Source丨Machine Heart
Editor丨Extreme City Platform
Extreme City Introduction
This article is the first comprehensive study introducing the progress of the SAM foundational model. It focuses on the application of SAM in various tasks and data types, discussing its historical development, recent advancements, and profound impacts on widespread applications.
Artificial Intelligence (AI) is evolving towards AGI, which refers to AI systems capable of performing a wide range of tasks and exhibiting human-like intelligence levels. In contrast, narrow AI is designed to efficiently execute specific tasks. Hence, the design of a general foundational model is urgent. Foundational models are trained on extensive data, allowing them to adapt to various downstream tasks. Recently, the Segment Anything Model (SAM) proposed by Meta has broken segmentation boundaries, significantly advancing the development of foundational models in computer vision.
SAM is a prompt-based model that has trained over 1 billion masks on 11 million images, achieving powerful zero-shot generalization. Many researchers believe “this is the GPT-3 moment for CV because SAM has learned the general concept of what objects are, even unknown objects, unfamiliar scenes (such as underwater, cellular microscopy), and ambiguous situations,” showcasing its enormous potential as a foundational model for CV.
To fully understand SAM, researchers from institutions such as the Hong Kong University of Science and Technology (Guangzhou) and Shanghai Jiao Tong University conducted in-depth research and jointly published the paper “A Comprehensive Survey on Segment Anything Model for Vision and Beyond.”

Paper: https://arxiv.org/abs/2305.08196
This paper is the first comprehensive introduction to the progress of the SAM foundational model, focusing on its applications across various tasks and data types while discussing its historical development, recent progress, and profound impacts on widespread applications.
The article first introduces the background and terminology of foundational models, including SAM, and the latest methods significant for segmentation tasks;
Then, the study analyzes and summarizes the advantages and limitations of SAM in various image processing applications, including software scenarios, real-world scenarios, and complex scenarios. Importantly, the study provides insights to guide future research in developing more versatile foundational models and improving SAM’s architecture;
Finally, the study summarizes the applications of SAM in vision and other fields.
Next, let’s look at the specific content of the paper.
Overview of the SAM Model
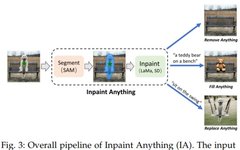
SAM originates from Meta’s Segment Anything (SA) project in 2023. This project discovered that foundational models emerging in the fields of NLP and CV exhibit strong performance, prompting researchers to establish a similar model to unify the entire image segmentation task. However, the available data in the segmentation field is relatively scarce, which differs from their design objectives. Therefore, as shown in Figure 1, researchers divided the path into three steps: task, model, and data.
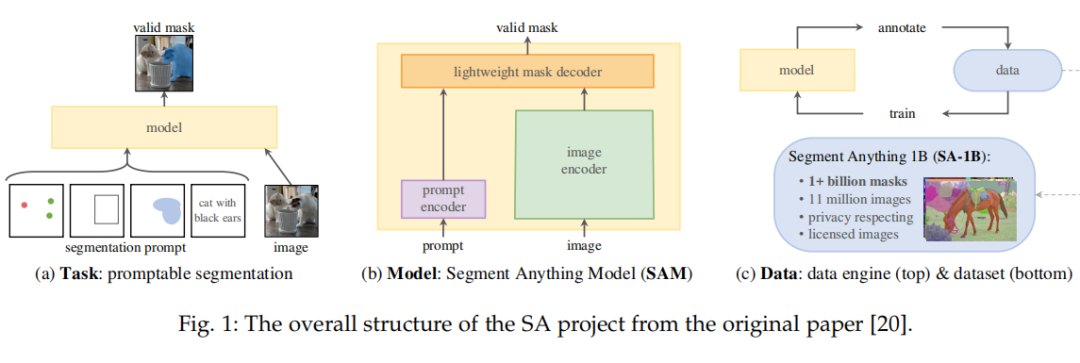
The architecture of SAM is shown below, mainly consisting of three parts: image encoder; prompt encoder; and mask decoder.
After gaining a preliminary understanding of SAM, the study then introduces SAM’s application in image processing.
SAM in Image Processing
This section introduces SAM by dividing it into scenarios: software scenarios, real-world scenarios, and complex scenarios.
Software Scenarios
Software scenarios require operations on image editing and restoration, such as object removal, object filling, and object replacement. However, existing restoration works, such as [99], [100], [101], [102], require fine annotations for each mask to achieve good performance, which is labor-intensive. SAM [20] can generate accurate masks with simple prompts like points or boxes, assisting in image editing scenarios.
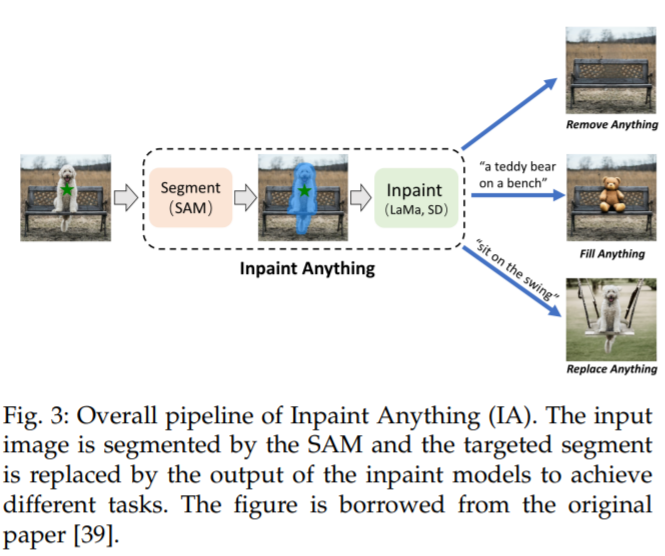
Inpaint Anything (IA) [39] designed a process that combines the advantages of SAM, state-of-the-art image restorers [99], and AI-generated content models [103] to address restoration-related issues. This process is illustrated in Figure 3. For object removal, the process consists of SAM and a state-of-the-art restorer, such as LaMa [99]. User clicks are used as prompts for SAM to generate a mask for the object region, which is then filled using corrosion and dilation operations by LaMa. For object filling and replacement, the second step employs AI-generated content models like Stable Diffusion (SD) [103] to fill the selected object with newly generated objects through text prompts.
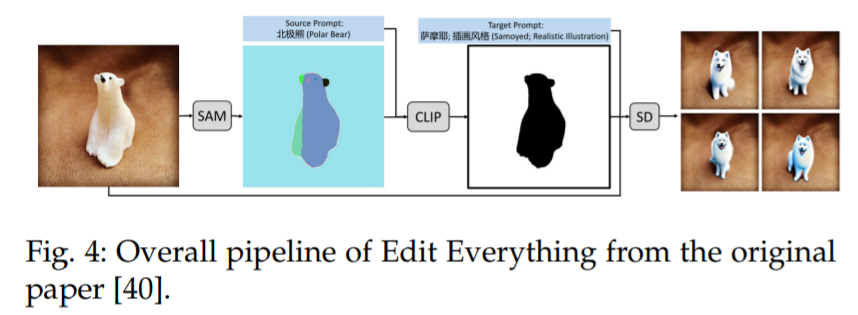
A similar idea can also be seen in Edit Everything [40], as shown in Figure 4, which allows users to edit images using simple text instructions.
Real-World Scenarios
Researchers indicate that SAM has the capability to assist in processing many real-world scenarios, such as real-world object detection, object counting, and moving object detection scenarios. Recently, [108] evaluated SAM’s performance in various real-world segmentation scenarios (e.g., natural images, agriculture, manufacturing, remote sensing, and healthcare scenarios). The paper found that in common scenarios like natural images, it exhibits excellent generalization capabilities, while its performance is poorer in low-contrast scenarios and requires strong prior knowledge in complex scenarios.
For instance, in the application of civil infrastructure defect assessment, [42] utilized SAM to detect cracks in concrete structures and compared its performance with the baseline U-Net [109]. The crack detection process is illustrated in Figure 6. The results show that SAM outperforms U-Net in detecting longitudinal cracks, which are more likely to find similar training images in normal scenes, while in uncommon scenarios, namely spalling cracks, SAM’s performance is inferior to U-Net.
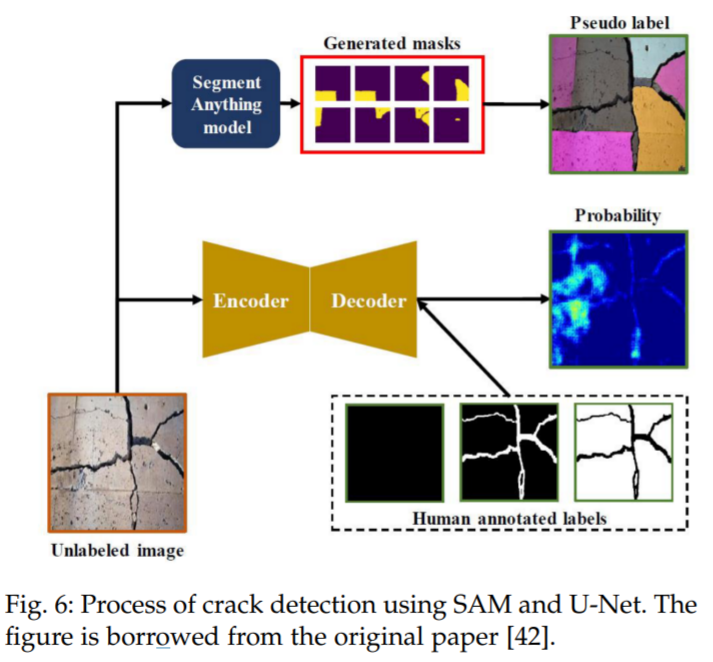
The process of using SAM and U-Net for crack detection. Figure excerpted from the original paper [42].
Unlike the complex image cases in crack detection, SAM is more suitable as a detection tool for crater detection, as the shapes of craters mainly focus on circular or elliptical forms. Craters are one of the most important morphological features in planetary exploration, and detecting and counting them is an important yet time-consuming task in planetary science. Although existing machine learning and computer vision works have successfully addressed some specific problems in crater detection, they rely on specific types of data and thus do not perform well across different data sources.
In [110], researchers proposed a general crater detection scheme using SAM for zero-shot generalization on unfamiliar objects. This process uses SAM to segment the input image without restrictions on data type and resolution. It then filters out segmentation masks that are not circular or elliptical using circular-elliptical indices. Finally, a post-processing filter is used to remove duplicates, artifacts, and false positives. This process demonstrates its enormous potential as a general tool in the current field, and the authors also discuss the disadvantages of being able to identify only specific shapes.
Complex Scenarios
In addition to the conventional scenarios mentioned above, whether SAM can solve segmentation problems in complex scenarios (such as low-contrast scenarios) is also a meaningful question that can expand its application range. To explore SAM’s generalization capabilities in more complex scenarios, Ji et al. [22] quantitatively compared it with cutting-edge models across three scenarios: camouflaged animals, industrial defects, and medical lesions. They conducted experiments on three camouflaged object segmentation (COS) datasets, namely CAMO [116] with 250 samples, COD10K [117] with 2026 samples, and NC4K [118] with 4121 samples, comparing them with Transformer-based models CamoFormer-P/S [119] and HitNet [120]. The results indicate that SAM lacks finesse in concealed scenarios and point out that potential solutions may rely on support from prior knowledge in specific domains. The same conclusion can also be drawn in [29], where the author compared SAM with 22 state-of-the-art methods for camouflaged object detection on the same three datasets.
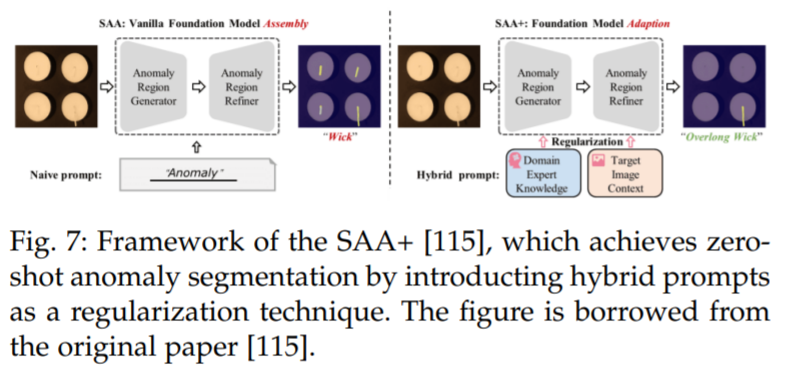
Cao et al. [115] proposed a new framework called Segment Any Anomaly + (SAA+), for zero-shot anomaly segmentation, as shown in Figure 7. This framework utilizes mixed prompt normalization to enhance the adaptability of modern foundational models, enabling more precise anomaly segmentation without domain-specific fine-tuning. The authors conducted detailed experiments on four anomaly segmentation benchmarks: VisA [122], MVTecAD [123], MTD [124], and KSDD2 [125], achieving state-of-the-art performance.
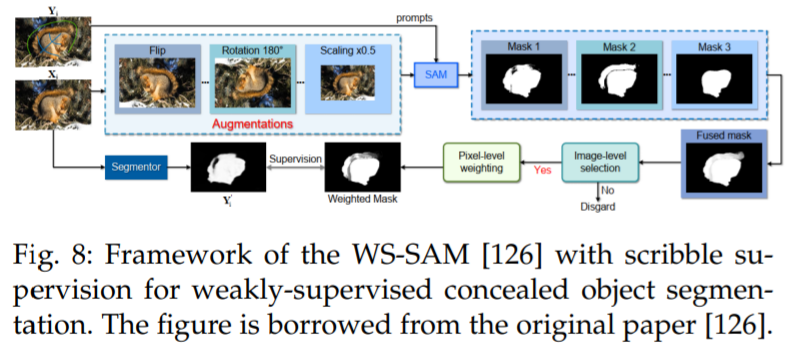
He et al. [126] proposed the first method (WSSAM) that utilizes SAM for weakly supervised segmentation of concealed objects, addressing the challenge of segmenting objects that blend into their surroundings using sparse annotated data (see Figure 8). The proposed WSSAM includes SAM-based pseudo-labeling and multi-scale feature grouping to enhance model learning and distinguish concealed objects from the background. The authors found that using only scribble supervision [127], SAM can generate sufficiently good segmentation masks to train the segmenter.
More Models and Applications: Vision and Beyond
Vision-Related
First, in medical imaging. The goal of medical image segmentation is to display the anatomical or pathological structures of the corresponding tissues, which can be used for computer-aided diagnosis and intelligent clinical surgery.
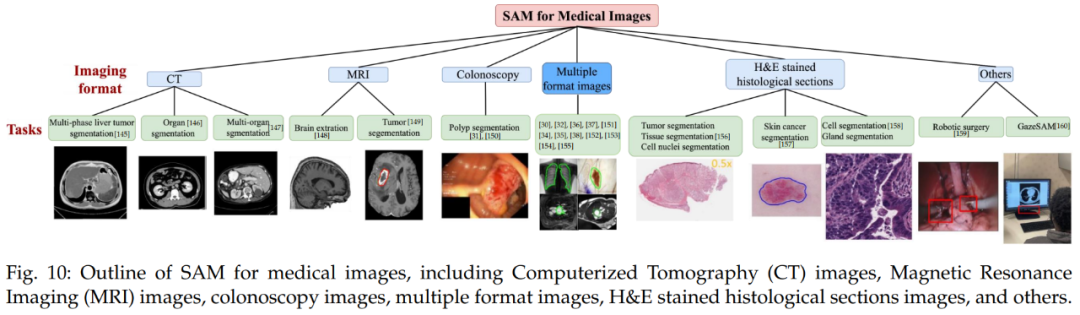
Figure 10 provides an overview of medical images with SAM, including computed tomography (CT) images, magnetic resonance imaging (MRI) images, colonoscopy images, multi-format images, and H&E stained tissue slice images.
Second, in videos. In the field of computer vision, video object tracking (VOT) and video segmentation are considered crucial and indispensable tasks. VOT involves locating specific targets in video frames and then tracking them throughout the rest of the video. Therefore, VOT has various practical applications, such as surveillance and robotics.
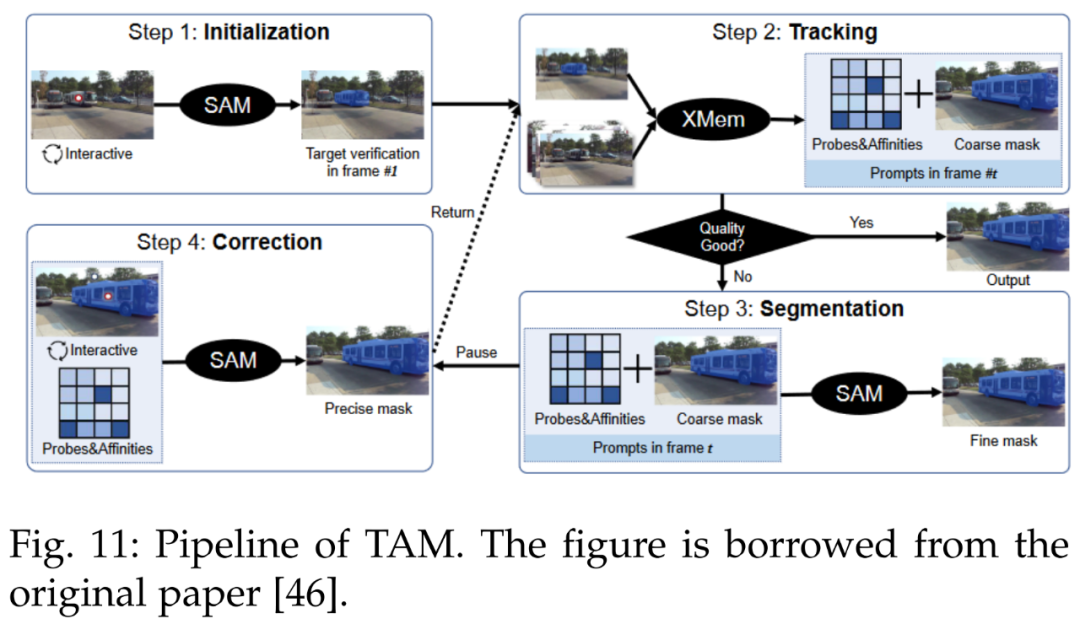
SAM has made outstanding contributions in the VOT field. Reference [46] introduced the Track Anything Model (TAM), which efficiently achieves excellent interactive tracking and segmentation in videos. Figure 11 shows the TAM pipeline.
Another tracking model is SAMTrack, detailed in reference [172]. SAMTrack is a video segmentation framework that achieves target tracking and segmentation through interactive and automatic methods. Figure 12 shows the SAMTrack pipeline.
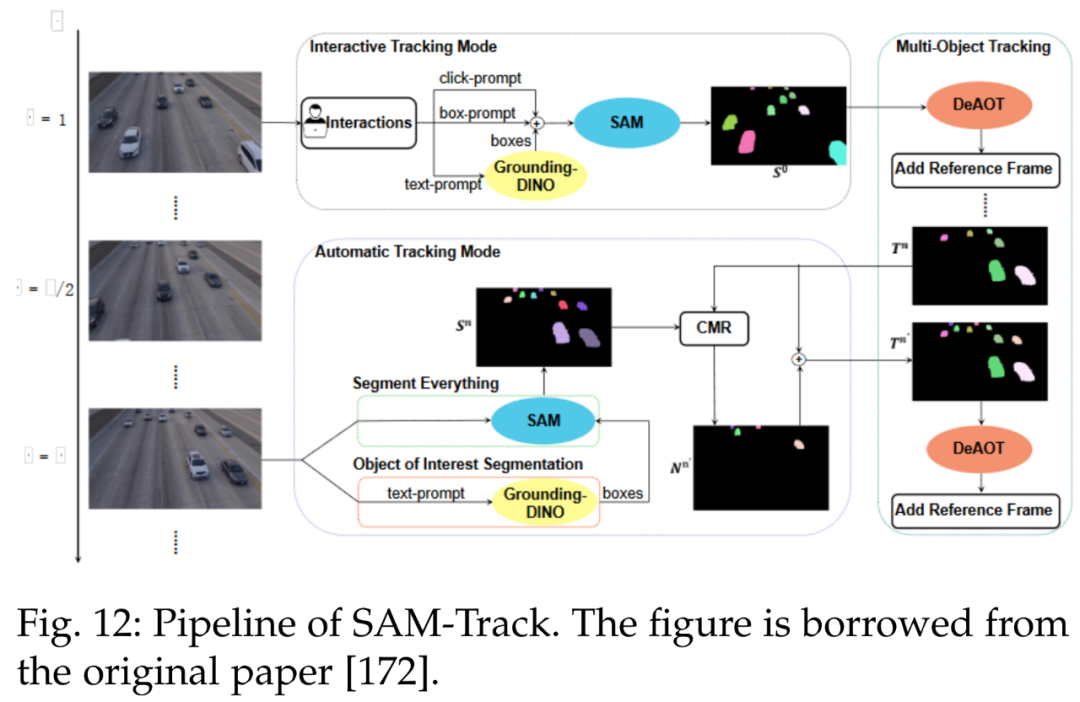
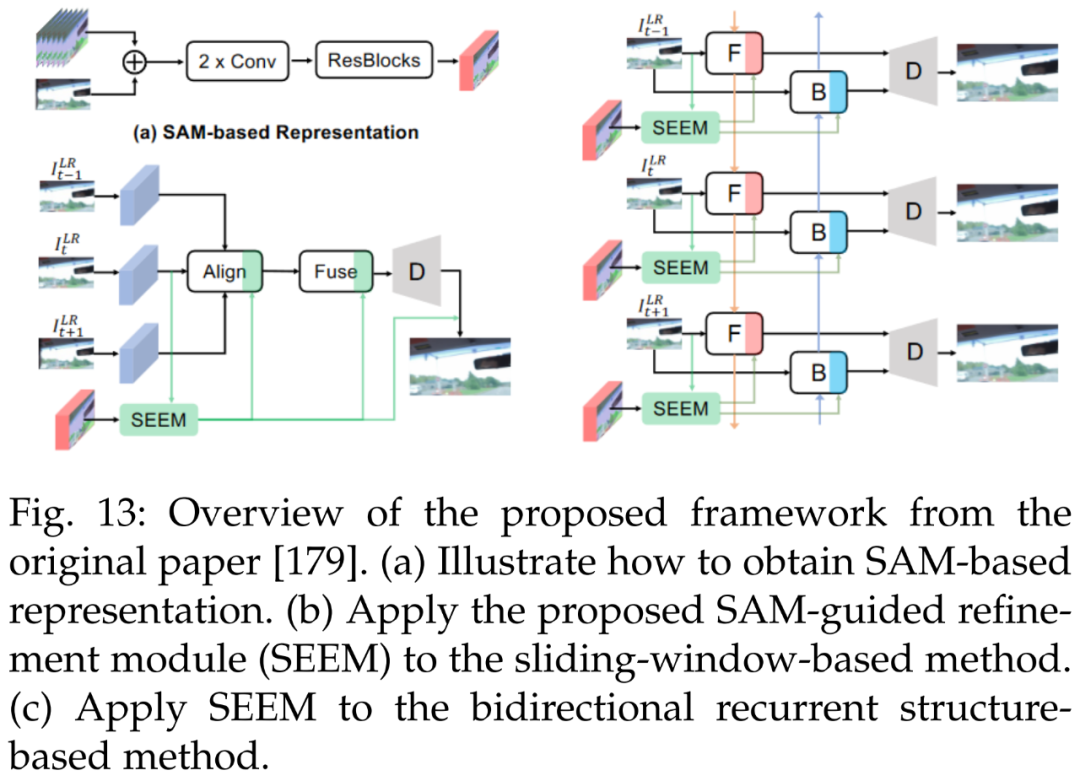
Figure 13 shows a lightweight SAM-guided optimization module (SAM-guided refinement module, SEEM) designed to enhance the performance of existing methods.
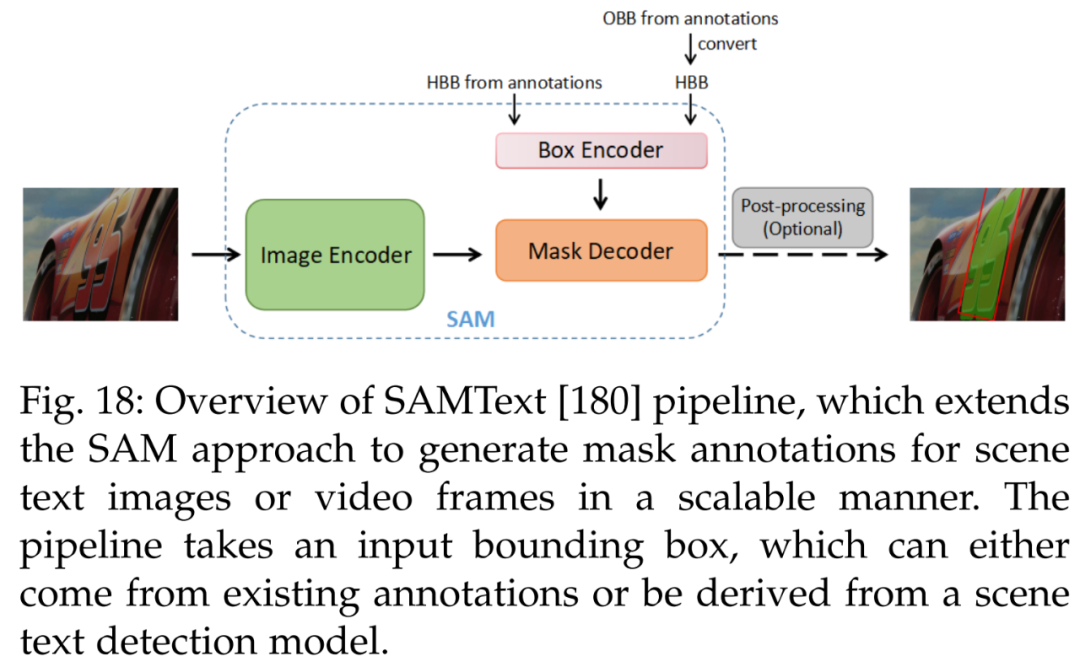
Next is data annotation. SAMText [180] is a scalable pipeline for scene text mask annotation in videos. It utilizes SAM to generate mask annotations on a large dataset, SAMText-9M, which contains over 2,400 video clips and more than 9 million mask annotations.
Moreover, reference [143] constructed a large-scale remote sensing image segmentation dataset, SAMRS, utilizing existing remote sensing object detection datasets and data-centric machine learning models SAM, which contains target classification, location, and instance information, and can be used for semantic segmentation, instance segmentation, and object detection research.
Beyond Vision
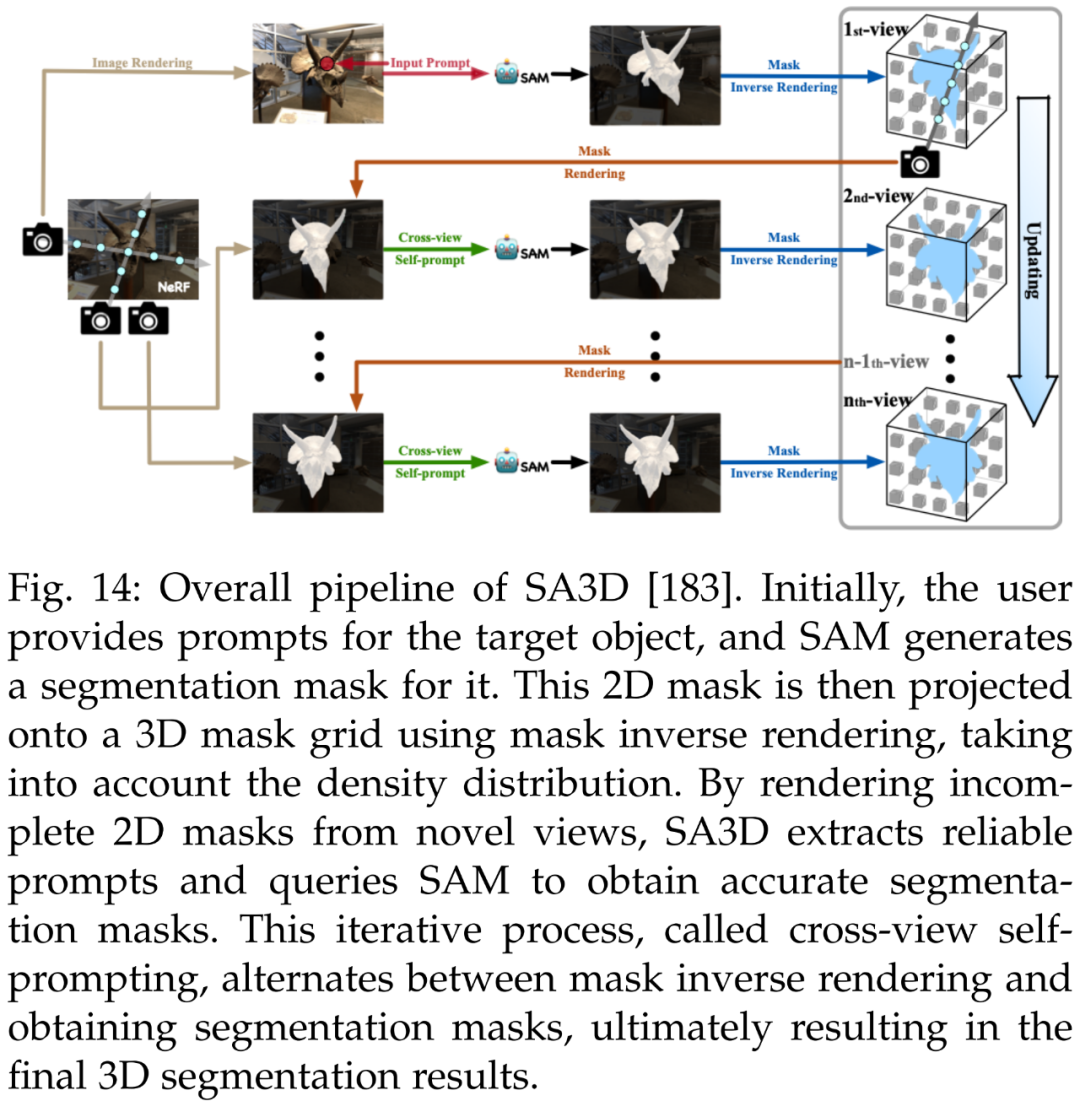
First, in 3D reconstruction. Besides achieving fine-grained 3D segmentation, SA3D [183] can be used for 3D reconstruction. Using 3D mask grids, researchers can determine the occupied space of objects in 3D and reconstruct in various ways. Figure 14 illustrates the overall pipeline of SA3D.
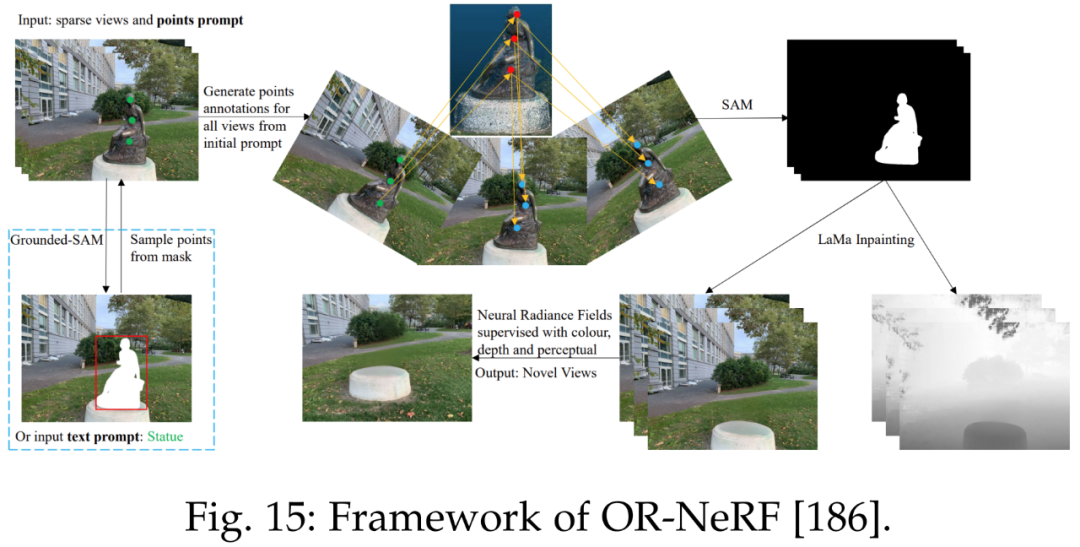
Reference [186] proposed a new object removal pipeline, ORNeRF, which removes objects from 3D scenes using point or text prompts on a single view. By quickly propagating user annotations to all views using point projection strategies, this method achieves better performance in less time than previous works. Figure 15 shows the framework of ORNeRF.
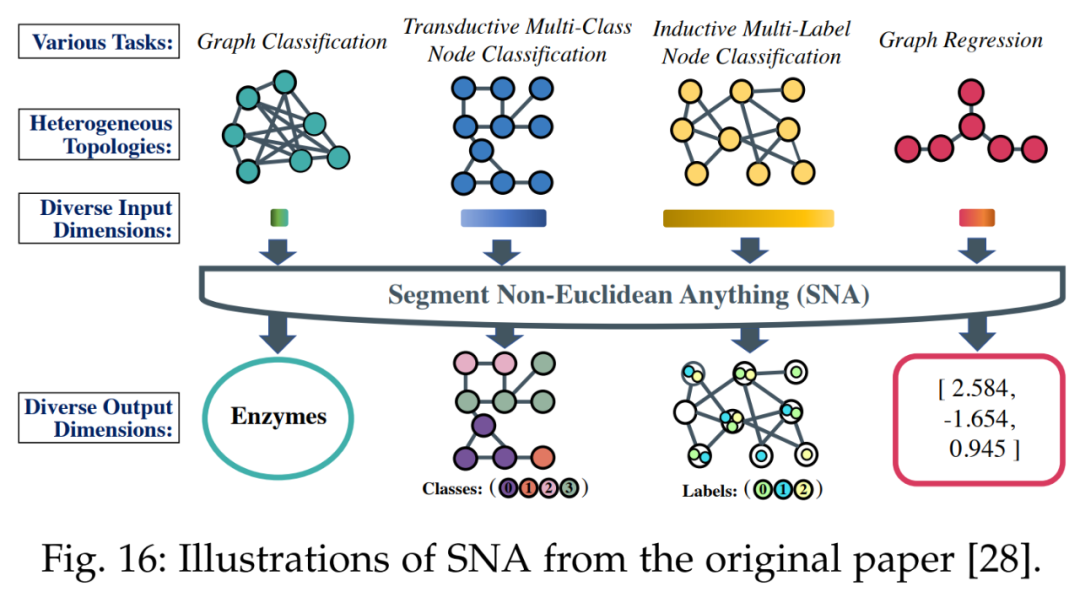
Next is non-Euclidean domains. To handle different feature dimensions for different tasks, the SNA method shown in Figure 16 introduces a specialized scalable graph convolution layer. This layer can dynamically activate or deactivate channels based on the input feature dimensions.
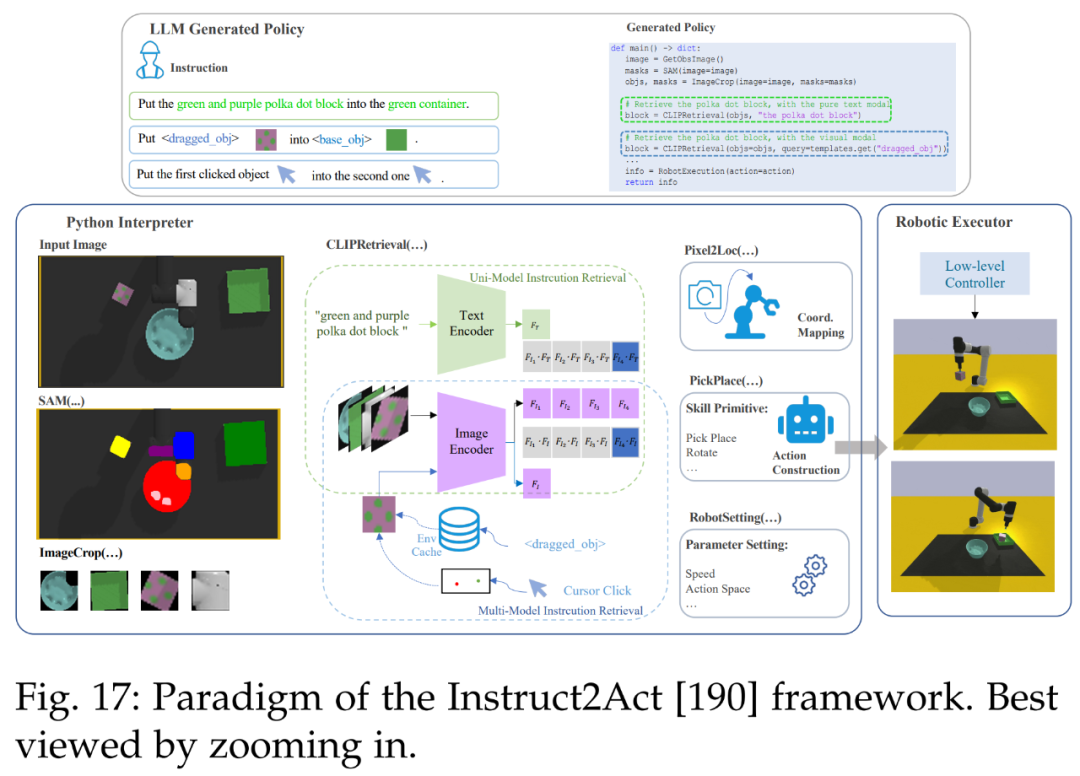
Then, in robotics. Figure 17 illustrates the overall process of Instruct2Act [190]. In the perception part, predefined APIs are used to access multiple foundational models. SAM [20] accurately locates candidate objects, and CLIP [13] classifies them. This framework leverages the expertise of foundational models and robotic capabilities to transform complex high-level instructions into precise strategy codes.
Next is video text localization. Figure 18 presents a scalable and efficient solution for generating mask annotations for video text localization tasks, SAMText [180]. By applying the SAM model to bounding box annotations, it can generate mask annotations for large-scale video text datasets.
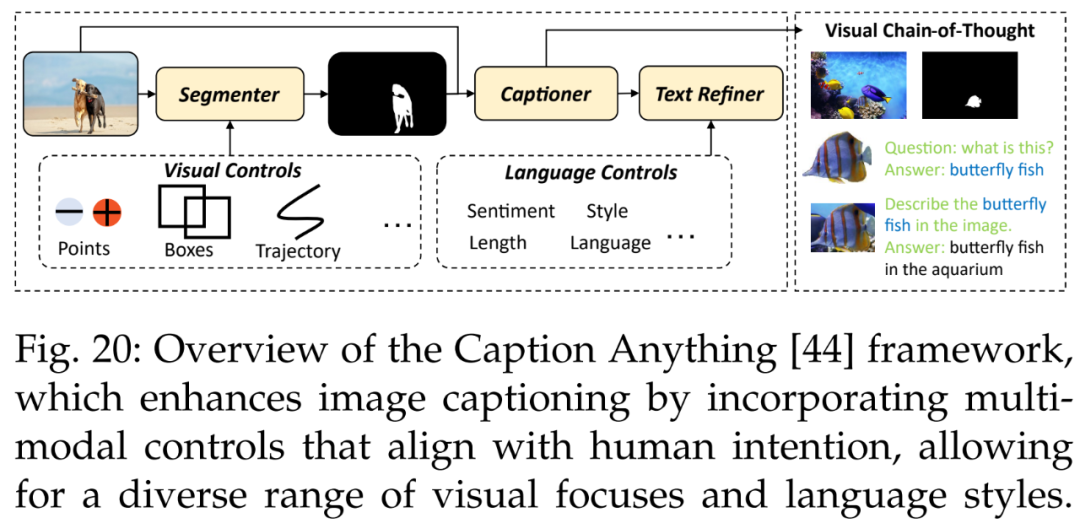
Additionally, there are image captions. Wang et al. [44] proposed a method for controllable image captioning, Caption Anything (CAT), as shown in Figure 20. The CAT framework introduces multimodal control into image captioning, presenting various visual focuses and language styles that align with human intentions.
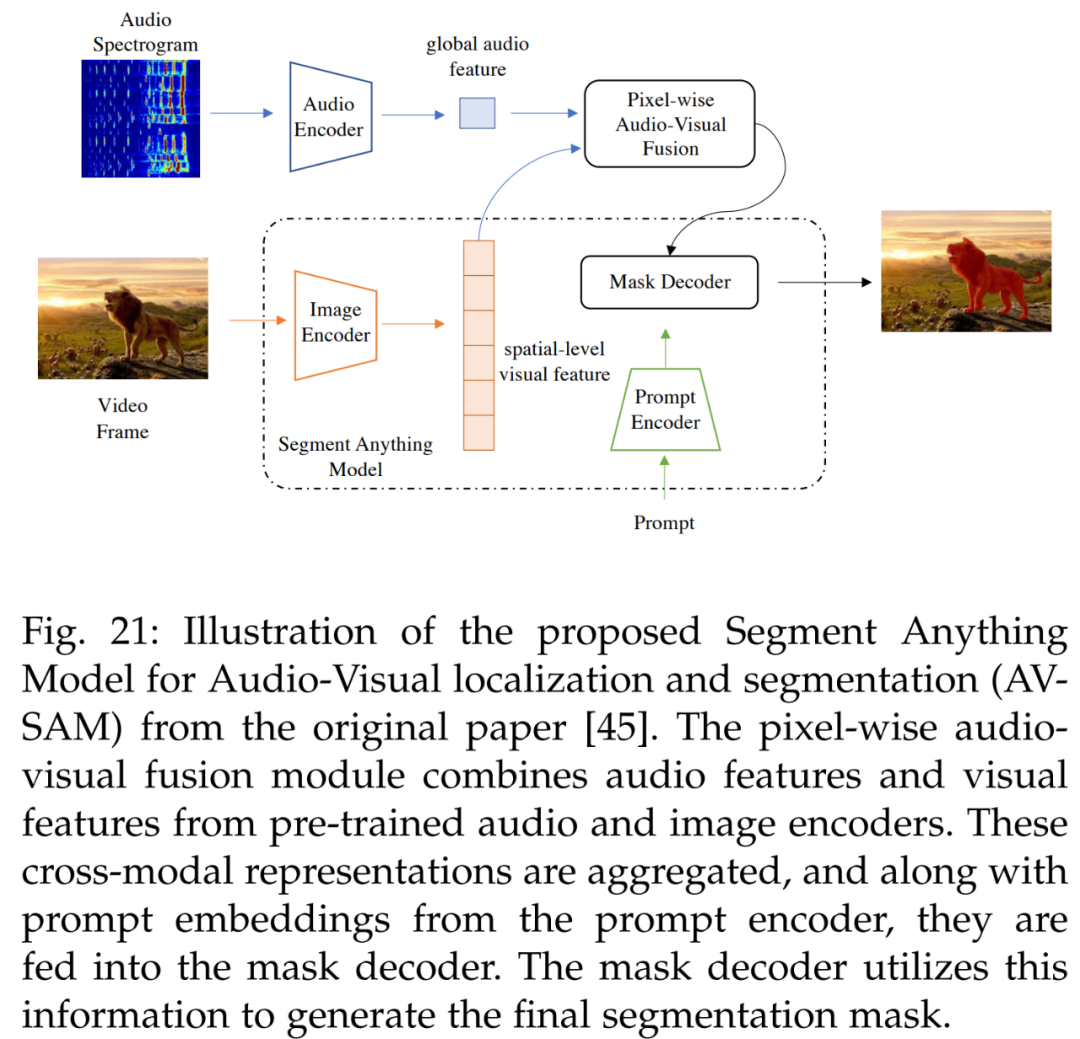
Audio-visual aspects are also involved. The audiovisual localization and segmentation method in reference [45] learns cross-modal representations that can align audio and visual information, as shown in Figure 21. AV-SAM utilizes pixel-level audiovisual fusion of cross-modal features in pre-trained audio and image encoders to aggregate cross-modal representations. The aggregated cross-modal features are then input into the prompt encoder and mask decoder to generate the final audiovisual segmentation mask.
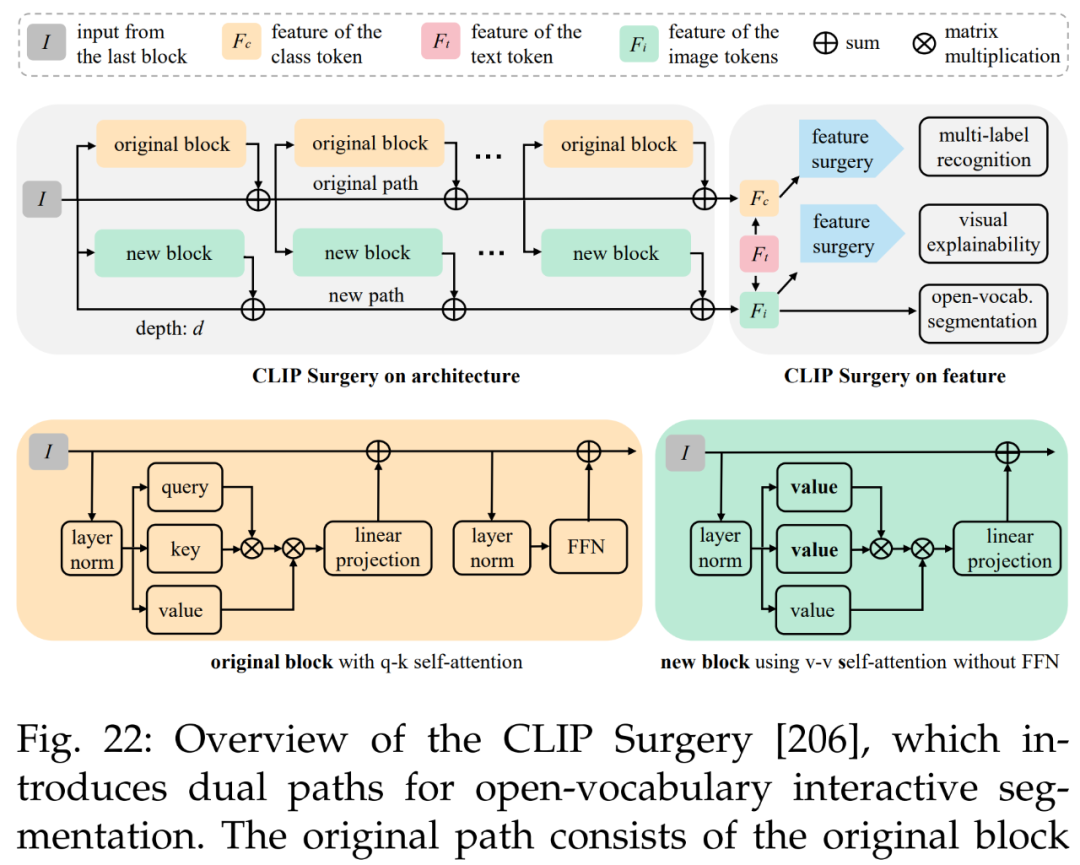
Finally, there is multimodal vision and open vocabulary interactive segmentation. The method in reference [44] is illustrated in Figure 22, aiming to completely replace manual points with a CLIP strategy using only text inputs. This approach provides pixel-level results from text inputs, which can easily be converted into point prompts for the SAM model.
Conclusion
This article provides a comprehensive review of the research progress of the SAM foundational model in computer vision and other fields for the first time. It first summarizes the historical development of foundational models (large language models, large visual models, and multimodal large models) and the basic terminology of SAM, focusing on its applications across various tasks and data types, summarizing and comparing SAM’s parallel work and its subsequent efforts. The researchers also discuss the enormous potential of SAM in a wide range of image processing applications, including software scenarios, real-world scenarios, and complex scenarios.
Additionally, the researchers analyze and summarize the advantages and limitations of SAM in various applications. These observations can provide insights for future development of more powerful foundational models and further enhance the robustness and generalization of SAM. The article concludes with a summary of numerous other astounding applications of SAM in vision and other fields.