MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and corporate researchers.The Vision of the Community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners.Reprinted from | ZhihuAuthor | GlanThe following hot terms are not limited to the year 2024, nor do they encompass all of 2024. Let’s see if there are any you are familiar with.[ MoE, Agent/Agentic, Sora, GraphRAG, GPT-4o, o1, ORM, PRM, test-time compute, Inference Scaling Laws, MCTS, Self-Play, Self-Rewarding, RFT, PPO, DPO, GRPO ……]
Di Xia Jia: The “Chinese” field takes the most common Chinese name; if there isn’t one, it’s a hard translation; the “Related” field refers to similar terms, not necessarily all; the “Source” is taken from what can be found on the internet, which may not be accurate; the “Hu Kan” field is just for fun, one person’s opinion;
Feel free to share your opinions in the comments section, let’s begin.
MoE
Full Name: Mixture-of-ExpertsChinese: 混合专家(模型)Source: The concept was first proposed by Hinton in 1991 in the paper “Adaptive Mixtures of Local Experts” [1], and it gained popularity after the release of GPT-4 in March 2023, as hackers speculated that it used the MoE architecture. In December 2023, Mistral AI released the first open-source MoE architecture model Mixtral-8x7B [2], followed by DeepSeek releasing the first domestic open-source MoE architecture model DeepSeekMoE in January 2024 [3].Hu Kan: In 2024, models started with DeepSeekMoE, thinking that the MoE architecture would shine in 2024, but it was interrupted by o1. However, by the end of the year, DeepSeek-V3 [4] somewhat restored MoE’s reputation. But V3 is so large; its download count has reached 155K [5] so far. Is everyone so wealthy now?
Agentic
Chinese: 智能体化Source: To discuss Agentic, one must first mention Agent, a term that has been around for a long time. However, in the LLM field, it was first comprehensively defined in a June 2023 blog by OpenAI titled “LLM Powered Autonomous Agents” [6]. Later, in December 2023, OpenAI’s report “Practices for Governing Agentic AI Systems” [7] mentioned the term Agentic.Hu Kan: In 2024, applications starting with Agent/Agentic were expected to flourish, but by the end of 2024, the impact was minimal. However, Anthropic’s report at the end of 2024, “Building effective agents” [8], was quite realistic. Currently, most agents are essentially Workflow + Prompt, but the story still needs to be told using the term “Agent”.
Sora
Source: In February 2024, OpenAI released a video generation model.Related: In June 2024 Kuaishou Keling, July Zhiyu Qingying, August MiniMax video-01, September ByteDance PixelDance and Seaweed.Hu Kan: At the end of 2024, I finally can pay to experience Sora, but after the experience, I found it quite different from what was touted at the beginning of the year!
GraphRAG
Chinese: 图检索增强生成Source: In April 2024, Microsoft proposed this in “From Local to Global: A Graph RAG Approach to Query-Focused Summarization” [9].Related: The concept of RAG was first proposed by Meta in 2020 in “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” [10]. Currently, various RAG implementations are emerging, which will not be discussed here.Hu Kan: Currently, RAG has become a paradigm for addressing issues such as poor knowledge timeliness, hallucinations, and lack of domain expertise in LLMs. The RAG direction remains hot in 2024, as it can be realistically applied. But is the Graph approach the correct way to unlock RAG?
GPT-4o
Source: In May 2024, OpenAI released a multimodal model.Related: In July 2024, Step-1.5V, September Meta Llama 3.2, September Mistral AI Pixtral 12B, October Alibaba Qwen2-VL, October Baichuan Omni.Hu Kan: 4o is multimodal end-to-end, but looking at 2024, multimodal still has a long way to go. The future AGI will certainly be multimodal, but the current AGI is still text-based.
o1
Source: In September 2024, OpenAI released an inference model.Related: In November 2024, Alibaba QwQ-32B-Preview, November DeepSeek-R1-Lite, November Yuean k0-math, December Zhiyu GLM-Zero-Preview.Hu Kan: 2024 is truly a divine year!
Next are the hot terms related to o1, as everyone has been researching o1 in the second half of the year
ORM; PRM
Full Name: Outcome-supervised Reward Model; Process-supervised Reward ModelChinese: 结果监督奖励模型;过程监督奖励模型Source: As early as May 2023, OpenAI proposed this in “Let’s Verify Step by Step” [11].Hu Kan: After the emergence of o1, everyone has been decrypting it. PRM should be one of its core methods, and people have started training PRM. However, OpenAI has 800K labeled data. Although it is open-source, how much is not open-source?
train-time compute; test-time compute
Chinese: 训练时计算量;测试时计算量Source: In September 2024, OpenAI mentioned this in the blog “Learning to reason with LLMs” [12].Hu Kan: Looking at the original text,We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute)Time spent truly strengthens performance.
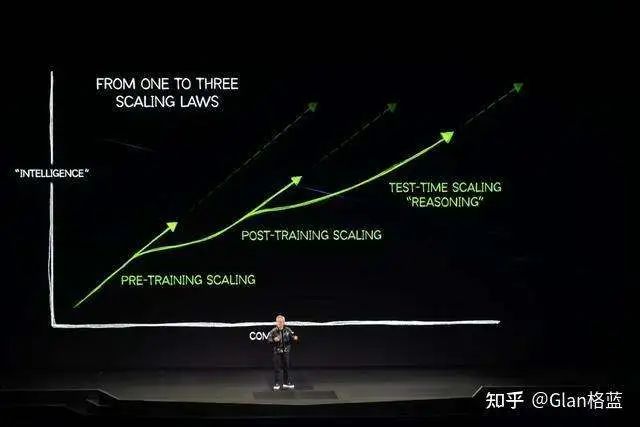
Inference Scaling Laws/Test-Time Scaling
Chinese: 推理扩展定律Source: After the release of o1, the inference version of Scaling Laws emerged. The exact source is unclear, but this paper performed well: “Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for LLM Problem-Solving” [13].Hu Kan: Opening a new phase, this diagram by Lao Huang is quite good.Three Phases
MCTS
Full Name: Monte Carlo Tree SearchChinese: 蒙特卡洛树搜索Source: First proposed in 2006 in “Bandit based Monte – Carlo Planning” [14].Hu Kan: Is o1 really useful?
Speculated o1 reasoning paradigm: SA, MR, DC, SR, CI, EC
Source: A paper speculating on the o1 reasoning paradigm, “A Comparative Study on Reasoning Patterns of OpenAI’s O1 Model” [15].Hu Kan: You close yours, and I’ll study mine.
Next are several “self” terms
Self-Play
Chinese: 自博弈Source: The first heat was after the 2016 AlphaGo battle against Lee Sedol; this time, it became popular again with o1. Self-Play is a concept in traditional RL, and in August 2024, this review was quite good: “A Survey on Self-play Methods in Reinforcement Learning” [16].Hu Kan: Those from NLP who are working on LLMs should embrace traditional RL.
Self-Rewarding
Chinese: 自我奖励Source: In January 2024, Meta mentioned this in “Self-Rewarding Language Models” [17].Hu Kan: It means no need for humans to label data, letting LLM act as a judge, but it feels like a long road ahead.
Self-Correct/Correction
Chinese: 自我纠错Source: This concept emerged after the appearance of LLMs, and in September 2024, DeepMind mentioned it in “Training Language Models to Self-Correct via Reinforcement Learning” [18].Hu Kan: Eight days after the release of o1, DeepMind released this paper, but it seems to have received little attention.
Self-Refine
Chinese: 自我优化Source: Generally refers to a paper from Carnegie Mellon University in March 2023 titled “Self-refine: Iterative refinement with self-feedback” [19].Hu Kan: It has become a baseline in many papers.
Self-Reflection
Chinese: 自我反思Source: This has been mentioned quite a lot, here are a few good papers:“Self-Reflection in LLM Agents: Effects on Problem-Solving Performance” [20];“Self-RAG: Learning to Retrieve, Generate and Critique through Self-Reflection” [21];“Towards Mitigating Hallucination in Large Language Models via Self-Reflection” [22];Hu Kan: What is human reflection, and what is LLM reflection?
Self-Consistency
Chinese: 自我一致性Source: Generally refers to a paper from Google in 2023 titled “Self-Consistency Improves Chain of Thought Reasoning in Language Models” [23].Hu Kan: Looking forward to more practical “self” terms, as humans prefer low-energy tasks and do not like to do things themselves (like data cleaning).
RFT
Full Name: Reinforcement Fine-TuningChinese: 强化微调Source: Proposed during OpenAI’s 12 Days live stream on the second day; this is the video of the live stream [24], and this is the application form [25].Note the difference from ByteDance’s ReFT (so is there really a difference?), OpenAI’s official abbreviation is RFT.
Today, we’re excited to introduce a new way of model customization for our O1 series: reinforcement fine-tuning, or RFT for short.
ReFT
Full Name: Reinforced Fine-TuningChinese: 强化微调Source: In January 2024, ByteDance proposed this in “ReFT: Reasoning with Reinforced Fine-Tuning” [26].Hu Kan: From the information currently disclosed by OpenAI, the principles should not differ significantly from ByteDance’s ReFT. However, OpenAI’s concept is divine, PPO~RFT, Reward Model ~ Verifier. But in specialized fields where answers are fixed and Verifiers can also be well-defined tasks, if “dozens of data” can be very effective, it’s quite exciting. Let’s not wait until the end of 2025 to experience it like Sora…
Next are several “O” terms
PPO
Full Name: Proximal Policy OptimizationChinese: 近端策略优化Source: Proposed by OpenAI in 2017 in “Proximal Policy Optimization Algorithms” [27].Hu Kan: The ancestor of the following O terms.
DPO
Full Name: Direct Preference OptimizationChinese: 直接偏好优化Source: Proposed by Stanford in 2023 in “Direct Preference Optimization: Your Language Model is Secretly a Reward Model” [28].Hu Kan: Your emergence has delighted small workshops!
GRPO
Full Name: Group Relative Policy OptimizationSource: Proposed by DeepSeek in February 2024 in “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models” [29].Hu Kan: Elegant, practical, and efficient.
Some common “O” terms that have already been implemented
ORPO
Full Name: Odds Ratio Preference OptimizationSource: Proposed by KAIST AI in March 2024 in “ORPO: Monolithic Preference Optimization without Reference Model” [30].
KTO
Full Name: Kahneman-Tversky OptimizationSource: Proposed in February 2024 in “KTO: Model Alignment as Prospect Theoretic Optimization” [31].
SimPO
Full Name: Simple Preference OptimizationSource: Proposed in May 2024 in “SimPO: Simple Preference Optimization with a Reference-Free Reward” [32].
RLOO
Full Name: Reinforce Leave-One-OutSource: Proposed by Cohere For AI in February 2024 in “Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs” [3].As 2024 ends, what waves will GPT-5 and o3 bring in 2025? The bigger the waves, the more expensive the fish!References
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)to apply to join the Natural Language Processing/Pytorch and other technical groups
About Us
MLNLP Community is a civil academic community jointly constructed by domestic and international scholars in machine learning and natural language processing. It has developed into a well-known machine learning and natural language processing community, aiming to promote progress between the academic and industrial sectors of machine learning and natural language processing.The community can provide an open communication platform for related practitioners’ further education, employment, and research. Everyone is welcome to follow and join us.