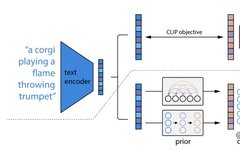

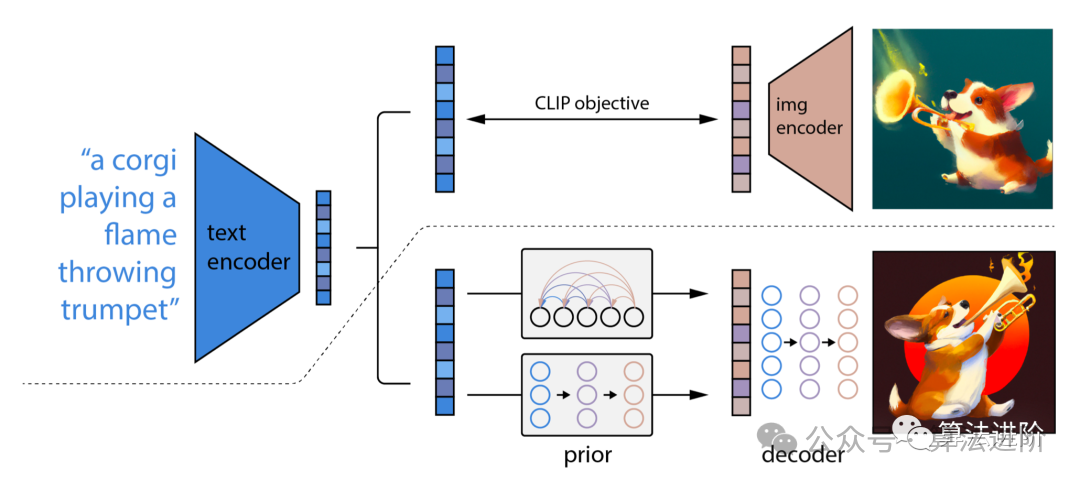
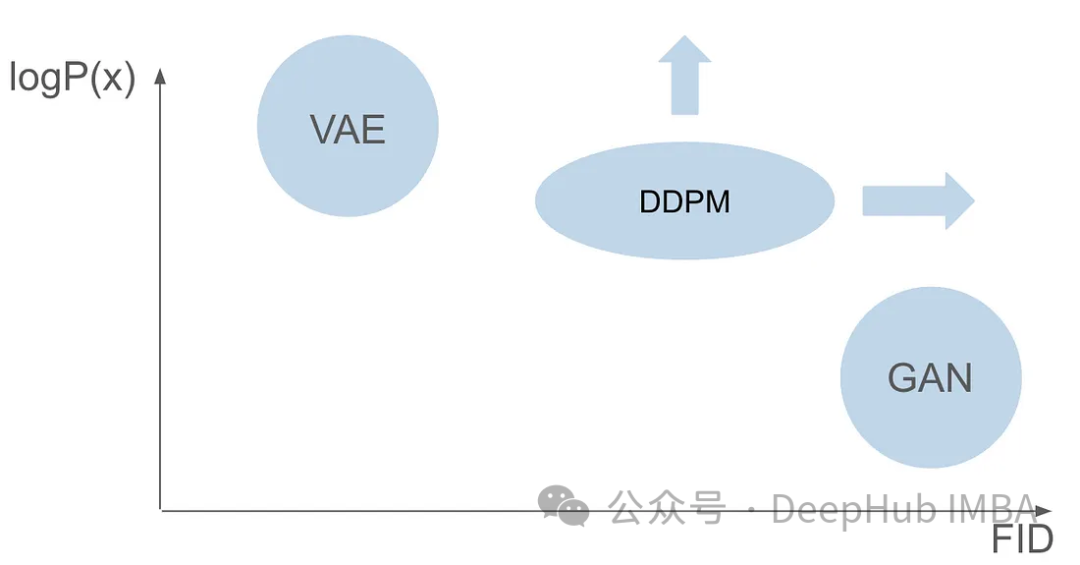
Diffusion Model DDPM

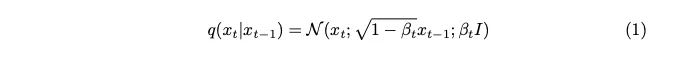
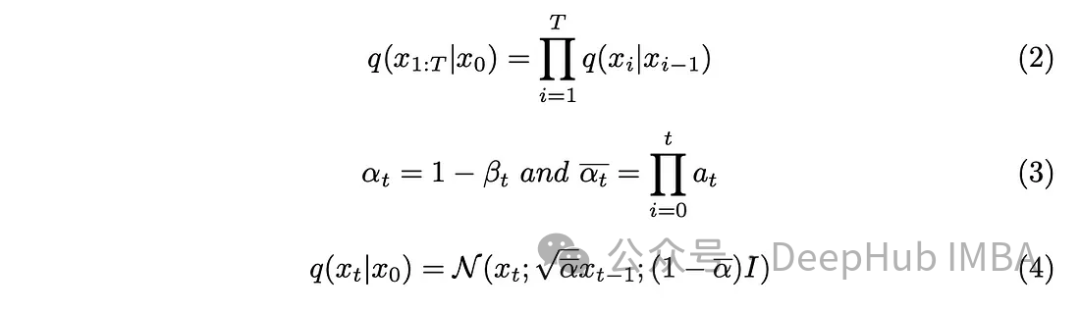


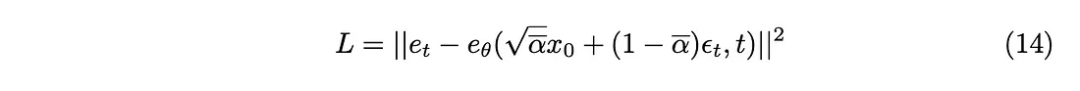


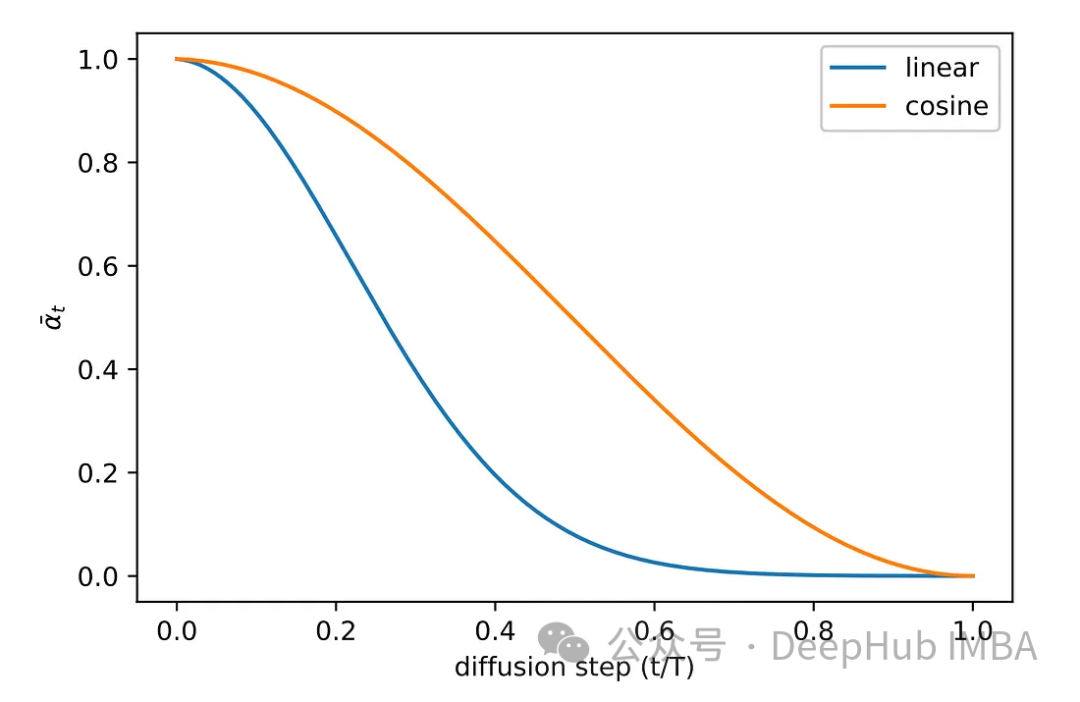
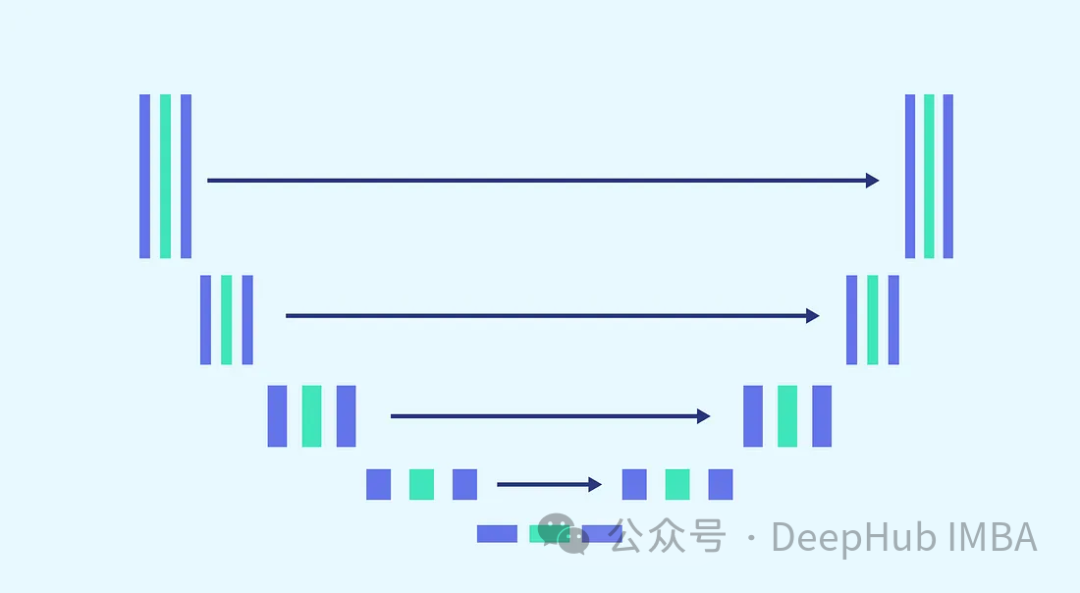
PyTorch Implementation of Diffusion Models
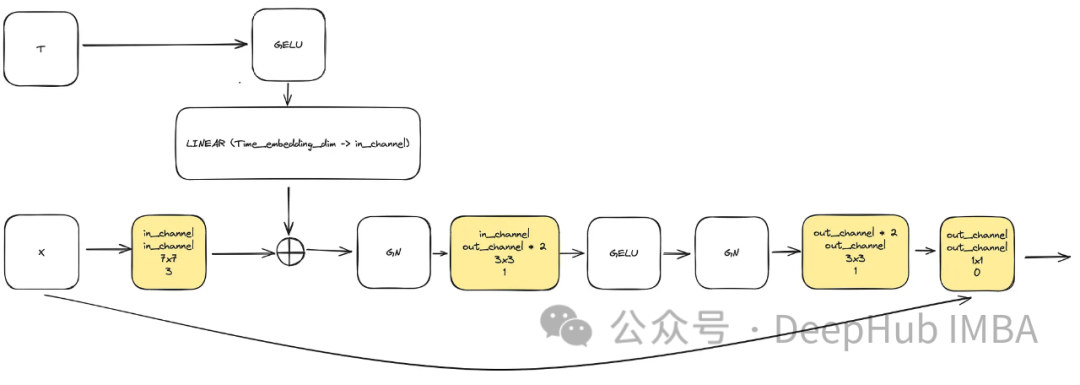
class ConvNextBlock(nn.Module):
def __init__(self,
in_channels,
out_channels,
mult=2,
time_embedding_dim=None,
norm=True,
group=8,
):
super().__init__()
self.mlp = (
nn.Sequential(nn.GELU(), nn.Linear(time_embedding_dim, in_channels))
if time_embedding_dim
else None
)
self.in_conv = nn.Conv2d(
in_channels, in_channels, 7, padding=3, groups=in_channels
)
self.block = nn.Sequential(
nn.GroupNorm(1, in_channels) if norm else nn.Identity(),
nn.Conv2d(in_channels, out_channels * mult, 3, padding=1),
nn.GELU(),
nn.GroupNorm(1, out_channels * mult),
nn.Conv2d(out_channels * mult, out_channels, 3, padding=1),
)
self.residual_conv = (
nn.Conv2d(in_channels, out_channels, 1)
if in_channels != out_channels
else nn.Identity()
)
def forward(self, x, time_embedding=None):
h = self.in_conv(x)
if self.mlp is not None and time_embedding is not None:
assert self.mlp is not None, "MLP is None"
h = h + rearrange(self.mlp(time_embedding), "b c -> b c 1 1")
h = self.block(h)
return h + self.residual_conv(x) class SinusoidalPosEmb(nn.Module):
def __init__(self, dim, theta=10000):
super().__init__()
self.dim = dim
self.theta = theta
def forward(self, x):
device = x.device
half_dim = self.dim // 2
emb = math.log(self.theta) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
emb = x[:, None] * emb[None, :]
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
return emb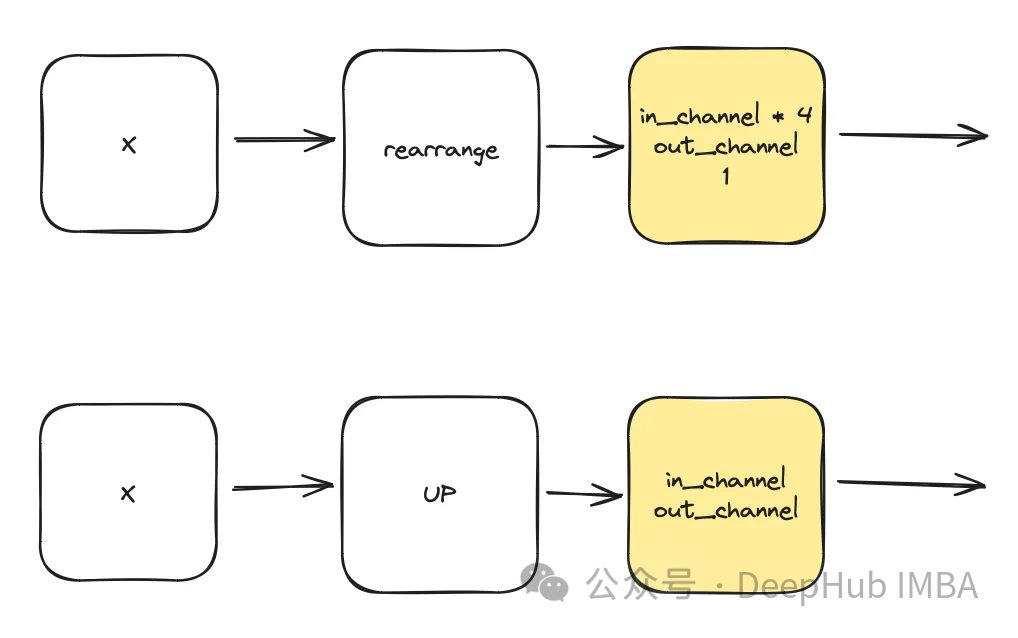
class DownSample(nn.Module):
def __init__(self, dim, dim_out=None):
super().__init__()
self.net = nn.Sequential(
Rearrange("b c (h p1) (w p2) -> b (c p1 p2) h w", p1=2, p2=2),
nn.Conv2d(dim * 4, default(dim_out, dim), 1),
)
def forward(self, x):
return self.net(x)
class Upsample(nn.Module):
def __init__(self, dim, dim_out=None):
super().__init__()
self.net = nn.Sequential(
nn.Upsample(scale_factor=2, mode="nearest"),
nn.Conv2d(dim, dim_out or dim, kernel_size=3, padding=1),
)
def forward(self, x):
return self.net(x)
sinu_pos_emb = SinusoidalPosEmb(dim, theta=10000)
time_dim = dim * 4
time_mlp = nn.Sequential(
sinu_pos_emb,
nn.Linear(dim, time_dim),
nn.GELU(),
nn.Linear(time_dim, time_dim),
)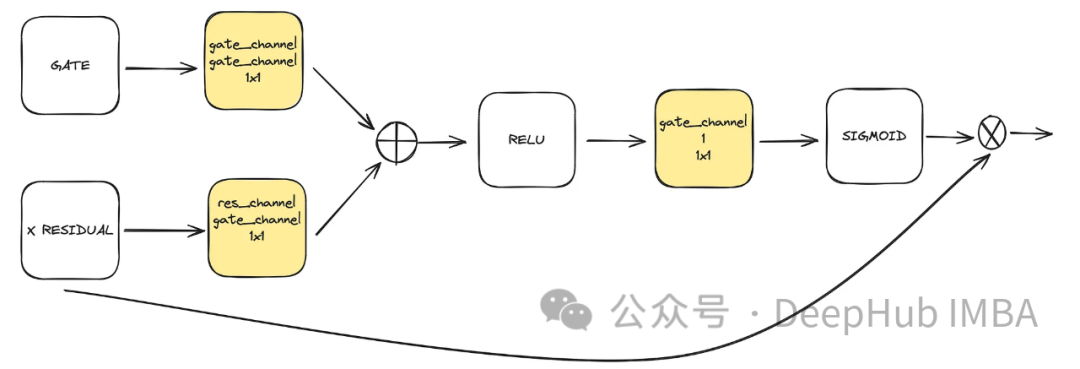
class BlockAttention(nn.Module):
def __init__(self, gate_in_channel, residual_in_channel, scale_factor):
super().__init__()
self.gate_conv = nn.Conv2d(gate_in_channel, gate_in_channel, kernel_size=1, stride=1)
self.residual_conv = nn.Conv2d(residual_in_channel, gate_in_channel, kernel_size=1, stride=1)
self.in_conv = nn.Conv2d(gate_in_channel, 1, kernel_size=1, stride=1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x: torch.Tensor, g: torch.Tensor) -> torch.Tensor:
in_attention = self.relu(self.gate_conv(g) + self.residual_conv(x))
in_attention = self.in_conv(in_attention)
in_attention = self.sigmoid(in_attention)
return in_attention * x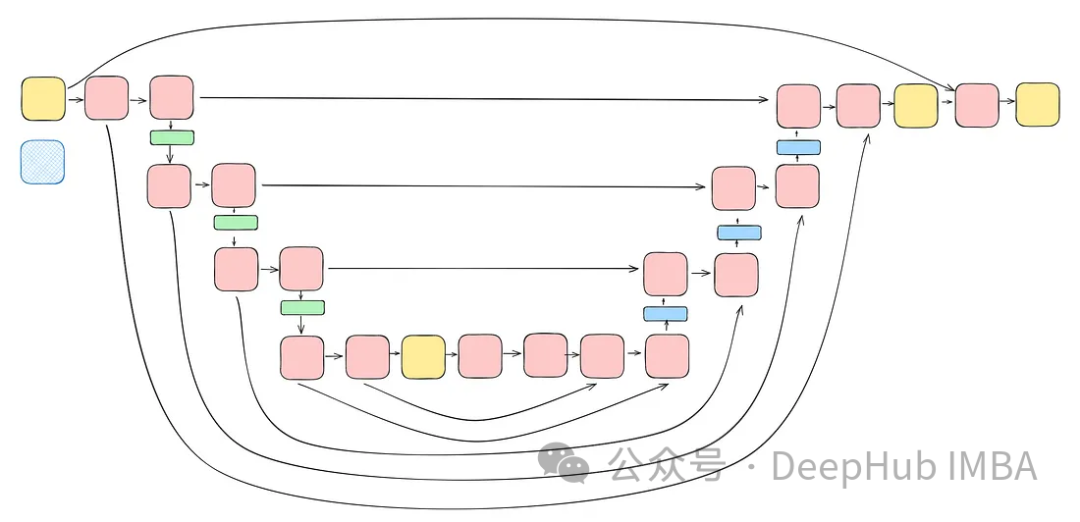
class DiffusionModel(nn.Module):
SCHEDULER_MAPPING = {
"linear": linear_beta_schedule,
"cosine": cosine_beta_schedule,
"sigmoid": sigmoid_beta_schedule,
}
class TwoResUNet(nn.Module):
def __init__(self,
dim,
init_dim=None,
out_dim=None,
dim_mults=(1, 2, 4, 8),
channels=3,
sinusoidal_pos_emb_theta=10000,
convnext_block_groups=8,
):
super().__init__()
self.channels = channels
input_channels = channels
self.init_dim = default(init_dim, dim)
self.init_conv = nn.Conv2d(input_channels, self.init_dim, 7, padding=3)
dims = [self.init_dim, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:]))
sinu_pos_emb = SinusoidalPosEmb(dim, theta=sinusoidal_pos_emb_theta)
time_dim = dim * 4
self.time_mlp = nn.Sequential(
sinu_pos_emb,
nn.Linear(dim, time_dim),
nn.GELU(),
nn.Linear(time_dim, time_dim),
)
self.downs = nn.ModuleList([])
self.ups = nn.ModuleList([])
num_resolutions = len(in_out)
for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1)
self.downs.append(
nn.ModuleList(
[
ConvNextBlock(
in_channels=dim_in,
out_channels=dim_in,
time_embedding_dim=time_dim,
group=convnext_block_groups,
),
ConvNextBlock(
in_channels=dim_in,
out_channels=dim_in,
time_embedding_dim=time_dim,
group=convnext_block_groups,
),
DownSample(dim_in, dim_out)
if not is_last
else nn.Conv2d(dim_in, dim_out, 3, padding=1),
]
)
)
mid_dim = dims[-1]
self.mid_block1 = ConvNextBlock(mid_dim, mid_dim, time_embedding_dim=time_dim)
self.mid_block2 = ConvNextBlock(mid_dim, mid_dim, time_embedding_dim=time_dim)
for ind, (dim_in, dim_out) in enumerate(reversed(in_out)):
is_last = ind == (len(in_out) - 1)
is_first = ind == 0
self.ups.append(
nn.ModuleList(
[
ConvNextBlock(
in_channels=dim_out + dim_in,
out_channels=dim_out,
time_embedding_dim=time_dim,
group=convnext_block_groups,
),
ConvNextBlock(
in_channels=dim_out + dim_in,
out_channels=dim_out,
time_embedding_dim=time_dim,
group=convnext_block_groups,
),
Upsample(dim_out, dim_in)
if not is_last
else nn.Conv2d(dim_out, dim_in, 3, padding=1)
]
)
)
default_out_dim = channels
self.out_dim = default(out_dim, default_out_dim)
self.final_res_block = ConvNextBlock(dim * 2, dim, time_embedding_dim=time_dim)
self.final_conv = nn.Conv2d(dim, self.out_dim, 1)
def forward(self, x, time):
b, _, h, w = x.shape
x = self.init_conv(x)
r = x.clone()
t = self.time_mlp(time)
unet_stack = []
for down1, down2, downsample in self.downs:
x = down1(x, t)
unet_stack.append(x)
x = down2(x, t)
unet_stack.append(x)
x = downsample(x)
x = self.mid_block1(x, t)
x = self.mid_block2(x, t)
for up1, up2, upsample in self.ups:
x = torch.cat((x, unet_stack.pop()), dim=1)
x = up1(x, t)
x = torch.cat((x, unet_stack.pop()), dim=1)
x = up2(x, t)
x = upsample(x)
x = torch.cat((x, r), dim=1)
x = self.final_res_block(x, t)
return self.final_conv(x) class TwoResUNet(nn.Module):
def __init__(
self,
model: nn.Module,
image_size: int,
*,
beta_scheduler: str = "linear",
timesteps: int = 1000,
schedule_fn_kwargs: dict | None = None,
auto_normalize: bool = True,
) -> None:
super().__init__()
self.model = model
self.channels = self.model.channels
self.image_size = image_size
self.beta_scheduler_fn = self.SCHEDULER_MAPPING.get(beta_scheduler)
if self.beta_scheduler_fn is None:
raise ValueError(f"unknown beta schedule {beta_scheduler}")
if schedule_fn_kwargs is None:
schedule_fn_kwargs = {}
betas = self.beta_scheduler_fn(timesteps, **schedule_fn_kwargs)
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
posterior_variance = (
betas * (1.0 - alphas_cumprod_prev) / (1.0 - alphas_cumprod)
)
register_buffer = lambda name, val: self.register_buffer(
name, val.to(torch.float32)
)
register_buffer("betas", betas)
register_buffer("alphas_cumprod", alphas_cumprod)
register_buffer("alphas_cumprod_prev", alphas_cumprod_prev)
register_buffer("sqrt_recip_alphas", torch.sqrt(1.0 / alphas))
register_buffer("sqrt_alphas_cumprod", torch.sqrt(alphas_cumprod))
register_buffer(
"sqrt_one_minus_alphas_cumprod", torch.sqrt(1.0 - alphas_cumprod)
)
register_buffer("posterior_variance", posterior_variance)
timesteps, *_ = betas.shape
self.num_timesteps = int(timesteps)
self.sampling_timesteps = timesteps
self.normalize = normalize_to_neg_one_to_one if auto_normalize else identity
self.unnormalize = unnormalize_to_zero_to_one if auto_normalize else identity
@torch.inference_mode()
def p_sample(self, x: torch.Tensor, timestamp: int) -> torch.Tensor:
b, *_, device = *x.shape, x.device
batched_timestamps = torch.full(
(b,), timestamp, device=device, dtype=torch.long
)
preds = self.model(x, batched_timestamps)
betas_t = extract(self.betas, batched_timestamps, x.shape)
sqrt_recip_alphas_t = extract(
self.sqrt_recip_alphas, batched_timestamps, x.shape
)
sqrt_one_minus_alphas_cumprod_t = extract(
self.sqrt_one_minus_alphas_cumprod, batched_timestamps, x.shape
)
predicted_mean = sqrt_recip_alphas_t * (
x - betas_t * preds / sqrt_one_minus_alphas_cumprod_t
)
if timestamp == 0:
return predicted_mean
else:
posterior_variance = extract(
self.posterior_variance, batched_timestamps, x.shape
)
noise = torch.randn_like(x)
return predicted_mean + torch.sqrt(posterior_variance) * noise
@torch.inference_mode()
def p_sample_loop(
self, shape: tuple, return_all_timesteps: bool = False
) -> torch.Tensor:
batch, device = shape[0], "mps"
img = torch.randn(shape, device=device)
# This cause me a RunTimeError on MPS device due to MPS back out of memory
# No ideas how to resolve it at this point
# imgs = [img]
for t in tqdm(reversed(range(0, self.num_timesteps)), total=self.num_timesteps):
img = self.p_sample(img, t)
# imgs.append(img)
ret = img # if not return_all_timesteps else torch.stack(imgs, dim=1)
ret = self.unnormalize(ret)
return ret
def sample(
self, batch_size: int = 16, return_all_timesteps: bool = False
) -> torch.Tensor:
shape = (batch_size, self.channels, self.image_size, self.image_size)
return self.p_sample_loop(shape, return_all_timesteps=return_all_timesteps)
def q_sample(
self, x_start: torch.Tensor, t: int, noise: torch.Tensor = None
) -> torch.Tensor:
if noise is None:
noise = torch.randn_like(x_start)
sqrt_alphas_cumprod_t = extract(self.sqrt_alphas_cumprod, t, x_start.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
self.sqrt_one_minus_alphas_cumprod, t, x_start.shape
)
return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
def p_loss(
self,
x_start: torch.Tensor,
t: int,
noise: torch.Tensor = None,
loss_type: str = "l2",
) -> torch.Tensor:
if noise is None:
noise = torch.randn_like(x_start)
x_noised = self.q_sample(x_start, t, noise=noise)
predicted_noise = self.model(x_noised, t)
if loss_type == "l2":
loss = F.mse_loss(noise, predicted_noise)
elif loss_type == "l1":
loss = F.l1_loss(noise, predicted_noise)
else:
raise ValueError(f"unknown loss type {loss_type}")
return loss
def forward(self, x: torch.Tensor) -> torch.Tensor:
b, c, h, w, device, img_size = *x.shape, x.device, self.image_size
assert h == w == img_size, f"image size must be {img_size}"
timestamp = torch.randint(0, self.num_timesteps, (1,)).long().to(device)
x = self.normalize(x)
return self.p_loss(x, timestamp)Implementation of Diffusion
class DiffusionModel(nn.Module):
SCHEDULER_MAPPING = {
"linear": linear_beta_schedule,
"cosine": cosine_beta_schedule,
"sigmoid": sigmoid_beta_schedule,
}
def __init__(
self,
model: nn.Module,
image_size: int,
*,
beta_scheduler: str = "linear",
timesteps: int = 1000,
schedule_fn_kwargs: dict | None = None,
auto_normalize: bool = True,
) -> None:
super().__init__()
self.model = model
self.channels = self.model.channels
self.image_size = image_size
self.beta_scheduler_fn = self.SCHEDULER_MAPPING.get(beta_scheduler)
if self.beta_scheduler_fn is None:
raise ValueError(f"unknown beta schedule {beta_scheduler}")
if schedule_fn_kwargs is None:
schedule_fn_kwargs = {}
betas = self.beta_scheduler_fn(timesteps, **schedule_fn_kwargs)
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
posterior_variance = (
betas * (1.0 - alphas_cumprod_prev) / (1.0 - alphas_cumprod)
)
register_buffer = lambda name, val: self.register_buffer(
name, val.to(torch.float32)
)
register_buffer("betas", betas)
register_buffer("alphas_cumprod", alphas_cumprod)
register_buffer("alphas_cumprod_prev", alphas_cumprod_prev)
register_buffer("sqrt_recip_alphas", torch.sqrt(1.0 / alphas))
register_buffer("sqrt_alphas_cumprod", torch.sqrt(alphas_cumprod))
register_buffer(
"sqrt_one_minus_alphas_cumprod", torch.sqrt(1.0 - alphas_cumprod)
)
register_buffer("posterior_variance", posterior_variance)
timesteps, *_ = betas.shape
self.num_timesteps = int(timesteps)
self.sampling_timesteps = timesteps
self.normalize = normalize_to_neg_one_to_one if auto_normalize else identity
self.unnormalize = unnormalize_to_zero_to_one if auto_normalize else identity
@torch.inference_mode()
def p_sample(self, x: torch.Tensor, timestamp: int) -> torch.Tensor:
b, *_, device = *x.shape, x.device
batched_timestamps = torch.full(
(b,), timestamp, device=device, dtype=torch.long
)
preds = self.model(x, batched_timestamps)
betas_t = extract(self.betas, batched_timestamps, x.shape)
sqrt_recip_alphas_t = extract(
self.sqrt_recip_alphas, batched_timestamps, x.shape
)
sqrt_one_minus_alphas_cumprod_t = extract(
self.sqrt_one_minus_alphas_cumprod, batched_timestamps, x.shape
)
predicted_mean = sqrt_recip_alphas_t * (
x - betas_t * preds / sqrt_one_minus_alphas_cumprod_t
)
if timestamp == 0:
return predicted_mean
else:
posterior_variance = extract(
self.posterior_variance, batched_timestamps, x.shape
)
noise = torch.randn_like(x)
return predicted_mean + torch.sqrt(posterior_variance) * noise
@torch.inference_mode()
def p_sample_loop(
self, shape: tuple, return_all_timesteps: bool = False
) -> torch.Tensor:
batch, device = shape[0], "mps"
img = torch.randn(shape, device=device)
# This cause me a RunTimeError on MPS device due to MPS back out of memory
# No ideas how to resolve it at this point
# imgs = [img]
for t in tqdm(reversed(range(0, self.num_timesteps)), total=self.num_timesteps):
img = self.p_sample(img, t)
# imgs.append(img)
ret = img # if not return_all_timesteps else torch.stack(imgs, dim=1)
ret = self.unnormalize(ret)
return ret
def sample(
self, batch_size: int = 16, return_all_timesteps: bool = False
) -> torch.Tensor:
shape = (batch_size, self.channels, self.image_size, self.image_size)
return self.p_sample_loop(shape, return_all_timesteps=return_all_timesteps)
def q_sample(
self, x_start: torch.Tensor, t: int, noise: torch.Tensor = None
) -> torch.Tensor:
if noise is None:
noise = torch.randn_like(x_start)
sqrt_alphas_cumprod_t = extract(self.sqrt_alphas_cumprod, t, x_start.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
self.sqrt_one_minus_alphas_cumprod, t, x_start.shape
)
return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
def p_loss(
self,
x_start: torch.Tensor,
t: int,
noise: torch.Tensor = None,
loss_type: str = "l2",
) -> torch.Tensor:
if noise is None:
noise = torch.randn_like(x_start)
x_noised = self.q_sample(x_start, t, noise=noise)
predicted_noise = self.model(x_noised, t)
if loss_type == "l2":
loss = F.mse_loss(noise, predicted_noise)
elif loss_type == "l1":
loss = F.l1_loss(noise, predicted_noise)
else:
raise ValueError(f"unknown loss type {loss_type}")
return loss
def forward(self, x: torch.Tensor) -> torch.Tensor:
b, c, h, w, device, img_size = *x.shape, x.device, self.image_size
assert h == w == img_size, f"image size must be {img_size}"
timestamp = torch.randint(0, self.num_timesteps, (1,)).long().to(device)
x = self.normalize(x)
return self.p_loss(x, timestamp)Summary of Training Points


Conclusion

Scan the QR code to add the assistant WeChat
About Us
