
Follow our WeChat public account to discover the beauty of CV technology
This article shares the NeruIPS 2023 paper SegRefiner: Towards Model-Agnostic Segmentation Refinement with Discrete Diffusion Process, which achieves high-precision image segmentation through diffusion.
Details are as follows:

-
Paper link: https://arxiv.org/abs/2312.12425 -
Open-source code: https://github.com/MengyuWang826/SegRefiner
Background Introduction
Although image segmentation has been widely researched and rapidly developed in the past, achieving very accurate segmentation masks with details has always been quite challenging. This is because achieving high-precision segmentation requires both high-level semantic information and fine-grained texture information, leading to significant computational complexity and memory usage.
This challenge is particularly prominent for images with resolutions of 2K or higher. Since directly predicting high-quality segmentation masks is challenging, some studies have begun to focus on refining the coarse masks output by existing segmentation models.
To achieve high-precision image segmentation, researchers from Beijing Jiaotong University, Nanyang Technological University, ByteDance, etc., have introduced a method based on diffusion models to gradually improve mask quality.
Existing Methods
Model-Specific
A common type of refinement method is Model-Specific, which enhances the existing segmentation model’s ability to perceive details by introducing new modules to supplement additional information for mask prediction. Representative works in this category include PointRend, RefineMask, MaskTransfiner, etc. However, these methods are improvements based on specific models and cannot be directly used to refine the coarse masks output by other segmentation models.
Model-Agnostic
Another class of refinement methods is Model-Agnostic, which only uses the original image and coarse masks as input information, such as BPR, SegFix, CascadePSP, CRM, etc. Since these methods do not utilize intermediate features of existing models during the refinement process, they are not dependent on specific segmentation models and can be used for refinement across different segmentation models. However, although these methods can effectively improve segmentation accuracy, the diverse errors present in the coarse masks (as shown below) make it difficult for the model to stably correct all prediction errors in the coarse masks.

Implementation Goals
Compared to Model-Specific methods, Model-Agnostic methods can be directly applied to the refinement of different segmentation models, thus having higher practical value. Furthermore, since the results of different segmentation tasks (semantic segmentation, instance segmentation, etc.) can be represented as a series of binary masks with the same representation form, it is also possible to unify the implementation of refinement for different segmentation tasks within the same model. Therefore, we aim to achieve a general refinement model applicable to different segmentation models and tasks.
As mentioned earlier, the errors produced by existing segmentation models are diverse, and correcting all these diverse errors at once with a single general model is quite challenging. In the face of this problem, the diffusion probabilistic models that have achieved great success in image generation tasks inspire us: the iterative strategy of diffusion probabilistic models allows the model to eliminate only a portion of the noise at each time step and gradually approach the distribution of real images through multiple iterations. This significantly reduces the difficulty of fitting the target data distribution all at once, thus endowing diffusion models with the ability to generate high-quality images. Intuitively, if we transfer the strategy of diffusion probabilistic models to the refinement task, it allows the model to focus on some ‘most obvious errors’ at each step during refinement, which reduces the difficulty of correcting all prediction errors at once and enables the model to gradually approach fine segmentation results through continuous iterations, thus allowing it to handle more challenging instances and continuously correct errors to produce accurate segmentation results.
Under this idea, we propose a new perspective: treating the coarse mask as a noisy version of the ground truth and achieving the refinement of the coarse mask through a denoising diffusion process, thus representing the refinement task as a data generation process conditioned on images with the target being fine masks.
Algorithm Scheme
The diffusion probabilistic model is a generative model represented by forward and backward processes, where the forward process gradually adds Gaussian noise to obtain images with different levels of noise and trains the model to predict the noise; the backward process starts from pure Gaussian noise and iteratively denoises it to ultimately sample an image. When transferring the diffusion probabilistic model to the refinement task, the difference in data form brings about the following two problems:
-
Since natural images are often viewed as high-dimensional Gaussian variables, modeling the image generation process as a series of Gaussian processes is quite natural, so most existing diffusion probabilistic models are established based on Gaussian assumptions; however, our target data is binary masks, and it is unreasonable to fit the distribution of such discrete variables with Gaussian processes. -
As a segmentation refinement method, our core idea is to treat the coarse mask as a noisy ground truth and to restore high-quality segmentation results by eliminating this noise. This means that the end of our diffusion process should converge to a deterministic coarse mask (rather than pure noise), which also differs from existing diffusion probabilistic models.
To address the above issues, we establish a discrete diffusion process based on “random state transition” as shown in the figure below. In the forward process, the ground truth is converted into masks of “different roughness levels” and used for training; the backward process is used for model inference, where SegRefiner starts from the given coarse mask and iteratively corrects the error prediction areas in the coarse mask. The following will detail the forward and backward processes.
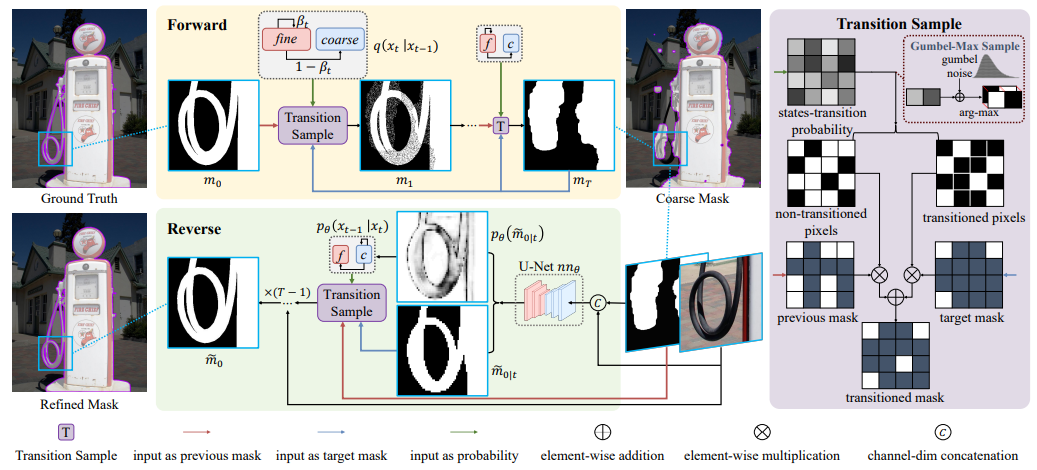
Forward Process
The goal of the forward process is to gradually dissolve the fine mask provided by the ground truth into a coarse mask. Let the variable at each step of the forward process be denoted as , then the forward process should satisfy:
-
is the ground truth -
is the coarse mask -
is between and , gradually evolving towards the coarse mask as t increases
Based on these constraints, we express the forward process using random state transitions: assuming each pixel in the variable has two possible states: fine and coarse, the pixel value in the fine state remains consistent, while the pixel in the coarse state takes the value (even if both are consistent).
We propose a “transition sampling” module to carry out this process, as shown on the right side of the above figure. At each time step, it takes the current mask, coarse mask, and state transition probability as input. In the forward process, the state transition probability describes the probability of each pixel in the current mask transitioning to the state in .
Sampling based on state transition probabilities can yield the states of each pixel at the next time step, thereby determining their values. This module establishes a “one-way” process, meaning that only “transitions to the target state” will occur. This one-way nature ensures that the forward process will converge to (even though each step is completely random), thus satisfying the above constraints (2) and (3).
Through the reparameterization trick, we introduce a binary random variable to describe the above process: we represent as a one-hot vector to indicate the states of pixels in the intermediate mask while setting and to represent the fine and coarse states, respectively. Thus, the forward process can be expressed as:
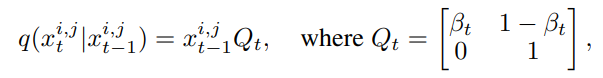
Where is a hyperparameter, and corresponds to the state transition probability mentioned above, which is the state transition matrix. The marginal distribution of the forward process can be expressed as:
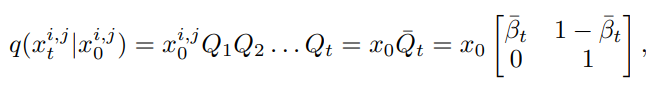
Thus, we can directly obtain the mask at any intermediate time step and use it for training without the need for step-by-step sampling.
Backward Process
The backward diffusion process is used for model inference, aiming to gradually correct the coarse mask into a fine mask. Since the fine mask and state transition probabilities are unknown at this point, similar to DDPM, we train a neural network to predict the fine mask, expressed as:
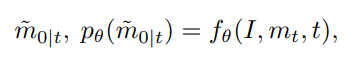
Where is the corresponding image. and represent the predicted fine mask and its confidence score, respectively. Here, indicates the network’s confidence in the accuracy of the prediction, hence it can also be viewed as the probability of each pixel being in the “fine state”. To obtain the backward state transition probabilities, based on the settings of the forward process and Bayes’ theorem, continuing the DDPM approach, we can derive the probability distribution of the backward process from the posterior probability of the forward process and the predicted as:
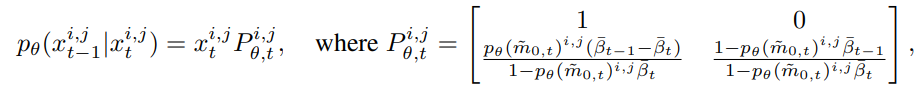
Where is the state transition probability of the backward process. Given the coarse mask and the corresponding image, we first initialize all pixels to the coarse state, and then gradually correct the predicted values through continuous iterations of state transitions. The following figure visualizes an inference process.
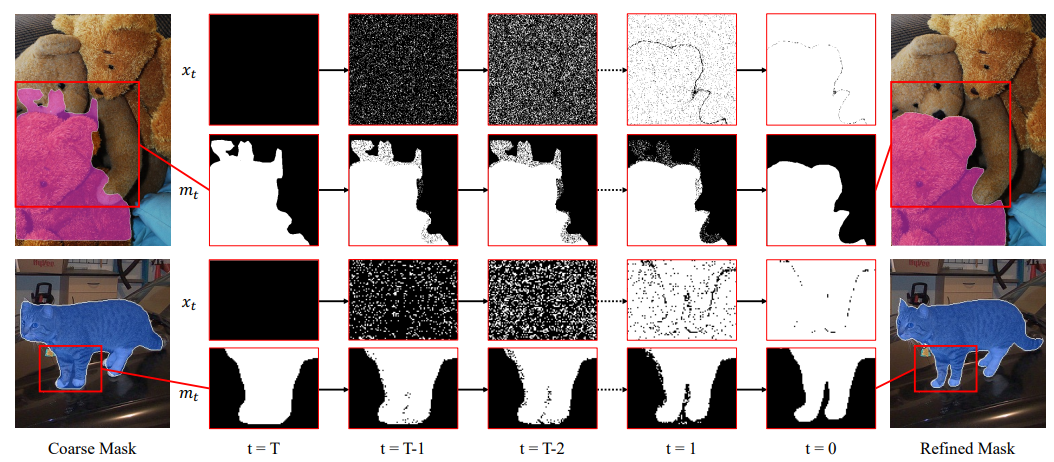
Model Structure
Any network satisfying the form can meet our requirements. Here, we follow the approach of previous works and use U-Net as our denoising network, modifying its input channel number to 4 (concatenating the image and in the channel dimension) and outputting a 1-channel improved mask.
Algorithm Evaluation
Since the core of the refinement task is to obtain detail-accurate segmentation results, we selected three representative high-quality segmentation datasets for experimentation, corresponding to Semantic Segmentation, Instance Segmentation, and Dichotomous Image Segmentation.
Semantic Segmentation
As shown in Table 1, we compared the proposed SegRefiner with four existing methods: SegFix, CascadePSP, CRM, and MGMatting on the BIG dataset. Among these, the first three are refinement methods for semantic segmentation, while MGMatting uses images and masks for matting tasks and can also be used for refinement tasks. The results indicate that our proposed SegRefiner significantly improved IoU and mBA metrics when refining the coarse masks of four different semantic segmentation models, surpassing previous methods.

Instance Segmentation
In instance segmentation, we chose the widely used COCO dataset for testing and used the annotations from the LVIS dataset. Compared to the original COCO annotations, the LVIS annotations provide higher quality and more detailed structures, making them more suitable for evaluating the performance of improved models.
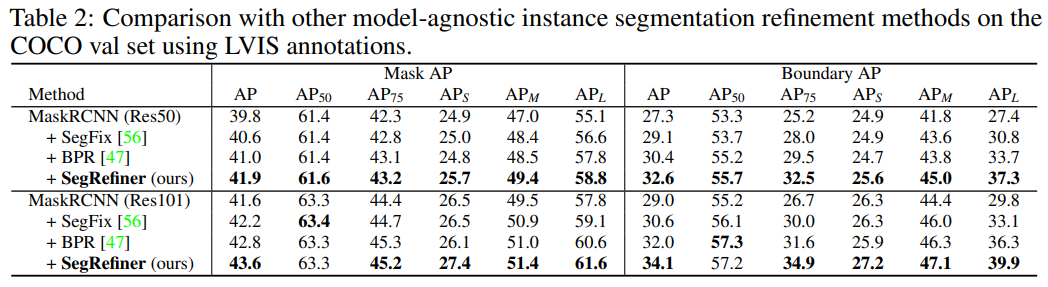
First, in Table 2, we compared the proposed SegRefiner with two model-agnostic instance segmentation refinement methods, BPR and SegFix. The results show that our SegRefiner significantly outperformed these two methods.
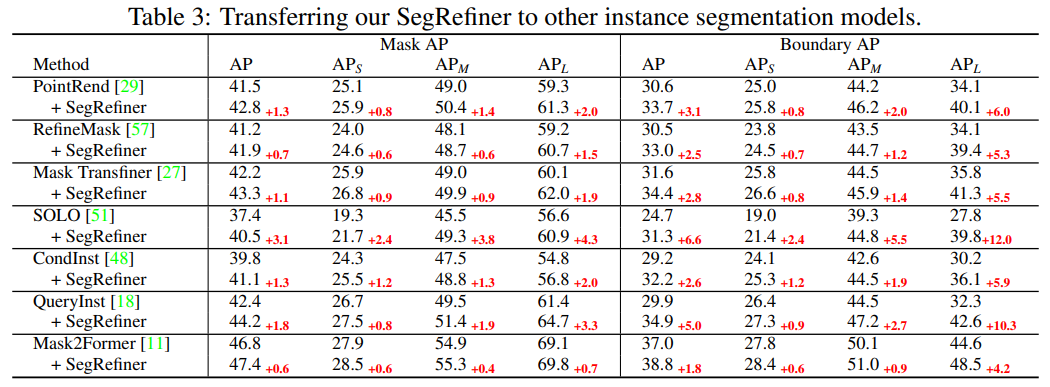
Then in Table 3, we applied SegRefiner to seven other instance segmentation models. Our method achieved significant enhancement effects across models with different accuracy levels. Notably, when applied to three model-specific instance segmentation refinement models (including PointRend, RefineMask, and Mask TransFiner), SegRefiner still consistently improved their performance, indicating that SegRefiner possesses a stronger detail perception capability.
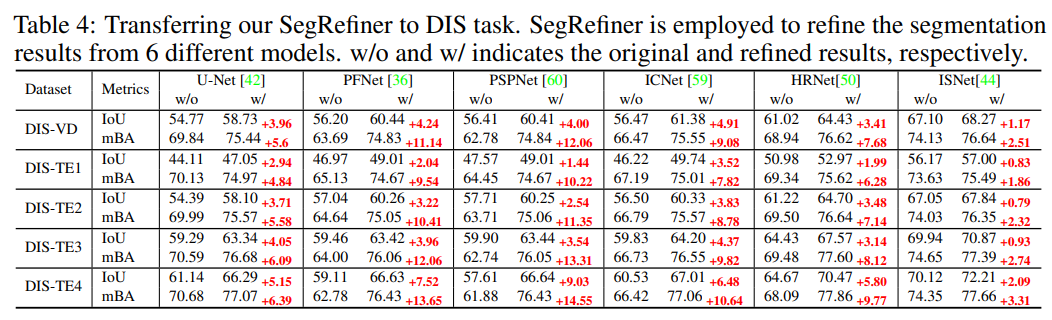
Dichotomous Image Segmentation
Dichotomous Image Segmentation is a relatively newly proposed task, as shown in the figure below, with datasets containing a large number of objects with complex detailed structures, making it very suitable for evaluating our SegRefiner’s detail perception ability.

In this experiment, we applied SegRefiner to six segmentation models, and the results are shown in Table 4. It can be seen that our SegRefiner significantly improved the accuracy of each segmentation model in both IoU and mBA metrics.
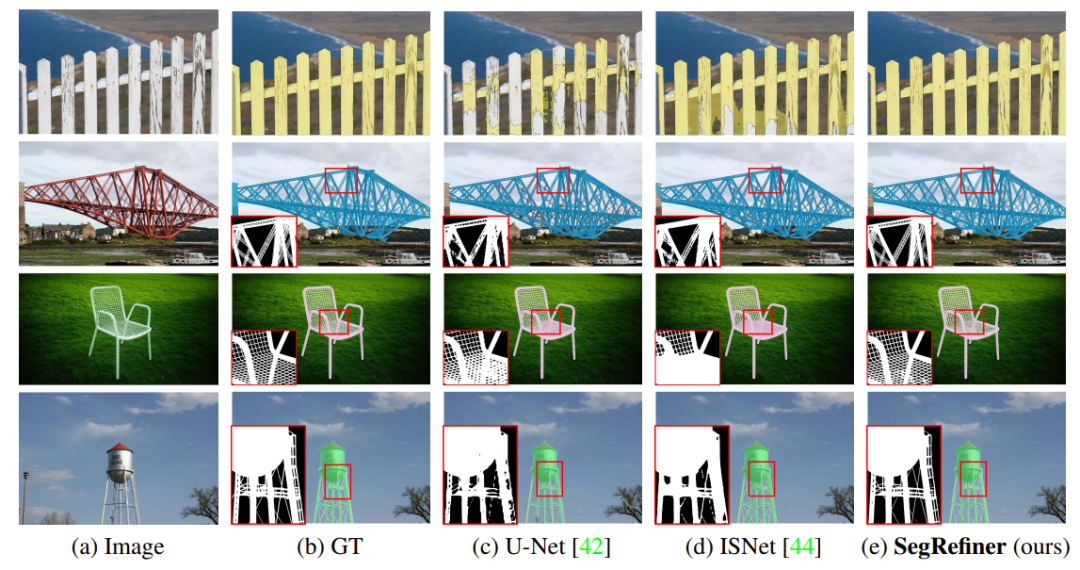
Visualization Display

END
Welcome to join the “Image Segmentation“ group 👇 Please note:Seg
