
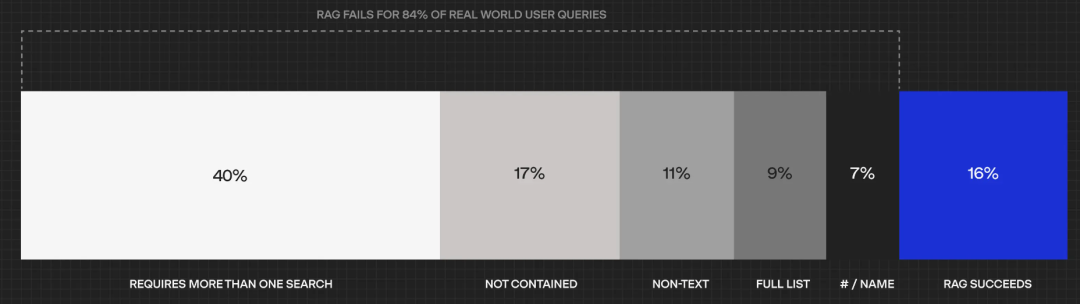
Index Construction
Block Optimization: By using sliding windows, adding metadata, and other methods, the size, structure, and relevance of content blocks can be divided more reasonably.
Multi-level Index: This involves creating two indexes, one consisting of document summaries and the other consisting of document blocks, and searching in two steps: first filtering out relevant documents through summaries, and then searching only within that relevant group.
Knowledge Graph: Extract entities and relationships between entities to build a global information advantage, thus enhancing the accuracy of RAG.
Pre-retrieval
Multi-query: Use prompt engineering to expand queries with large language models, transforming the original query into multiple similar queries and executing them in parallel.
Sub-query: By decomposing and planning complex problems, the original query is broken down into multiple sub-queries, which are then summarized and merged.
Query Transformation: Transform the user’s original query into a new query content before retrieval and generation.
Query Construction: Convert natural language queries into a language that specific machines or software can understand, such as text2SQL or text2Cypher.
Retrieval
Sparse Retriever: Convert queries and documents into sparse vectors using statistical methods. Its advantage is high efficiency when handling large datasets, focusing only on non-zero elements.
Dense Retriever: Provide dense representations for queries and documents using pre-trained language models (PLMs). Although the computational and storage costs are high, it offers more complex semantic representations.
Retriever Fine-tuning: Fine-tune retrieval models based on labeled domain data, usually using contrastive learning to achieve this.
Post-retrieval
Re-ranking: For the retrieved content blocks, use a specialized ranking model to recalculate the relevance scores of the context.
Compression: For the retrieved content blocks, do not input them directly into the large model, but first remove irrelevant content and highlight important context, thereby reducing the overall prompt length and minimizing the interference of redundant information on the large model.
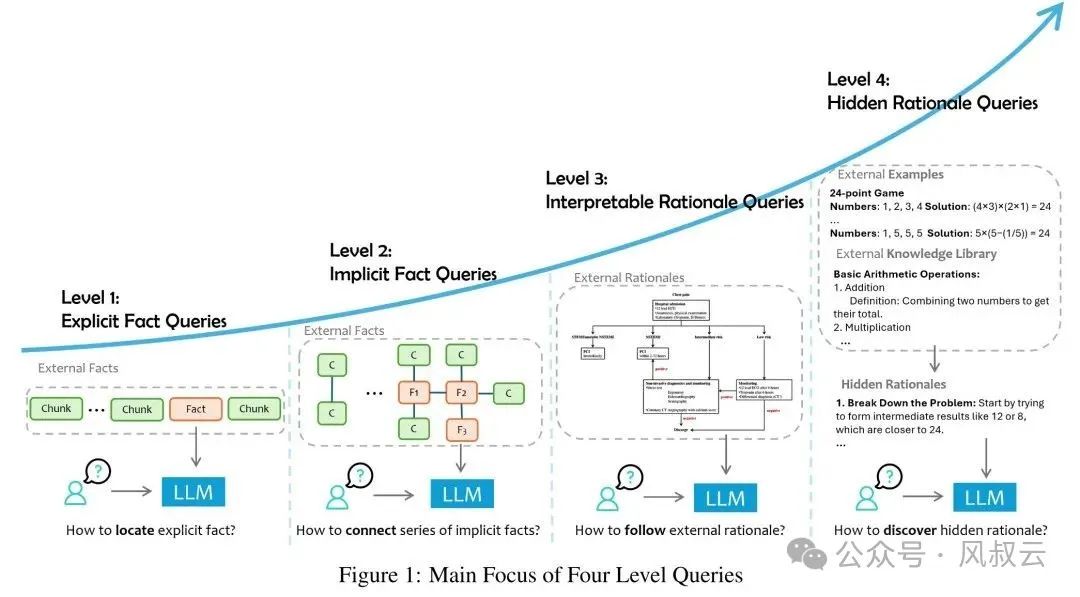
Implicit Fact Queries
Explainable Reasoning
Explainable reasoning refers to problems that cannot be derived from explicit or implicit facts and require comprehensive data for relatively complex reasoning, induction, and summarization, with the reasoning process being business-explainable.
Attribution analysis in ChatBI is a typical example of explainable reasoning. For instance, “What caused the 5% revenue decline in the South China region in the past month?”. This question cannot be answered directly but can be reasoned through certain means, as shown below:
Total Revenue = New Customers * Conversion Rate * Average Transaction Value + Existing Customers * Repurchase Rate * Average Transaction ValueAnalysis shows that the number of new customers, conversion rate, and average transaction value did not change significantly, while the repurchase rate of existing customers declined by about 10%. Therefore, it can be inferred that reasons such as “service quality and competition from rival products” led to the decline in the repurchase rate of existing customers, consequently causing the total revenue to decrease.
Explainable reasoning problems face two main challenges: diverse prompts and limited explainability.
Diverse Prompts: Different query problems require specific business knowledge and decision-making basis. For example, reasoning for revenue decline can use the aforementioned business rules, but if it involves reasoning for the decline in gross margin, a different set of business rules is needed. This diversity in rule sedimentation requires industry experts to organize and convert them into suitable prompts, allowing the large model to understand the underlying logic.
Limited Explainability: The impact of prompts on large models is opaque, making it difficult to assess their influence, thereby hindering the construction of consistent explainability.
In the face of such challenges, I mainly have the following suggestions:
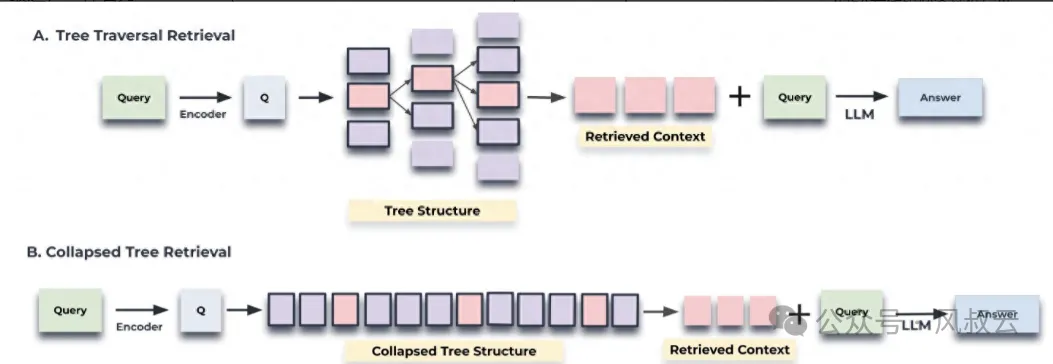
Prompt Engineering Optimization
Optimizing Prompts: It is essential to effectively integrate business reasoning logic into large language models, which tests the industry know-how of prompt designers.
Prompt Fine-tuning: Manually designing prompts can be time-consuming; this issue can be addressed through prompt fine-tuning techniques. For example, using reinforcement learning, the probability of the large model generating correct answers can be used as a reward to guide the model in discovering the best prompt configuration across different datasets.
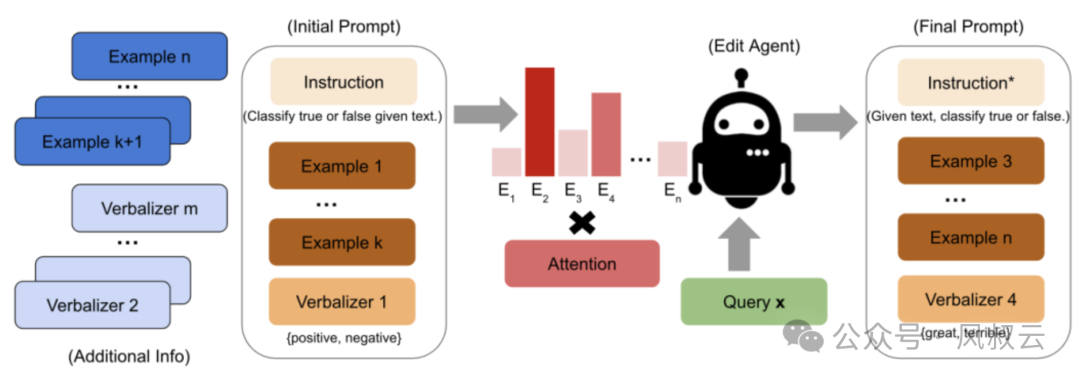
Building Decision Trees
Decision Trees: Transform decision-making processes into state machines, decision trees, or pseudocode for execution by large models. For instance, in equipment maintenance, constructing fault trees is a highly effective fault detection solution.
Using Agentic Workflows
Agentic Workflow: Construct specific steps for the large model’s thinking and actions through workflows, thereby constraining its thought direction. The advantage of this method is that it can provide relatively stable outputs, but the downside is a lack of flexibility, requiring workflows to be designed for each type of problem.
Implicit Reasoning Queries
Implicit reasoning queries refer to those that cannot be judged based on pre-established business rules or decision logic but must be inferred through observation and analysis of external data.
For example, in IT intelligent operations and maintenance, there are no pre-existing comprehensive documents detailing the handling methods and rules for each type of problem. The operations and maintenance team only has records of various fault events and solutions handled in the past. The large model needs to mine the best handling solutions for different faults from this data, which constitutes implicit reasoning queries.
Similarly, scenarios such as intelligent operations and maintenance on production lines and intelligent quantitative trading involve numerous implicit reasoning query issues.
The main challenges of implicit reasoning problems include difficulty in logical extraction, data dispersion, and insufficiency, making them the most complex and challenging issues.
Difficulty in Logical Extraction: Mining implicit logic from vast amounts of data requires developing complex and effective algorithms capable of parsing and identifying the logic hidden behind the data. Therefore, relying solely on superficial semantic similarity is insufficient; dedicated small models need to be built to address this.
Data Dispersion and Insufficiency: Implicit logic is often hidden in very dispersed knowledge, requiring the model to possess strong data mining and comprehensive reasoning capabilities. Moreover, when external data is limited or of insufficient quality, it becomes challenging to extract valuable information from it.
For the challenges faced by implicit reasoning problems, the following solution approaches can be considered:
Machine Learning: Summarize potential rules from historical data and cases using traditional machine learning methods.
Context Learning: Include relevant examples in prompts to reference for the model. However, the drawback of this method is how to enable the large model to master reasoning capabilities beyond its training domain.
Model Fine-tuning: Fine-tune the model using a large amount of business data and case data, internalizing domain knowledge. However, this method can be resource-intensive, so small and medium-sized enterprises should use it cautiously.
Reinforcement Learning: Encourage the model to generate reasoning logic and answers that best align with business realities through a reward mechanism.
Conclusion
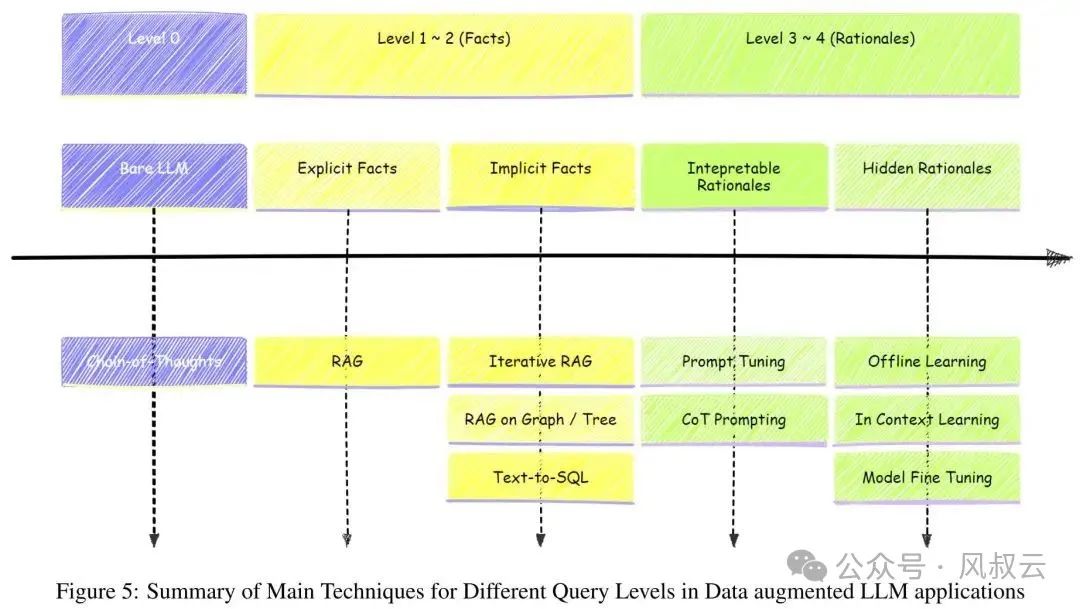
In this article, addressing the issue of RAG being easy to start but difficult to go live, I introduced the four types of user queries and the corresponding problem-solving approaches for each type.
For explicit fact queries and implicit fact queries, various RAG optimization schemes can be employed. However, when facing explainable reasoning and implicit reasoning problems, relying solely on RAG becomes inadequate, necessitating the introduction of methods such as prompt engineering, decision trees, agentic workflows, machine learning, model fine-tuning, and reinforcement learning.
Each of these methods could be elaborated on in a separate series. Therefore, this article merely presents these problem-solving directions without detailed exposition. In the future, I will provide detailed introductions based on practical cases.
This is my last article of 2024, and I wish everyone a Happy New Year, hoping for great prospects in 2025!
More Exciting Articles:
What is AI Agent that the big shots are paying attention to? Analyzing AI Agent using the 5W1H framework (Part 1)
AI Large Model Practical Series: AI Agent Design Pattern – ReAct
RAG Practical Series: Building a Minimum Viable RAG System
In-depth Analysis of Core Application Scenarios of AI Large Models in the Retail Industry
After leaving Tencent after seven years, I officially embark on my entrepreneurial journey in the AI large model field.
I am Feng Shu, an entrepreneur in the AI large model field, former product director at Tencent, with over ten years of product design and commercialization experience, possessing rich practical experience in e-commerce, marketing, AI, and big data products. I will continue to share my summaries and reflections, hoping they will be helpful to you.