
Machine Heart Report
Transformer models have revolutionized almost all natural language processing (NLP) tasks, but their memory and computational complexity grows quadratically with sequence length. In contrast, Recurrent Neural Networks (RNNs) grow linearly in memory and computational requirements, but due to limitations in parallelization and scalability, it is difficult to achieve performance levels comparable to Transformers. This paper proposes a novel model architecture, Receptance Weighted Key Value (RWKV), which combines the efficient parallel training of Transformers with the efficient inference of RNNs. Experiments have shown that RWKV performs comparably to Transformers of the same scale.
Deep learning technologies have made significant strides in the field of artificial intelligence, playing a key role in various scientific and industrial applications. These applications often involve complex sequence data processing tasks, including natural language understanding, conversational AI, time series analysis, etc., with technologies primarily including Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and Transformers.
However, these methods each have different drawbacks that limit their efficiency in certain scenarios. Recurrent Neural Networks (RNNs) face the problem of gradient vanishing, making it difficult for them to train on long sequences. Moreover, they cannot be parallelized across the time dimension during training, thus limiting their scalability. On the other hand, Convolutional Neural Networks (CNNs) are only good at capturing local patterns and are lacking in handling long-range dependencies, which are crucial for many sequence processing tasks.
The Transformer model has become a powerful alternative due to its ability to handle both local and long-range dependencies and its feature of parallelizable training, as demonstrated by architectures like GPT-3, ChatGPT, GPT-4, LLaMA, and Chinchilla, pushing the frontier of natural language processing. Despite these significant advances, the inherent self-attention mechanism in Transformers poses unique challenges, mainly due to its quadratic complexity. This complexity makes the architecture costly in terms of computation and memory when dealing with long input sequences or in resource-constrained situations. This has also prompted a significant amount of research aimed at improving the scalability of Transformers, often at the expense of some features.
To address these challenges, an open-source research team composed of 27 universities and research institutions jointly published a paper titled ‘RWKV: Reinventing RNNs for the Transformer Era’, which introduces a new model: RWKV (Receptance Weighted Key Value), a novel architecture that effectively combines the advantages of RNNs and Transformers while avoiding their known limitations. RWKV is well-designed to alleviate the memory bottleneck and quadratic scaling issues brought by Transformers, achieving more effective linear scaling while retaining some properties that have made Transformers dominant in this field.

-
Paper link: https://arxiv.org/pdf/2305.13048.pdf
-
RWKV model download: https://huggingface.co/BlinkDL/rwkv-4-raven
-
Demo link: https://www.codewithgpu.com/i/app/BlinkDL/ChatRWKV/RWKV-4-Raven-7B
This article utilizes a linear attention mechanism, allowing the model to be defined as either a Transformer or RNN, thereby enabling parallel computation during training while maintaining constant computational and memory complexity during inference, making it the first non-Transformer architecture that can scale up to hundreds of billions of parameters.
One feature of RWKV is its ability to provide parallel training and robust scalability, similar to Transformers. Additionally, the study reinterprets the attention mechanism in RWKV, introducing a variant of linear attention that avoids traditional dot-product token interactions in favor of a more efficient channel-directed attention. This approach sharply contrasts with traditional Transformer architectures, where specific token interactions dominate the attention. In RWKV, the implementation of linear attention is done without approximation, providing significant improvements in efficiency and enhancing scalability, as detailed in Table 1.
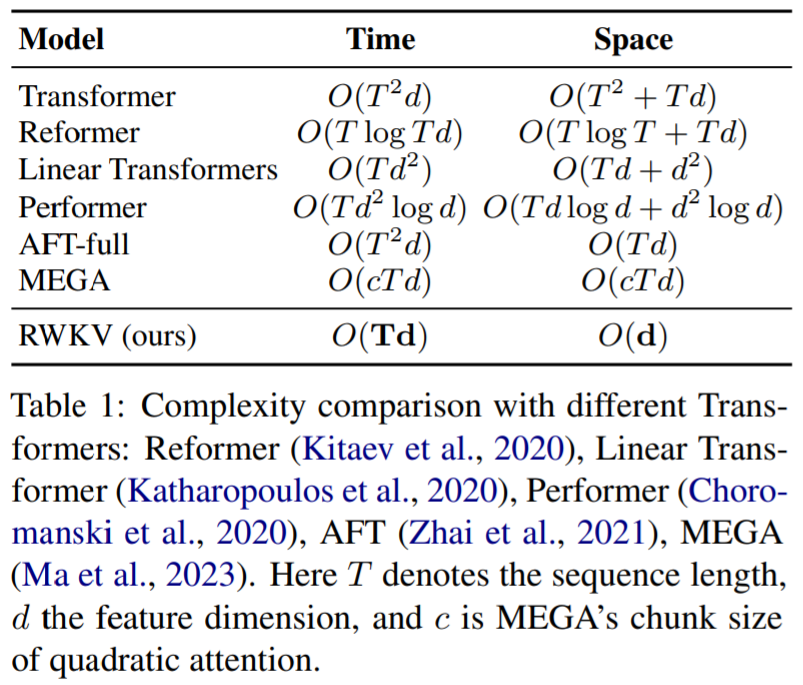
The main motivation for developing RWKV is to bridge the gap between computational efficiency and expressive power in neural network architectures. It offers a promising and feasible solution for tasks involving large-scale models with billions of parameters, demonstrating strong competitiveness at extremely low computational costs.
Experimental results indicate that RWKV can be a valuable tool for addressing various challenges in scaling and deploying AI models across different domains, especially those involving sequence data processing. RWKV paves the way for the next generation of more sustainable and computationally efficient AI models for sequence processing tasks.
In summary, the contributions of this paper are as follows:
-
Introduced the RWKV network architecture, which combines the advantages of RNNs and Transformers while alleviating their known limitations.
-
Proposed a new attention mechanism reconstruction, leading to linear attention that avoids the quadratic complexity associated with standard Transformer models.
-
Conducted a series of comprehensive experiments on benchmark datasets, demonstrating RWKV’s performance, efficiency, and scalability in handling large-scale models and long-distance dependency tasks.
-
Released pre-trained models ranging from 169 million to 14 billion parameters, trained on the Pile dataset.
It is worth noting that EleutherAI, one of the participating institutions in the paper, stated that this paper is not the final version and will continue to be refined.
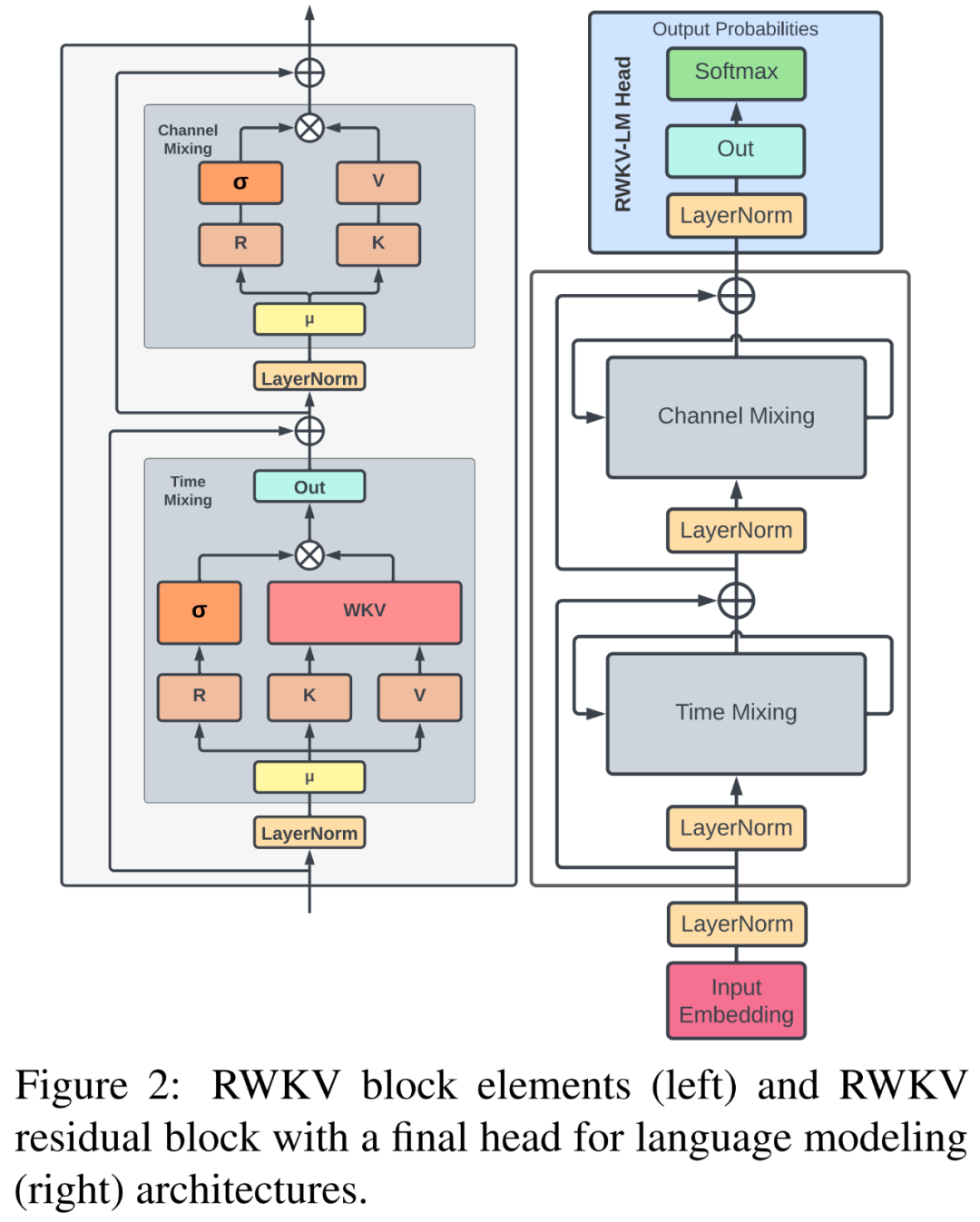
RWKV Model
The name of the RWKV architecture comes from the four main model elements used in time mixing and channel mixing blocks, as follows:
-
R: Receptance vector, used to receive past information;
-
W: Weights are position weight decay vectors, which are trainable model parameters;
-
K: Keys are vectors similar to K in traditional attention;
-
V: Values are vectors similar to V in traditional attention.
The interaction between the main elements at each time step is multiplicatively increased, as shown in Figure 2 below.
Architecture Details
The RWKV architecture consists of a series of stacked residual blocks, each of which is composed of time mixing and channel mixing sub-blocks with recurrent structures.
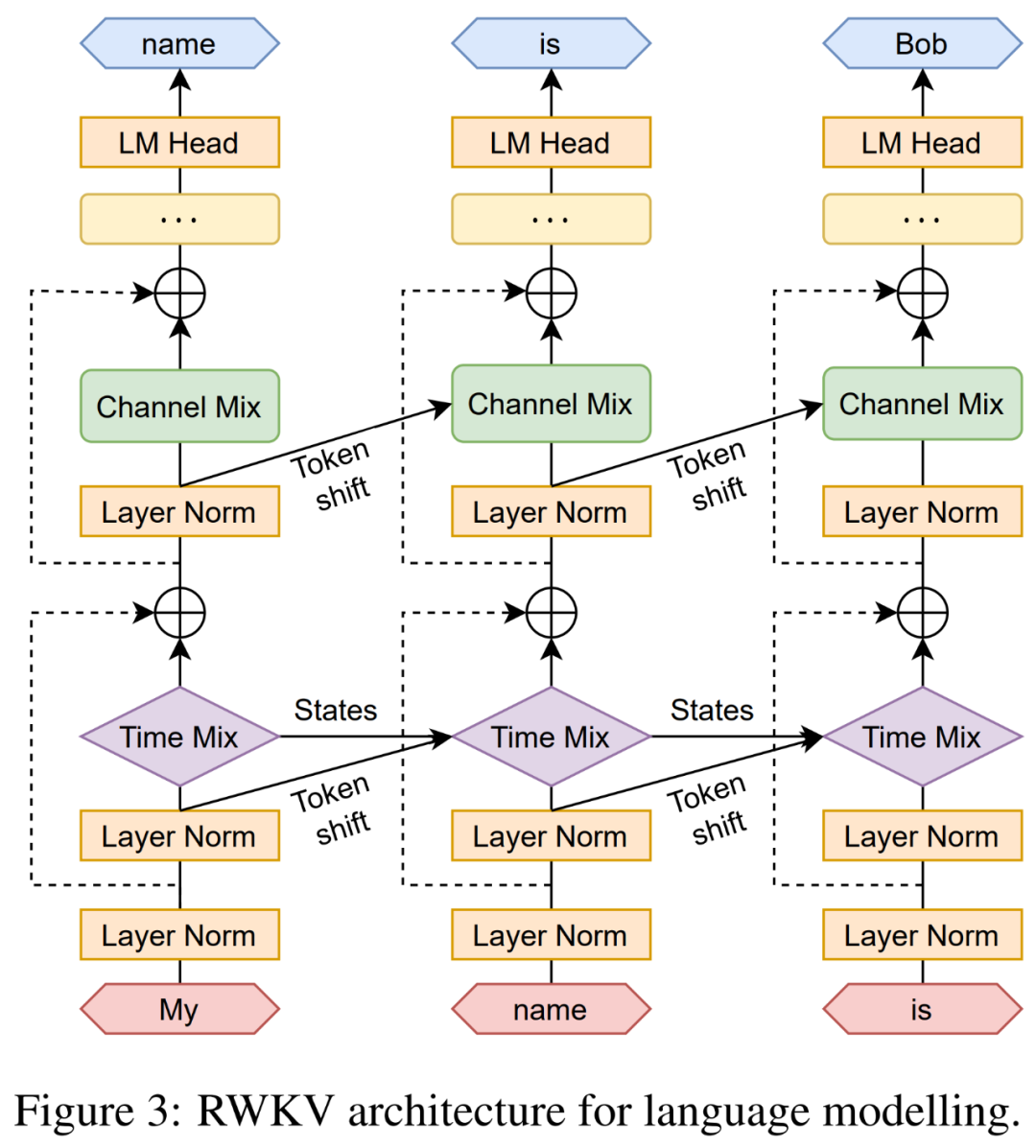
Recurrent structure is represented as linear interpolation between the current input and the input from the previous time step (the researchers refer to this technique as time shift mixing or token shift, as shown in Figure 3 below), which can be independently adjusted for each linear projection of the input embedding (e.g., R, K, and V in time mixing, R and K in channel mixing), and serves as the time-varying update of WKV formalized in Equation 14.
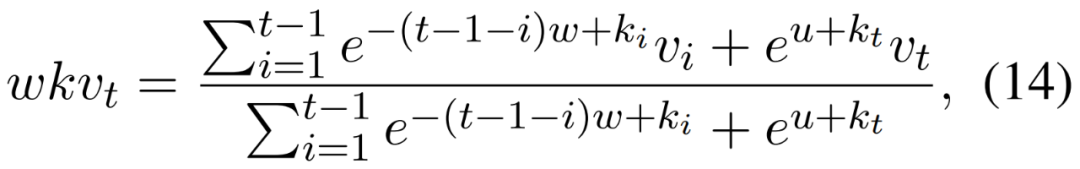
Transformer-like Parallelization
RWKV can be efficiently parallelized in a time-parallel mode, reminiscent of Transformers. The time complexity of a batch sequence in a single layer is O (BTd^2), primarily driven by matrix multiplications W_□, □ ∈ {r, k, v, o} (assuming B sequences, T maximum tokens, and d channels). Updating the attention scores wkv_t requires a serial scan, with a complexity of O (BTd).
RNN-like Sequence Decoding
In recurrent networks, it is common to use the output at time t as the input at time t+1. This is particularly evident in the autoregressive decoding inference of language models, where each token must be computed before feeding it into the next step, allowing RWKV to utilize an RNN-like structure (i.e., temporal mode). In this case, RWKV can conveniently loop for inference decoding, leveraging the advantage that each output token depends only on the latest state.
Then RWKV acts as an RNN decoder, maintaining constant speed and memory occupancy in terms of sequence length, thus processing longer sequences more efficiently. In contrast, self-attention typically requires KV caching to grow linearly with sequence length, leading to decreased efficiency and consuming more memory and time as sequence length increases.
Software Implementation
RWKV was initially implemented using the PyTorch deep learning library and custom CUDA kernels (which are used for WKV computation). Although RWKV is a general recurrent network, its current implementation primarily focuses on language modeling tasks (RWKV-LM). The model architecture includes an embedding layer, for which the researchers followed the setup in Section 4.7 and sequentially applied several identical residual blocks according to the principles in Section 4.6, as shown in Figures 2 and 3 above.
Gradient Stability and Layer Stacking
The RWKV architecture is designed as a fusion of Transformers and RNNs, benefiting from the stable gradients and deeper architectures of Transformers compared to traditional RNNs, while also maintaining high inference efficiency.
The RWKV model features a single-step process for updating attention-like scores, which includes a time-dependent softmax operation that aids in numerical stability and prevents gradient vanishing (for strict proofs, see Appendix F). Intuitively, this operation ensures that gradients propagate along the most relevant paths. Layer normalization (Ba et al., 2016) is another key aspect of the architecture, enhancing the training dynamics of deep neural networks by stabilizing gradients and addressing gradient vanishing and explosion issues.
Utilizing Temporal Structure for Time Series Data Processing
RWKV captures and propagates temporal information through a combination of three mechanisms: recurrence, temporal decay, and token shift.
The recurrence in RWKV’s time mixing blocks forms the basis of the model’s ability to capture complex relationships between sequence elements and propagate local information over time.
The temporal decay mechanism (e^−w and e^u in Equation 14) maintains sensitivity to the positional relationships between sequence elements. By gradually reducing the impact of past information over time, the model retains temporal locality and a sense of progression, which is crucial for temporal processing.
Token shift or time-shift mixing (the diagonal arrows in Figure 3) also helps the model adapt to temporal data. By performing linear interpolation between the current input and the input from the previous time step, the model naturally aggregates and gates information in the input channels.
Experimental Results
The focus of the experiments is to answer the following questions:
-
RQ1: Is RWKV competitive with quadratic transformer architectures when the number of parameters and the number of training tokens are equal?
-
RQ2: Does RWKV still maintain competitive capabilities when the number of parameters is increased?
-
RQ3: When RWKV is trained on context lengths that open-source quadratic transformers cannot efficiently handle, does increasing RWKV’s parameters lead to better language modeling loss?
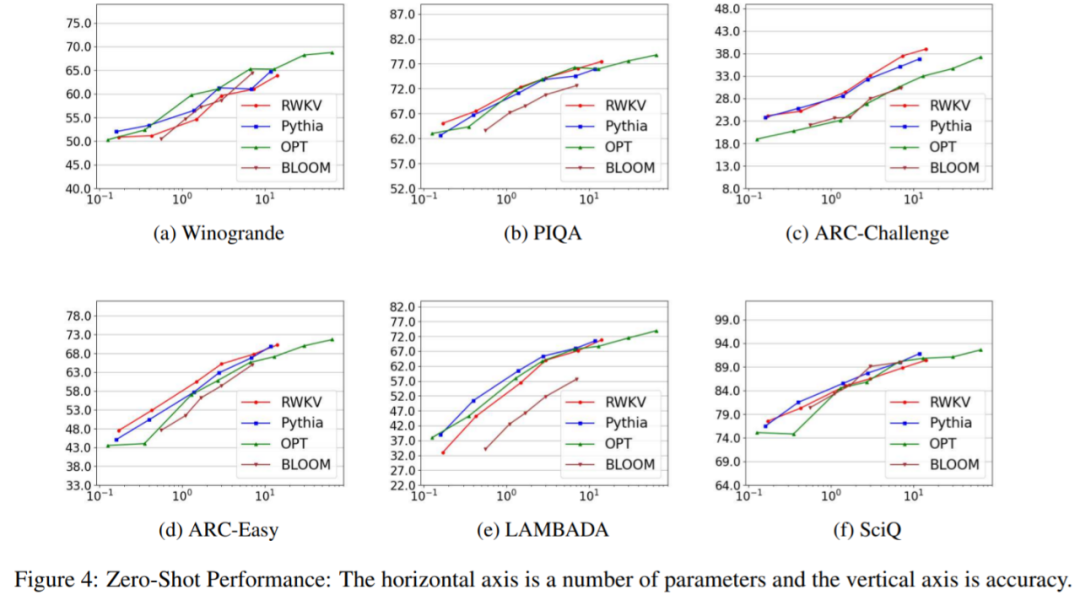
First, to answer RQ1 and RQ2, as shown in Figure 4, RWKV is competitive with open-source quadratic complexity transformer models Pythia, OPT, and BLOOM across six benchmarks (Winogrande, PIQA, ARC-C, ARC-E, LAMBADA, and SciQ). RWKV even outperformed Pythia and GPT-Neo in four tasks (PIQA, OBQA, ARC-E, and COPA).
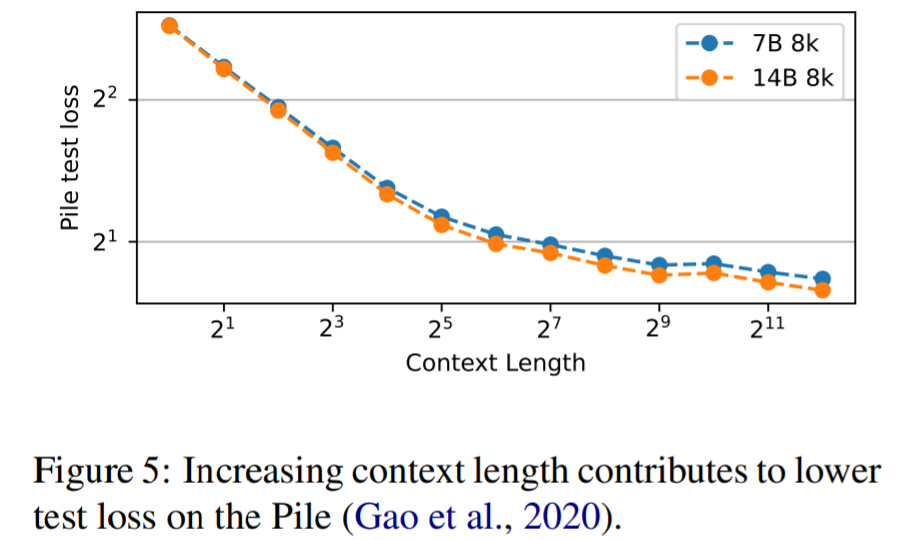
For RQ3, Figure 5 shows that increasing context length leads to lower test loss on the Pile, indicating that RWKV can effectively utilize longer context information.

© THE END
For reprints, please contact this public account for authorization
Submissions or inquiries: [email protected]