
Introduction: The author will delve into the concept of Multimodal Large Language Models (MLLMs). This model not only inherits the powerful reasoning capabilities of Large Language Models (LLMs) but also integrates the ability to process multimodal information, enabling it to easily handle various types of data, such as text and images.©️【Deep Blue AI】

● A medical image; ● A text query: “Is there any pleural effusion in this image?” The system then outputs an answer (i.e., a prediction) for the given query.

■1.1 The Rise of Multimodal Technology in AI
 ▲Figure 2|Some of the multimodal large language models (MLLMs) developed between 2022 and 2024 ©️【Deep Blue AI】
▲Figure 2|Some of the multimodal large language models (MLLMs) developed between 2022 and 2024 ©️【Deep Blue AI】● Multimodal models can handle a wider variety of modalities, while VLMs are mainly limited to processing text and images;
● Compared to multimodal models, VLMs have weaker reasoning capabilities.
■1.2 MLLM Structure
●Modal Encoder:This component is responsible for compressing raw data formats such as visual and audio into more concise representations. A popular strategy is to use pre-trained encoders (such as CLIP) to calibrate other modalities, avoiding the need to train from scratch.
●LLM Backbone:This is the “brain” of the MLLM, requiring a language model to output text responses. The encoder receives images, audio, or video and generates features, which are then processed by the connector (or modal interface).
●Modal Interface (i.e., Connector): It serves as an intermediary or link between the encoder and the LLM. Since the LLM can only interpret text, it is crucial to effectively connect text with other modalities.
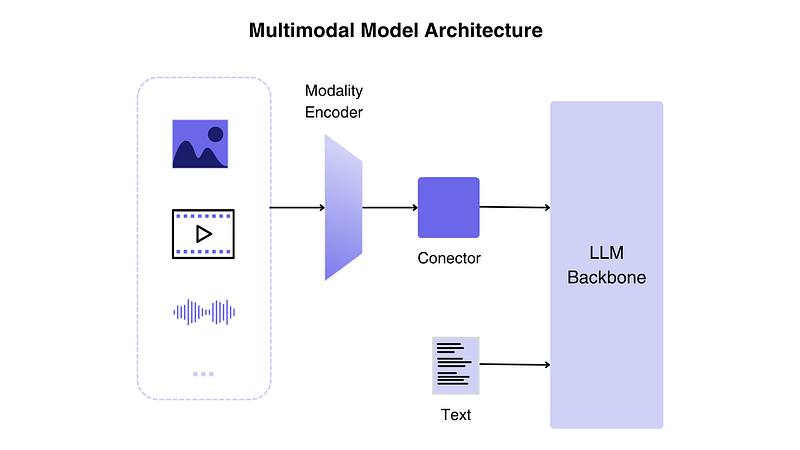 ▲Figure 3|Multimodal Understanding: Components of the First Stage of Multimodal ©️【Deep Blue AI】
▲Figure 3|Multimodal Understanding: Components of the First Stage of Multimodal ©️【Deep Blue AI】
●GPT-4o:The most powerful multimodal model released by OpenAI in May 2024. This model is accessible through OpenAI’s API visual features.
●LLaVA 7b:This model integrates a visual encoder and Vicuna for general visual and language understanding, and its performance is impressive, sometimes even comparable to GPT-4.
●Apple Ferret 7b: An open-source MLLM developed by Apple. It achieves spatial understanding through comprehension and association, enabling the model to recognize and describe any shape in an image, providing precise understanding, especially excelling in understanding smaller image areas.
■2.1 Counting Objects in the Presence of Occlusion

2.2 Autonomous Driving: Risk Perception and Planning
 ▲Figure 5|Asking the models to detect objects and assess risks: The Apple Ferret model performed better than GPT-4o ©️【Deep Blue AI】
▲Figure 5|Asking the models to detect objects and assess risks: The Apple Ferret model performed better than GPT-4o ©️【Deep Blue AI】2.3 Sports Analysis: Object Detection and Scene Understanding
 ▲Figure 6|Football match scene tested with the three MLLMs in this article ©️【Deep Blue AI】
▲Figure 6|Football match scene tested with the three MLLMs in this article ©️【Deep Blue AI】
Providing a detailed description of the scene;
Accurately counting the number of players from each team;
Providing the boundary box coordinates for the football and goalkeeper;
Assessing the likelihood of a goal and predicting which team is more likely to score.
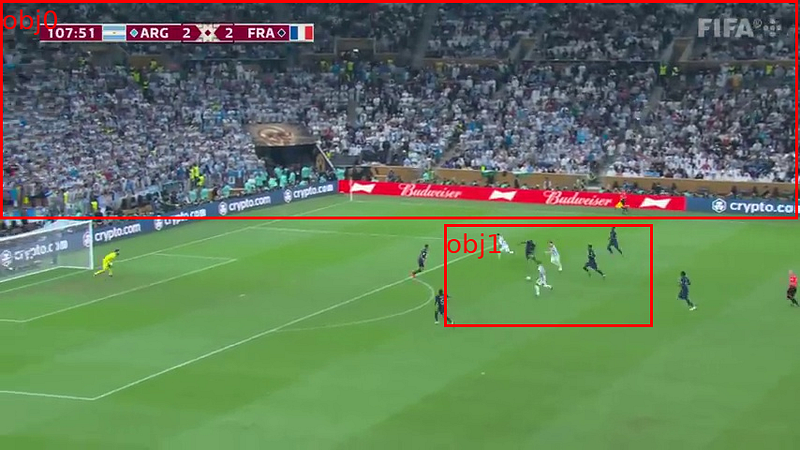 ▲Figure 7|Football match scene tested with the three MLLMs in this article ©️【Deep Blue AI】
▲Figure 7|Football match scene tested with the three MLLMs in this article ©️【Deep Blue AI】
● Input: Text, Image, Audio (Beta), Video (Beta)
● Output: Text, Image
● Introduction: GPT-4o, or “GPT-4 Omni,” where “Omni” represents its multimodal capabilities across text, visual, and audio modalities. It is a unified model capable of understanding and generating any combination of text, image, audio, and video input/output.
● Trial link: https://chatgpt.com/
● Fun fact: GPT-4o employs a “multimodal thinking chain” approach, first considering how to break down the problem into a series of steps across different modalities before executing these steps to arrive at a solution.
● Input: Text, Image
● Output: Text, Image
● Introduction: Claude 3.5 Sonnet is a multimodal AI system with a context window of 200,000 tokens, capable of understanding and generating text, images, audio, and other data formats. It excels in in-depth analysis, research, hypothesis generation, and task automation across various fields.
● Trial link: https://claude.ai
● Fun fact: Anthropic employs a technique called “recursive reward modeling,” which uses earlier versions of Claude to provide feedback and rewards for the model’s outputs.
● Input: Text, Image
● Output: Text, Image
● Introduction: Gemini is a series of large language models developed by Google that can understand and operate across multiple modalities, including text, image, audio (Beta), and video (Beta). It debuted in December 2023, with three optimized variants: Gemini Ultra (largest), Gemini Pro (for scaling), and Gemini Nano (for device tasks).
● Trial link: https://gemini.google.com/
● Fun fact: The name Gemini is derived from the Gemini constellation in Greek mythology, representing duality, which aptly reflects its powerful capabilities as both a language model and its ability to process and generate multimodal data such as images, audio, and video.
● Input: Text, Image
● Output: Text, Image
● Introduction: Qwen-VL is an open-source multimodal AI model that combines language and visual capabilities. It is an extension of the Qwen language model, designed to overcome the limitations of multimodal generalization. Recent upgraded versions (Qwen-VL-Plus and Qwen-VL-Max) have improved image reasoning capabilities, better image and text detail analysis, and support for high-resolution images with different aspect ratios.
● Trial link: https://qwenlm.github.io/blog/qwen-vl/
● Fun fact: After its launch, Qwen-VL quickly rose to the top of the OpenVLM leaderboard, but was surpassed by other more powerful models, especially GPT-4o.
Deep Blue AcademySeptember Series Public Course · Robotic Arm Themestart! A total of 6 sessions! Welcome to scan the code to join the public course group ⬇️

The first public course“Generalizable Object Manipulation Strategies Based on Foundation Models” will start onSeptember 10 (This Tuesday) at 19:55, with the speaker beingDoctoral Student at Renmin University of China, Xia Wenke. Click the card below to reserve the live broadcast and not get lost 👇
⬇️ The Deep Blue AI author team is recruiting long-term…

Recommended Reading:
“I have become smaller but stronger! NVIDIA releases the latest large language model compression technology, lossless performance and several times improvement!”
The first open-source hybrid motion planning framework for autonomous driving, holding “planning explainability” and “decision accuracy” as two trump cards!
