
🫱Click here to join the group chat of 18 sub-fields (🔥Highly recommended)🫲
Paper Title: Depth Anything V2 Authors: Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao Project Address: https://depth-anything-v2.github.io/ Compiled by: xlh Reviewed by: Los
Abstract:
In monocular depth estimation research, the widely used labeled real images have many limitations, thus synthetic images are needed to ensure accuracy. To address the generalization issues caused by synthetic images, the authors adopted a data-driven (large-scale pseudo-labeled real images) and model-driven (expanding the teacher model) strategy. They also demonstrated the indispensable role of unlabeled real images in a real-world application scenario, proving that “accurate synthetic data + pseudo-labeled real data” is more promising than labeled real data. Finally, the research team distilled transferable knowledge from the teacher model to smaller models, similar to the core spirit of knowledge distillation, proving that pseudo-label distillation is easier and safer.©️【Deep Blue AI】Compiled

This work demonstrates Depth Anything V2, which aims to establish a powerful monocular depth estimation model without pursuing tricks. Notably, compared to V1, this version produces more refined and robust depth predictions through three key practices:
●Replacing all labeled real images with synthetic images;●Expanding the capacity of the teacher model;●Teaching the student model through a bridge of large-scale pseudo-labeled real images.
Compared to the latest models built on Stable Diffusion, Depth Anything v2 is more efficient and accurate. The authors provide models of different sizes (from 25M to 1.3B parameters) to support a wide range of scenarios. Thanks to its strong generalization ability, the research team fine-tuned the model using metric labels to obtain a metric depth model. In addition to the model itself, considering the limited diversity and frequent noise of the current test set, the research team constructed a versatile evaluation benchmark with precise annotations and diverse scenarios to facilitate future research.

Monocular depth estimation (MDE) has received increasing attention due to its significant role in a wide range of downstream tasks. Accurate depth information is beneficial not only in classical applications such as 3D reconstruction, navigation, and autonomous driving but also applicable in other generative scenarios.
From the perspective of model construction, existing MDE models can be divided into two categories: one based on discriminative models and the other based on generative models. According to the comparison results in Figure 1, Depth Anything is more efficient and lightweight. As shown in Table 1, Depth Anything V2 can achieve reliable predictions in complex scenes, including but not limited to complex layouts, transparent objects, reflective surfaces, etc.; it contains fine details in the predicted depth maps, including but not limited to thin objects, small holes, etc.; provides different model sizes and inference efficiencies to support a wide range of applications; and has sufficient generalizability to transfer to downstream tasks. Starting from Depth Anything v1, the research team launched v2, believing that the most critical part is still the data, which utilizes large-scale unlabeled data to accelerate data expansion and increase data coverage. The research team further constructed a versatile evaluation benchmark with precise annotations and diverse scenarios.
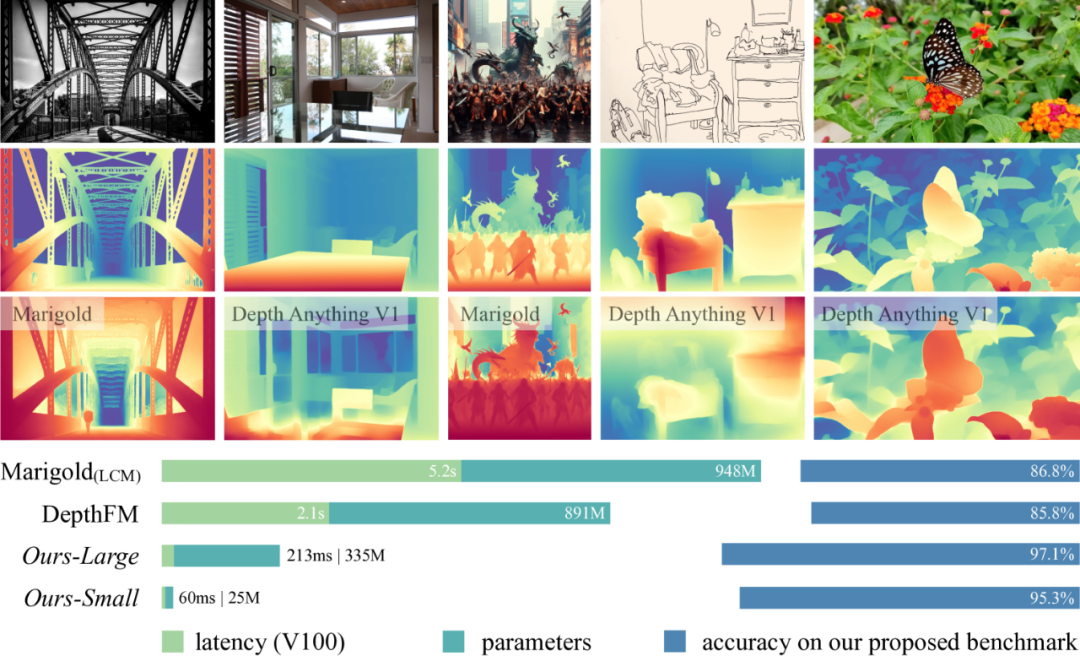 ▲Figure 1|Comparison of Depth Anything v2 with other models ©️【Deep Blue AI】Compiled
▲Figure 1|Comparison of Depth Anything v2 with other models ©️【Deep Blue AI】Compiled ▲Table 1|Preferred Characteristics of Powerful Monocular Depth Estimation Models ©️【Deep Blue AI】Compiled
▲Table 1|Preferred Characteristics of Powerful Monocular Depth Estimation Models ©️【Deep Blue AI】Compiled
Revisiting the design of labeled data for Depth Anything V1, is such a large number of labeled images really beneficial? Labeled real data has two drawbacks: one is label noise, meaning the labels in the depth maps are inaccurate. Due to the inherent limitations of various collection procedures, labeled real data inevitably contains inaccurate estimates, such as failing to capture the depth of transparent objects, and the impact of stereo matching algorithms and SFM algorithms when dealing with dynamic objects or outliers. The other is detail neglect, as some real data often neglect certain details in the depth maps, such as the depth of trees and chairs often being represented very coarsely. To overcome these issues, the researchers decided to change the training data, seeking images with the best annotations and specifically utilizing synthetic images with depth information for training, extensively examining the label quality of synthetic images.
Advantages of Synthetic Images:
● All fine details will be correctly labeled, as shown in Figure 2;
● Actual depths of challenging transparent objects and reflective surfaces can be obtained, as shown in the vase in Figure 2.
 ▲Figure 2|Depth of Synthetic Data ©️【Deep Blue AI】Compiled
▲Figure 2|Depth of Synthetic Data ©️【Deep Blue AI】Compiled
However, synthetic data also has the following limitations:
● There is a distribution bias between synthetic images and real images. Although current image engines strive for photorealistic effects, there are still significant differences in style and color distribution compared to real images. The colors of synthetic images are too “clean,” and the layouts are too “ordered,” while real images contain more randomness;
● The scene coverage of synthetic images is limited. They are iteratively sampled from graphic engines with predefined fixed scene types, such as “living room” and “street view.”
Therefore, in MDE, transferring from synthetic images to real images is not an easy task. To alleviate the generalization problem, some works use a combined training set of real images and synthetic images, but the coarse depth maps of real images can be detrimental to fine-grained predictions. Another potential solution is to collect more synthetic images, but this is unsustainable. Thus, in this paper, the researchers propose a roadmap to solve the accuracy and robustness dilemma without making any trade-offs, applicable to any model scale.
 ▲Figure 3|Qualitative Comparison of Different Visual Encoders in Synthetic-to-Real Transfer ©️【Deep Blue AI】Compiled
▲Figure 3|Qualitative Comparison of Different Visual Encoders in Synthetic-to-Real Transfer ©️【Deep Blue AI】Compiled
The solution proposed by the research team is to integrate unlabeled real images. The team’s strongest MDE model is based on DINOV2-G, initially trained only with high-quality synthetic images, then assigns pseudo-depth labels on unlabeled real images, and finally trains only with large-scale and accurate pseudo-labeled images. Depth Anything v1 highlighted the importance of large-scale unlabeled real data. Addressing the shortcomings of synthetic labeled images, the role of integrating unlabeled real images is elaborated:
● Bridging the Gap: Due to distribution shifts, directly transferring from synthetic training images to real test images is challenging. However, if additional real images can be utilized as intermediate learning objectives, the process will be more reliable. Intuitively, after explicitly training on pseudo-labeled real images, the model can become more familiar with the data distribution of the real world. Compared to manually annotated images, automatically generated pseudo-labels are finer and more complete.
● Enhancing Scene Coverage: The diversity of synthetic images is limited and does not cover enough real scenes. However, by merging large-scale unlabeled images from public datasets, a wide variety of different scenes can be easily covered. Additionally, since synthetic images are redundantly resampled from predefined videos, they are indeed very redundant. In contrast, unlabeled real images are clear and rich in information. By training on sufficient images and scenes, the model not only exhibits stronger zero-shot MDE capabilities but also serves as a better training source for downstream related tasks.
● Transferring Experience from the Strongest Model to Smaller Models: As shown in Figure 5, smaller models alone cannot directly benefit from the transfer from synthetic to real. However, with large-scale unlabeled real images, they can learn to mimic the high-quality predictions of stronger models, similar to knowledge distillation.

 ▲Figure 4|Depth Anything v2 ©️【Deep Blue AI】Compiled
▲Figure 4|Depth Anything v2 ©️【Deep Blue AI】Compiled
■3.1 Overall Framework
Based on the above analysis, the training process for Depth Anything v2 is as follows:
● Train a reliable teacher model based on high-quality synthetic images using DINOv2-G;
● Generate precise pseudo-depth on large-scale unlabeled real images;
● Train the final student model on pseudo-labeled real images to achieve robust generalization.
The research team released four student models based on small, base, large, and gigantic models of DINOv2.
■3.2 Details
As shown in Table 2, training was conducted using five precise synthetic datasets and eight large-scale pseudo-labeled real datasets. Similar to V1, for each pseudo-labeled sample, the top-n-largest-loss regions are ignored, where n is set to 10%. Meanwhile, the model can produce affine invariant inverse depth as it optimizes the labeled images using two loss terms, namely translation-invariant loss and gradient matching loss. Among them, gradient matching loss is very effective for depth clarity optimization when using synthetic images. On pseudo-labeled images, additional feature alignment loss is added following V1 to retain the semantic information from the pre-trained DINOv2 encoder.
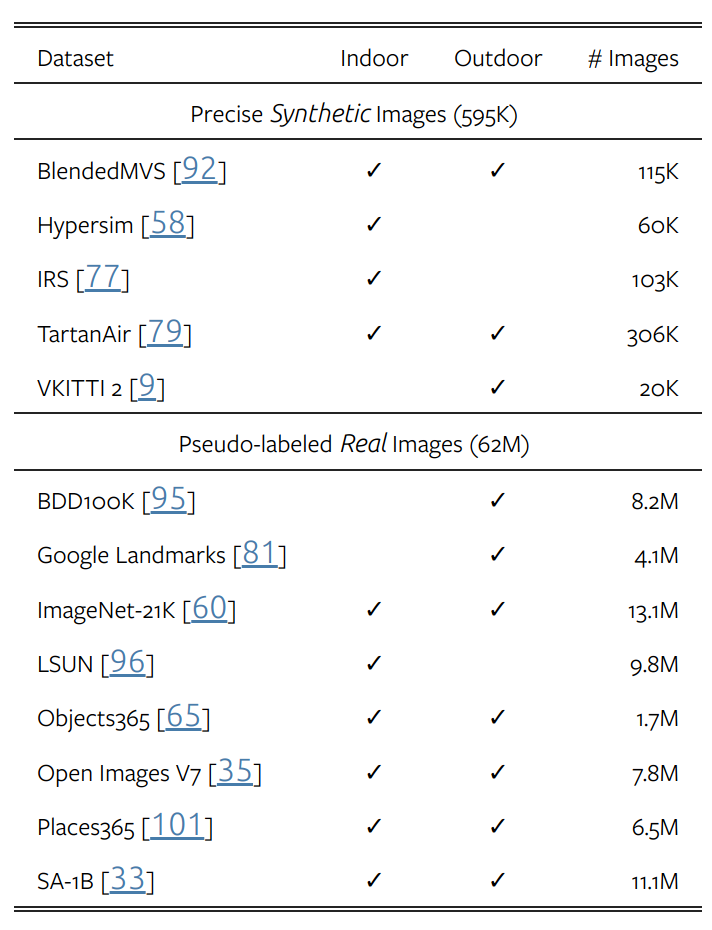 ▲Table 2|Training Datasets ©️【Deep Blue AI】Compiled
▲Table 2|Training Datasets ©️【Deep Blue AI】Compiled
■3.3 DA-2K
Considering the limitations of existing noisy data, the goal of this research is to construct a universal relative monocular depth estimation evaluation benchmark. This benchmark can:
● Provide accurate depth relations;● Cover a wide range of scenes;● Include most high-resolution images suitable for modern use.
In fact, it is challenging for humans to label the depth of every pixel, especially for natural images, so researchers label sparse depth for each image. Typically, for a given image, two pixels can be selected and their relative depth determined.
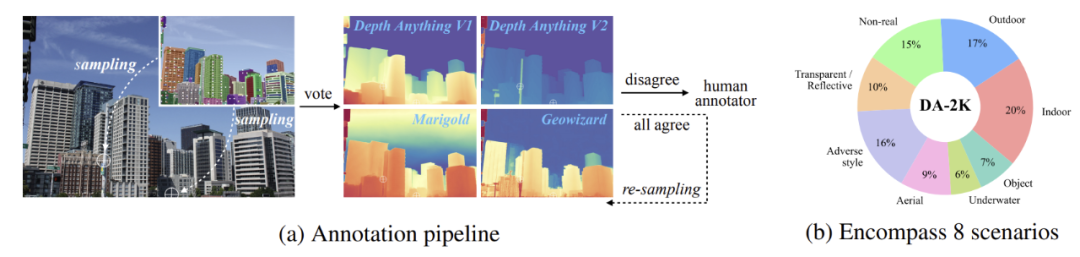 ▲Figure 5|DA-2K ©️【Deep Blue AI】Compiled
▲Figure 5|DA-2K ©️【Deep Blue AI】Compiled
Specifically, two different pipelines can be used to select pixel pairs. In the first pipeline, as shown in Figure 5(a), SAM is used to automatically predict object masks. However, there may be cases where the model prediction occurs, leading to the introduction of a second pipeline to carefully analyze images and manually identify challenging pixel pairs. DA-2K does not replace current benchmarks; it merely serves as a prerequisite for accurate dense depth.

Like Depth Anything v1, DPT is used as the depth decoder and constructed based on the DINO v2 encoder. All images are cropped to 518 for training, with a batch size of 64 for 160k iterations when training the teacher model on synthetic images. In the third stage of training on pseudo-labeled real images, the model uses a batch size of 192 for 480k iterations. The Adam optimizer is used, with learning rates set at 5e-5 and 5e-6 for the encoder and decoder, respectively.
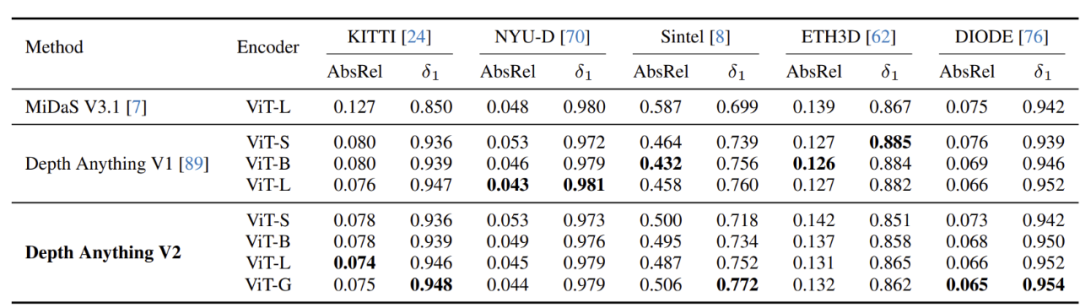 ▲Table 3|Zero-shot Depth Estimation ©️【Deep Blue AI】Compiled
▲Table 3|Zero-shot Depth Estimation ©️【Deep Blue AI】Compiled ▲Table 4|Performance on DA-2K Evaluation Benchmark ©️【Deep Blue AI】Compiled
▲Table 4|Performance on DA-2K Evaluation Benchmark ©️【Deep Blue AI】Compiled
As shown in Table 3, the results outperform MiDaS, slightly lagging behind V1. However, v2 itself is aimed at fine-grained predictions for thin structures and robust predictions for complex scenes and transparent objects. Improvements in these dimensions cannot be accurately reflected in the current benchmark. In DA-2K testing, even the smallest model significantly outperformed other large models based on SD. The proposed largest model achieved 10.6% higher accuracy in relative depth discrimination compared to Margold.
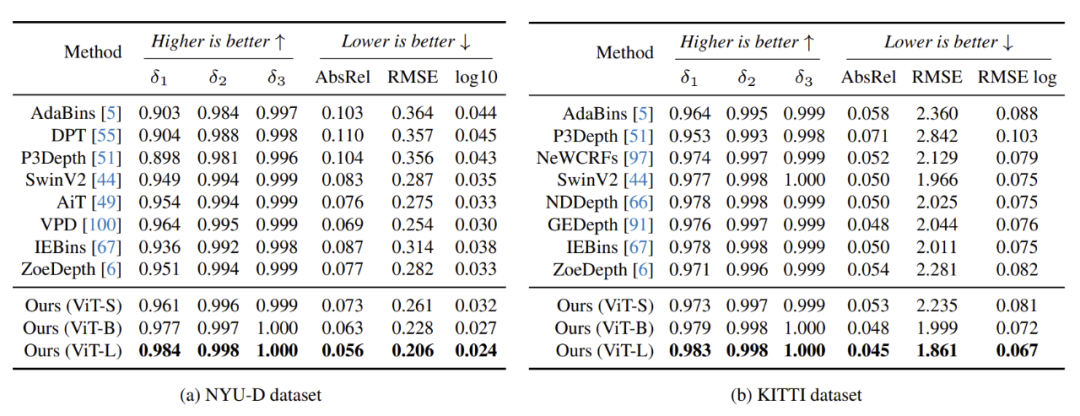 ▲Table 5|Fine-tuning Depth Anything V2 Pre-trained Encoder to Domain Metric Depth Estimation, where Training and Testing Images Share the Same Domain. All Comparison Methods Use Encoder Sizes Close to ViT-L ©️【Deep Blue AI】Compiled
▲Table 5|Fine-tuning Depth Anything V2 Pre-trained Encoder to Domain Metric Depth Estimation, where Training and Testing Images Share the Same Domain. All Comparison Methods Use Encoder Sizes Close to ViT-L ©️【Deep Blue AI】Compiled
As shown in Table 5, transferring the encoder to downstream metric depth estimation tasks achieved significant improvements on both the NYU-D and KITTI datasets, notably even for the lightest ViT-S based model.
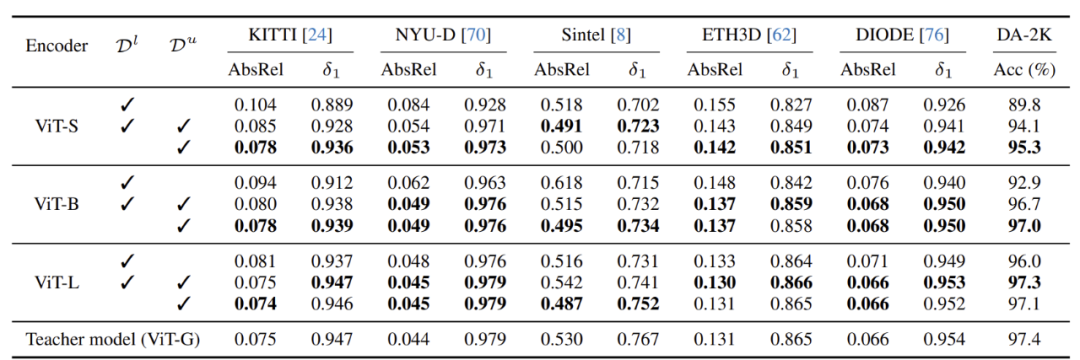 ▲Table 6|Importance of Pseudo-labeled Real Images ©️【Deep Blue AI】Compiled
▲Table 6|Importance of Pseudo-labeled Real Images ©️【Deep Blue AI】Compiled
As shown in Table 6, ablation experiments demonstrate the importance of large-scale pseudo-labeled real images. The model achieved significant enhancement by combining pseudo-labeled real images compared to training with only synthetic images.
In this study, the authors proposed Depth Anything v2, a more powerful monocular depth estimation foundational model. It can:
● Provide robust and fine-grained depth predictions;
●Support a wide range of applications with various model sizes (from 25M to 1.3B parameters);●Be easily fine-tuned to downstream tasks and serve as an effective model initialization.
The research team revealed this key finding, and additionally, considering the weak diversity and strong noise characteristics of the existing test set, the team constructed a versatile evaluation benchmark DA-2K, covering various high-resolution images with accurate and challenging sparse depth labels.


【Deep Blue AI】 aims to provide a platform for professionals in “AI + Intelligent Driving + Robotics” to freely express their thoughts and exchange information. Additionally, we offer cutting-edge technical insights and paper interpretations.
Hereby, we present a “ten-thousand-level” communication community, where not only industry leaders occasionally appear to exchange ideas and clarify doubts but also ultimate content awaits your exploration!
Scan the QR code below to join us and let technology fly💨


