

Source: DeepHub IMBA
This article is approximately 2100 words long and is recommended to be read in 7 minutes.
This article summarizes the paper by Chai et al., which proposes a new method that enables diffusion models to edit videos with high temporal consistency.
The experiments in the paper show that compared to state-of-the-art methods, the video editing results are better.
The StableVideo proposed in the paper is a text-driven video editing framework that, through extensive experiments on natural videos, shows superior editing results while maintaining geometric shapes and temporal continuity compared to other diffusion-based methods.
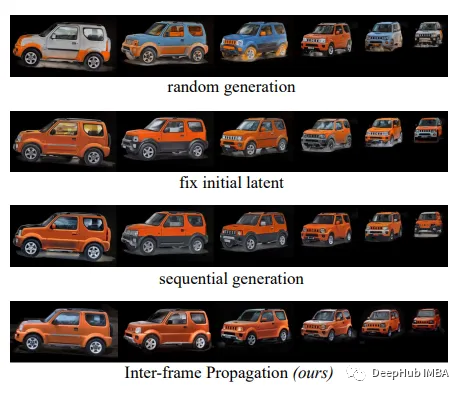
Image Editing and Diffusion Models
Diffusion models have become the state-of-the-art deep generative models for generating and editing high-fidelity images based on text prompts or conditions. Models like DALL-E 2 and Stable Diffusion can synthesize realistic images that match the desired text descriptions. For image editing, modifications can also be made semantically based on text.
However, applying diffusion models directly to video editing has remained a challenge so far. One of the main reasons here is the lack of temporal consistency: SD models edit each frame independently, often leading to flickering effects and discontinuous motion.
Atlas-based Video Editing
To smoothly propagate edits between video frames, many studies have proposed decomposing videos into atlas representations. Video frames are mapped to a unified two-dimensional coordinate space called atlases, which aggregate pixels over time. Editing this collection allows for coherent changes across the entire video during the mapping process.
Previous studies like Omnimates and Neural Layered Atlases (NLA) separate the foreground and background into different atlases. Text2LIVE adds an additional layer on the NLA atlas for text-driven appearance editing. However, research directly using diffusion models has not been successful.

StableVideo Framework
The StableVideo framework achieves high-quality diffusion-based video editing with temporal consistency by combining the strengths of both. The idea is to first edit keyframes rather than directly editing the atlas, then aggregate them into the edited atlas to achieve better results.
Specifically, the pipeline first uses NLA to decompose the input video into foreground and background atlases. Then, based on text prompts, the diffusion model edits the background and keyframe foreground separately. To ensure a coherent appearance, inter-frame propagation edits the foreground keyframes. The edited keyframes are aggregated into a new foreground atlas, which is reconstructed with the edited background to produce the final output video.

Method Overview
1. Video Decomposition Based on Neural Layered Atlases
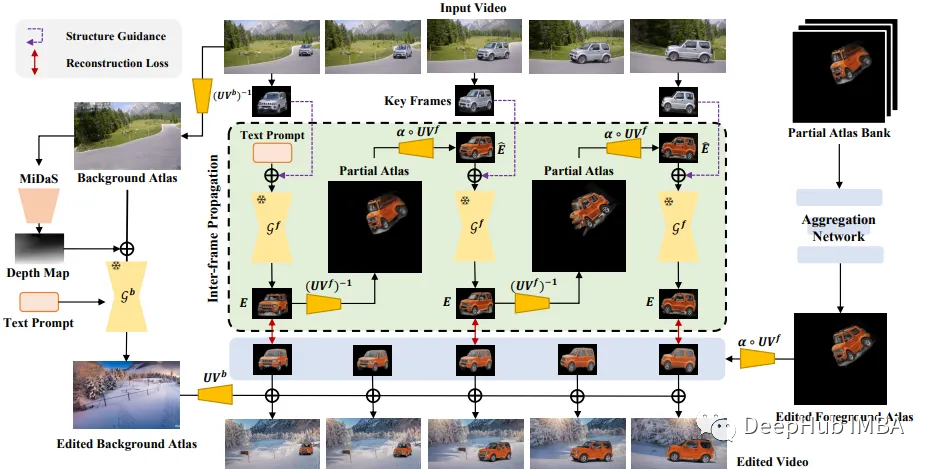
As a prerequisite, a pre-trained NLA model is used to decompose the input video into foreground and background atlases. This provides a mapping between pixel coordinates for the foreground and background:
UVb(.) = Mb(I)UVf(.) = Mf(I)Here, I is the input frame, while UVb and UVf give the corresponding positions in the background and foreground atlases, respectively.
2. Diffusion-based Editing
The actual editing process uses diffusion models Gb and Gf for background and foreground. Gb directly edits the background atlas, while Gf edits the keyframe foreground:
Ab_edit = Gb(Ab, text_prompt) // Edit background atlasEi = Gf(Fi, text_prompt) // Edit keyframeWorking on keyframes provides more reliable edits compared to severely distorted atlases.
3. Inter-frame Propagation of Foreground Edits
To ensure temporal consistency of keyframe edits, an inter-frame propagation mechanism is proposed. For the first frame F0, the diffusion model Gf edits normally:
E0 = Gf(F0, text_prompt, structure_guidance)For subsequent frames Fi, the editing conditions are the text prompt and the appearance of the previous frame Ei-1:
-
Mapping Ei-1 to the partial atlas ai-1f; -
Reverse mapping Ai-1_f to the current frame E^i; -
Denoising E^i under text prompt and structural guidance to obtain Ei.
This propagation allows for sequential generation of new foreground objects with consistent appearances between keyframes.
4. Atlas Aggregation
The edited keyframes are aggregated into a unified foreground atlas using a simple 3D CNN. This network is trained to minimize the reconstruction error between the keyframes and their reverse mapping from the aggregated atlas. This tight coupling ensures that edits are merged into a temporally consistent atlas.
Finally, the edited foreground and background atlases are mapped and composited to obtain the final edited video frames. The original foreground segmentation mask is used to mix the layers.
Advantages
The paper demonstrates various video editing scenarios including synthesis, style transfer, and background replacement on natural videos with complex actions. Both qualitative and quantitative experiments show that StableVideo outperforms existing diffusion-based methods:
-
Higher credibility of text prompts compared to Tune-A-Video; -
Significantly reduced flickering and deviations compared to Tune-A-Video; -
More comprehensive editing than Text2LIVE by avoiding atlas distortions; -
Faster inference than full video/re-training in Text2LIVE/Tune-A-Video.
Ablation experiments also validate the contributions of the proposed propagation and aggregation modules—keyframe propagation greatly improves appearance consistency compared to independent editing. It takes only 30 seconds to run for a 70-frame 768×432 video on one GPU.
Installation and Usage
git clone https://github.com/rese1f/StableVideo.git
conda create -n stablevideo python=3.11
pip install -r requirements.txt
All models and detectors can be downloaded from the ControlNet page.
The working directory looks like this:
StableVideo ├── ... ├── ckpt │ ├── cldm_v15.yaml | ├── dpt_hybrid-midas-501f0c75.pt │ ├── control_sd15_canny.pth │ └── control_sd15_depth.pth ├── data │ └── car-turn │ ├── checkpoint # NLA models are stored here │ ├── car-turn # contains video frames │ ├── ... │ ├── blackswan │ ├── ... └── ...
Run:
python app.py
After clicking the render button, the generated mp4 video and keyframes will be stored in the /log directory.
Conclusion
StableVideo is a new method for high-quality and temporally consistent text-driven video editing with diffusion models. The core idea is to edit keyframes and propagate appearances between them, aggregating edits into a unified atlas space. Extensive experiments show that this method has superior coherence in editing a wide range of natural videos. The technique provides an efficient solution to leverage powerful diffusion models for smooth video editing.
