In recent years, artificial intelligence has made significant leaps, primarily due to large language models (LLMs). LLMs are very good at understanding and generating human-like text, leading to the creation of various new tools, such as advanced chatbots and AI writers.
Although LLMs excel at generating fluent, human-like text, they sometimes struggle with factual accuracy. This can be a huge problem when accuracy is crucial.
So, what is the solution to this problem? The answer is Retrieval-Augmented Generation (RAG) systems.
RAG integrates the powerful capabilities of models like GPT and adds the ability to retrieve information from external sources, such as proprietary databases, articles, and content. This helps AI generate text that is not only well-written but also more accurate in terms of facts and contextual correctness.
By combining the ability to generate text with the power to find and utilize accurate, relevant information, RAG opens up many new possibilities. It helps bridge the gap between AI that merely writes text and AI that can use actual knowledge.
In this article, we will take a closer look at RAG, how it works, where it is used, and how it might change our future interactions with AI.
Let’s start with a formal definition of RAG:
Retrieval-Augmented Generation (RAG) is an AI framework that enhances LLMs by connecting them with external knowledge bases. This allows access to the latest, accurate information, improving the relevance and factual accuracy of their outputs.
Now, let’s explain it in simple terms for easier understanding.
We have all used AI chatbots like ChatGPT to answer our questions. These are powered by large language models (LLMs) that have been trained and built on vast amounts of internet content/data. They can generate human-like text on almost any topic, making it seem like they can perfectly answer all our questions, but that’s not always the case. Sometimes the information they share may be inaccurate or factually incorrect.
This is where RAG comes into play. Here’s how it works:
2. RAG searches for reliable information in a curated knowledge base.
3. Retrieve relevant information.
4. Pass this information to the LLM.
5. The LLM uses this accurate information to formulate an answer.
The result of this process is a response supported by accurate information.
Let’s understand this with an example: imagine you want to know the baggage allowance for international flights. A traditional LLM like ChatGPT might say, “Typically, you can check one bag weighing up to 50 pounds and have one carry-on. But please check with your airline for specifics.” A RAG-enhanced system would say, “For Airline X, economy class passengers can check one bag weighing 50 pounds and one carry-on weighing 17 pounds. Business class can check two bags weighing 70 pounds each. Be aware of rules regarding special items like sports equipment, and always verify at check-in.”
Do you notice the difference? RAG provides specific, more accurate information regarding actual airline policies. In summary, RAG makes these systems more reliable and trustworthy, which is crucial in developing AI systems that are more applicable to the real world.
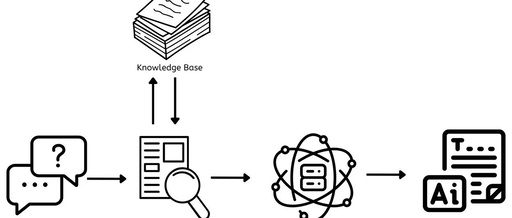
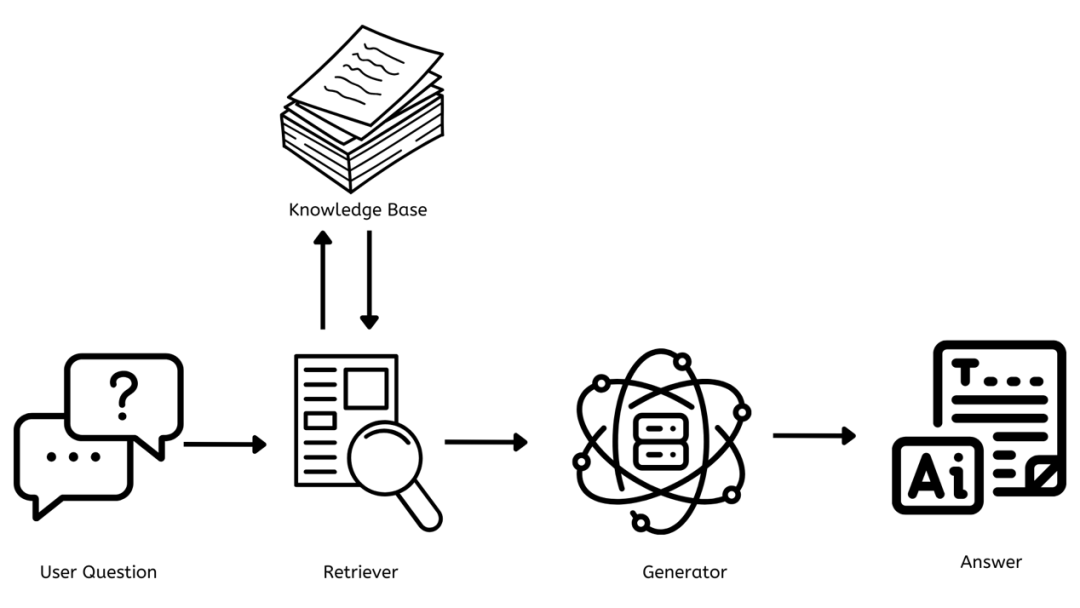
Now that we have a good understanding of RAG, let’s explore how it works. First, let’s start with a simple architecture diagram.
From the architecture diagram above, there are three key components crucial to how RAG works, from the user’s question to the final answer.
Now, let’s understand them one by one.
This is a repository containing all the documents, articles, or data that can be referenced to answer all questions. It needs to be continuously updated with new and relevant information so that responses are accurate and provide users with the most relevant and up-to-date information.
From a technical perspective, this typically uses vector databases like Pinecone, FAISS, etc., to store text as numerical representations (embeddings), allowing for fast and efficient search.
It is responsible for finding documents or data relevant to the user’s question. When a question is posed, the retriever quickly searches the knowledge base to find the most relevant information.
From a technical perspective, this typically uses dense retrieval methods like Dense Passage Retrieval or BM25. These methods convert the user’s question into the type of numerical representation used in the knowledge base and match it with relevant information.
It is responsible for generating coherent content that is relevant and contextually appropriate to the user’s question. It takes the information from the retriever and uses it to construct a response to the question.
From a technical perspective, this is powered by large language models (LLMs) such as GPT-4 or open-source alternatives like LLAMA or BERT. These models are trained on large datasets and can generate human-like text based on the inputs they receive.
Benefits and Applications of RAG
Now that we know what RAG is and how it works, let’s explore some of the benefits it offers and its applications.
-
Access to the Latest Knowledge
Unlike traditional AI models (like ChatGPT) that are limited to training data, RAG systems can access and utilize the most up-to-date information in their knowledge bases.
-
Enhanced Accuracy and Reduced Hallucinations
RAG improves the accuracy of responses by utilizing facts and the latest information from the knowledge base. This greatly reduces the issue of “AI hallucinations”—instances where AI generates more plausible but incorrect information.
-
Customization and Specialization
Companies can build RAG systems tailored to their specific needs, using specialized knowledge bases and creating AI assistants for specific domains.
-
Transparency and Explainability
RAG systems often provide sources for their information, making it easier for users to understand the origins, verify claims, and comprehend the reasoning behind responses.
-
Scalability and Efficiency
RAG allows for efficient use of computational resources. Instead of constantly retraining large models or building new ones, organizations can update their knowledge bases, making it easier to scale and maintain AI systems.
RAG makes customer support chatbots smarter and more helpful. These chatbots can access the latest information in the knowledge base and provide precise and contextual answers.
Companies can create customized AI assistants that utilize their unique and proprietary data. By leveraging internal documents about policies, procedures, and other data, these assistants can quickly and effectively answer employee queries.
Organizations can use RAG to analyze and extract actionable insights from a wide range of customer feedback channels, gaining a comprehensive understanding of customer experiences, sentiments, and needs. This enables them to quickly identify and address key issues, make data-driven decisions, and continuously improve their products based on a complete picture of customer feedback.
RAG has already become a game-changing technology in the field of artificial intelligence, combining the power of large language models with dynamic information retrieval. Many organizations are already leveraging this and building custom solutions for their needs.
Looking ahead, RAG will change the way we interact with information and make decisions. Future RAG systems will:
· Have greater contextual understanding and enhanced personalization;
· Go beyond text and integrate images, audio, and video, becoming multimodal systems;
· Have real-time updates of knowledge bases;
· Seamlessly integrate with various workflows to enhance productivity and collaboration.
In summary, RAG will fundamentally change the way we interact with AI and information. By bridging the gap between AI-generated content and its factual accuracy, RAG will pave the way for intelligent AI systems that are not only more capable but also more accurate and trustworthy. As this technology continues to evolve, our interactions with information will be more efficient and accurate than ever before.
|
High-End WeChat Group Introduction
|
|
|
AI, IOT, chip founders, investors, analysts, brokers
|
|
|
Covering over 5000 global Chinese flash memory and storage chip elites
|
|
|
Discussion on all-flash, software-defined storage SDS, hyper-converged, and public/private cloud
|
|
|
Discussion on AI chips and heterogeneous computing with GPUs, FPGAs, CPUs
|
|
|
Discussion on IoT and 5G chips
|
|
Third Generation Semiconductor Group
|
Discussion on compound semiconductors like GaN, SiC
|
|
|
Discussion on various storage media and controllers like DRAM, NAND, 3D XPoint
|
|
Automotive Electronics Group
|
Discussion on MCUs, power supplies, sensors, etc.
|
|
Optoelectronic Devices Group
|
Discussion on optical communication, lasers, ToF, AR, VCSELs, etc.
|
|
|
Quotations, market trends, channels, supply chain for storage and chip products
|

< Long press to identify the QR code to add friends >
Join the above WeChat groups
Bringing you into the era of information revolution with storage, intelligence, and interconnectivity

WeChat ID: SSDFans