
Follow our public account to discover the beauty of CV technology
Spatial-temporal prediction learning is a field with a wide range of application scenarios, such as weather forecasting, traffic flow prediction, precipitation prediction, autonomous driving, and human motion prediction.
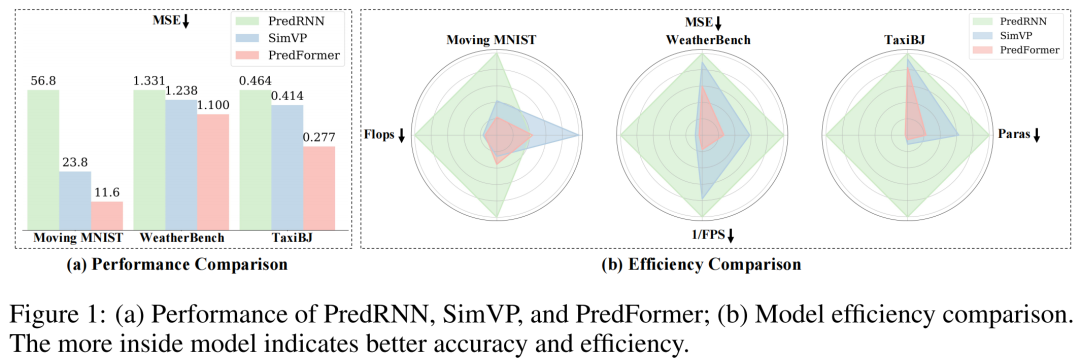
When it comes to spatial-temporal prediction, we must mention the classic model ConvLSTM and the most classic benchmark Moving MNIST. During the ConvLSTM era, predictions for Moving MNIST exhibited visible artifacts and prediction errors. However, in the latest model, PredFormer, the error for Moving MNIST has reached nearly perfect prediction results that are nearly indistinguishable to the naked eye.
 ConvLSTM
ConvLSTM
PredFormer
In previous spatial-temporal prediction works, there were mainly two schools: models based on recurrence (autoregressive), represented by ConvLSTM/PredRNN/E3DLSTM/SwinLSTM/VMRNN, and more recently, researchers have proposed the loop-free SimVP framework, consisting of a CNN Encoder-Decoder structure and a temporal transformer, represented by works like SimVP/TAU/OpenSTL.
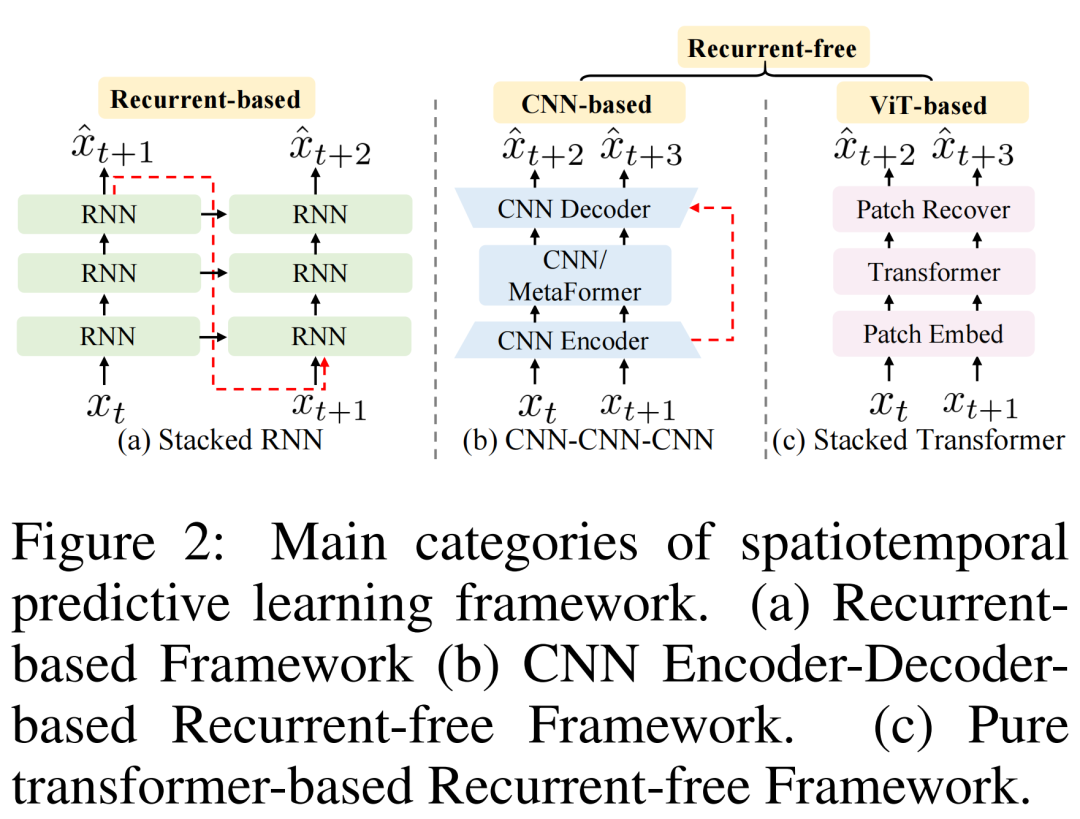
The drawbacks of RNN series models are that they cannot be parallelized, autoregressive speed is slow, memory usage is high, and efficiency is low; CNN series models improve efficiency without recurrence, benefiting from inductive bias, but often at the cost of generalization and scalability, resulting in a low model ceiling.
Thus, the authors raised the question, Do we really need RNN for spatial-temporal prediction? Do we really need CNN?
Can we design a model that can automatically learn the spatial-temporal dependencies in data without relying on inductive bias?
An intuitive idea is to use Transformers, given their broad success in various visual tasks and their strong potential as replacements for RNNs and CNNs. In previous spatial-temporal prediction works, some researchers have embedded Transformers into the aforementioned two frameworks, such as SwinLSTM (ICCV23), which integrates Swin Transformer and LSTM, and OpenSTL (NeurIPS23), which uses various MetaFormer structures (like ViT, Swin Transformer) as the temporal transformer in the SimVP framework. However, pure Transformer structured networks have rarely been explored.
The challenge of designing a pure Transformer model lies in how to handle both temporal and spatial information within a single framework. A simple idea is to merge spatial sequences and temporal sequences to compute spatial-temporal full attention. However, since the computational complexity of Transformers is quadratic to the sequence length, this approach can lead to high computational costs.
In this paper, the authors propose a new framework for spatial-temporal prediction learning called PredFormer, which is a pure ViT model that contains neither autoregression nor any convolution. The authors utilize a meticulously designed gated Transformer module to conduct a comprehensive analysis of 3D Attention, including spatial-temporal full attention, spatial-temporal decomposed attention, and spatial-temporal interleaved attention.
PredFormer adopts a non-recurrent, Transformer-based design that is both simple and efficient, requiring fewer parameters, FLOPS, and achieving faster inference speeds, with performance significantly superior to previous methods.
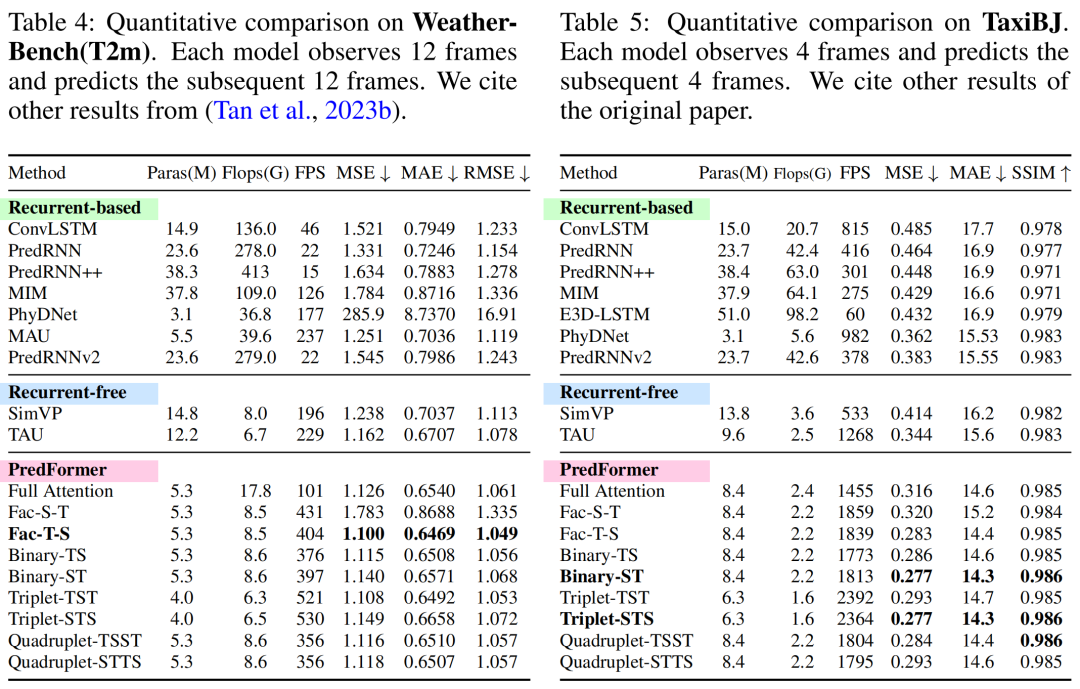
Extensive experiments conducted on synthetic and real datasets demonstrate that PredFormer achieves state-of-the-art performance. On Moving MNIST, PredFormer achieves a 51.3% reduction in MSE compared to SimVP, breaking through to 11.6. For TaxiBJ, the model reduces MSE by 33.1% and increases FPS from 533 to 2364.
Additionally, on WeatherBench, it reduces MSE by 11.1% while increasing FPS from 196 to 404. These improvements in accuracy and efficiency demonstrate the potential of PredFormer in practical applications.
The PredFormer model follows the standard ViT design, first performing Patch Embedding to convert the input spatial-temporal sequence of [B, T, C, H, W] into a tensor of [B, T, N, D]. In the positional encoding stage, the authors adopt a learnable positional encoding different from the general ViT design, instead using absolute positional encoding based on the sine function. The authors further elaborate on the superiority of absolute positional encoding in spatial-temporal tasks in their ablation experiments.
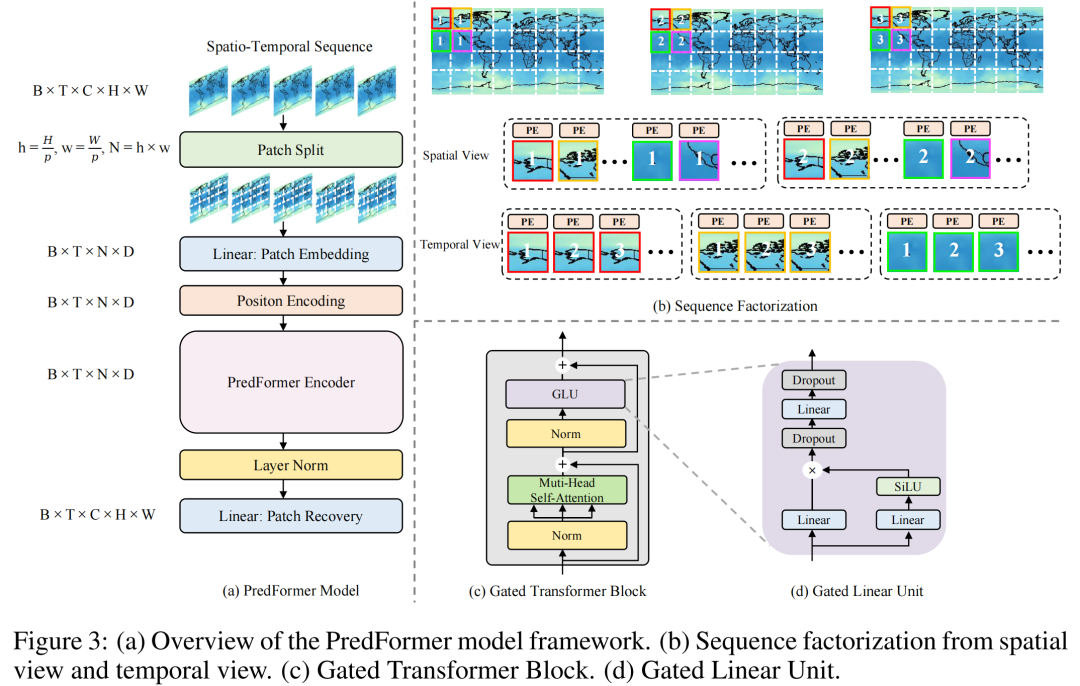
The encoder part of PredFormer is stacked using gated Transformer modules in different ways. Since the encoder part is a pure Transformer structure, without any convolution and without resolution reduction, each gated Transformer module models global information, allowing the model to form a powerful prediction model using only a simple decoder. The authors use a linear layer as a decoder for Patch Recovery, which recovers the model output from [B, T, N, D] back to [B, T, C, H, W].
Unlike standard Transformer models that use MLP as FFN, PredFormer employs Gated Linear Unit (GLU) as FFN, inspired by the superior performance of GLU over MLP in NLP tasks. The authors further elaborate on the superiority of GLU compared to MLP in spatial-temporal tasks in their ablation experiments.
The authors conducted a comprehensive analysis of 3D Attention and proposed 9 variants of PredFormer. In previous designs used for video classification, such as Video ViT, TimesFormer (ICML21), ViviT (ICCV21), and TSViT (CVPR23), analysis has also been conducted on spatial-temporal decomposition. However, TimesFormer performs decomposition at the self-attention level, meaning that spatial attention and temporal attention share one MLP. ViviT proposed decomposition at the encoder level (spatial first, then temporal), self-attention level, and head level. TSViT found that an encoder that processes temporal information first and spatial information second is more effective for classifying satellite sequence images.
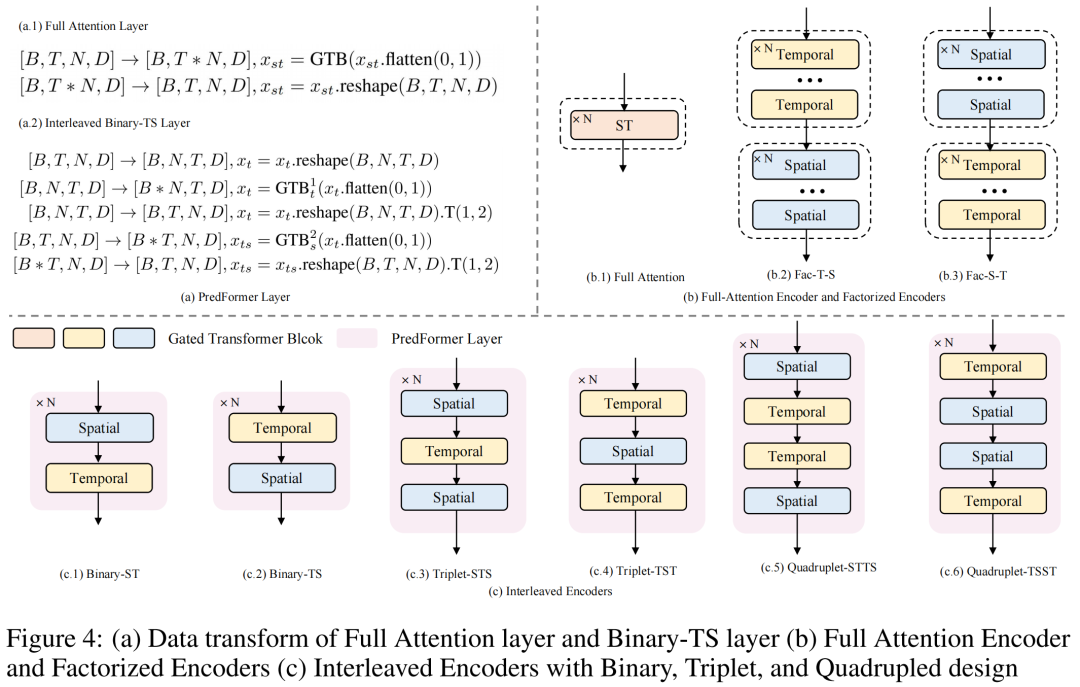
Unlike the aforementioned works, PredFormer conducts spatial-temporal decomposition at the Gated Transformer Block (GTB) level (adding Gated Linear Unit). Adding GLU to both temporal and spatial self-attention is crucial, as it allows the learned spatial-temporal features to interact and enhances non-linearity.
PredFormer proposes a spatial-temporal full attention encoder, two types of decomposed encoders (temporal first and spatial first), and six novel spatial-temporal interleaved encoders, totaling 9 models. PredFormer introduces the concept of the PredFormer Layer, which is the smallest unit capable of modeling both spatial and temporal information. Based on this idea, the authors propose three basic paradigms: pairs (composed of one Temporal GTB and one Spatial GTB, with T-S and S-T configurations), triplets (T-S-T and S-T-S), and quadruplets (two pairs reorganized in opposite directions).
This design stems from the fact that different spatial-temporal prediction tasks often have different spatial resolutions and temporal resolutions (time intervals and degrees of change), meaning that the degree of dependency on temporal and spatial information varies across different datasets. The authors designed these models to enhance the adaptability of the PredFormer model across different tasks.
In the experimental section, the authors controlled the number of proposed variants to use the same number of GTBs, ensuring that the model parameters were essentially consistent, thus allowing for performance comparison across different models. In cases where the number of triplet GTBs cannot be evenly divided, the closest number of triplets is selected.
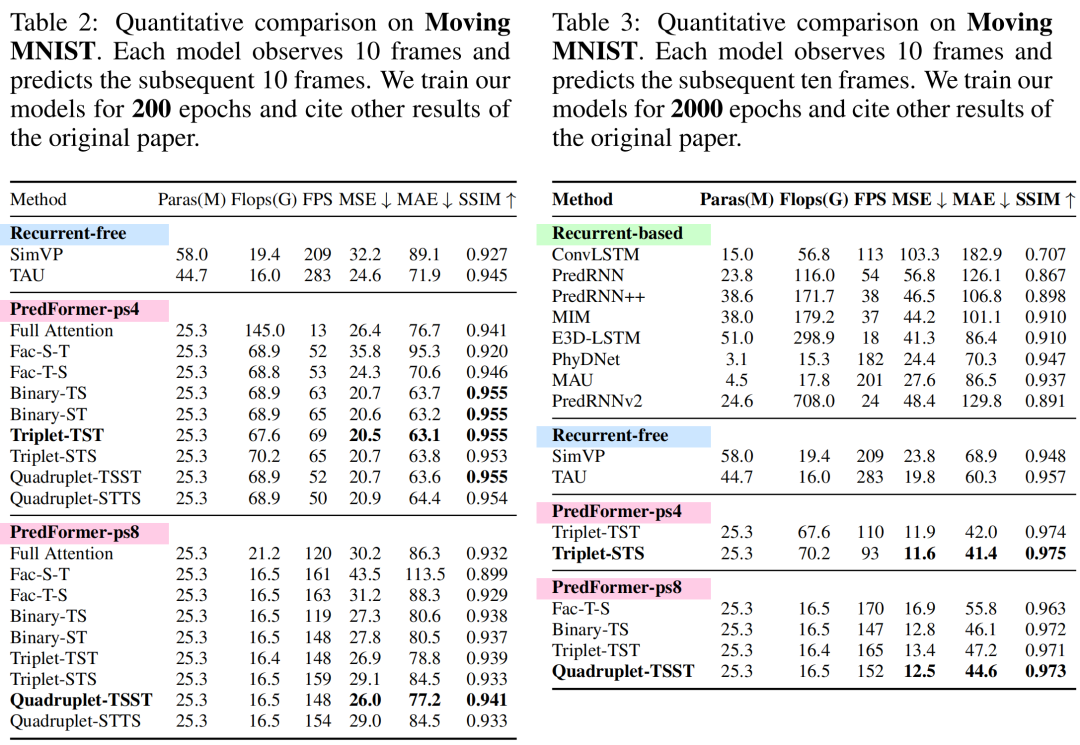
The experiments revealed some patterns:
-
Models with temporal-first decomposed encoders outperform the spatial-temporal full attention models, due to the spatial-first decomposed encoder models; -
The six spatial-temporal interleaved models perform well across most tasks, achieving state-of-the-art (SOTA) performance, but the optimal model varies due to the different spatial-temporal dependency characteristics of the datasets, highlighting the advantages of the PredFormer framework and its interleaved design; -
In the discussion section, the authors suggest starting with the quadruplet-TSST for other spatial-temporal prediction tasks, as this model has shown SOTA performance across three datasets. They recommend first adjusting the M parameter for TSST (which means 4M gated Transformers), and then trying M TSTs and M STSs to determine whether the dataset is more strongly dependent on temporal or spatial information. Thanks to the scalability of the Transformer architecture, unlike the CNN Encoder-Decoder model in the SimVP framework, which sets different values for spatial and temporal hidden dimensions and block numbers, PredFormer uses the same fixed parameters for spatial and temporal GTBs. Therefore, only adjusting the value of M allows for optimal performance after relatively few adjustments.
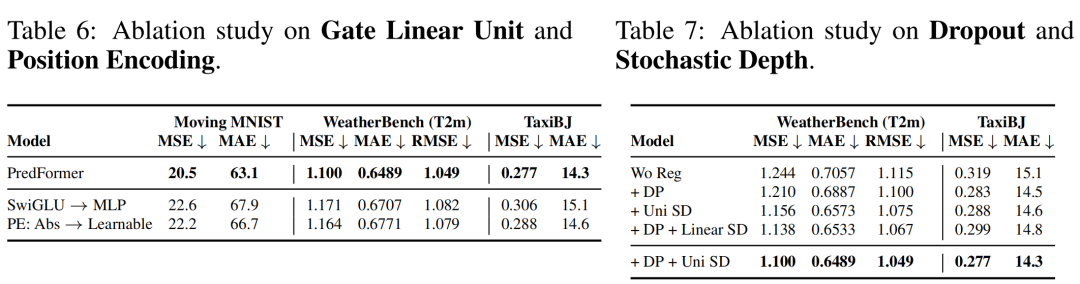
Training ViT models typically requires large datasets. In spatial-temporal prediction tasks, most datasets range from thousands to tens of thousands, making them prone to overfitting. The authors also explored different regularization strategies, including dropout and drop path. Through extensive ablation experiments, the authors found that using both dropout and uniform drop path (unlike the linear increase in drop path rate used in general ViTs) yields the best model performance.
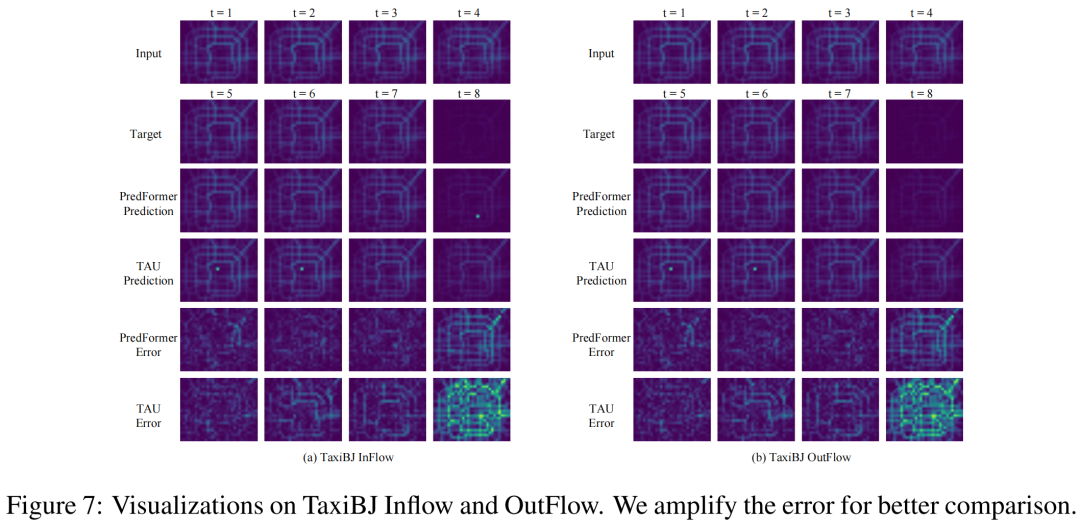
The authors also conducted visual comparisons, showing that PredFormer significantly reduces prediction error compared to TAU. They also provided a special example to demonstrate the superiority of the PredFormer model over CNN models in terms of generalization. In the traffic flow prediction task, when the fourth frame shows a significant decrease in flow compared to the previous three frames, TAU, constrained by inductive bias, still predicted a high flow, while PredFormer captured this change. The ability of PredFormer to predict drastic changes may have valuable applications in traffic flow and weather forecasting.

This paper proposes a non-recurrent, non-convolutional pure Transformer model and conducts a comprehensive analysis of spatial-temporal attention decomposition. PredFormer not only provides a robust baseline model but also paves the way for future innovative works based on pure Transformer architectures.
References
[1] PredFormer: Transformers Are Effective Spatial-Temporal Predictive Learners https://arxiv.org/abs/2410.04733

END
