
Today, let’s take a look at a classic agent work from Princeton, Google Brain, and others published at 2023 ICLR – ReAct.
Project address: https://github.com/ysymyth/ReAct?tab=readme-ov-file
Research motivation: Although existing large language models excel in language understanding and interactive decision-making, their reasoning and action capabilities are often studied separately. Currently, the most famous work on reasoning with language models is Chain-of-Thought (CoT), which reveals that large language models can formulate their own “thinking programs” to solve problems. However, CoT and other similar methods mainly focus on isolated, fixed reasoning without integrating the model’s behavior and its corresponding observations into a coherent input stream.
Thus, ReAct is proposed, a new paradigm based on prompts, aimed at integrating reasoning and action within language models to achieve general task resolution.
ReAct prompts LLMs to alternately generate task-related language reasoning trajectories and actions, enabling the model to perform dynamic reasoning to create, maintain, and adjust high-level plans of action (reasoning to action), while interacting with external environments (like Wikipedia) to incorporate additional information into reasoning (action to reasoning).
Let’s first visually compare ReAct with several other prompting methods. The figure below shows the comparison of four different prompting methods in task resolution: standard prompting, reasoning only (Chain-of-Thought, CoT), action only (Act-only), and the combined reasoning and action ReAct method. Specifically:
-
In HotpotQA question answering, the ReAct method constructs a more understandable task resolution path by alternating between thinking and acting. It not only overcomes common hallucinations and error propagation issues in chain-of-thought reasoning but also enables the model to provide more accurate answers based on external information through interaction with a simple Wikipedia API. -
For complex environmental interactive decision-making tasks in the ALFWorld game, the ReAct method shows advantages over action-only methods. In this environment, the agent needs to navigate and interact with the simulated home environment through text actions to achieve high-level goals. For example, in one scenario, the agent needs to check all possible locations (like tables, shelves, or closets) to find an item (like a lamp). ReAct allows the language model to leverage its pre-trained common sense knowledge to determine where common household items might be located.

1
Method Introduction

In simple terms, the core of ReAct is to achieve more efficient and reliable task resolution through the synergy of reasoning and action, combining flexible thinking generation and interaction with external environments.
In Figure 1, we can see that a ReAct-compliant action process includes multiple iterations of Thought-Act-Obs, which is the repeated process of thinking – acting – observing/analysing.
-
Thought: Reflects the thinking process of the LLM model, demonstrating the role of the LLM’s “brain”. The LLM generates the actions needed for this iteration based on input or external environment feedback. For example:
“The Apple remote was initially designed to control the Front Row media center application, so next I need to search for the Front Row application…”
-
Act: The specific action taken based on the results of thinking, which ultimately reflects in the use of some external tool to interact with the external environment and obtain results. For example:
“Use the Google search engine API to search for Front Row”
-
Obs: Feedback information obtained from external actions, used for the LLM to make the next action decision. For example:
“Could not find Front Row, similar information includes Front Row (Software)…”
Through this iterative process, the task is ultimately completed.
Working Principle
ReAct expands the action space of agents by 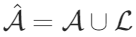 where L is the language space, and
where L is the language space, and 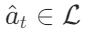 represents an action in the language space, called thought or reasoning trajectory. Such actions do not affect the external environment, thus there is no feedback from the environment. Instead, thinking
represents an action in the language space, called thought or reasoning trajectory. Such actions do not affect the external environment, thus there is no feedback from the environment. Instead, thinking 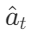 reasons through the current context
reasons through the current context 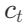 to combine useful information and update the context
to combine useful information and update the context 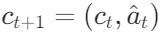 to assist the agent in internal thinking, thus supporting subsequent reasoning or action. This allows the agent to decompose task goals, create action plans, inject common sense knowledge, track progress, handle exceptions, etc.
to assist the agent in internal thinking, thus supporting subsequent reasoning or action. This allows the agent to decompose task goals, create action plans, inject common sense knowledge, track progress, handle exceptions, etc.
As shown in Figure 1, there may be multiple useful thoughts, such as decomposing task goals and creating action plans (Figure 1(2b), Action 1; Figure 1(1d), Thought 1), injecting common sense knowledge related to task resolution (Figure 1(2b), Action 1), extracting important parts from observations (Figure 1(1d), Thought 2, 4), tracking progress and transforming action plans (Figure 1(2b), Action 8), handling exceptions and adjusting action plans (Figure 1(1d), Thought 3), etc.
Applications and Advantages
ReAct does not require fine-tuning of model parameters and generates specific domain actions and free-form language thinking through a few sample context examples, making it very friendly for independent developers. For tasks that primarily rely on reasoning, ReAct alternately generates thinking and actions, forming a task resolution path composed of multiple Thought-Act-Obs steps. For decision-making tasks that may involve a large number of actions, ReAct allows the language model to decide when to generate thoughts, ensuring that thoughts only appear where most relevant.
Characteristics of ReAct:
-
Intuitive and easy to design: Designing ReAct prompts is very simple; human annotators only need to add their thinking processes based on actions. -
Universal and flexible: Due to the flexibility of the thinking space and the diversity of the thinking-action appearance format, ReAct is suitable for a variety of tasks with different action spaces and reasoning needs, including Q&A, fact verification, text games, and web navigation. -
Superior and robust performance: Even learning from a small number of context examples, it can outperform methods that rely solely on reasoning or action. -
Human-consistent and controllable: Provides an explainable decision-making process, allowing humans to check and correct the agent’s behavior in real-time.
2
Knowledge-Intensive Reasoning Tasks

In knowledge-intensive reasoning tasks, ReAct demonstrates how to enhance model performance by combining reasoning and action. Specifically, ReAct can retrieve information to support reasoning by interacting with the Wikipedia API and use reasoning to determine what to retrieve next, thus achieving a synergy of reasoning and action.
Experimental Setup
Dataset Selection:
-
HotPotQA: A multi-hop question answering benchmark that requires reasoning across two or more Wikipedia paragraphs. -
FEVER: A fact verification benchmark where each statement is labeled as SUPPORTS, REFUTES, or NOT ENOUGH INFO based on the existence of supporting Wikipedia paragraphs.
In both tasks, the model only receives the question/statement as input, cannot access supporting paragraphs, and must rely on its internal knowledge or retrieve knowledge through interaction with the external environment to support reasoning.
Action Space Design:
To support interactive information retrieval, a simple Wikipedia web API was designed, containing the following three types of actions:
-
search[entity]: Returns the first 5 sentences if a corresponding entity’s Wikipedia page exists; otherwise, suggests the top 5 similar entities in the search engine. -
lookup[string]: Returns the next sentence in the page containing the string, simulating the Ctrl+F function in a browser. -
finish[answer]: Ends the current task with an answer.
Baseline Comparisons:
To evaluate the effectiveness of ReAct, multiple baseline prompts were constructed: Standard Prompt: Removes all thoughts, actions, and observations. Chain-of-Thought Prompt (CoT): Removes actions and observations, serving as the baseline for reasoning only. Self-consistency Baseline (CoT-SC): Samples multiple CoT trajectories and adopts the majority answer. Act-only Prompt: Removes thoughts from the ReAct trajectory, similar to WebGPT.
Combining Internal and External Knowledge: Experimental observations indicated that ReAct’s problem-solving process is more factual and concrete, while CoT is more accurate in constructing reasoning structures but is more susceptible to hallucinations. Therefore, a method combining ReAct and CoT-SC is proposed: (1) ReAct → CoT-SC: When ReAct fails to return an answer within a given step, it falls back to CoT-SC. (2) CoT-SC → ReAct: When internal knowledge is insufficient to confidently support the task, it falls back to ReAct.
Fine-tuning: Due to the challenges of manually annotating reasoning trajectories and actions on a large scale, a bootstrapping method is used to fine-tune a smaller language model (PaLM-8/62B) with 3000 correct answer trajectories generated by ReAct to decode conditional trajectories based on input questions/statements.
Results
ReAct vs. Act
Table 1 shows the results of HotpotQA and FEVER using PaLM-540B as the base model with different prompting methods. From the table, it can be seen that ReAct outperforms Act on both tasks, especially excelling in synthesizing final answers (as shown in Figure 1(1c-d)). This indicates the value of reasoning guiding action and the importance of alternately generating thinking, action, and observation steps.
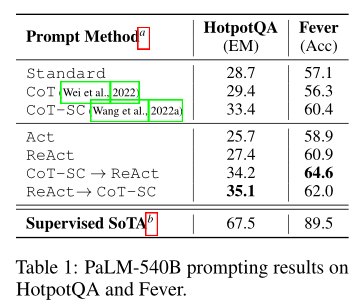
ReAct vs. CoT
Although ReAct performs excellently in some aspects, its comparison with Chain-of-Thought (CoT) reveals some interesting patterns:
-
Performance on FEVER: ReAct significantly outperforms CoT on FEVER (60.9% vs. 56.3%), which may be due to the task characteristics of FEVER – SUPPORTS/REFUTES statements often differ only slightly. In this case, retrieving accurate and up-to-date knowledge through action is particularly important.
-
Performance on HotpotQA: ReAct slightly lags behind CoT on HotpotQA (27.4% vs. 29.4%). To better understand the behavioral differences between the two, researchers randomly sampled 50 correct and incorrect trajectories (judged by EM) and manually annotated their success and failure patterns (totaling 200 examples), with the following results:
Hallucination Issues:One serious issue with CoT is hallucination, leading to a much higher false positive rate than ReAct (14% vs. 6%) and becoming its primary failure mode (56%). In contrast, ReAct’s problem-solving trajectories are more fact-based and credible, benefiting from access to external knowledge bases.
The Impact of Structural Constraints: Although alternating reasoning, action, and observation steps improve ReAct’s factuality and credibility, this structure also reduces its flexibility in constructing reasoning steps, leading to a higher reasoning error rate than CoT. A common error pattern is the model repeatedly generating previous thoughts and actions, failing to break out of the loop, which we classify as “reasoning errors”.
The Importance of Search Quality: For ReAct, retrieving useful knowledge through search is crucial. Non-informative searches (accounting for 23% of error cases) can disrupt the model’s reasoning, making it difficult to recover and reconstruct thinking. This may be an expected trade-off between factuality and flexibility, prompting the authors to propose a strategy that combines both methods.

-
Success (Success, defined as: correct reasoning trajectory and facts): Indicates that the model generated the correct reasoning trajectory and used the correct facts to answer the question. ReAct significantly outperformed CoT in this respect, with success rates of 94% and 86%, respectively. -
False Positive (False Positive, defined as: hallucinated reasoning trajectory or facts): Refers to the model generating a hallucinated reasoning trajectory or facts, leading to incorrect answers. ReAct has a lower false positive rate of 6%, while CoT has a false positive rate of 14%, indicating that CoT is more prone to hallucinations. -
Reasoning error (Reasoning error, defined as: incorrect reasoning trajectory (including failure to recover from repetitive steps)): Occurs when the model fails to correctly derive the path to solve the problem. ReAct has a higher reasoning error rate of 47%, while CoT is only 16%. This may be due to alternating reasoning, action, and observation steps improving factuality and credibility but reducing flexibility in constructing reasoning steps, causing the model to sometimes get stuck in repetitive loops. -
Search result error (Search result error, defined as: search results are empty or do not contain useful information): Occurs when the information retrieved by the model through the API is insufficient to support its reasoning. For ReAct, this type of error accounts for 23% of all error cases, emphasizing the importance of effective search. -
Hallucination (Hallucination, defined as: hallucinated reasoning trajectory or facts): Occurs when the model generates facts or reasoning that do not match reality. The hallucination problem with CoT is very serious, accounting for 56% of error cases, while ReAct completely avoids this situation, with a hallucination rate of 0%. -
Label ambiguity (Label ambiguity, defined as: prediction is correct but does not precisely match the label): Occurs when the model’s predicted answer is correct but fails to precisely match the given label. This situation exists in both ReAct and CoT, accounting for 29% and 28%, respectively. -
Table 2
ReAct + CoT-SC Prompting Effectiveness for LLMs
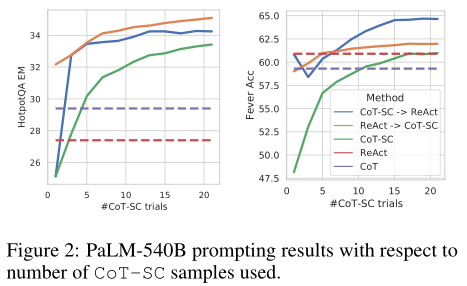
Table 1 also shows that the best prompting methods on HotpotQA and FEVER are ReAct → CoT-SC and CoT-SC → ReAct. Additionally, Figure 2 shows the performance of different methods when using different numbers of CoT-SC samples. Although the two ReAct + CoT-SC methods have their advantages in each task, they consistently and significantly outperform standalone CoT-SC across different sample sizes, achieving the performance of CoT-SC using only 3-5 samples compared to 21 samples. These results emphasize the value of appropriately combining internal and external knowledge in reasoning tasks.
Fine-tuning Effects
Figure 3 shows the effects of prompting/fine-tuning the four methods (Standard, CoT, Act, ReAct) on HotpotQA. When using PaLM-8/62B, ReAct performed the worst among the four methods due to the difficulty of learning reasoning and actions from context examples. However, after fine-tuning with only 3000 examples, ReAct quickly surpassed the other methods, becoming the best-performing method among the four:
-
The fine-tuned PaLM-8B ReAct outperformed all PaLM-62B prompting methods. -
The fine-tuned PaLM-62B ReAct outperformed all 540B prompting methods.
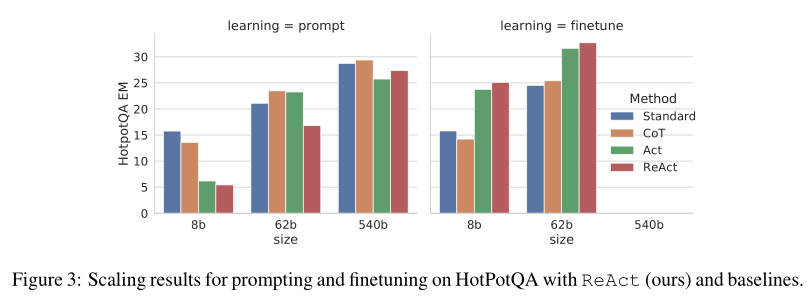
In contrast, fine-tuning Standard or CoT shows significantly lower performance than fine-tuning ReAct or Act, as the former essentially teaches the model to memorize (potentially hallucinatory) knowledge facts, while the latter teaches the model how to (reason and) access information through Wikipedia, a more general knowledge reasoning skill. Since all prompting methods still fall far short of the state-of-the-art in specific domains (Table 1), we believe using more manually crafted data for fine-tuning may be a better way to unlock ReAct’s potential.
3
Decision-Making Tasks

In decision-making tasks, researchers tested ReAct’s performance on two language-based interactive decision-making tasks: ALFWorld and WebShop. Both tasks involve complex environments requiring agents to operate over long periods with sparse rewards, necessitating reasoning to effectively act and explore.
ALFWorld
ALFWorld is a synthetic text game aimed at aligning with the embodied ALFRED benchmark (Shridhar et al., 2020a). It includes six types of tasks, each requiring agents to navigate and interact with a simulated home environment through text to achieve high-level goals (e.g., checking papers under a lamp). Specific features include:
-
Complexity: A task instance may contain over 50 locations and require expert strategies to solve in over 50 steps. -
Challenges: Requires agents to plan and track sub-goals and explore systematically (e.g., checking all tables one by one to find the lamp). -
Common Sense Knowledge: A built-in challenge is determining the possible locations of common household items (e.g., lamps may be on tables, shelves, or dressers), allowing LLMs to leverage their pre-trained common sense knowledge.
Experimental Setup:
Prompt Design: To prompt ReAct, researchers randomly annotated three trajectories for each task type from the training set, each containing sparse thinking to decompose goals, track sub-goal completion, determine the next sub-goal, and use common sense reasoning to identify the location and handling of items.
Evaluation: Following the method of Shridhar et al., evaluation was conducted on 134 unseen evaluation games under specific task settings. To improve robustness, 6 prompts were constructed through combinations of 2 annotated trajectories for each task type.
Baseline Comparison: Using BUTLER as a baseline, which is an imitation learning agent trained on
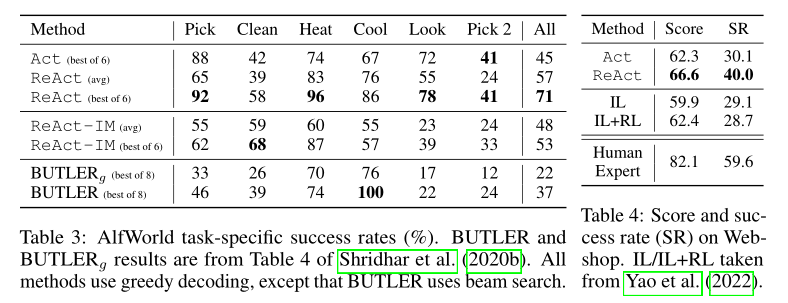
Results: ReAct significantly outperformed the action-only Act. The best ReAct trial achieved a 71% average success rate, significantly outperforming the best Act (45%) and BUTLER (37%) trials. Even the worst ReAct trial (48%) beat the best trials of both methods. The advantage of ReAct over Act is consistent across six controlled trials, with relative performance improvements ranging from 33% to 90%, averaging 62%.
WebShop
WebShop is an online shopping website environment containing 11,800 real-world products and 12,000 human instructions. This environment is characterized by a large amount of structured and unstructured text (such as product titles, descriptions, and options) and requires agents to purchase products through web interactions based on user instructions (e.g., “I’m looking for a nightstand with a drawer. It should have a nickel finish and cost less than $140”).
Evaluation Criteria: Evaluated on 500 test instructions through average scores (the average percentage of all expected attributes covered by the selected products) and success rates (the percentage of selected products that meet all requirements).
Experimental Setup:
Using action prompts, including search, select products, choose options, and purchase, while ReAct prompts also determine what to explore, when to buy, and which product options are relevant to the instructions through reasoning.
Compared an imitation learning (IL) method and an imitation + reinforcement learning (IL + RL) method, the latter of which underwent additional training on 10,587 training instructions.
Results: The single prompt Act performed comparably to IL and IL+RL methods. Through additional sparse reasoning, ReAct significantly improved performance, increasing the success rate by 10% over the previous best. Qualitatively, ReAct is more likely to bridge the gap between noisy observations and actions through reasoning, thereby identifying products and options relevant to the instructions.
The Value of Internal Reasoning and External Feedback
To demonstrate the differences between ReAct and previous works (like Inner Monologue, IM) and emphasize the importance of internal reasoning versus simple responses to external feedback, researchers conducted an ablation experiment using a thinking pattern composed of dense external feedback in the style of IM. The results showed:
ReAct vs. ReAct-IM: ReAct significantly outperformed the IM-style prompt (ReAct-IM) (53% vs. 53% overall success rate), consistently showing advantages in five out of six tasks. ReAct-IM often made errors in identifying when sub-goals were completed or what the next sub-goal should be due to a lack of high-level goal decomposition; additionally, many ReAct-IM trajectories struggled to determine the possible locations of items in the ALFWorld environment due to a lack of common sense reasoning. These shortcomings can all be addressed within the ReAct paradigm.
4
Conclusion

ReAct provides a powerful framework that enhances language models’ performance in complex tasks by combining reasoning and action. It not only improves the efficiency and accuracy of model problem-solving but also increases the transparency and controllability of its behavior. A very user-friendly AI application method, the next update will focus on the implementation of ReAct, a minimalist agent code implementation.
Please open in the WeChat client