose the padded inputs. It directly ignores the padding part and returns the hidden state of the non-padded elements.
Now that we have an understanding of all the components in this architecture, let’s look at the code!
The next step is to define hyperparameters and initialize the model.
Let’s look at the model summary and use pre-trained word embeddings to initialize the embedding layer. Here, I defined the model’s optimizer, loss, and metrics, with two phases of modeling:
-
Training Phase: model.train() sets the model into training mode and activates the dropout layers;
-
Prediction Phase: model.eval() begins the evaluation phase of the model and turns off the dropout layers.
Next, here’s the code block defining the functions for training the model.
So we have a function to train the model, but we also need a function to evaluate the model. Let’s do this!
Finally, we will train the model for a set number of epochs and save the best model from each epoch.
Let’s load the best model and define an inference function that accepts user-defined input and makes predictions. How amazing is that! Let’s use this model to predict a few questions.
We have seen how to build our own text classification model in PyTorch and understood the importance of packed padding. You can freely use hyperparameters of long short-term models, such as the number of hidden nodes, the number of hidden layers, etc., to further improve performance.
https://www.analyticsvidhya.com/blog/2020/01/first-text-classification-in-pytorch/
Intern/Full-Time Editor Journalist Recruitment
Join us and experience every detail of professional tech media writing, grow with a group of the best people in the most promising industry. Located at Tsinghua East Gate in Beijing, reply with “Recruitment” on the Big Data Digest homepage dialogue page for details. Please send your resume directly to [email protected]
People who click “Looking” have all become good-looking!