
Introduction This article will introduce a research-oriented topic regarding the observability of Multi-Agent Systems. Currently, our work is primarily based on the Swarm project released by OpenAI last month, where we analyzed the source code of the Swarm project and customized modifications to achieve better observability of multi-agent systems.
Today’s discussion will revolve around three core topics. First, we will briefly introduce multi-agent systems. Currently, there are various open-source multi-agent systems, such as Swarm, Auto-GPT, Microsoft’s Auto-GEN, as well as platforms like LangChain and LangGraph, which integrate multi-agent functionalities to varying degrees. Next, we will outline the mainstream multi-agent systems in the industry and discuss the observability challenges these systems face. Specifically, the internal implementation principles of these systems are complex, and due to their black-box characteristics, the interpretability of machine learning model applications is poor. With the introduction of multi-agents, observability and controllability may further decrease. Therefore, how to enhance the observability of systems and improve this issue through workflows or similar replay functions will be the focus of this sharing. Finally, we will detail the planned code extension work to improve visualization solutions.
Main content includes the following sections:
1. Introduction to Multi-Agent Systems
2. Observability Issues in Multi-Agent Systems
3. How to Extend OpenAI Swarm for Better Visualization Solutions
4. Q&A
Speaker|Chen Dihao Shunfeng Technology Head of AI Technology Platform
Editor|Student Ma
Content Proofreader|Li Yao
Produced by|DataFun
Introduction to Multi-Agent Systems
1. Introduction to Multi-Agent Systems
A multi-agent system (MAS) is a system composed of multiple agents that collaborate in the same environment, capable of solving problems that a single agent finds difficult to handle. The relevant definition in Wikipedia states that multi-agent systems have broader applicability than single-agent systems. In this context, agents are not limited to the large language models (LLMs) commonly discussed today but can be any system component with independent interaction capabilities. This article particularly focuses on LLM-based agents and the multi-agent layer integrated by such agents. After refining the scenario, the multi-agent system mainly refers to a research paper organized by foreign universities on multi-agent systems, which emphasizes that multi-agent systems consist of individual agents based on LLMs and address problems that single agents struggle to solve through communication, memory sharing, or capability expansion among these agents.

Multi-agent systems are suitable for various complex scenarios, with practical application cases already existing within Shunfeng. For example, Root Cause Analysis (RCA) aims to analyze the root causes of failures in complex systems. The complexity of modern cloud-native architectures and computer system structures (including networks, middleware, underlying components, and microservices) makes it particularly difficult to determine the specific reasons for alerts or failures. The root causes of these systems may involve components at different levels, such as discrepancies between the health check methods of middleware MySQL and the monitoring metrics of microservices; similarly, the network monitoring metrics of underlying components vary.
In such complex large system environments, a single agent struggles to effectively collect sufficient information and resolve issues at once. Therefore, adopting a multi-agent system becomes a necessary choice. Taking the illustrated RCA implementation solution as an example, each agent focuses on specific tasks, such as data exploration, dependency checks, error analysis, task scheduling, and assessing the completion of root cause analysis. Since each agent has a clear work objective and can be equipped with different tools or functions, they can efficiently complete their respective tasks. By organically integrating these agents into a multi-agent system, effective handling of complex RCA tasks can be achieved.
Moreover, the software engineering field—covering product development, code testing, and version release management—also includes scenarios of collaboration among users or multiple developers. With the emergence of more open-source multi-agent systems, different roles can be assigned to each agent, allowing them to collaborate towards a common goal, which also applies to collaborative models in software engineering or company operations. A single agent struggles to solve all problems, while a multi-agent system can provide a more comprehensive solution.
The industry is also exploring the application of multi-agent systems in world simulation and gaming scenarios. By defining agents with different roles, they can autonomously communicate and gradually explore the environment, simulating details similar to the real world. These scenarios are very suitable for the application of multi-agent systems.
In summary, multi-agent systems are not only suitable for root cause analysis but can also be widely applied in software engineering, enterprise operations, simulation, and gaming, effectively addressing challenges that single agents find difficult to overcome.
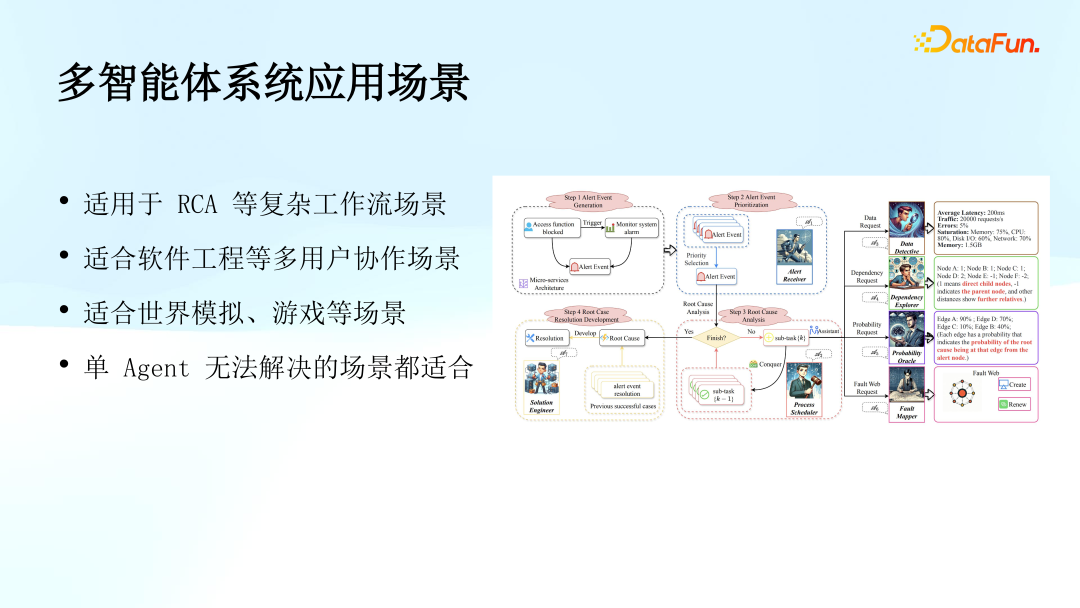
There are several mainstream or open-source multi-agent systems in the industry, and below we will introduce some representative examples.
First, we mention MetaGPT, a project that has emerged from the Chinese open-source community. In this framework, various employee roles are defined, including human resources, administrative management, etc., with the expectation that agents will replace humans to complete as many tasks as possible. For needs requiring human-machine interaction, MetaGPT provides corresponding implementation mechanisms. This framework not only implements the memory and interaction functions of agents but also defines the role of the human agent, allowing humans to participate in the collaboration and interaction with agents. This makes MetaGPT a relatively mature framework. However, since it can automatically handle collaborative tasks for the entire company, it raises higher requirements for its observability and reliability.
Next is CAMEL, a foreign agent ecology project exploring the definitions of agents, memory mechanisms, and interaction patterns among agents. This project consists of multiple sub-projects that delve into the design principles of agents.
The third is AutoGen, a programming framework open-sourced by Microsoft. Unlike MetaGPT, AutoGen focuses more on programming interfaces, allowing users to define relationships among agents, whether equal or hierarchical, and control interactions among agents through configuration and definition. For example, in a superior-subordinate relationship, the supervising agent can actively interact with other agents, providing a programming paradigm that offers more flexible control than traditional workflows.
AutoGPT is a project that gained significant popularity last year, achieving a high level of intelligence through internal multi-agent collaboration to understand user intentions, execute code generation tasks, and reflect on outcomes.
GPT Researcher focuses on reading papers and reports, sharing knowledge bases, and correcting papers.
Although the aforementioned frameworks provide excellent solutions for specific scenarios, they are often complex, difficult to scale, and have poor observability. For instance, when using AutoGPT, users find it challenging to participate in its internal thought process, making it difficult to extend their agents or migrate them to other scenarios.
Surprisingly, OpenAI recently open-sourced the Swarm framework, aiming to provide an educational framework and an easy-to-learn research platform. The characteristics of Swarm lie in its simple abstraction and unified interface design: the user interface adopts a Python function format, tools can be defined through Python, and communication among agents can achieve dynamic routing based on function calls. Although the functionalities of Swarm and the internal memory of agents are relatively simple, it provides a clear perspective for understanding and extending the scheduling mechanisms of multi-agent systems, helping to improve system observability.

2. Introduction to OpenAI Swarm
Next, we will briefly introduce OpenAI’s Swarm framework. First, Swarm is entirely implemented in Python, with its core code amounting to only about 500 lines, making it both concise and easy to use. Additionally, Swarm is compatible with OpenAI’s API interface, meaning users do not need to rely on specific models provided by OpenAI, such as GPT-4; as long as the OpenAI API Key and service address are configured, they can seamlessly switch to other models, such as domestic services or locally deployed models. Swarm directly uses OpenAI’s Python SDK, hence it is not tied to any commercial model.
In Swarm, agents and their tools are defined through Python, supporting historical dialogue records, thereby enhancing the multi-turn dialogue capabilities.
Finally, Swarm officially provides installation guides, and specific examples can be found in its example directory, making it easy for users to understand and apply. Considering Swarm’s design philosophy, even relatively complex scenarios can be simplified through similar methods, such as the most basic single-agent scenarios, which resemble directly using the Python SDK to call OpenAI services.

Observability Issues in Multi-Agent Systems
Even if we successfully implement multi-agent applications, their observability remains a key challenge.
Observability is an important concept that refers to the ability to infer the internal state of a system from external observations, i.e., assessing the reliability of the system’s responses to external observations. If the system’s observability is strong, such as in AIOps scenarios or cloud-native services, we can better understand and manage these systems. This is because cloud-native services and their deployment architectures often have uncertainties, unlike traditional holistic machines or virtual machine development models, which perform operational tasks after selecting nodes for deployment; in a cloud-native environment, ports may be dynamically allocated to different nodes. Therefore, we need to rely on external flow monitoring, statistical information, and metrics, such as APM (Application Performance Management) call chains, to enhance observability, ensuring balanced task scheduling and timely detection of potential issues.
For large language models or multi-agent systems, improving observability means whether we can infer whether the internal intelligent routing is correct or meets expectations through external performances, such as final outputs or execution histories. To achieve this, it is essential to strengthen the system’s observability capabilities. Good observability not only determines the controllability of the system but also enables us to understand the behavior paths of agents under specific prompts or data scenarios. For example, under normal circumstances, the express order process should follow predetermined steps. When we input an abnormal order, whether the system can handle the abnormal workflow or adjust scheduling as expected are aspects we hope to expand and optimize.
In short, if we only run a multi-agent script and only obtain the final result, such results lack sufficient reliability and controllability. If we want to reproduce similar scenarios, the calling process may not be as consistent as expected. Therefore, enhancing the observability and controllability of multi-agent systems is crucial, which helps ensure the stability and reliability of the system.

Large language models face several inherent problems regarding observability. First, these models are based on transformer and neural network architectures, which have poorer interpretability compared to traditional memory learning algorithms such as logistic regression or decision trees. With decision trees, we can intuitively understand the decision paths and thresholds; however, neural networks output results through complex matrix operations, leading to their inherent unexplainability. As a result, the outputs of large language models are difficult to observe and parse directly, although certain degrees of control can be achieved through customized prompts.
Secondly, when optimizing large language models, for example, addressing their hallucination phenomena or unstable outputs, we can limit them by defining workflows and setting specific prompts. Workflows are widely used methods because single agents typically cannot complete all business tasks, and their accuracy may be low. Taking natural language to SQL (NL2SQL) as an example, even with the most advanced large models, the accuracy in general scenarios may only reach around 40%, far from meeting production needs. To improve this situation, we can limit application scenarios or define specific workflows. For instance, rather than requiring a complete SQL query to be generated at once, we can first generate a framework or business indicators and then gradually refine the SQL statements through the business system. Combining business processes and logic, this method can effectively control the final output and achieve good results in specific scenarios, such as the currently popular ChatBI or natural language assistance tools like Copilot.
In internal applications within enterprises, such as Shunfeng’s use of customized workflow software like LangChain and LangGraph, controllability of processes can be achieved in conjunction with existing business processes. However, the goal of multi-agent systems is to handle more generalized scenarios. When faced with numerous workflows, we do not want to define each process individually but expect agents to autonomously exert dynamic routing scheduling capabilities. In this case, the system’s observability needs to be expanded through external mechanisms to ensure the transparency and traceability of agent behaviors.

Taking the express collection, transfer, and delivery process as an example, we can define multiple agents. During the user’s use of the express service, the agents they may interact with include but are not limited to customer service agents. For non-sending inquiries, the questions posed by users are usually answered by customer service agents, such as providing information queries or consulting services. If it involves order-related operations, interactions occur through the client application, which can also be regarded as an agent. The client application is mainly responsible for interacting with the order processing system, while the order processing system, as an agent, schedules nearby couriers for collection tasks. Once the courier receives the package, if it’s a same-city package, they can deliver it directly; for inter-city packages, they need to send the package to a transfer station. The transfer station, as another agent, must notify the order processing system to select an appropriate transfer station and arrange for a courier to deliver it.
In this express scenario, although it is difficult to define all workflows in detail, the roles of each agent can be clearly defined. Each agent operates within its specific responsibility scope and collaborates with other agents to complete the complex express process. For example, the customer service agent is responsible for answering user inquiries, the client app agent manages the submission and tracking of user orders, the order processing system agent coordinates the task assignment of couriers, while couriers and transfer stations execute collection and transfer tasks, respectively. This structure of the multi-agent system ensures that even when workflow details are not completely defined, the roles and responsibilities of each agent remain clear.

Additionally, regarding the immediate calling relationships among agents, the actual system is much more complex than described, so we have made appropriate abstractions. For instance, the client app system contains an ordering tool. When users place an order through this app, this tool notifies the order scheduling system to execute the order allocation task. The order processing agent has scheduling tools to arrange for couriers to pick up and deliver, while the courier agent has tools to perform the actual collection and delivery tasks.
Specifically, when users place an order through the client app, the order information is passed to the order processing system, where the agent is responsible for scheduling related resources, including notifying couriers to perform collection work. Once the package arrives at the transfer station, the transfer station agent will notify the order processing system to arrange delivery manpower. Thus, although the internal calling relationships among agents are complex, their roles and responsibilities can be clearly defined.
Therefore, through this abstraction method, we can clearly define the functions of each agent and its tools, ensuring that in the complex express process, interactions and task assignments among agents can proceed in an orderly manner.

When users present natural language requests, such as wanting to send a computer from Shenzhen to Beijing, the multi-agent system begins processing this request. First, the client app receives the message and recognizes that this is not a customer service inquiry, so it does not route it to the customer service agent but directly routes it to the order system for processing. Ultimately, the system outputs the corresponding text information.
However, relying solely on the inputs and outputs of large language models is not sufficient. Although we have defined multiple agents and their calling relationships, and these relationships can be visualized through diagram software, in multi-agent models, when both the input and output are natural language, the internal calling relationships are not transparent. This is precisely the observability issue mentioned earlier: we cannot know how many agents the natural language input has gone through, and whether these agents have activated and called specific tools. Additionally, we find it difficult to understand what tools each agent has to perform actual operations, such as placing orders, which tools were specifically activated in this process, and the business logic, input-output parameters, and intermediate execution logs of these tools. All this information cannot be directly reflected in the final natural language output, lacking visualization capabilities.
Furthermore, this mode of agent invocation makes reproduction and replay difficult. For example, if modifications are made to the requirements or if new agents and calling relationships are added to the system, can the system still call as expected? This poses challenges for writing unit test cases since even slight changes in input text can lead to variations in output, increasing the difficulty of consistency and predictability in testing.
Therefore, to enhance the controllability and reliability of the system, it is necessary to improve the observability and visualization capabilities of the multi-agent system, ensuring that its internal workflows are transparent and visible to better support debugging, testing, and maintenance work.

In fact, we may want to test whether the routing and scheduling of the multi-agent system are correct. However, if we only have the final output of the large language model, it is insufficient to fully assess the accuracy of the scheduling and related metrics. For more comprehensive assessments and historical case expansions, for example, currently only the last step is recorded, namely notifying the order system for delivery, which is evidently insufficient.
If we subsequently need to add additional logic, such as the customer follow-up process, we may need to introduce more agents and make certain modifications to the existing system. This means that not only do we need to record the final operation, but we also need to track each agent’s behavior throughout the entire process in detail, including what tools they called, what functionalities were activated, and the specific business logic executed. Only then can we ensure that the system’s behavior aligns with expectations and provides a basis for future optimizations and adjustments.
Therefore, to achieve accurate testing and evaluation of the routing and scheduling of the multi-agent system, it is essential to enhance the system’s observability and recording capabilities to comprehensively capture all agents’ historical activities and interaction details. This not only aids in the transparency of current operations but also lays a solid foundation for future functional expansions and system improvements.

How to Extend OpenAI Swarm for Better Visualization Solutions
1. Implementing Observability in Multi-Agent Systems
Currently, the work is in its initial stages, and our goal is to enhance the observability of the system. One specific measure is to obtain all historical records of agents throughout the operation process. One method is to enable the internal logging function of the Swarm framework, particularly its debug mode. Once this function is enabled, we can observe some historical information, which is very helpful for understanding the intermediate calling chains.
For example, when the debug logs are not enabled, the text output only displays the final result; however, once the debug logs are enabled, we can see more information about the intermediate calling chains, including internal interaction records. Through these records, we can trace system prompts, user inputs, function calls, and their parameters. As processing deepens, this information gradually accumulates because the system concatenates historical messages to subsequent requests. By viewing the debug logs, we can understand the requests that individual agents actually send to the large model and their parameters, which enhances observability capabilities.
Through this method, we can roughly analyze which agent is currently handling the task and see the specific parameters of the large model calls initiated by that agent, including system prompts, user prompts, historical messages, and relevant information about function calls. Enabling debug logs is helpful for debugging, but its primary purpose is to gain deeper insights into agent behavior.
The second aspect is to collect data on agent responses based on unified historical information. This part will be detailed in a later demonstration, which includes all historical information of agent calls. Although the system will partially truncate this information, we can achieve a degree of visualization and storage capability by collecting this data.
The third aspect is the ability to collect function execution data. In multi-agent systems, each agent calls multiple Python functions. If we only rely on printed logs, we cannot effectively collect response data. Therefore, we have modified the code to enable it to summarize this information through global context and ensure long-term preservation of this data through data persistence techniques.
Furthermore, based on persistent data, we have also developed visualization techniques to further improve the observability of the system.

The overall architecture design is as follows: In the future, we will support multiple frameworks, including OpenAI’s Swarm, Meta, GPT, and AutoGen. These frameworks will provide their operational historical data according to specific response formats, which may require some code modifications or collection of information through global context.
We have developed a service called “AgentInsight,” which is responsible for parsing the formats of agents’ responses and implementing various visualization displays. For instance, it can visualize the interaction process as a chatbot-like interface, allowing users to intuitively see the dialogue content of each agent, with different agents represented by different icons, thereby clearly displaying how many agents were involved in the task, which agent is processing the task, and their processing times. Additionally, specific information accessed by agents can also be obtained.
For complex scenarios, such as root cause analysis (RCA), we provide a display format similar to a “war room.” In this mode, multiple agents can simultaneously troubleshoot issues, while a unified agent is responsible for overall scheduling. This display method can help users better understand the troubleshooting process and progress.
In addition to the aforementioned advanced display formats, we also support simple command-line outputs, allowing users to directly view the output results of current agents and the functions called. Moreover, chart display functionalities are also provided to meet the visualization needs of different users.
On the agent side, we have extended the Replay function, allowing users to specify previously run scenarios to replay to specific nodes. Based on this, users can add new agents and continue executing tasks based on the new agent model. This function helps reproduce and debug complex workflows, ensuring system stability and controllability.
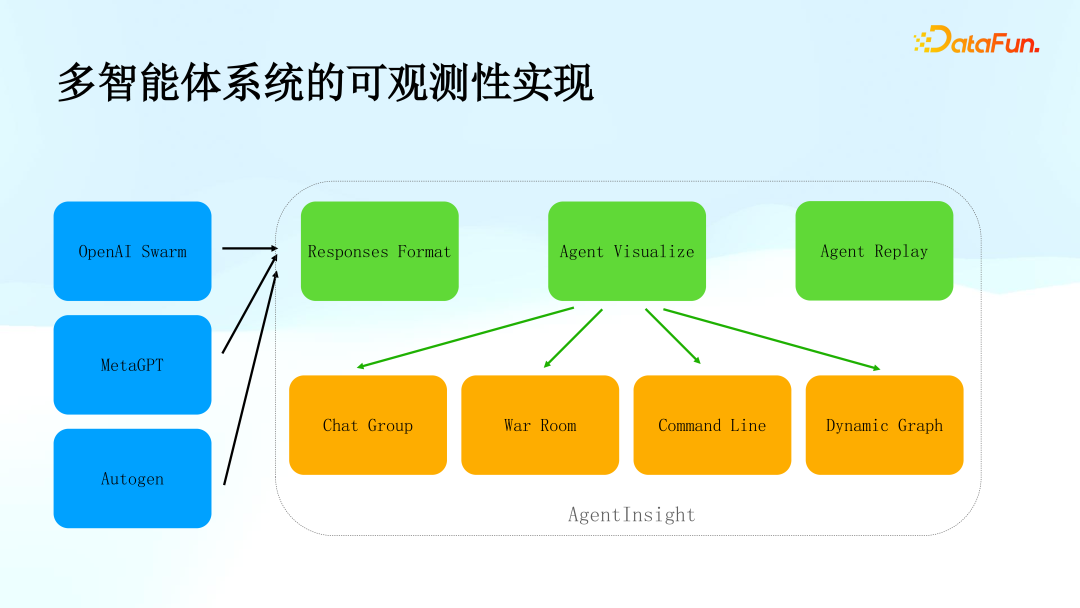
2. Modifications Based on OpenAI Swarm
The modifications based on OpenAI Swarm mainly include the following aspects: understanding the source code of OpenAI Swarm, collecting response information from multi-agent applications, expanding context support for function information, and performing visualization output displays.
The main task of source code analysis is to understand the overall implementation principles of Swarm, especially how its simple programming entry works. We need to delve into how it calls the OpenAI API.

We also need to understand the logic of multi-turn dialogue implementation, where each large model output will determine whether to hand over to another large model until it finally decides to output the final result.

Domain abstraction implementation requires collecting response information. After each large model output, the result will be passed to the next agent for further processing until the final agent outputs a response that can conclude the process. Each agent’s output not only contains historical records of discussions but also determines whether it needs to be passed to another downstream agent for further processing.
Swarm does not have internal memory functionality, which is an improvement direction we can later contribute back to OpenAI. We plan to add persistent storage to save historical data, thereby enhancing the system’s observability and traceability.

The main components of an agent include its system prompt, the large model used, and the available function calls. These elements together determine the behavior patterns of the agent. Function calls output in a fixed format, which includes role information (such as user, assistant, or specific roles) and can call native functions through reflection mechanisms to generate outputs.

To better support visualization, we will implement persistent modifications, such as writing all historical data to local JSON files and supplementing necessary information to ensure that users’ input messages are not overlooked. This persistent data can be used to create more complex visualization displays, such as command-line interfaces or dynamic charts resembling chat windows.

In terms of visualization displays, the command-line interface shows the calling relationships among agents and specific called Python functions along with their execution details. Through persistent data, we can build more intuitive visualization tools to help understand and debug the workflows of agents.

Most contextual information can be obtained through OpenAI’s history message, but for certain action execution log information, we need to perform additional context completion. We have designed a global context variable for each function call, which appends function execution information during each invocation to ensure that this information is consistent with the actual code order. By abstracting a method, we ensure that each time a Python function is called, relevant information is actively appended to the context variable for subsequent data persistence and visualization.

Future modification plans include introducing more visualization formats, such as dynamic graphs and other advanced display functionalities. Currently, we have implemented historical record replay functions, but in the future, we will further support continuation functionalities. This means we can pass a historical agent calling relationship to the Swarm client and continue to draw and execute new workflows based on the new agent configuration on the original process. These improvements will significantly enhance the system’s observability and controllability, including the following directions.
Enhanced Visualization: We will introduce more visualization formats, such as dynamic charts and other advanced display tools, to provide a more intuitive view of operational processes.
Historical Record Replay and Continuation: The current system can replay historical records, and in the future, we will further support continuation functions, i.e., based on existing historical data, continue executing and expanding the original workflows with new agent configurations.
Frontend Interface Control: In the frontend interface, users can define preset workflows by dragging nodes and implement dynamic scheduling based on these workflows. This flexibility allows users to operate directly in the graphical interface, defining and adjusting the workflows of agents.
Support for More Open Source Intelligence Submission Systems: We will continue to integrate and support more mentioned open-source agent systems to enrich our technology ecosystem and enhance the interoperability of the system.
Through these improvements, we can not only enhance the observability of the system but also provide users with more control options, ensuring they can flexibly define and manage complex workflows. This will help achieve a more intelligent and automated task processing flow.
Q&A
Q1:What is the difference between Multi-agent and Workflow? Can the ordering example be used with Workflow?
A1: Indeed, Workflow can achieve the integrated definition of standard processes. For example, when handling a normal order collection and delivery process, we can use tools like LangChain to define and link multiple objects, forming a standardized workflow. However, the advantage of multi-agent systems (MAS) lies in their flexibility and adaptability. Multi-agent systems can handle not only standard processes but also non-standard requests. For instance, when users pose customer service-related questions, such as inquiring how to send items from Shenzhen, MAS can dynamically schedule the appropriate customer service agent based on the specific situation instead of merely following a preset workflow.
Through visual logs, it can be seen that when the client app receives a specific type of inquiry, it directly returns information without triggering the standard delivery process. In this case, the large language model agent can dynamically adjust the scheduling path based on the user’s input.
Therefore, while workflows provide stronger controllability and clear process definitions, the flexibility and self-adaptive capabilities of multi-agent systems stand out when facing open-domain issues or complex scenarios. For scenarios that require broader coverage and more complexity, MAS is a direction worth exploring. However, in practice, we encounter challenges with observability, which is one of the reasons we are exploring based on the OpenAI Swarm framework.
Q2:What is the core role of the Agent framework? Do the built-in prompt and memory components really facilitate the emergence of Agent applications? Is the model’s inherent capability more important?
A2: The core role of the Agent framework is to provide developers with an abstraction layer that simplifies the creation of agent classes, inter-agent communication, and memory management functions. This not only reduces redundant work but also promotes modular design. While the inherent reasoning and expressive capabilities of the model are crucial, a good framework can significantly facilitate the development and deployment of Agent applications. Customized Agent frameworks often have higher flexibility, while lightweight frameworks like OpenAI Swarm are favored for their simplicity and scalability.
For those looking to get started quickly without much customization, MetaGPT or Research GPT may be better choices; while for projects pursuing higher customization levels, OpenAI Swarm provides a flexible infrastructure. Frameworks like Agent Universe focus more on specific application scenarios, internally implementing various predefined agents and their interaction methods, suitable for demonstration purposes but may still require adjustments based on specific business needs. Therefore, the choice of framework should be based on specific business requirements and technical demands.
Q3:In team organization, what roles can algorithm engineers play in multi-agent collaboration?
A3: At Shunfeng Technology, we are responsible for the development of AI platforms and large model technology components, including both work based on open-source frameworks and our proprietary development, such as Swarm, LangChain, LangGraph, and Dify. Each of these frameworks has its characteristics; some are highly engineered and mainly constructed by architects and backend developers, while frameworks like OpenAI Swarm, which are pure Python interface frameworks, are more suitable for algorithm engineers with strong programming skills and algorithm backgrounds to develop and optimize.
Especially as the threshold for multi-agent frameworks lowers, algorithm engineers can play roles in more areas, such as implementing dynamic scheduling logic among multi-agents and defining agent behavior patterns. Additionally, algorithm engineers can also participate in optimizing large model inference to ensure that models operate efficiently in production environments. For open-source projects like Qianwen 2.5, we have also conducted tests and found that they perform well, meeting production environment needs. Therefore, the role of algorithm engineers in multi-agent collaboration is becoming increasingly important, especially in customized development that aligns with business requirements.
Q4:What is the impact of the newly released MC protocol?
A4: Regarding the newly released MC protocol, I currently have limited information. However, in principle, even without relying on specific calling mechanisms (such as function calls), interactions can occur through other means, such as JSON format outputs or structured data exchanges. In fact, many functionalities can be implemented through high-level programming languages like Python without requiring additional support from lower-level or tool layers. If there are specific questions about the MC protocol, we can further discuss them after the meeting.
That concludes this sharing session, thank you all.
Currently serving as a senior engineer of the AI technology platform at Shunfeng Technology, responsible for the AI and large model infrastructure functions of Shunfeng Group. Previously served as a platform architect at Fourth Paradigm and PMC of OpenMLDB, and was the head of the storage and container team at Xiaomi’s cloud deep learning platform. Active in open-source communities related to distributed systems and machine learning, and also a contributor to open-source projects like HBase, OpenStack, TensorFlow, and TVM.
NVIDIA Nemo Framework High-Performance Reinforcement Learning Training
Content Volunteer Recruitment|January Update Topic: Data and AI Solutions (Includes 2025 Annual Meeting Schedule)
Data “Entering the Table” Nearly a Hundredfold Improvement! Exploring New Paradigms of Data Governance with Dataphin
The Current Status and Trends of MLOps Development in the Era of Large Models
The Evolution of Data Governance at Alibaba: Multi-Engine Compatibility and Unified Asset Consumption Practices Based on Lingyang Dataphin
How Graph Databases Improve Complex Analysis Efficiency
Exploring Faster GPU Training Distributed Cache Technologies Using NVMe, GDS, and RDMA
How Does Zhihu Reduce Costs and Increase Efficiency?
Decentralized Content Distribution Technology of Xiaohongshu
Exploration of ChatBI Applications in Advertising
Click to see your best view







