R-CNN series object detection networks are the first series of networks in the field of object detection using deep learning, serving as a typical Two-Stage object detection network. This series includes R-CNN, Fast R-CNN, and Faster R-CNN, and as their names suggest, each generation is faster than the previous one, primarily because the characteristic of Two-Stage networks is high accuracy but slow speed. By the time the Faster R-CNN network was introduced, it had already achieved an end-to-end fully convolutional object detection network. Its author, Ross Girshick, became a member of Facebook’s Artificial Intelligence Research (FAIR) lab, which is part of the Detectron2 platform, and is continually working to optimize the R-CNN series algorithms.
(1) R-CNN
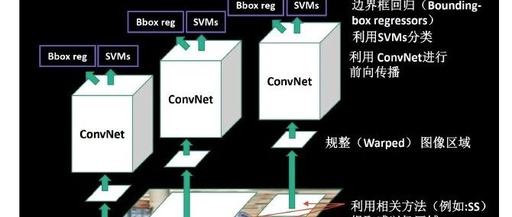
The R-CNN object detection network, where the letter R stands for Region, meaning area, is officially named Region Convolutional Neural Network. It appeared in 2014 and was the first deep learning algorithm to emerge in the field of object detection, marking a new chapter for deep learning in this domain, paving the way for subsequent series like YOLO. The structural logic of the R-CNN network is shown in the figure below.
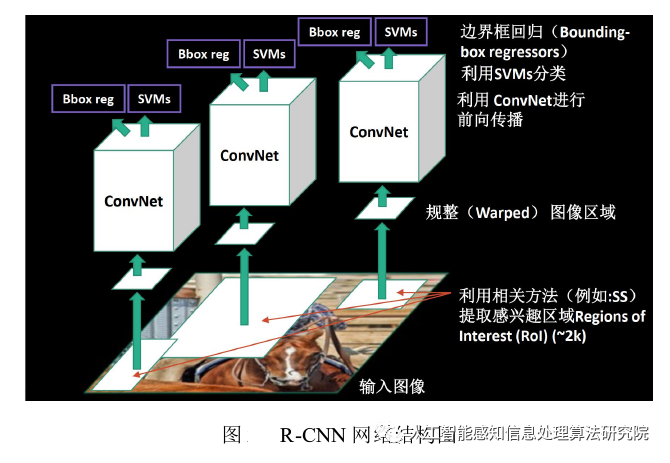
The data processing flow of the R-CNN network is as follows:
1) Input image.
2) Use the selective search method to generate multiple candidate boxes.
3) Input each candidate box into convolutional layers for feature extraction, commonly using networks like AlexNet or VGG.
4) Input the extracted features from step three into a series of SVM classifiers to determine and predict category information.
5) Finally, perform regression and correction on the classified candidate boxes to predict location information.
After introducing deep learning into the detection field, the detection rate on PASCAL VOC significantly improved from 35.1% to 53.7%. It has the following advantages:
1) The use of CNN for feature extraction provides insights for visual tasks, marking the end of the era where humans had to consider which features to extract.
2) Introduces the concept of transfer learning, using pre-trained models on large datasets and then fine-tuning on smaller datasets.
(2) Fast R-CNN
Following the R-CNN, the author released Fast R-CNN in 2015, optimizing the original network structure, improving detection speed, and reducing the spatial requirements for network training. The structural logic of the network is shown in the figure below.
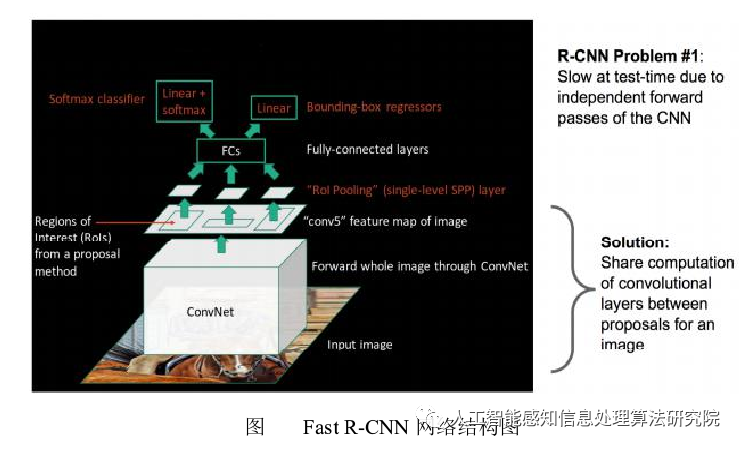
The data processing flow of Fast R-CNN is as follows:
1) Input image.
2) Use the selective search method to generate multiple candidate boxes.
3) Input the entire image into convolutional layers for feature extraction.
4) Find the corresponding candidate box regions on the feature map after convolution.
5) Convert the corresponding candidate box regions into fixed-size feature maps through ROI Pooling.
6) Input the feature maps into fully connected layers to generate feature vectors for classification and regression, obtaining category and location information, respectively.
The Fast R-CNN model has significantly improved compared to R-CNN, reducing training time to one-ninth and testing time to one-hundredth of the original, with a slight increase in testing accuracy, indicating the potential for real-time detection with the R-CNN series networks. It has the following advantages:
1) Softmax replaces SVM for classification, and classification and regression are performed together, reducing training and testing times.
2) The network structure is optimized by first inputting the entire image into the convolutional neural network for feature extraction, and then adding an RoI pooling layer to ensure the final feature map size is consistent, allowing the entire process to require only one fully connected layer, with classification and regression achieved through deep network methods, saving memory requirements.
(3) Faster R-CNN
In 2015, the team led by Kaiming He proposed a new algorithm, Faster R-CNN, which generates candidate boxes using a neural network approach, making it the first end-to-end object detection network, significantly increasing detection speed and winning at various visual competitions that year. The structural logic of the network is shown in the figure below.
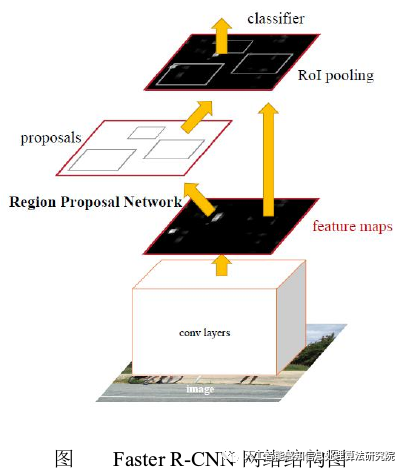
The data processing flow of Faster R-CNN is as follows:
1) Input image.
2) Input the entire image into convolutional layers for feature extraction.
3) RPN generates candidate boxes.
4) Find the corresponding candidate box regions on the feature map after convolution.
5) Convert the corresponding candidate box regions into fixed-size feature maps through ROI Pooling.
6) Input the feature maps into fully connected layers to generate feature vectors for classification and regression, obtaining category and location information, respectively.
The Faster R-CNN object detection network has greatly improved both speed and accuracy, winning multiple awards in various competitions that year. It has the following advantages:
1) Proposes the Region Proposal Network (RPN) method, using convolutional neural networks to generate candidate boxes, achieving an end-to-end network.
2) The CNN that generates proposal windows is shared with the CNN for object detection.
WeChat official account QR code

WeChat official account: Artificial Intelligence Perception Information Processing Algorithm Research Institute
Zhihu homepage: https://www.zhihu.com/people/zhuimeng2080