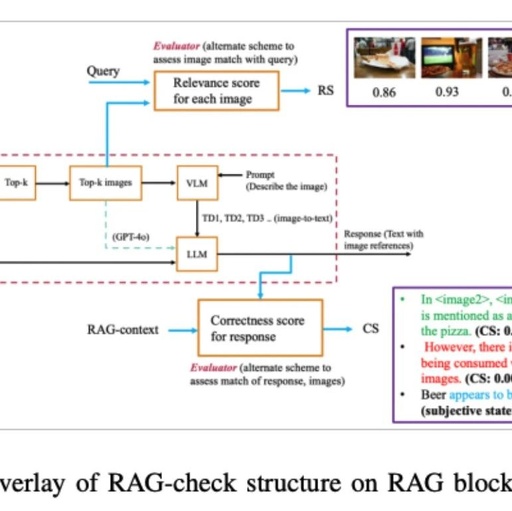
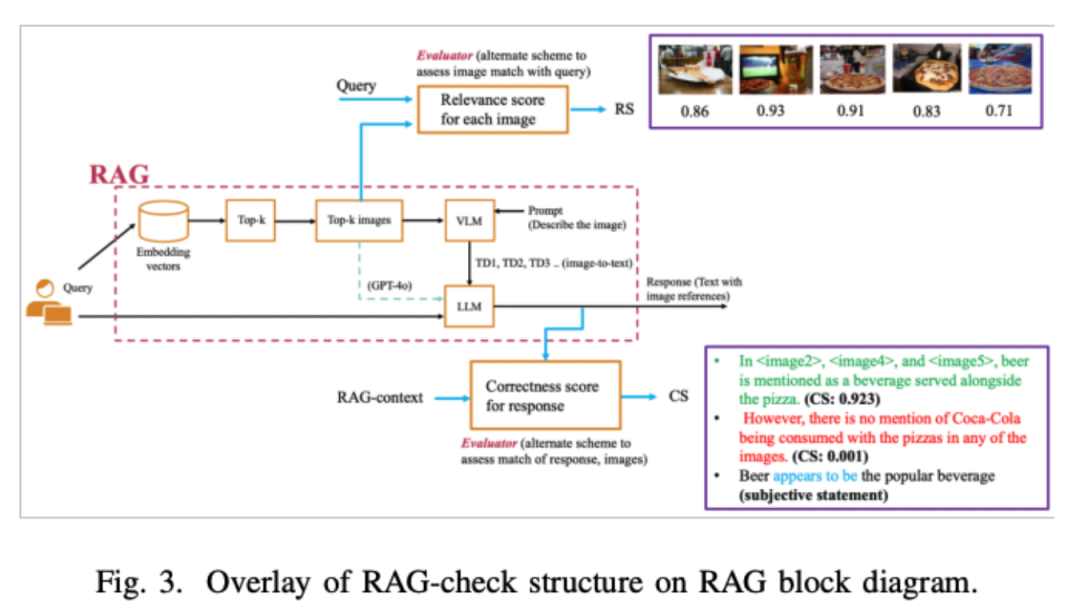
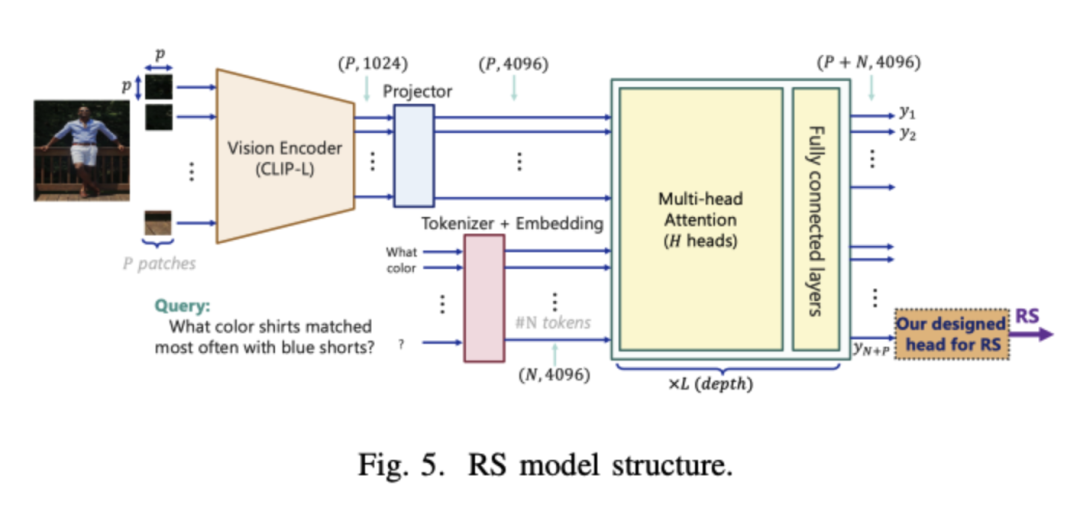
Large Language Models (LLMs) have made significant progress in the field of generative artificial intelligence, but they face the “hallucination” problem, which is the tendency to generate inaccurate or irrelevant information. This issue is particularly severe in high-risk applications such as medical assessments and insurance claims processing. To address this challenge, researchers from the University of Maryland and NEC Labs have proposed RAG-check, a comprehensive method for evaluating multimodal RAG systems, which includes three key components aimed at assessing the relevance and accuracy of retrieval results. This framework significantly enhances the performance evaluation of multimodal systems by introducing relevance scores and correctness scores, and it identifies GPT-4o as the most effective model for generating context, demonstrating the potential of unified multimodal language models in improving the accuracy and reliability of RAG systems.
Reference:
-
https://arxiv.org/abs/2501.03995
Give ascoreshare,like andwatch for the best experience~