Introduction
Today I would like to share a Perspective paper published in October 2023 in Nature Review Neuroscience by Daniel Durstewitz, Georgia Koppe, and Max Ingo Thurm from Heidelberg University, Germany. The title of the paper is Reconstructing computational system dynamics from neural data with recurrent neural networks.
This article focuses on data-driven reconstruction of neural dynamical systems. It first introduces the basic background of neural dynamical systems and the prerequisites for reconstructing neural dynamical systems using RNNs, describes several different RNN models (Reservoir, Echo State Machines, NeuralODE, SINDy, etc.), and compares the training, evaluation, and performance validation methods of different RNN models, as well as how to explain RNN models as much as possible in the context of neuroscience.
TL;DR:
In the past, computational models in neuroscience were often represented in the form of differential equations, falling under the study of dynamical systems theory (DST), which provides mathematical tools for neural computational models. Recently, machine learning tools such as recurrent neural networks (RNNs) have begun to be used for modeling neural dynamical systems, simulating the nonlinear dynamics of neural and behavioral processes through the underlying systems of differential equations. RNN models can be used to train brain neural activities under recognition tasks in humans and animals, and RNNs can also be used to directly fit neural data, such as physiological and behavioral data, thus directly inheriting the temporal and geometric characteristics within the data. The approach of using RNNs to simulate neural data from animals and humans in experiments is called dynamical system reconstruction. This article will introduce the background, conditions, and methods for using RNNs for dynamical system reconstruction.
01
Article Background
The realization of cognitive functions is related to neural dynamics:
Theoretical neuroscience suggests that computations in the nervous system can be described based on potential nonlinear system dynamics. On one hand, most physical or biological processes can be represented by differential or difference equations; on the other hand, dynamical systems are computationally universal and can operate on any computer. Therefore, dynamical systems theory (DST) provides a mathematical language for understanding physiological processes in the brain as well as the processes of information processing and computation. Thus, we can connect different levels of the nervous system by interpreting biochemical and physical mechanisms to produce network dynamics, and conversely, how network dynamics achieve computation and cognitive operations. However, until the past 5-10 years, most studies have struggled to directly evaluate the characteristics of dynamical systems (DS) from neural time series recordings.
DS Reconstruction:
01
Article Background
The realization of cognitive functions is related to neural dynamics:
Theoretical neuroscience suggests that computations in the nervous system can be described based on potential nonlinear system dynamics. On one hand, most physical or biological processes can be represented by differential or difference equations; on the other hand, dynamical systems are computationally universal and can operate on any computer. Therefore, dynamical systems theory (DST) provides a mathematical language for understanding physiological processes in the brain as well as the processes of information processing and computation. Thus, we can connect different levels of the nervous system by interpreting biochemical and physical mechanisms to produce network dynamics, and conversely, how network dynamics achieve computation and cognitive operations. However, until the past 5-10 years, most studies have struggled to directly evaluate the characteristics of dynamical systems (DS) from neural time series recordings.
02
Article Content
Dynamical Systems Theory DST:
Here we will provide a more detailed introduction to DST technology and its applications in neuroscience.
DST provides a universal mathematical language that can be applied to any system that evolves over time and space and can be described by a set of differential (in continuous time) or recursive (in discrete time) equations that provide a mathematical representation of the system under study. DST helps us explain and understand some intrinsic properties of natural systems, such as under what conditions certain phenomena (e.g., convergence to equilibrium states, jumping between different stable states, chaotic behavior, oscillations, etc.) occur, and how these phenomena are regulated, generated, or destroyed.
One important concept in DST is the state space or phase space, as shown in Figure 1. For a bivariate single-neuron dynamical model, a point in its state space indicates the current values of voltage and refractory period. For a neural population model, a point in its state space represents the instantaneous firing rates of excitatory and inhibitory neuronal populations.
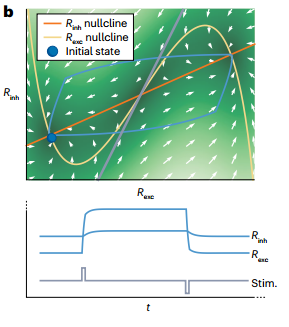
Figure1: State space and vector field of the Wilson–Cowan neural population model
A classic method for reconstructing trajectories directly from time series data is temporal delay embedding. We first assume that a time series scalar x obtained from the DS is available. Typically, xt is obtained through some recording device. At time t, some function of the unknown DS state y is x=h(y(t)). The unknown state vector y that causes our observation may be some biophysical quantity, such as the membrane potentials of all neurons, or a more abstract quantity that thoroughly describes the potential DS. Based on the measurement xt, by connecting the observed variables x at different lag times, we can form a time delay vector,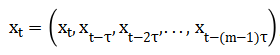 , where m is the embedding dimension. The mechanism of forming these delayed embedding vectors from time series is called delay coordinate mapping.
, where m is the embedding dimension. The mechanism of forming these delayed embedding vectors from time series is called delay coordinate mapping.
One significant mathematical fact contained in the delay embedding theory is that if the embedding dimension m is sufficiently large, the trajectories reconstructed in the space of delayed coordinate vectors will represent the original trajectories in a 1:1 manner. In this case, all original topological properties will be preserved, resulting in the reconstructed state space. Here, topological preservation means that certain continuous deformations of the original state space are still allowed.
In DS reconstruction, once trained on empirical data, these models will generate trajectories with topological and geometric structures in state space that correspond to the long-term temporal characteristics of the real DS. The most popular model for achieving this goal is RNN (as shown in Figure 2 process). Over the past few decades, various RNN architectures have existed, some representing discrete time, while others represent continuous time.
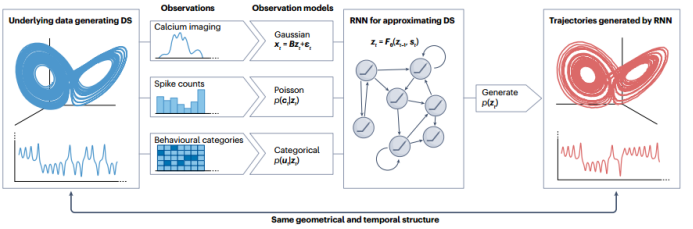
Figure 2: RNN-based dynamical system reconstruction
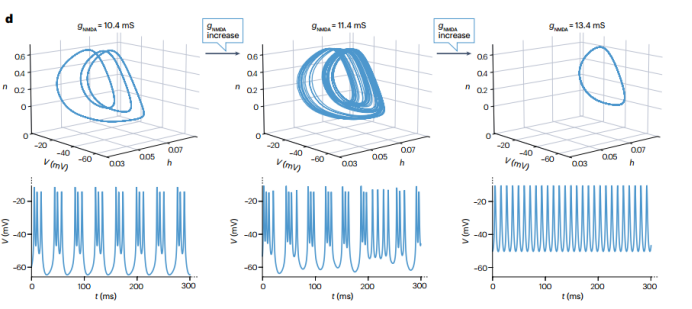
Figure 3: Slow oscillations driven by rapid spikes
Long Short-Term Memory (LSTM) networks were the first architecture to address this issue by integrating a protected “working memory” buffer, allowing the loss gradient to remain approximately constant (see Figure 4).
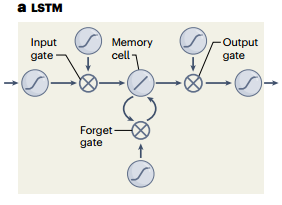
Figure 4: LSTM training process
Gated Recurrent Units (GRUs) are a simplified LSTM structure and have become widely adopted as an alternative to LSTMs. Recent architectures consider coupled or independent oscillators that can stably maintain information without bias. Another recent study aims to maintain the structural simplicity of the variants by applying specific constraints on parameters or by applying “soft constraints” in the loss function to gently push the parameters into a state of stable loss gradients during training, preventing uncontrollable loss gradient explosions.But the NCC lab would like to remind everyone that the DS reconstruction problem is actually different from classical machine learning problems. Scholars designing solutions for DS reconstruction often also consider classical machine learning applications, such as prediction or sequence-to-sequence regression; therefore, these architectures do not necessarily make RNNs more suitable for DS reconstruction. For chaotic systems, gradient explosion is theoretically unavoidable, as it results from trajectories that diverge exponentially in the system. Even in most complex biological or physical systems, chaotic dynamics are the norm rather than the exception.
Figure 5: The explosion of a three-variable minimal biophysical NMDA-modulated bursting neuron model
Reservoir Computers and Echo State Machines are another clever RNN design that is popular in DS reconstruction, initially introduced as a computationally efficient alternative to classic RNNs. They consist of a large pool or “reservoir” of nonlinear units with fixed network connections. Training is performed only by adjusting the linear mapping of the reservoir to a layer of linear readout units fed back to the reservoir, thus providing the desired output for the network. Because the mappable reservoir is linear, the learning of these systems is very fast and is not affected by gradient explosion and vanishing issues. However, because they rely on a fixed large reservoir, it is not particularly clear whether they are genuinely performing DS reconstruction or merely predicting DS. Reservoir computers and echo state machines are also quite complex and high-dimensional, making them difficult to analyze as models of the underlying DS.
Most RNNs operate at discrete time steps but typically assume that the underlying DS evolves in continuous time and space. Therefore, continuous-time RNNs can better approximate the vector field of the observed DS, which is estimated through numerical differences along the observed time series using simple feedforward neural networks. This feedforward neural network is then reshaped into an RNN defined by differential equations. Neural Ordinary Differential Equations are essentially an extension of this idea, using deep feedforward neural networks reshaped into RNNs to approximate vector fields. Neural ordinary differential equations are a powerful tool for reconstructing observed DS in low dimensions and naturally extend to spatially continuous systems, such as dendrites. Due to their continuous time representation, neural ordinary differential equations can naturally handle observations that occur at irregular intervals, as they do not rely on discretizing time into equal binaries. Neural ordinary differential equations also easily allow the incorporation of prior domain knowledge in the form of known differential equations, such as in physics-based neural networks. However, as it stands, training neural ordinary differential equations seems to be more tedious, as they depend on numerical integration techniques to solve differential equations and loss gradients.
In contrast to RNNs, a more elegant idea is the sparse identification of nonlinear dynamical systems (SINDy), which uses a large basis function library to fit the observed DS, providing a degree of interpretability, as seen in Figure 6. SINDy is similar to LASSO regression, selecting a small number of functions from its large basis function library while forcing all other regression coefficients to be zero (L1 regularization to make it sparse). If the basis function library contains the correct terms that naturally describe the studied DS (e.g., if the DS equation consists of polynomial terms and the basis function library also contains the correct polynomials), SINDy is fast and highly accurate. However, if we cannot establish a suitable basis function library based on prior knowledge, SINDy often fails to converge to the correct solution. As in many empirical scenarios, we may not know the precise DS equations at all.
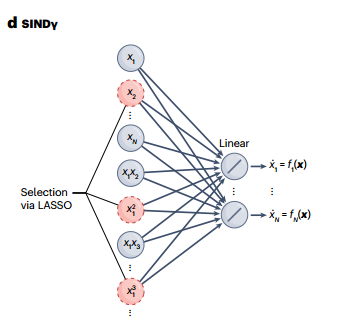
Figure 6: Sparse identification of nonlinear dynamical systems (SINDy)
Enhancing RNN Performance with Autoencoders:
Typically, the interest lies in facilitating DS learning and interpretability with the lowest dimensional dynamical representation or appropriate coordinate transformations. This can be achieved by embedding SINDy or any RNN into an autoencoder architecture (as shown in Figure 7). An autoencoder consists of a deep encoder and a deep decoder. The encoder network typically projects the observed data into a much lower-dimensional latent space configured to possess certain desired properties, and then the decoder recovers the original data from the latent representation. By combining this autoencoder with the DS reconstruction model and jointly training using a combined loss function, a latent model most suited for learning potential dynamics can be constructed.
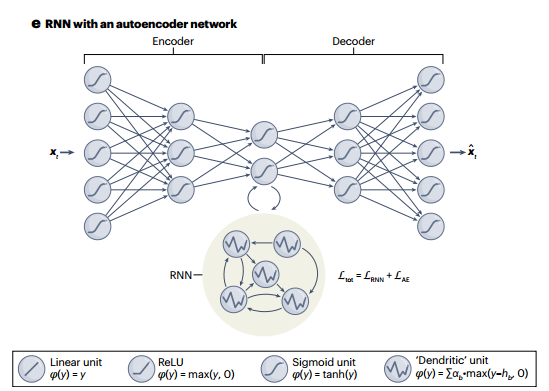
Figure 7: Embedding models into autoencoder architecture
This latent model provides a means for generating a holistic probability distribution of potential state spaces and parameters. Probabilistic DS reconstruction models also naturally explain various statistically recorded but different data patterns simultaneously. For example, neuroscience experiments may involve Poisson-type spike count data from many neurons. By connecting RNNs to different modality-specific decoder models, these models can be integrated into the same latent DS model, capturing the unique statistical characteristics of the three distinct data modalities observed. This establishes direct connections between different data patterns within a shared latent space, which can reveal relationships between neural trajectories, DS objects, and behavioral choice processes.
Analysis and Interpretation of RNNs::
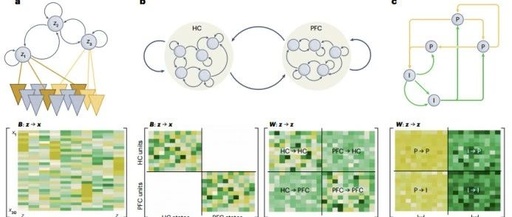
First, the parameters of latent RNNs reflect certain physiological or anatomical characteristics of the latent DS, such as connectivity between neurons or brain regions (as shown in Figure 8).
Second, latent RNNs serve as substitutes for the dynamical processes of data generation, providing unprecedented interpretability and insights into the underlying computational mechanisms: DST tools can be used to reveal the internal workings of the model in detail.
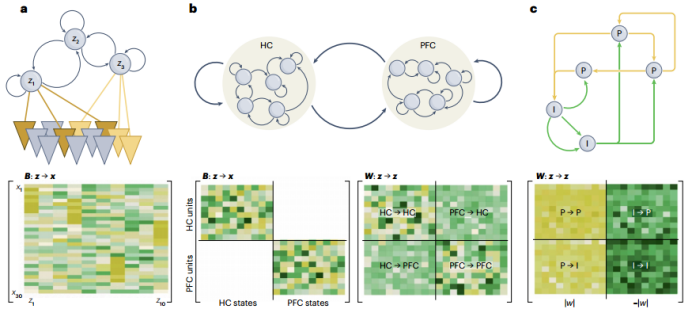
Figure 8: Evaluating connectivity between neurons or brain regions using RNNs
However, the analysis of DS largely depends on the dynamical accessibility and interpretability of the ML–AI models. If the mathematical setup of the RNNs used is relatively complex, such as in LSTMs or neural ordinary differential equations, approximate numerical methods will be needed to find the dynamical objects and structures of interest. Thus, many ideas that make ML–AI models interpretable in the DS sense are based on some form of local linear dynamics, as linear models are easier to handle, understand, and analyze. However, from a global perspective, a suitable DS model still needs to be nonlinear; otherwise, it will not produce phenomena such as limit cycles or chaos. Further enhancing interpretability can be achieved by discovering low-dimensional DS representations, for example, by improving the expressiveness of individual network units or jointly training with autoencoders to extract low-dimensional DS. Equally important are the analytical tools that connect the structure and dynamics of RNNs to computational and task performance; computational neuroscience has made significant progress in this area in recent years. Therefore, a particular challenge in the field of DS reconstruction is to design simple yet mathematically manageable models with strong expressive power.
03
Future Extensions
This article also presents the problems that need to be addressed and the directions that need to be tackled in this field:
1. First, the nervous system is highly dimensional. Modern neural recording technologies typically provide hundreds or thousands of simultaneous time series observations. Even so, this still represents only a small portion of all the dynamical variables in the biological substrate, for example, there are billions of neurons in a tiny mouse brain, not to mention all the cellular and molecular processes in the human brain. It cannot be ensured that all dynamically relevant variables are observed. How to infer the multi-scale dynamical system of the complete brain from different scales of partially observed neural data is a direction that needs to be tackled in the future.
2. Moreover, neural recording technologies often only represent block signals that need to be processed, usually providing filtered versions of the variables of interest or producing variables that may be highly non-Gaussian or even discontinuous. Even in principle, it is unclear how much detailed information about the potential dynamics can be retrieved from such observational data. We cannot determine to what extent different types of data preprocessing weaken or enhance the effectiveness of DS reconstruction.
3. Another significant challenge faced by DS reconstruction algorithms is that neuroscience data is often non-stationary and the observation process injects extra noise. Slow changes in the subject’s physical, motivational, or emotional states can affect the collection of neural data. The slow drift of parameters in the nervous system often leads to various types of complex bifurcations. Therefore, how to control or eliminate this additional complexity (non-stationary, bifurcations caused by noisy data) in DS reconstruction is an important research direction.
[Discussion in NCC lab]:
This article also proposes some solutions, such as explicitly designing DS reconstruction methods that map processes across multiple time scales may be helpful, but the choice of variables often only holds significance for specific variables. For example, there are many strong nonlinearities and higher-order characteristics in the nervous system, and heterogeneity of biophysics and synapses can easily lead to highly chaotic activity. Point attractors are often the result of averaging over faster time scales that dominate those based on chaos in many RNN-based analyses, but the latter may also be computationally relevant.
More generally, to date, most DS descriptions in neuroscience have focused on very simple DS objects, such as linear attractors or limit cycles. As different time and spatial scales are traversed, and as neuroscience continues to delve into more complex behaviors and decision-making in natural environments, there is a need to introduce more advanced DS theories and tools, including modeling of the direct problem of dynamical systems, solving inverse problems, evaluating reconstruction performance, controlling dynamical systems, and so on.
The neural dynamical models obtained through DS reconstruction can not only utilize modern powerful ML/AI methods for data fitting and system identification but can also conceptually integrate representations of neural dynamics, latent states, and observational behaviors across different spatiotemporal scales within neural computational theory. The potential brought about by data-driven DS reconstruction, along with the rich analytical tools provided by DST, may one day change our understanding of brain functions.
References
[1] Durstewitz, Daniel, Georgia Koppe, and Max Ingo Thurm. “Reconstructing computational system dynamics from neural data with recurrent neural networks.” Nature Reviews Neuroscience 24.11 (2023): 693-710.
[2] Rinzel, J. & Ermentrout, G. B. in Methods of Neuronal Modeling: From Synapses to Networks (eds Koch, C. & Segev, I.) 251–292 (MIT Press, 1998).
[3] Izhikevich, E. M. Dynamical Systems in Neuroscience (MIT Press, 2007).
[4] Yu, B. M. et al. Extracting dynamical structure embedded in neural activity. In Proc. 18th Advances in Neural Information Processing Systems (eds. Weiss, Y., Schölkopf, B. & Platt, J.) 1545-1552 (MIT Press, Vancouver, 2005).
[5] Kramer, D., Bommer, P. L., Tombolini, C., Koppe, G. & Durstewitz, D. Reconstructing nonlinear dynamical systems from multi-modal time series. In Proc. 39th International Conference on Machine Learning (eds Chaudhuri, K. et al.) 11613–11633 (PMLR, 2022).