
A critical prerequisite for training large language models is a high-quality, large-scale dataset. To promote the development of the open-source large model ecosystem, Cerebras has released a massive text dataset called SlimPajama, which can serve as a training dataset for large language models and is of very high quality. Cerebras is an American AI chip startup focused on developing large-scale artificial neural network acceleration chips. Previously, they released CerebrasGPT.

In addition to the SlimPajama dataset, Cerebras has also open-sourced scripts for processing the raw data, including deduplication and preprocessing. They believe this is the first open-source tool for cleaning and MinHashLSH deduplication of trillion-scale datasets.
Why Did Cerebras Release the SlimPajama Dataset?
The SlimPajama dataset is derived from the cleaning and deduplication results of RedPajama.
MetaAI has detailed how they collected their dataset in the LLaMA model. The effectiveness of LLaMA also demonstrates the importance of training on high-quality datasets. Although LLaMA has open-sourced their pre-training results (non-commercial), they have not publicly disclosed their training dataset. To address this, TOGETHER, in collaboration with several companies, initiated the RedPajama project.
RedPajama is an open-source large model project initiated by TOGETHER and several companies. It currently includes an open-source dataset containing 1.2 trillion tokens, collected strictly according to the methods described in the LLaMA model paper.
Despite RedPajama’s claims of strictly following the LLaMA paper’s description for data collection, Cerebras found two issues with the dataset: one is that some corpora lacked data files, and the other is that it contained a significant amount of duplicate data. RedPajama employed a non-strict deduplication strategy from LLaMA, without considering deduplication between different corpora.
Duplicate datasets can have many adverse effects on large models, including wasted training time and overfitting.
Therefore, Cerebras decided to take action themselves, further processing the data based on RedPajama to improve the dataset’s quality. Ultimately, they released the SlimPajama dataset.
Overview of the SlimPajama Dataset
The RedPajama dataset released by TOGETHER contains 1.21 trillion tokens. After filtering out duplicate and low-quality datasets, SlimPajama reduced the original RedPajama’s byte size by 49.6%, lowering the 1.21 trillion tokens to 627 billion tokens.
The process of generating the SlimPajama dataset is as follows: first, short and low-quality documents were removed from RedPajama. After removing punctuation, whitespace, line breaks, and tabs, documents shorter than 200 characters were eliminated. Most of these documents only contained metadata and lacked useful information. This strategy was applied to all corpora, but excluded the Books and GitHub datasets, as they found that short texts in these two datasets also had significant value. This step removed 1.86% of the documents from RedPajama, mainly consisting of:
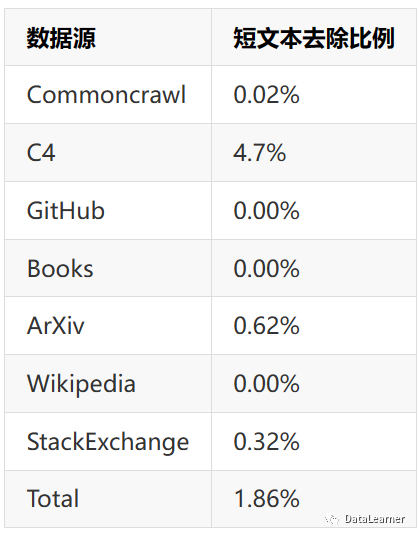
After these steps, Cerebras used the MinHashLSH deduplication tool, which is based on a paper by Leskovec et al. from 2014, to perform deduplication; this tool has also been open-sourced. Finally, the calculated duplication rates for each dataset are as follows:
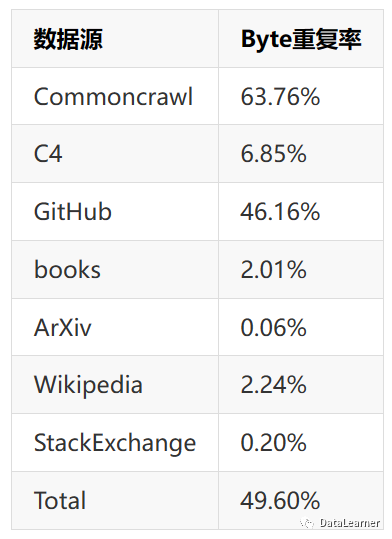
The result was the SlimPajama dataset. This is a high-quality, extensively deduplicated dataset. Based on this dataset, training large models is believed to enhance training efficiency and potentially yield better results than the original models.
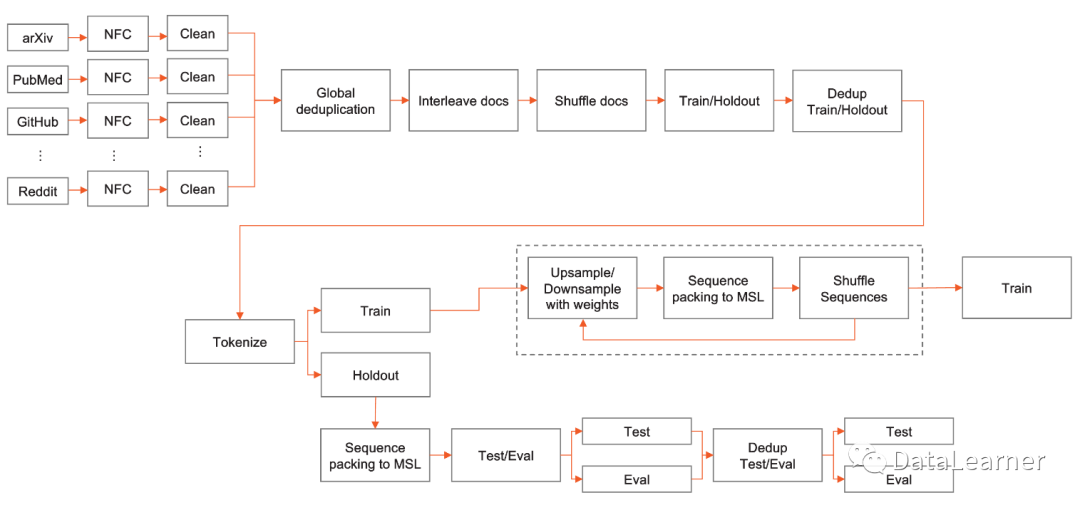
The complete processing flow of the SlimPajama dataset is shown in the image below:
Comparison of the SlimPajama Dataset with Other Datasets
Currently, large language models are trained on large-scale datasets, which typically come from publicly available datasets on the internet, including Wikipedia, GitHub, etc. Most large-scale datasets have similar sources, but the proportions and processing methods differ.
The composition of the SlimPajama dataset compared to other datasets is as follows:
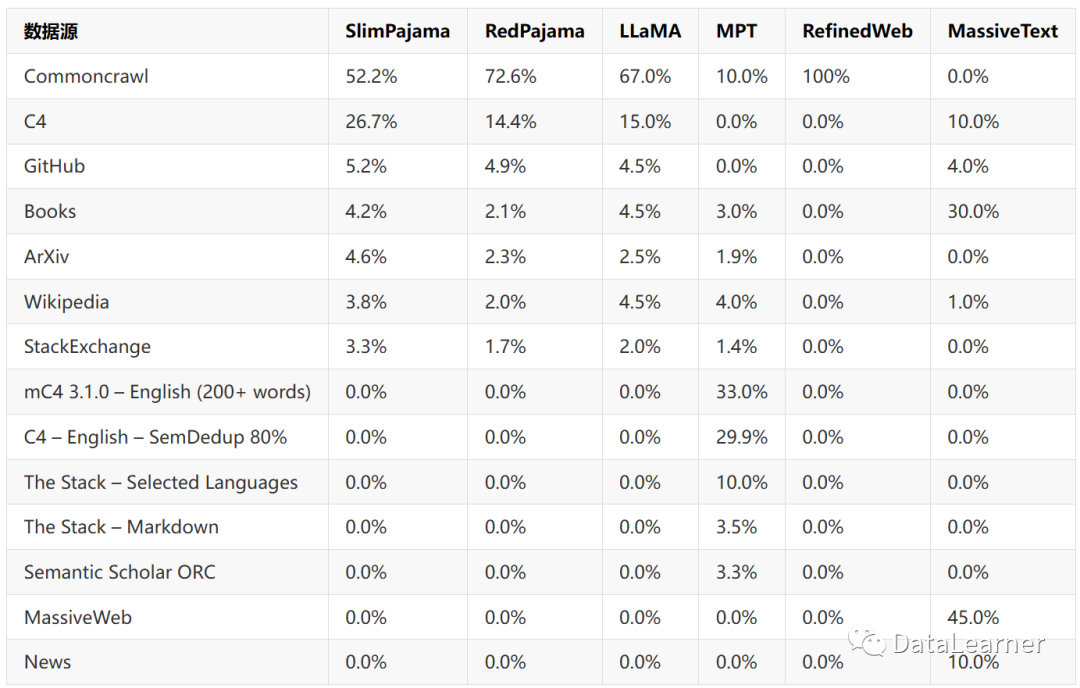
As seen, compared to RedPajama, LLaMA, and RefinedWeb datasets, the SlimPajama dataset is less concentrated, with a lower proportion of web data. The proportions of Books, arXiv, and Wikipedia datasets are higher, with these three being higher-quality datasets.
Additionally, SlimPajama is based on the Apache 2.0 open-source license, which means it is more open and more commercial-friendly. The comparison with other datasets is as follows:
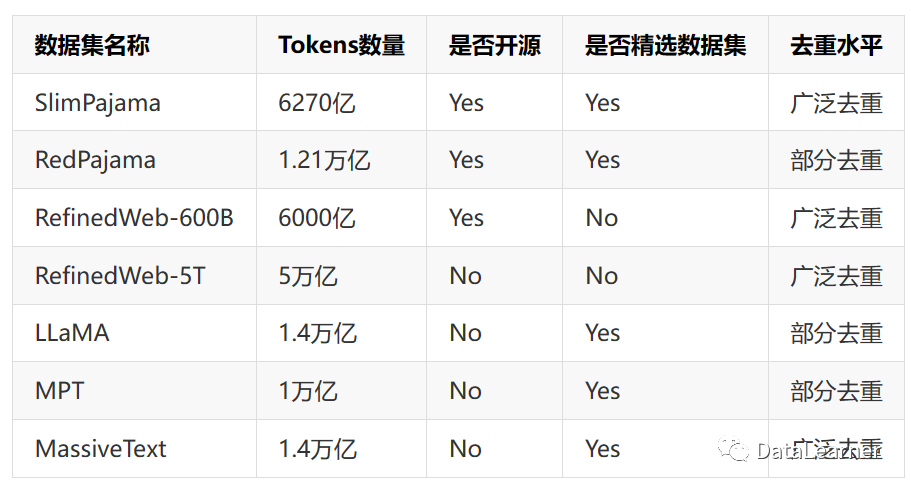
Clearly, in terms of scale, quality, and openness of the license, SlimPajama is the most balanced and best dataset.
Note that the SlimPajama dataset is primarily in English, but also contains some non-English corpora. The specific proportion has not been disclosed by the officials.
Resources Related to SlimPajama and Download Links
The SlimPajama dataset is approximately 895GB in size after compression, containing 59,166 jsonl files.
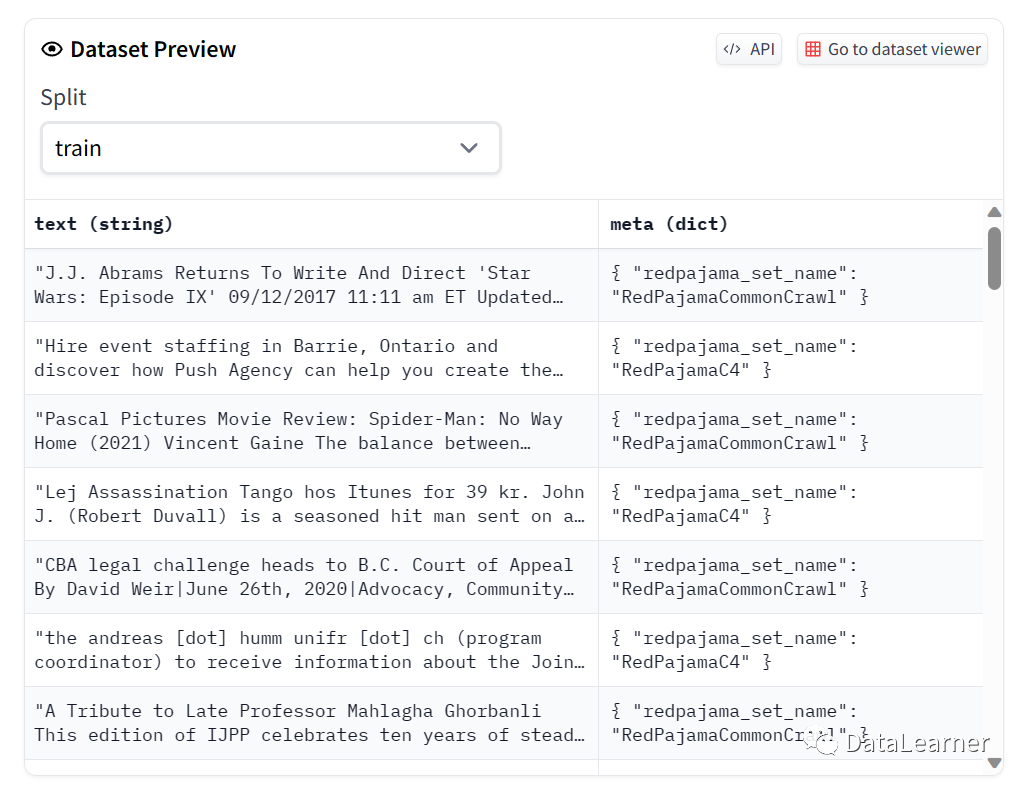
Sample shown below:
Download link for the SlimPajama dataset:https://huggingface.co/datasets/cerebras/SlimPajama-627B/tree/main/trainDownload link for the SlimPajama test dataset:https://huggingface.co/datasets/cerebras/SlimPajama-627B/tree/main/testDownload link for the SlimPajama validation dataset:https://huggingface.co/datasets/cerebras/SlimPajama-627B/tree/main/validationData processing tools for the SlimPajama dataset:https://github.com/Cerebras/modelzoo/tree/main/modelzoo/transformers/data_processing/slimpajamaDataLearner information card for SlimPajama:https://www.datalearner.com/ai-dataset/SlimPajama