

About 3800 words, recommended reading time is 7 minutes.
This article provides a comprehensive overview of MM-LLMs.
1. Introduction
Multimodal large language models (MM-LLMs) have made significant progress over the past year by optimizing modality alignment and human intent alignment, enhancing existing unimodal foundational models (LLMs) to support various MM tasks. This article provides a comprehensive overview of MM-LLMs, including an overview of model architecture and training processes, as well as a classification system for the latest advancements in 122 MM-LLMs.This article also discusses the role of output projectors in machine translation, and explores the pattern generators, training pipelines, SOTAMM-LLM, and future directions. MM-LLMs demonstrate high performance, with future development directions including expanding model modalities, diversifying LLMs, improving MM generation capabilities, and developing more challenging benchmarks. The article thoroughly examines the latest advancements in modern machine learning models MM-LLMs, focusing on challenges in fine-tuning and hallucination mitigation, and offers some suggestions. The timeline of MM-LLMs is shown in Figure 1.

2. Model Architecture
This section outlines the five components that make up a general model architecture, as shown in Figure 2, including modality encoders, LLM backbone, pattern generators, and input-output projectors. MM-LLM only includes the first three components; during training, the modality encoder, LLM backbone, and pattern generator are usually kept frozen, with the main optimization focus on the input and output projectors. The proportion of trainable parameters in MM-LLM is significantly smaller compared to the total number of parameters, usually around 2%. The total number of parameters depends on the scale of the core LLM used within the MM-LLM. Therefore, MM-LLM can be efficiently trained to support various MM tasks.
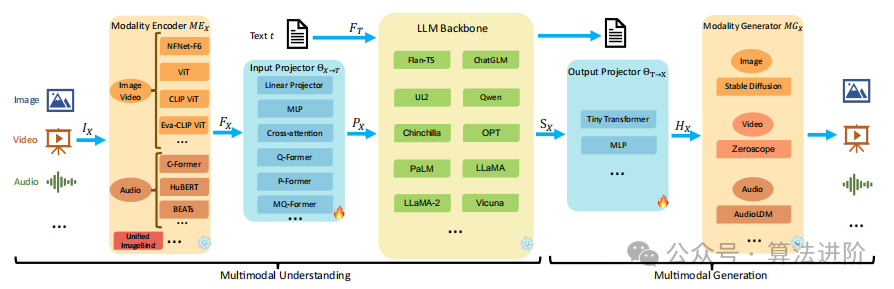 Figure 2 General model architecture of MM-LLMs and implementation choices for each component.
Figure 2 General model architecture of MM-LLMs and implementation choices for each component.2.1 Modality Encoder
The modality encoder (ME) encodes inputs IX from different modalities into corresponding features FX.
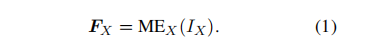
For different modalities, there are various pre-trained encoder options MEX, where X can be image, video, audio, 3D, etc. For images, there are multiple optional encoders such as NFNet-F6, ViT, CLIP ViT, Eva-CLIP ViT, BEiT-3, OpenCLIP, Grounding-DINOT, Swin-T, DINOv2, SAM-HQ, MAE, RAM++, Swin-B, InternViT, and VCoder. For videos, it can be uniformly sampled into 5 frames and preprocessed similarly to images. Audio modalities typically use CFormer, HuBERT, BEATs, Whisper, and CLAP for encoding. 3D point cloud modalities typically use ULIP-2 and PointBERT as backends for encoding. Additionally, to handle numerous heterogeneous modality encoders, some MM-LLMs, particularly those using arbitrary-to-arbitrary type encoders, utilize ImageBind, a unified encoder covering six modalities including images/videos, text, audio, heatmaps, inertial measurement units, and depth.
2.2 Input Projector
The input projector ΘX→T aligns the encoded features FX of other modalities with the text feature space T, generating prompts PX that are input together with text features FT into the LLM backbone. The goal is to minimize the text generation loss Ltxt-gen under X conditions.
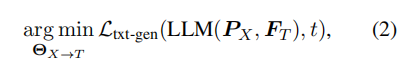
Where PX=ΘX→T(FX).
The input projector can be implemented via linear projectors or MLPs, or more complex implementations like cross-attention (Perceiver Resampler). Q-Former extracts features from FX as prompts PX, P-Former generates “reference prompts” for alignment constraints, and MQ-Former performs multi-scale signal alignment. However, these methods require additional PT process initialization.
2.3 LLM Backbone
MM-LLM acts as the core agent with LLM, inheriting significant attributes such as zero-shot generalization, few-shot ICL, chain of thought, and instruction following. The LLM backbone handles representations of various modalities, participating in semantic understanding, reasoning, and input decision-making. It generates direct text outputs t and signal tokens SX of other modalities. These signal tokens serve as instructions to guide the generator on whether to generate MM content, and if so, specify what content to generate.
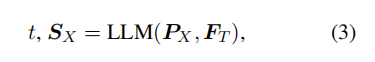
Representations of other modalities PX can be regarded as soft prompt fine-tuning for the LLM. Some works have introduced parameter-efficient fine-tuning (PEFT) methods such as prefix tuning, LoRA, and layer normalization fine-tuning. Commonly used LLMs in MM-LLM include Flan-T5, ChatGLM, UL2, Persimmon, Qwen, Chinchilla, OPT, PaLM, LLAMA, LLAMA-2, and Vicuna.
2.4 Output Projector
The output projector ΘT→X maps signal tokens SX in the LLM backbone to features HX that can be understood by the pattern generator MGX. For the X text dataset {IX, t}, after generating SX, the LLM maps it to HX. The goal is to minimize the distance between HX and MGX text representation to facilitate alignment between the two.
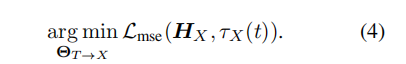
Optimization relies solely on subtitle text, without utilizing other resources. HX is obtained from ΘT→X(SX), τX is the text encoder of MGX. The output projector is implemented via a learnable decoder or MLP.
2.5 Pattern Generator
The pattern generator MGX generates outputs of various modalities. Current works often use latent diffusion models (LDMs), such as stable diffusion for image synthesis, zero-shot for video synthesis, and AudioLDM-2 for audio synthesis. The output projector uses features HX as conditional input for noise reduction during the MM content generation process. During training, real content is first converted to latent features z0, then noise is added to obtain zt. The pre-trained Unet is used to compute the conditional LDM loss LX-gen.
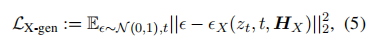
Optimize parameters ΘX→T and ΘT→X to minimize LX-gen.
3. Training Pipeline
The training process of MM-LLMs can be divided into two main phases: MM PT and MM IT.
3.1 MM PT
In the PT phase, the XText dataset is widely used to train the model. During training, the input and output projectors are optimized to ensure accurate alignment across various modalities. The MM understanding model mainly optimizes formula (2), while the MM generation model involves formulas (2), (4), and (5). The XText dataset includes various text data such as image-text, video-text, and audio-text, where image-text is further divided into image-text pairs and interleaved image-text corpora. For details, see Appendix G Table 3.
3.2 MM IT
MM IT is a method that improves zero-shot performance by fine-tuning pre-trained MM-LLMs using instruction-formatted data. MM IT includes supervised fine-tuning (SFT) and human feedback-driven reinforcement learning (RLHF), aimed at enhancing the interactive capabilities of MM-LLMs. SFT converts part of the data from the PT phase into instruction-aware format, fine-tuning the pre-trained MM-LLMs using the same optimization objectives. The SFT dataset can be structured as single-turn QA or multi-turn dialogues. After SFT, RLHF involves further fine-tuning the model, relying on feedback regarding the responses of MM-LLMs (e.g., natural language feedback (NLF) manually or automatically labeled). This process uses reinforcement learning algorithms to effectively integrate non-differentiable NLF. The model is trained based on NLF to generate corresponding responses.
4. SOTA MM-LLM
Figure 3 shows our classification of the functionalities and designs of 122 SOTA MM-LLMs. The design aspects are divided into “tool usage” and “end-to-end” approaches. We compared the architecture and training dataset scale of 43 of these models, as shown in Table 1. Development trends include transitioning from MM understanding to arbitrary modality conversion, improving training pipelines to better align with human intent, accepting diverse extended modalities, incorporating higher quality training datasets, and adopting more efficient model architectures.
Current trends in MM-LLM:
-
Transition from MM understanding to arbitrary modality conversion.
-
Continuous improvement of training pipelines, aligning with human intent, enhancing conversational interaction capabilities.
-
Acceptance of diverse extended modalities.
-
Incorporation of higher quality training datasets.
-
Adoption of more efficient model architectures.
 Figure 3 Classification of MM-LLMs. I: Image, V: Video, A/S: Audio/Speech, T: Text. ID: Document Understanding, IB: Output Bounding Box, IM: Output Segmentation Mask, IR: Output Retrieval Image.
Figure 3 Classification of MM-LLMs. I: Image, V: Video, A/S: Audio/Speech, T: Text. ID: Document Understanding, IB: Output Bounding Box, IM: Output Segmentation Mask, IR: Output Retrieval Image.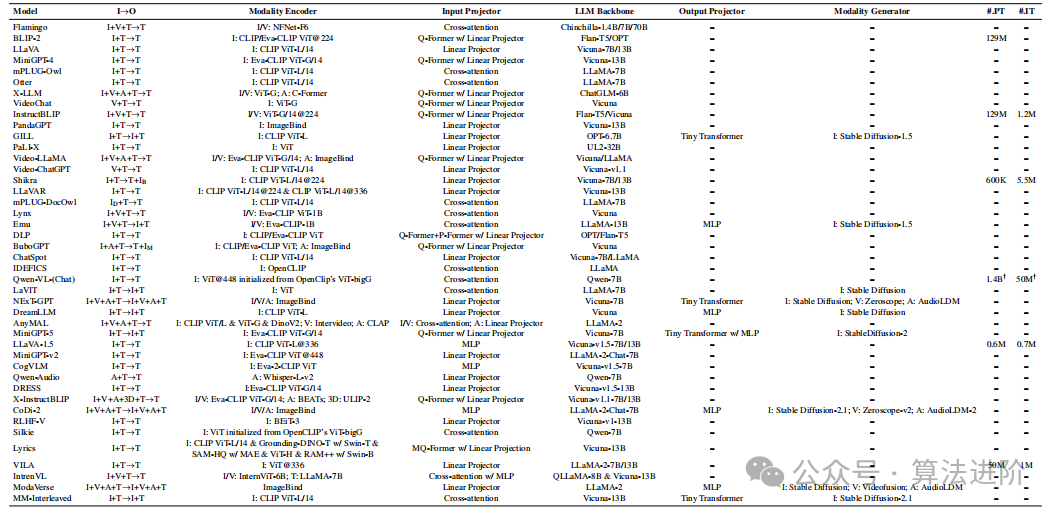
5. Benchmarks and Performance
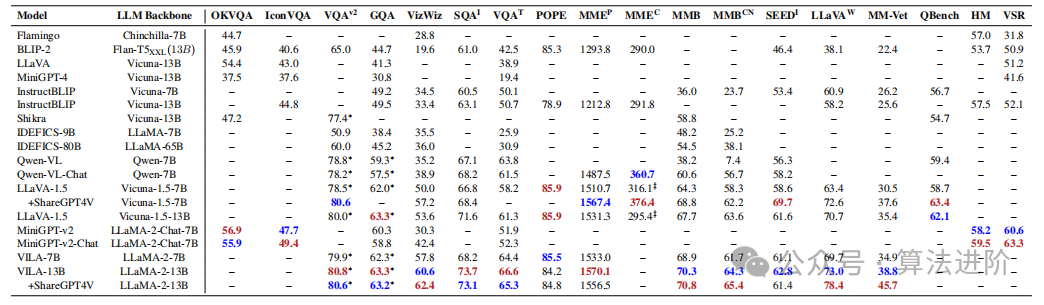
To compare the major MMLLMs on various visual language benchmarks, we compiled a table containing information from various papers, as shown in Table 2. To address the issue of high resolution leading to longer token sequences and additional training costs, some papers proposed solutions. Among them, Monkey proposed a solution that improves the input image resolution using only low-resolution visual encoders. Furthermore, high-quality SFT data can significantly enhance performance on specific tasks. VILA revealed several key findings, including the importance of performing PEFT on the LLM backend to facilitate deep embedding alignment, that interleaved image-text data is beneficial, while separate image-text pairs are not ideal. During SFT, re-mixing only text instruction data with image-text data can not only address the performance decline of pure text tasks but also improve accuracy on VL tasks.
6. Future Directions
This section discusses the promising future development trends exhibited by MM-LLMs in several areas:
More Powerful Models.Enhancing MM-LLMs in four key areas: (1) Expanding modalities: extending MM-LLMs to other modalities such as web pages, heatmaps, and charts to increase the model’s versatility and general applicability; (2) Diversified LLMs: integrating various types and sizes of LLMs to provide flexibility in selecting the most suitable LLM based on specific requirements; (3) Improving the quality of MM IT datasets: refining and expanding MM IT datasets to enhance the effectiveness of MM-LLMs in understanding and executing user commands; (4) Strengthening MM generation capabilities: exploring the integration of retrieval-based methods to enhance the overall performance of the model.
More Challenging Benchmarks.Existing benchmarks may not be sufficient to comprehensively assess the capabilities of MM-LLMs, as they may have become familiar with these tasks during training. Current benchmarks mainly focus on the VL subfields, making it essential to develop a larger scale benchmark for MM-LLMs that includes multiple modalities and unified evaluation standards. For example, GOAT-Bench and MathVista are used to assess MM-LLMs’ abilities in identifying subtle social abuse and mathematical reasoning capabilities in visual contexts, respectively. MMU and CMMMU are English and Chinese multidisciplinary MM understanding and reasoning benchmarks designed for expert AI. BenchLMM evaluates the cross-style visual capabilities of MM-LLMs, while Liu et al. delve into the optical character recognition capabilities of MM-LLMs.
Mobile / Lightweight Deployment.To deploy MM-LLM on resource-constrained platforms and achieve optimal performance, lightweight implementations are necessary. In recent years, many similar studies have been conducted, achieving effective computation and inference through performance comparison or minimal loss. However, this area still requires further exploration for additional progress. MobileVLM is a notable approach that achieves seamless deployment by reducing the scale of LLaMA and introducing lightweight downsampling projectors.
Embodied Intelligence.Embodied intelligence is an AI technology aimed at replicating human perception and interaction with the surrounding environment through understanding environments, recognizing objects, assessing spatial relationships, and planning tasks. PaLM-E and EmbodiedGPT are typical works in this field, with the former introducing multimodal agents through training MM-LLM to handle general VL tasks, while the latter proposes a cost-effective CoT method to enhance the interaction capabilities of embodied agents with the real world. Although there have been advances in integrating embodied intelligence based on MM-LLM in robotics, further exploration is needed to enhance the autonomy of robots.
Continual Learning.MM-LLMs are not suitable for frequent retraining due to high training costs; however, updates are necessary to refresh skills and keep up with human knowledge. Therefore, continual learning (CL) is essential, divided into continual PT and continual IT. Recently, a continuous MMIT benchmark was proposed to enable the capability of continuously fine-tuning MM-LLMs on new MM tasks while maintaining excellent performance on learned tasks. This introduces two major challenges: catastrophic forgetting, where the model forgets previous knowledge while learning new tasks, and negative transfer, indicating performance decline when attempting new tasks.
Mitigating Hallucinations.Hallucinations refer to generating textual descriptions of generated objects without visual cues, which can occur in various categories, such as misjudgments and inaccuracies in descriptions. The roots of hallucinations include biases and annotation errors in training data, as well as semantic drift biases related to paragraph separators. Current methods to mitigate hallucinations utilize self-feedback as visual cues, but challenges remain in distinguishing between accurate and hallucinated outputs and achieving progress in training methods to improve output reliability.
About Us
Data Pie THU, as a public account of data science, backed by the Tsinghua University Big Data Research Center, shares cutting-edge data science and big data technology innovation research dynamics, continuously disseminates data science knowledge, and strives to build a platform for gathering data talents, creating the strongest group in China’s big data.

Sina Weibo: @Data Pie THU
WeChat Video Account: Data Pie THU
Today’s Headlines: Data Pie THU